There are three aggregate functions that are most often used in practice: COUNT, SUM and AVG. The first one has already been discussed previously, while the other two have interesting performance nuances. But first, some theory…
When using aggregate functions in the execution plan, there may be two operators: Stream Aggregate and Hash Match, depending on the input stream.
The first may require pre-sorted set of input values, while Stream Aggregate does not block the execution of subsequent operators.
In turn, Hash Match is a blocking operator (with rare exceptions) and does not require sorting of the input stream. Hash Match uses a hash table that is created in memory, and in the case of incorrect assessment of the expected number of rows, the operator can spill the results into tempdb.
In summary, Stream Aggregate works well with small sorted data sets, and Hash Match copes well with large unsorted sets and can be easily subject to parallel processing.
Now that we have mastered the theory, let’s look how the aggregate functions work.
Suppose we need to calculate the average price of all products:
SELECT AVG(Price) FROM dbo.Price
using the table with a fairly simple structure:
CREATE TABLE dbo.Price (
ProductID INT PRIMARY KEY,
LastUpdate DATE NOT NULL,
Price SMALLMONEY NULL,
Qty INT
)
Since we have a scalar aggregation here, we expect to see Stream Aggregate on the execution plan:
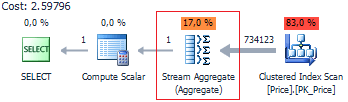
This operator executes two aggregation operations COUNT_BIG and SUM (although, on the physical layer, this is executed as a single operation) on the Price column:
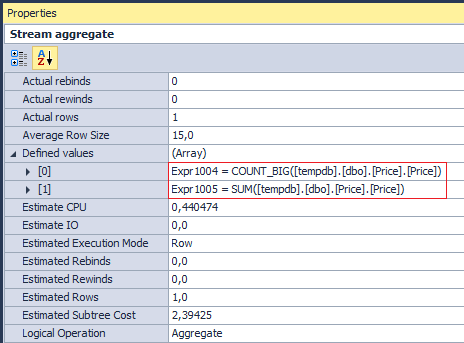
We should not forget that the average is calculated only for NOT NULL, because the COUNT_BIG operation uses a column, not an asterisk. Accordingly, the query is:
SELECT AVG(v)
FROM (
VALUES (3), (9), (NULL)
) t(v)
returns 6, not 4.
Now, let’s look at Compute Scalar, which has an interesting expression to check division by zero:
Expr1003 =
CASE WHEN [Expr1004]=(0)
THEN NULL
ELSE [Expr1005]/CONVERT_IMPLICIT(money,[Expr1004],0)
END
And try to calculate the total sum:
SELECT SUM(Price) FROM dbo.Price
The execution plan remains the same:
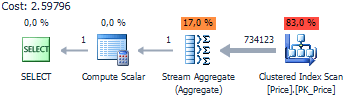
But if you look at the operations performed by Stream Aggregate…
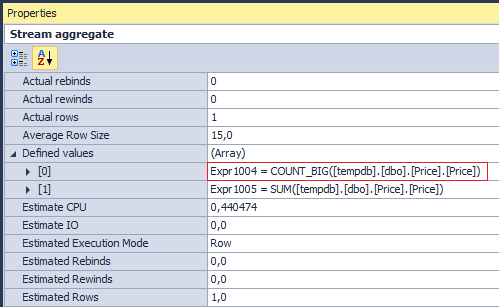
you can be slightly surprised. Why SQL Server counts, if I only need the sum? The answer lies in Compute Scalar:
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
If you do not take into account COUNT, than according to T-SQL semantics, when there are no rows in the input stream, we should get NULL, and not 0. This behavior true for both (scalar and vector) aggregations:
SELECT LastUpdate, SUM(Price) FROM dbo.Price GROUP BY LastUpdate OPTION(MAXDOP 1)
Expr1003 = Scalar Operator(CASE WHEN [Expr1008]=(0) THEN NULL ELSE [Expr1009] END)
Moreover, such a check is made both for NULL, and NOT NULL columns. Now let’s consider examples, in which the above-described features of SUM and AVG are effective.
If you want to calculate the average, do not use COUNT + SUM:
SELECT SUM(Price) / COUNT(Price) FROM dbo.Price
Since such a request would be less effective than the explicit use of AVG.
