
Can it happen that the data stored in databases include identical records? Yes, it happens frequently. However, having duplicate records in databases is a scenario that should be avoided. Duplicates pose an ongoing risk to the data consistency and the overall database efficiency. Database administrators (DBAs) spend a significant portion of their time identifying and removing these duplicates.
This article will explore the issue of duplicate records, including their origins, the effects they have on databases, and strategies for swiftly detecting and permanently removing duplicates.
Table of contents
- Duplicate records in MySQL: Causes and consequences
- Preparing the test table and the environment
- Method 1: Using DELETE JOIN
- Method 2: Using temporary tables
- Method 3: Using GROUP BY with aggregation
- Method 4: Using ROW_NUMBER() window function
- How visual database managers transform data handling
- Conclusion
Duplicate records in MySQL: Causes and consequences
Duplicate records in MySQL refer to identical rows within a specific SQL table.
Before we proceed to explore methods to remove duplicate records from the databases, we need to understand their origins. Early detection and prevention of duplicates is the most effective approach.
Factors leading to duplicates include:
- Lack of unique identifiers: Fields that should be unique (such as user IDs, SSNs, email addresses, etc.) are crucial. The system should verify the uniqueness of each entry against existing records. Without this mechanism, duplicates are likely to occur.
- Insufficient validation checks: Having unique identifiers alone doesn’t guarantee the absence of duplicates if they fail to meet strict requirements and integrity constraints to be effective.
- Data entry errors: Even with proper identifiers and validation checks in place, mistakes during data entry can still lead to duplicates.
Ideally, each database record should be unique, representing a distinct entity. When records get duplicated, it leads to data redundancies and inconsistency:
