")
In this article, we will show how you can take more control over the data in your database by using a custom hash function Python generator in the dbForge Data Generator tool. We will provide an example Python script, which you will be able to later use as a starting point for creating your own scripts.
Data-driven applications, that operate on diverse sets of data, are now appearing and spreading across the economy with a huge speed. Our world for sure has become data-driven itself. In data-driven apps, the behavior of an application is governed by the data it processes, and the input data set can significantly affect the flow of the application. This leads us to the question, ‘How should those apps be tested?’ It is axiomatic that real production data can not be used for this purpose. Thus, there appears an overwhelming need for precise, interrelated, and meaningful test data.
The other problem is that the test data needs to be quickly generated and accurately inserted into databases. There are dozens of data generator solutions on the market today, however, most of them have a problem generating interrelated, realistic-like data. dbForge Data Generator for SQL Server really stands out from the other tools as it delivers an advanced Python generator that allows defining the generated data using IronPython scripts.
What is more—you can use dbForge Data Generator not only for populating databases with high-quality fake data but also for managing data in your production databases. Let’s consider the example of using a custom hash function Python generator to create unique IDs based on the combination of columns with different data types.
Worked Example
Suppose, we have the actor table in a database. Here is the script for it:
CREATE TABLE actor_sample (
actor_id SMALLINT NOT NULL PRIMARY KEY
,first_name VARCHAR(45) NOT NULL
,last_name VARCHAR(45) NOT NULL
,last_update DATETIME NOT NULL DEFAULT (CURRENT_TIMESTAMP)
,Unique_ID VARCHAR(255) DEFAULT NULL
);Problem
We want to generate unique IDs into the Unique_ID column. The generated IDs unlike the auto-increment primary keys need to depend on the data in the table and be unique for different combinations of values in the three columns that contain meaningful data (first_name, last_name, and last_update). And when repopulating the Unique_ID column, it should always generate the number it generated before in case that combination has occurred earlier.
Solution
The task can be easily accomplished with the help of the custom hash function Python generator.
Python hash() is a built-in function that accepts input expressions of arbitrary types and returns the hash values of objects, which are also called hash codes, digests, or simply hash. These values represent fixed-sized integers that identify particular values. Hash is very useful, as it allows for a quick look-up of values in large sets of values.
In simple words, hashing is a method used to turn data into a fixed-length number that may serve as a digital “fingerprint” of that data. Those “fingerprints’ or hash values then can be used for compression, data comparison, cryptology, etc. Hash values are widely used in data indexing since they have fixed length regardless of the size of the values they were generated from. Thus hash occupies minimal space in a database compared to other values of varying lengths.
Python script to be used
import hashlib
t="|%s|%s|%s|" % (first_name, last_name, str(last_update))
t1=hashlib.sha1(t)
t1.hexdigest()Where:
1) Python hashlib module is used.
2) Non-string formats are converted into strings and concatenated.
3) The SHA1 hash function is used to calculate an alphanumeric string.
How to use the Python Generator of the dbForge Data Generator tool
dbForge Data Generator for SQL Server comes with the advanced Python Generator that allows generating data using IronPython scripts.
To generate data using the Python Generator:
1. Open the dbForge Data Generator for SQL Server and click New Data Generation on the ribbon.
2. In the Data Generator Project Properties window that opens, specify a required connection and database. Then click Next.
3. On the Options tab, make the necessary configurations for your Data Generator Project. Once done, click Open.
4. In the Data Generator Project that opens, select a table or tables you want to generate data for.
5. In the navigation tree, click the column you need to assign the Python Generator to.
6. Select Python from the Generator drop-down list on the right.
7. Enter the required Python script in the field and preview the data to be generated in the grid at the bottom of the window.
8. Click the Green arrow to populate the table with the generated data.
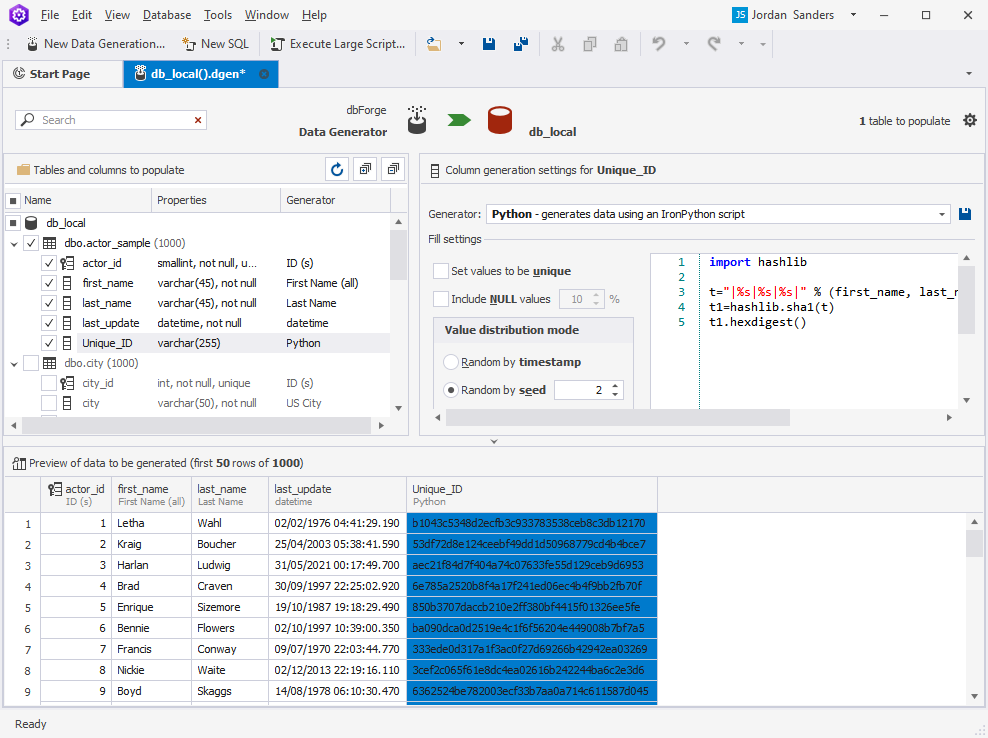
As you can see, the script works perfectly and the unique IDs have been successfully generated.
Potential for use
So, when might you need to generate hash keys like in our worked example? One reason is to prevent hackers from using sequential auto-incremented keys to take a stroll through your database. The other example is to simplify data comparison in two different databases—having the unique IDs generated with the help of the hash function will allow you not to compare all the columns in the two tables, but only the ones containing these unique IDs.
Conclusion
In the article, we consider a simple and elegant method to generate unique and conclusive IDs that depend on the data in the table. We provide a sample Python script and give a detailed step-by-step guide on how to use that script in the dbForge Data Generator tool to achieve a successful result.
Give dbForge Data Generator for SQL Server a try for 30 days absolutely free! Download the full-featured trial version of the product and test-drive it on your projects.