Furthermore … there is no need to explicitly pass NULL to the aggregate function:
SELECT
SUM(CASE WHEN Price > 100 THEN Qty ELSE NULL END),
SUM(CASE WHEN Price < 100 THEN Qty ELSE NULL END)
FROM dbo.Price
Since in this query:
SELECT
SUM(CASE WHEN Price > 100 THEN Qty END),
SUM(CASE WHEN Price < 100 THEN Qty END)
FROM dbo.Price
The optimizer automatically makes a substitution:
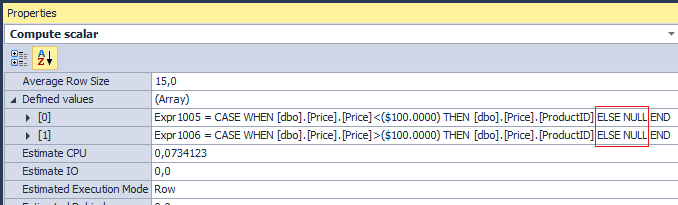
But what if I want to get 0 in the results, instead of NULL? People often use ELSE without hesitation:
SELECT
SUM(CASE WHEN Price > 100 THEN Qty ELSE 0 END),
SUM(CASE WHEN Price < 100 THEN Qty ELSE 0 END)
FROM dbo.Price
Obviously, in this case, we will achieve the desired result … and one warning will no longer be an eyesore:
Warning: Null value is eliminated by an aggregate or other SET operation.
Although, it is better to write the query like this:
SELECT
ISNULL(SUM(CASE WHEN Price > 100 THEN Qty END), 0),
ISNULL(SUM(CASE WHEN Price < 100 THEN Qty END), 0)
FROM dbo.Price
And this is good, not because the CASE operator will work faster. We already know that the optimizer automatically inserts ELSE NULL there … So what are the advantages of the last variant?
As it turned out, the aggregation operations, in which NULL values dominate, are processed faster.
SET STATISTICS TIME ON
DECLARE @i INT = NULL
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(@i),(@i),(@i),(@i),(@i),
(@i),(@i),(@i),(@i),(@i)
) t(N)
),
E2(N) AS (SELECT @i FROM E1 a, E1 b),
E4(N) AS (SELECT @i FROM E2 a, E2 b),
E8(N) AS (SELECT @i FROM E4 a, E4 b)
SELECT SUM(N) -- 100.000.000
FROM E8
OPTION (MAXDOP 1)
The execution took:
SQL Server Execution Times: CPU time = 5985 ms, elapsed time = 5989 ms.
Now, let’s change value:
DECLARE @i INT = 0
And execute again:
SQL Server Execution Times: CPU time = 6437 ms, elapsed time = 6451 ms.
It is not that essential, but in certain situations it still provides a reason for optimization.
The end of the play, the curtain falls? No. That’s not all…
As one of my friends says: “There is neither black nor white… the world is multicolored” and so I will provide an interesting example, where NULL can do harm.
Let’s create a slow function and a test table:
USE tempdb
GO
IF OBJECT_ID('dbo.udf') IS NOT NULL
DROP FUNCTION dbo.udf
GO
CREATE FUNCTION dbo.udf (@a INT)
RETURNS VARCHAR(MAX)
AS BEGIN
DECLARE @i INT = 1000
WHILE @i > 0 SET @i -= 1
RETURN REPLICATE('A', @a)
END
GO
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b)
SELECT *
INTO #temp
FROM E4
And execute the query:
SET STATISTICS TIME ON SELECT SUM(LEN(dbo.udf(N))) FROM #temp
SQL Server Execution Times: CPU time = 9109 ms, elapsed time = 11603 ms.
Now let’s try to add ISNULL for expression that is passed to SUM:
SELECT SUM(ISNULL(LEN(dbo.udf(N)), 0)) FROM #temp
SQL Server Execution Times: CPU time = 4562 ms, elapsed time = 5719 ms.
The execution speed decreased twofold. I must say that it’s not magic… but a bug in the SQL Server engine that has been “fixed” by Microsoft in SQL Server 2012 CTP.
The essence of the problem is as follows: the result of the expression inside the SUM or AVG function can be evaluate twice if the optimizer believes that it can return NULL.
Everything was tested on Microsoft SQL Server 2012 (SP3) (KB3072779) – 11.0.6020.0 (X64).
All execution plans from dbForge Studio for SQL Server.