- Data redundancies: This issue arises when the same data is stored multiple times, wasting storage space and causing confusion.
- Data inconsistency: Duplicates can corrupt the results of data retrieval operations.
Unfortunately, no single method can completely (entirely) prevent duplicate records. The focus is on reducing their occurrence and manually addressing them when they arise.
Consequently, DBAs face a dual challenge: identify and eliminate duplicate records, and mitigate their effects on the dataset. Let’s examine some practical examples of detecting and deleting duplicates.
Preparing the test table and the environment
We will use the standard MySQL test database sakila. To demonstrate various methods of deleting duplicate results, we also apply dbForge Studio for MySQL, a powerful, multi-featured integrated development environment (IDE) designed to handle all database tasks in MySQL and MariaDB.
In the sakila test database, we have created a new test table called customer_movie_rentals. It has duplicate records:
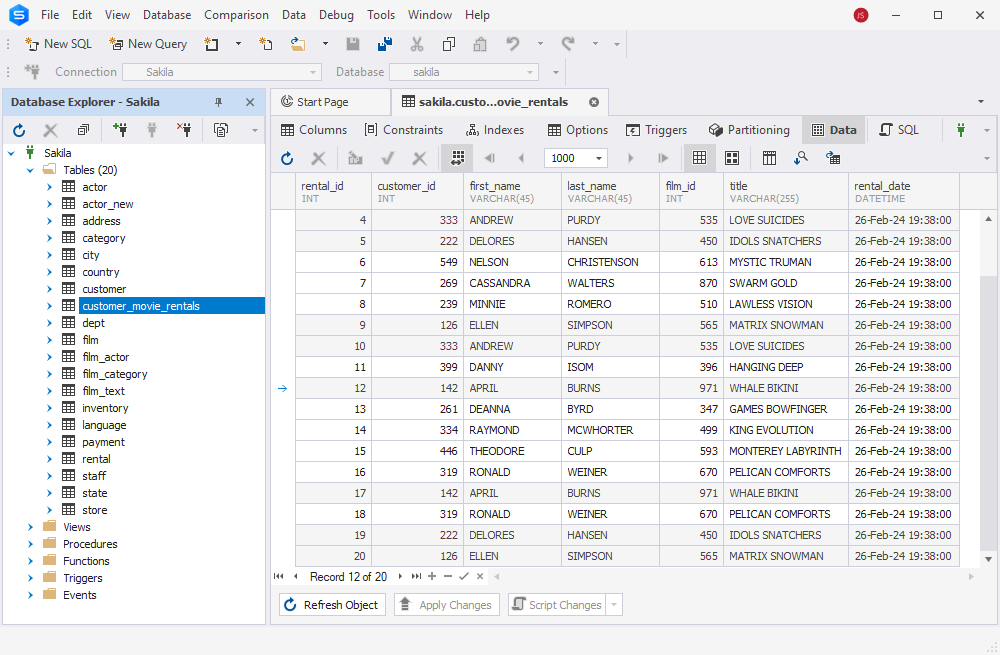
We can also check for duplicates using the below script – the output will inform us how many duplicate rows the table has. This option is convenient when dealing with large tables:
SELECT
customer_id,
first_name,
last_name,
COUNT(customer_id)
FROM customer_movie_rentals
GROUP BY customer_id
HAVING COUNT(customer_id) > 1;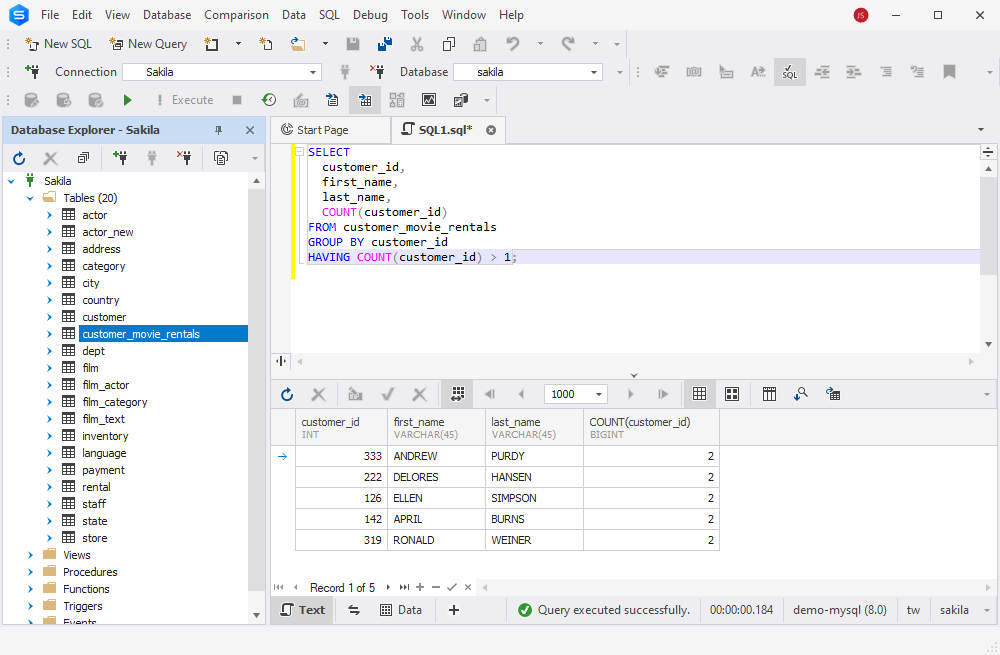
Another popular method of searching for duplicates involves the EXISTS statement:
-- EXISTS
SELECT t1.duplicate_column
FROM table_name t1
WHERE EXISTS (
SELECT 1
FROM table_name t2
WHERE t1.duplicate_column = t2.duplicate_column
AND t1.unique_column < t2.unique_column);
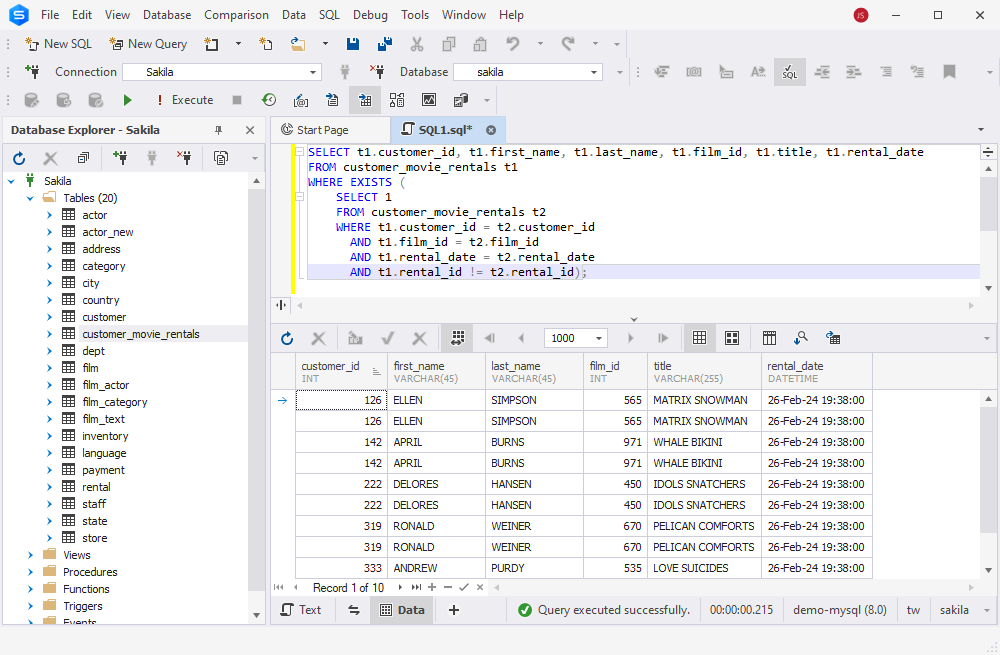
In our case, we modify this query to target the customer_movie_rentals table. The EXISTS query will find records with the same customer_id, film_id, and rental_date values but with a different rental_id (assuming rental_id is the unique identifier for each rental):
