
There is no way to completely avoid index fragmentation in any SQL Server environment. It does not depend on your SQL Server version, the I/O subsystem you have, or your hardware. In this article, we will drill down into the SQL Server index fragmentation issue and how to tackle it. We will figure out why index fragmentation is a problem and how it affects overall performance and discuss how to detect and avoid it.
This article has been updated on Oct/06/2023. We have added some useful information on best practices to prevent index fragmentation, optimizing performance through fill factor utilization, highlighting new features and updates in recent SQL Server versions, and strategies for minimizing index fragmentation.
Contents
- What is index fragmentation?
- Detecting index fragmentation
- How index fragmentation occurs?
- Best practices to avoid index fragmentation
- Leveraging fill factor for optimal performance
- New features and updates in recent SQL Server versions
- Strategies for removing index fragmentation
- Conclusion
What is index fragmentation?
We are going to begin with defining index fragmentation. It is a common term that describes numerous effects that can occur because of data modifications. Chances are, you already know that SQL Server stores data on 8KB data pages. Eight contiguous pages form the extent. A data page, both in clustered or non-clustered indexes, contains pointers to the next and previous pages. The following picture demonstrates that there is no fragmentation.
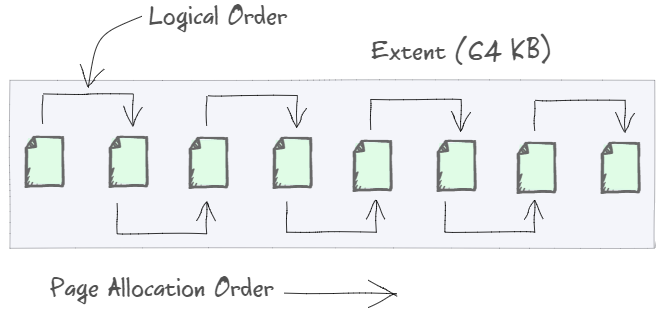
Let’s insert a new row into the index and see what happens. SQL Server inserts a new row on the data page in case there is enough free space on that page. Otherwise, the following happens:
- SQL Server allocates a new data page or even a new extent.
- A part of data from the existing (old) data page transfers to a newly allocated data page.
- In order to keep the logical sorting order in the index, pointers on both pages are updated.

As a consequence, we have two types of index fragmentation:
Logical fragmentation (also called external fragmentation or extent fragmentation) — the logical order of the pages does not correspond to their physical order. As a result, SQL Server increases the number of physical (random) reads from the hard drive, making the read-ahead mechanism less efficient. This directly impacts the query execution time because random reading from the hard drive is far less efficient compared to sequential reading.
Internal fragmentation — the data pages in the index contain free space. This leads to an increase in the number of logical reads during the query execution because the index utilizes more data pages to store data.
The fragmentation of a SQL Server database can significantly impact its performance. It leads to increased disk I/O operations and slower query response times as the server must sift through scattered data. Moreover, it can cause decreased efficiency in memory usage and even contribute to higher storage costs due to suboptimal space utilization.
Detecting index fragmentation
Using SQL commands
Before you decide which defragmentation approach to use, it is required to analyze the index to find out the degree of fragmentation. You can use the sys.dm_db_index_physical_stats data management function to analyze fragmentation. The following columns in the resultset are the most important:
avg_page_space_used_in_percenat shows the average percentage of the data storage space used on the page. This value allows you to see the internal index fragmentation.
avg_fragmentation_in_percent provides you with information about external index fragmentation. For tables with clustered indexes, it indicates the percent of out-of-order pages when the next physical page allocated in the index is different from the page referenced by the next-page pointer of the current page. For heap tables, it indicates the percent of out-of-order extents when extents are not residing continuously in data files.
fragment_count indicates how many continuous data fragments the index has. Every fragment constitutes a group of extents adjacent to each other. Adjacent data increases the chances that SQL Server will use sequential I/O and Read-Ahead while accessing the data.
Using SQL Server Management Studio (SSMS)
In case you are a SQL Server Management Studio (SSMS) user, the approach to detecting fragmentation will be a bit different:
- Launch SSMS and connect to the SQL Server instance containing the database you want to analyze.
- Expand the Databases node in the Object Explorer.
- Right-click the database you are interested in and select New Query.
- In the query window that opens, type
DBCC SHOWCONTIG ('table_name');replacingtable_namewith the name of the table you wish to analyze. Click Execute or press F5. - The results will display information about the fragmentation level of the indexes on the specified table. Look for the Scan Density and Logical Scan Fragmentation columns to assess the degree of fragmentation. Based on the output, you can determine whether index maintenance is needed.