SELECT t1.customer_id, t1.first_name, t1.last_name, t1.film_id, t1.title, t1.rental_date
FROM customer_movie_rentals t1
WHERE EXISTS (
SELECT 1
FROM customer_movie_rentals t2
WHERE t1.customer_id = t2.customer_id
AND t1.film_id = t2.film_id
AND t1.rental_date = t2.rental_date
AND t1.rental_id != t2.rental_id);
The output shows us all duplicate records in the customer_movie_rentals table:
Now we need to get rid of those duplicates. Several methods are available in MySQL:
- DELETE JOIN
- Temporary Table
- Using GROUP BY
- Using ROW NUMBER()
Let us try these methods and also consider the best scenarios for each of them.
Method 1: Using DELETE JOIN
One of the most common methods of deleting duplicate records from MySQL tables is using DELETE JOIN – the INNER JOIN clause in the DELETE statement. The DELETE JOIN method allows for deleting rows matching other rows from the same table.
The basic syntax of this query is as follows:
DELETE t1
FROM table_name AS t1
INNER JOIN table_name AS t2
WHERE t1.unique_column < t2.unique_column
AND t1.duplicate_column = t2.duplicate_column;
Parameters:
t1 and t2 are aliases for the table containing duplicate rows. These aliases are necessary to represent two logical instances of the same table to allow the SELF JOIN operation.
INNER JOIN is necessary to find duplicate rows in the table in question.
WHERE clause is the condition specifying which rows should be deleted. In this case, the query should keep the first record and delete the subsequent duplicate records.
Now, our goal is to delete the duplicates from our customer_movie_rentals table using the DELETE JOIN statement. The query is as follows:
DELETE cr1
FROM customer_movie_rentals cr1
INNER JOIN customer_movie_rentals cr2
ON cr1.customer_id = cr2.customer_id
AND cr1.rental_id > cr2.rental_id;
In that query, cr1 and cr2 are aliases for the customer_movie_rentals table, and the condition cr1.rental_id > cr2.rental_id serves to retain only the row with the lowest rental_id value for each group of duplicates.
Here the output of the query is:
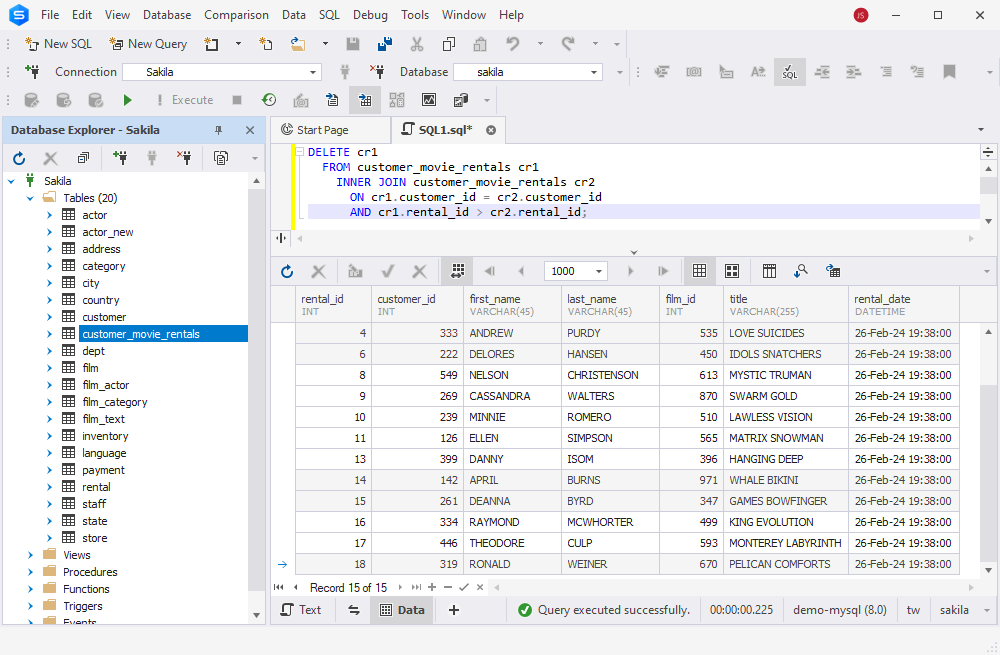
The duplicates for the customer_id values 333, 222, 126, 142, and 319 have been successfully deleted.
Using DELETE JOIN is most suitable for removing duplicates based on a specific join condition, especially when it is clear how tables (or data portions within one table) relate to each other. Also, this method is useful for complex queries, so you can control precisely which records to delete.
Method 2: Using temporary tables
Temporary tables in MySQL are a good choice when you need to retrieve, manipulate, and store some data portion temporarily without cluttering the databases. They can also help us detect and remove duplicates. As a rule, the process of deleting duplicate records with the help of temporary tables is as follows:
- Create a new temporary table with the same structure as the original table (with duplicates to delete).
- Insert unique rows from the original table into the temporary table.