Advanced tools and functions for analysis
While default tools within SQL Server can effectively address index fragmentation, there are instances where more advanced solutions become necessary, especially for ongoing maintenance. This is where dbForge Index Manager proves invaluable. Its specialized features and capabilities streamline the process of identifying and managing fragmented indexes, ensuring optimal database performance. With this tool, database administrators gain a powerful tool that simplifies the often complex task of maintaining index health, ultimately leading to smoother and more efficient database operations.
To open the Index Manager in SSMS, right-click the database you want to analyze and select Index Manager > Manage Index Fragmentation. This will trigger the database scanning.
After scanning the database, the Index Manager: [database_name] document opens, dividing all the indexes into two sections:
- Action required: This section displays all indexes that require maintenance based on the default index fragmentation analysis criteria.
- No action required: This section displays indexes that do not require maintenance based on the default index fragmentation analysis criteria.
Each section displays the following index details:
- Fix type, which is a recommended action to take on the indexes
- Index name
- Database object name to which the index belongs
- Type of the index, either clustered or non-clustered
- Index size in pages and Mb
- Index fragmentation in %
- Partition number
- Rows in partition
- Reason for index maintenance
- Result of the fix action. When you click Fix, this column will inform you that the index has been successfully rebuilt or reorganized (depending on the fix type)
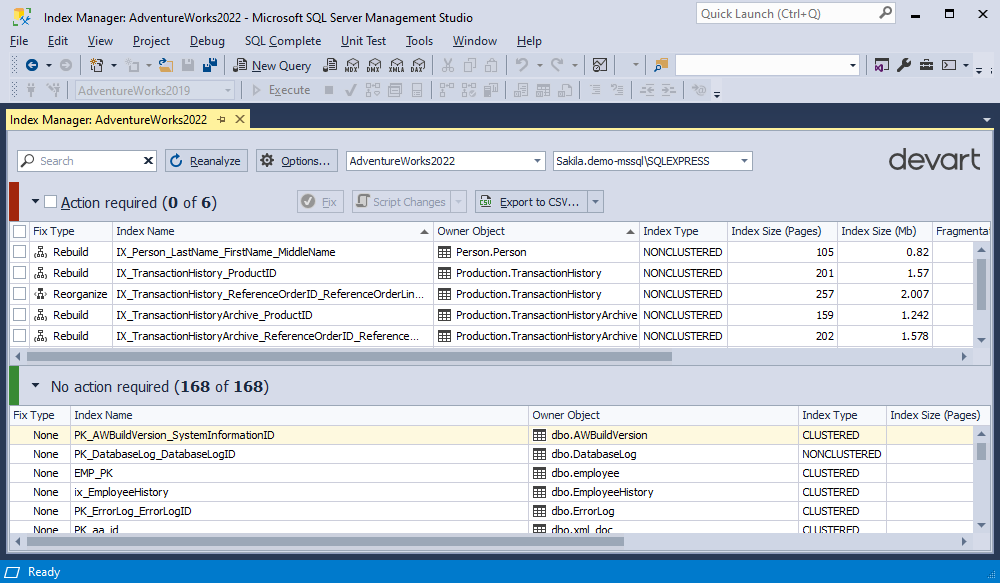
In the Action required section, you can perform the actions on all indexes by selecting the checkbox next to the section name or individual indexes by selecting the checkbox next to the specific index on the results grid.
How index fragmentation occurs?
In order to avoid or at least minimize the index fragmentation, we need to figure out why it occurs in the first place:
- Data modifications and fragmentation: When data is modified, such as through inserts, updates, or deletes, the index structure can become disorganized. This happens because the database engine may not always be able to keep the index perfectly ordered, leading to fragmentation over time.
- Page splits and extents: Page splits occur when a new record is added to a page that’s already full. This forces the page to split into two, causing fragmentation. Extents, which are groups of eight contiguous pages, can also contribute to fragmentation if they become unevenly distributed.
- Examples and real-world cases of fragmentation: Understanding specific examples and real-world cases of fragmentation provides insight into its impact. For instance, a table that experiences frequent inserts and deletes without regular maintenance can exhibit high levels of fragmentation. This can lead to slower query performance and increased disk I/O operations.
Best practices to avoid index fragmentation
To avoid index fragmentation, try to adhere to the following rules:
- Choose a cluster key that complements the table’s insert pattern.
- Do not insert records with random key values.
- Do not update records to make them longer.
- Do not update index key columns.
- Be aware of features that can cause page splits.
- Implement index fill factors.
Leveraging fill factor for optimal performance
Utilizing index fill factor
Set SQL Server to leave free space on index leaf pages. The main idea is to allow records to expand and records to be inserted without filling out the page and having to cause page split.
Therefore, you need to figure out how much space you want to leave. The amount of space to use is 100% minus the fill factor value (e.g., a fill factor of 70 means 30% free space).