- Truncate the original table and insert unique rows back to it from the temporary table.
This method is helpful when the duplicate rows are identical in all column values. Then we can use the SELECT DISTINCT command to copy only the unique rows into the temp table.
See the test table in the screenshot below. As you can see, some rows have identical values in all columns.
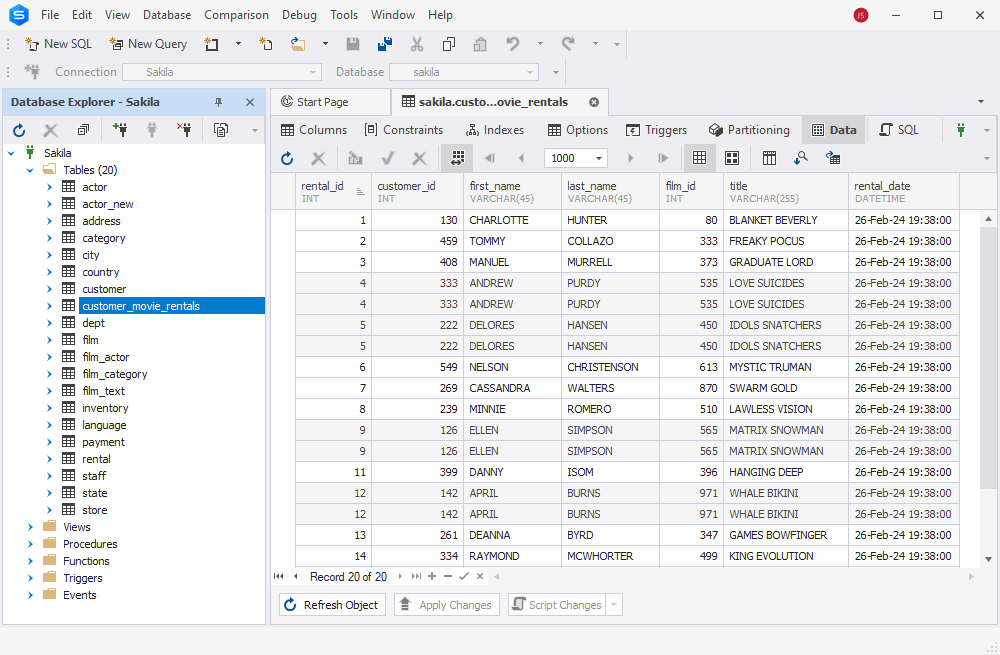
First, we create a temp table and copy only the unique rows from the customer_movie_rentals table into it:
-- 1. Create a temporary table
CREATE TEMPORARY TABLE temp_customer_movie_rentals LIKE customer_movie_rentals;
-- 2. Insert distinct rows into the temporary table
INSERT INTO temp_customer_movie_rentals
SELECT DISTINCT *
FROM customer_movie_rentals;
-- 3. View the temp table
SELECT * FROM temp_customer_movie_rentals;
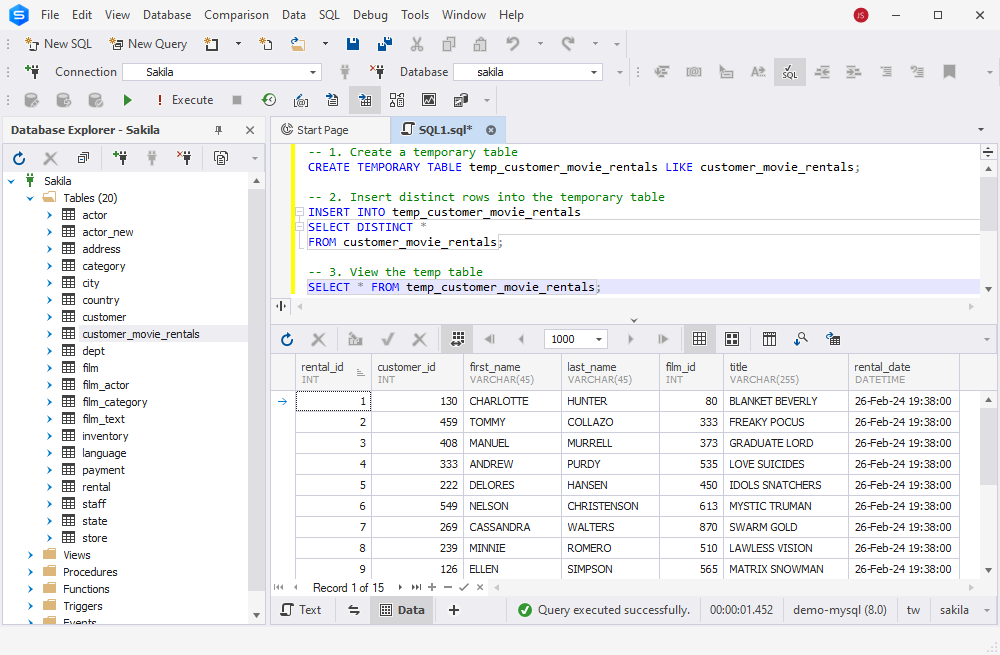
We can see that the temp table has only 15 rows, and all of them are unique. Now we can transfer this dataset back into the original table.
-- 1. Truncate the original table
TRUNCATE TABLE customer_movie_rentals;
-- 2. Insert records back into the original table
INSERT INTO customer_movie_rentals
SELECT * FROM temp_customer_movie_rentals;
-- 3. View the original table
SELECT * FROM customer_movie_rentals;
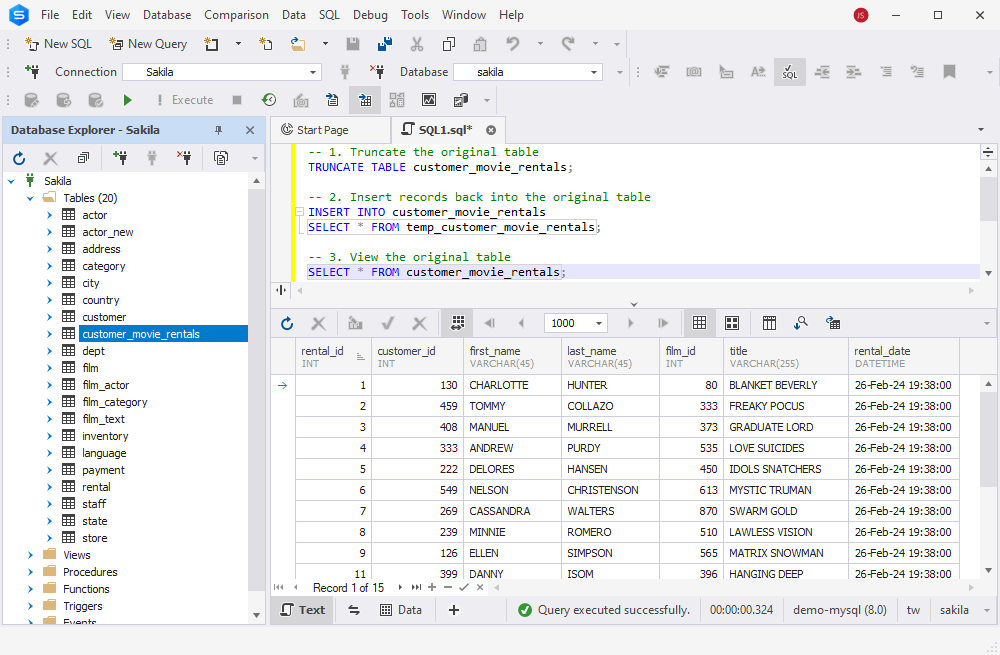
As you see, the original customer_movie_rentals table now has 15 rows instead of 20 and does not have duplicates.
The advantage of using a temporary table to delete duplicate rows is that it offers better data safety. You copy the unique records into a new temp table, and it won’t affect the original table. Then you can view the records in the temp table separately, compare it with the original table, and make sure that you have all the necessary data.
Method 3: Using GROUP BY with aggregation
The purpose of the GROUP BY clause in MySQL is to group table rows by one or several columns. When dealing with the duplicate rows issue, we can apply GROUP BY to identify the duplicates and then construct a query to delete them. This procedure involves several steps:
- Define the criteria for identifying duplicate rows. For instance, when you have a set of rows with identical values in all relevant columns, these rows are duplicates.
- Define the criteria for the row to keep when deleting duplicates. Usually, it is the smallest or the largest unique identifier.
- Delete all rows except for those matching the specific criteria.
The below script uses the aggregate MIN() function to determine the smallest unique identifier for the group of duplicates, and then it defines the range of rental_id values for unique rows. Finally, the query deletes rows matching the non-unique criterion.
The below script will remove duplicate rows from the customer_movie_rentals table using the GROUP BY clause with the aggregate function MIN():
DELETE
FROM customer_movie_rentals
WHERE rental_id NOT IN (SELECT
rental_id
FROM (SELECT
MIN(rental_id) AS rental_id
FROM customer_movie_rentals
GROUP BY CONCAT(customer_id, first_name, last_name)) AS duplicate_customer_ids);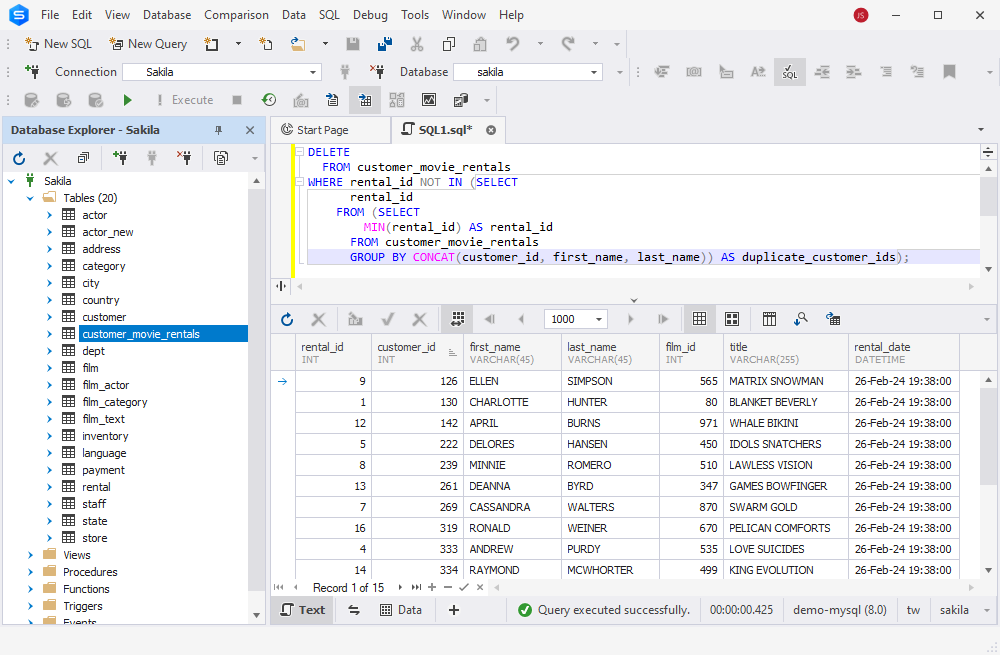
Using GROUP BY with aggregate functions is suitable when you want to identify duplicates based on the specific combination of columns, and where the criteria for duplicates are clear. However, it involves subqueries, which is not the most effective option especially when dealing with large tables. Therefore, it is not as straightforward as using temporary tables or DELETE JOIN in MySQL.