SQL Server only uses the fill factor when an index is created, rebuilt, or reorganized. The index fill factor is not used during regular inserts, updates, and deletes. In fact, that does not make any sense because the whole point is to allow inserts and updates to happen and to add more records without filling up the page.
It is possible to set the instance fill factor using sp_configure, but it is not recommended. The reason is when you set the fill factor for the entire instance, there are probably some indexes that do not need a fill factor. If you find that you’ve got fragmentation problems on the non-leaf level of the index (rare), you can use the PAD_INDEX option. It takes the fill factor that has been specified and puts it up to the non-leaf level.
Setting a fill factor
Probably the easiest way to set the fill factor is to use the FILLFACTOR option when you create or rebuild an index. You can also use the Object Explorer to set the fill factor. Note that you can not set the fill factor when you reorganize an index. Both REBUILD and REORGANIZE use the fill factor stored in index metadata. Otherwise, they use the instance-wide (default) fill factor unless the FILLFACTOR option is specified for a REBUILD.
An obvious question arises: “What fill factor do I use?”. Well, actually, there is no magic number. You just need to pick an initial fill factor and implement it. Put it into production and then monitor how quickly fragmentation occurs. Then, choose to do one or both of the following: increase/decrease the fill factor or change the frequency of index maintenance.
New features and updates in recent SQL Server versions
Understanding how the most recent SQL Server updates affect index fragmentation is crucial for database administrators and developers. It enables them to adapt their maintenance strategies to ensure optimal performance in the evolving SQL Server environment. New features can impact index fragmentation in several ways:
| Feature | Purpose |
| SQL Server ledger | Ledger provides a tamper-proof record of transactions, potentially reducing the need for extensive indexing by ensuring data integrity and reliability. |
| Support for more memory | Increased memory support allows for larger in-memory tables and indexes, lowering disk I/O and mitigating fragmentation. |
| Concurrency scalability support | Enhanced concurrency management can lead to more efficient transaction processing, reducing contention that can contribute to fragmentation. |
| Data virtualization for any data lake | Virtualization capabilities can streamline data access, reduce the need for extensive indexing, and minimize fragmentation. |
| Query Store by default and replica support | Query Store allows for the tracking of query performance over time. It can indirectly reduce fragmentation by identifying and optimizing poorly performing queries. |
Strategies for removing index fragmentation
Let’s figure out what is the difference between ALTER INDEX … REBUILD and ALTER INDEX … REORGANIZE. The following table demonstrates the difference:
| ALTER INDEX… REBUILD | ALTER INDEX… REORGANIZE |
| No knowledge of schema required | No knowledge of schema required |
| Can operate on single partition | Can operate on single partition |
| Possible to determine Progress | sys.dm_exec_requests |
| Can use multiple CPUs | Always single-threaded |
| Updates index statistics | No statistics update |
| Faster for a heavily-fragmented index | Slower for a heavily-fragmented index |
| Lots of options | Very few options |
| Can set the index FILLFACTOR | Cannot set the index FILLFACTOR |
| Can reduce logging by switching to the BULK_LOGGED recovery mode | Always fully logged |
| Choose online or offline | Always online |
| Offline requires the SCH_M table lock | Only requires the IX table lock |
| Must build a new index before dropping and old one | Only requires 8KB of disk space as existing pages are shuffled in place |
| Slower for a lightly fragmented index | Faster for a lightly fragmented index |
| All-or-nothing | Interruptible with no loss of work |
| Does not operate on LOB data | Compacts LOB data by default |
There is no correct answer in regards: “What to use: REBUILD or REORGANIZE?” One of Microsoft Books Online provides the following guidance:
0 to 5-10% — do nothing
5-10% to 30% — do REORGANIZE
30% to 100% — do REBUILD
Eventually, you have several basic options to remove index fragmentation:
- Choose to rebuild the index
- Choose to reorganize the index
- Be forced to reorganize by HA/DR features
- Do nothing
- Use CREATE INDEX…WITH (DROP_EXISTING=ON) — does the same as ALTER INDEX…REBUILD, but you need to specify the entire CREATE INDEX statement.
Conclusion
In conclusion, understanding and addressing index fragmentation is crucial for maintaining a high-performing SQL Server database. By learning how it occurs, detecting it effectively, and implementing best practices such as leveraging fill factor and staying updated with the latest features, you can proactively manage and mitigate fragmentation issues. Additionally, employing effective strategies for removing fragmentation ensures your database continues to operate at its optimal efficiency. By following these guidelines, you can enhance the overall performance and longevity of your SQL Server environment.
In case you need a tool that allows you to quickly collect index fragmentation statistics and detect databases that require maintenance, we might offer just the one. With dbForge Index Manager, you can instantly rebuild and reorganize SQL Server indexes in visual mode or generate SQL scripts for future use. Give it a go with its fully functional 30-day free trial.