Method 4: Using ROW_NUMBER() window function
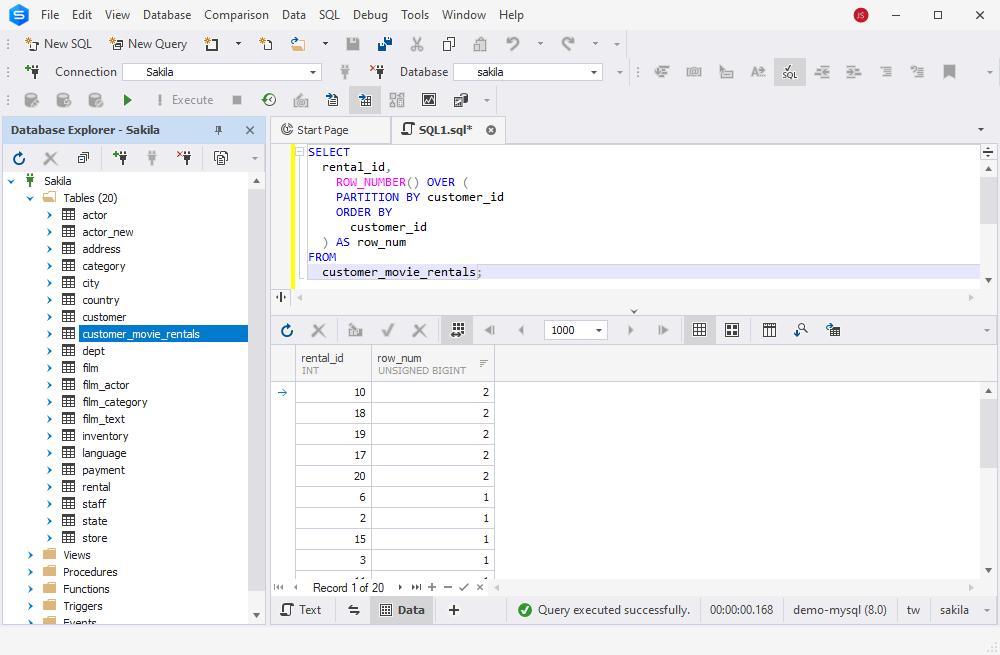
The ROW_NUMBER() function is one of the basic MySQL window functions that assigns unique numbers to each row, starting with 1 and further, sequentially. If we have duplicate records, their unique numbers will be > 1. This allows us to quickly identify duplicate records.
Let us apply ROW_NUMBER() to our customer_movie_rentals table:
SELECT
rental_id,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY customer_id
) AS row_num
FROM customer_movie_rentals;The output shows us the list of all rental_id values and we can quickly define the duplicate ones by simply sorting the results by the row_num column:
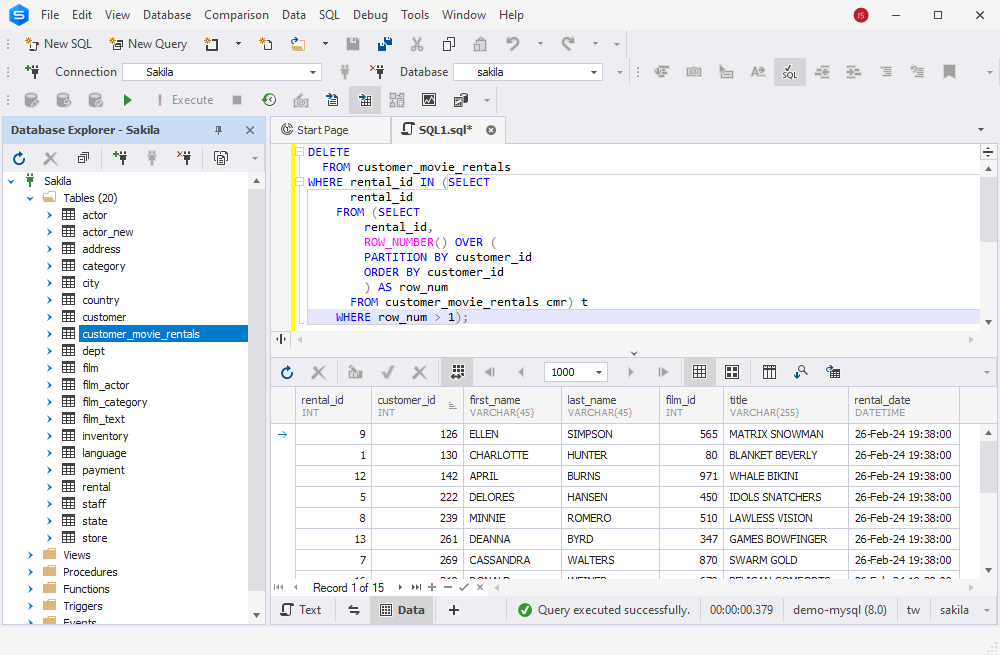
Now we can remove the duplicates using the DELETE command with the subquery:
DELETE
FROM customer_movie_rentals
WHERE rental_id IN (SELECT
rental_id
FROM (SELECT
rental_id,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY customer_id
) AS row_num
FROM customer_movie_rentals cmr) t
WHERE row_num > 1);
The output shows us no duplicates in the table.
Using the ROW_NUMBER() window function allows us to identify duplicate rows by assigning them unique numbers within the partition of the results set. This method is applicable when you have a complex set of duplicate criteria. Again, using the DELETE command with subqueries can consume more user time to construct the query and more resources to execute it.
How visual database managers transform data handling
We used dbForge Studio for MySQL to demonstrate how to remove duplicate rows. It is just one of many features available in this tool. dbForge Studio is a comprehensive integrated development environment (IDE) that is more advanced than the default MySQL Workbench. It provides users with a wide range of tools for managing MySQL and MariaDB databases, from SQL coding to version control, and more.
In our work, we primarily applied the coding assistance module of dbForge Studio, which offers extensive features to accelerate coding tasks, such as phrase auto-completion, context-sensitive suggestions, syntax checking, code formatting, and more. The functionality available in this module aims to enhance efficiency and ensure high-quality results.
The software’s graphical user interface presents query results in an easily interpretable format. Specifically, it enabled us to visually identify duplicate rows and formulate queries with greater precision to eliminate them.
While this example highlights just one aspect of dbForge Studio for MySQL, the IDE has consistently demonstrated its value to database developers, managers, and administrators globally, streamlining their tasks, optimizing workflows, and reducing manual labor.
Conclusion
While it is crucial to implement efficient data validation and cleaning processes to minimize the occurrence of duplicate records, some level of data entry errors causing these duplicates may still occur. There are multiple approaches to detecting and removing duplicate rows in MySQL tables, and we have reviewed them in this article. The choice depends on your unique conditions, work requirements, and preferences.
As eliminating duplicates is necessary to maintain data integrity, modern tools like dbForge Studio for MySQL can simplify this process, making it quicker and more efficient. This Studio is a comprehensive solution for managing database tasks, and you can assess its effectiveness in your work environment with a 30-day free trial. This trial provides full access to advanced features and professional support from the vendor, so you can integrate this tool effectively into your workflows.