
The news about Microsoft’s intention to “chum” SQL Server with Linux keeps floating around. But I haven’t heard a single word about SQL Server 2016 Release Candidate, that recently became available for download.
The release of SQL Server 2016 RTM is set for next month. So, in this overview I will cover some new features that will become available in new version on SQL Server, i.e. installation diffs, default TraceFlags, new functionality and the killer feature for analysis of execution plan.
Let’s start with the installation of an instance of SQL Server 2016. In comparison with the previous version, the installer has undergone the following transformations:
• Only the 64-bit version of SQL Server is available for installation (the last x86 build has been cut off in CTP2.3). Here is the official statement: “SQL Server 2016 Release Candidate (RC0) is a 64-bit application. 32-bit installation is discontinued, though some elements run as 32-bit components”.
• SQL Server 2016 does not support Windows 7 and Windows Server 2008. The official list of supported systems is as follows: all x64 editions of Windows 8/8.1/10 and Windows Server 2012.
• SSMS is not provided with SQL Server and is developed separately. To download the standalone edition of SSMS, click this link. The new edition of SSMS supports SQL Server 2005…2016. Thus, you don’t need to keep the collection of SSMS’s for each version.
• There are two new components that implement the support for the R languages and PolyBase (bridge between SQL Server and Hadoop):
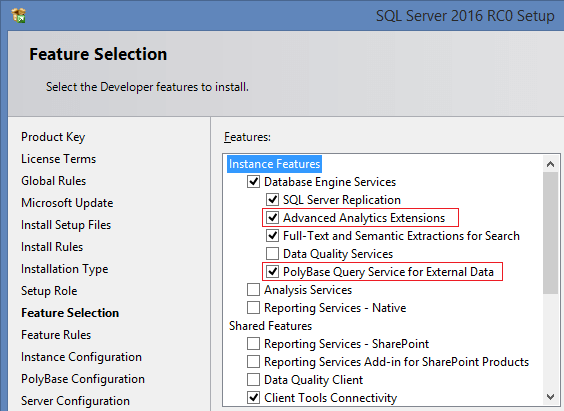
To work with PolyBase, you need to install JRE7, or a newer version:
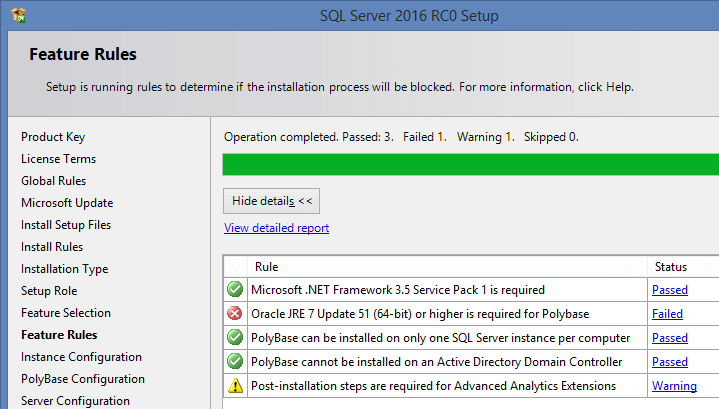
And don’t forget to add the selected range of ports to the Firewall extensions:
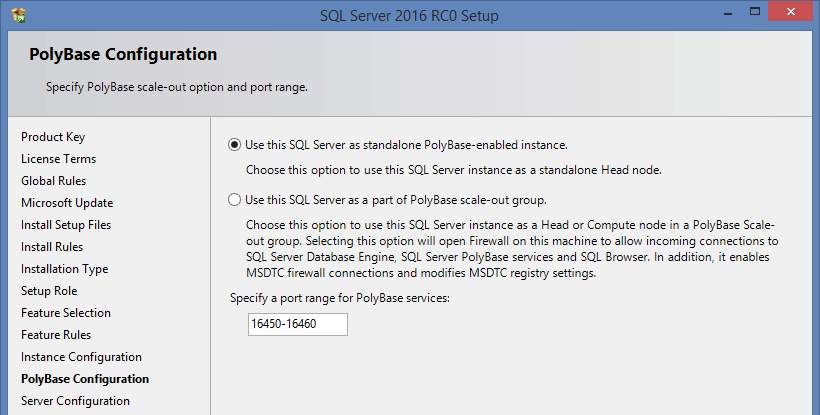
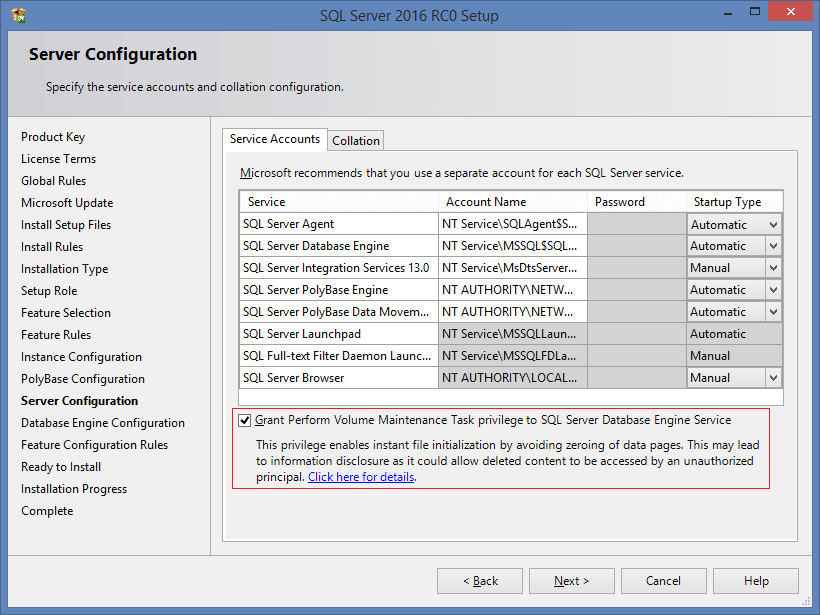
I’m really grateful to Microsoft. Now you can turn on Instant File Initialization in the easy way during installation:
The dialog box for selection of default paths has been also changed a bit:
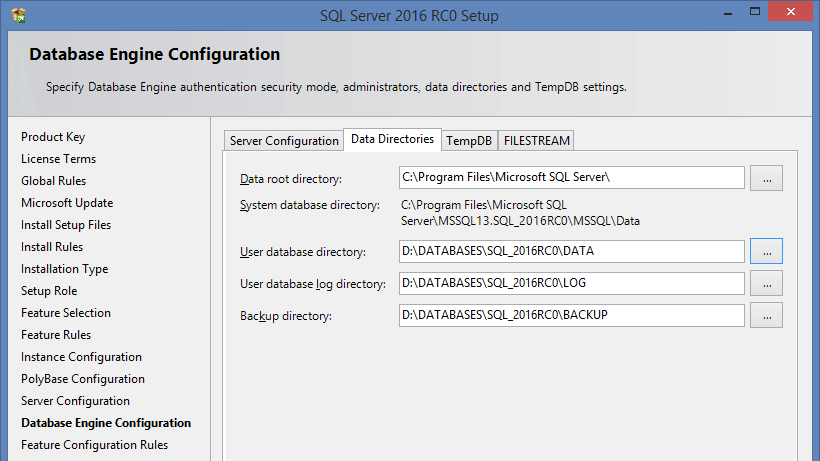
The separate tab for setting up tempdb has been introduced:
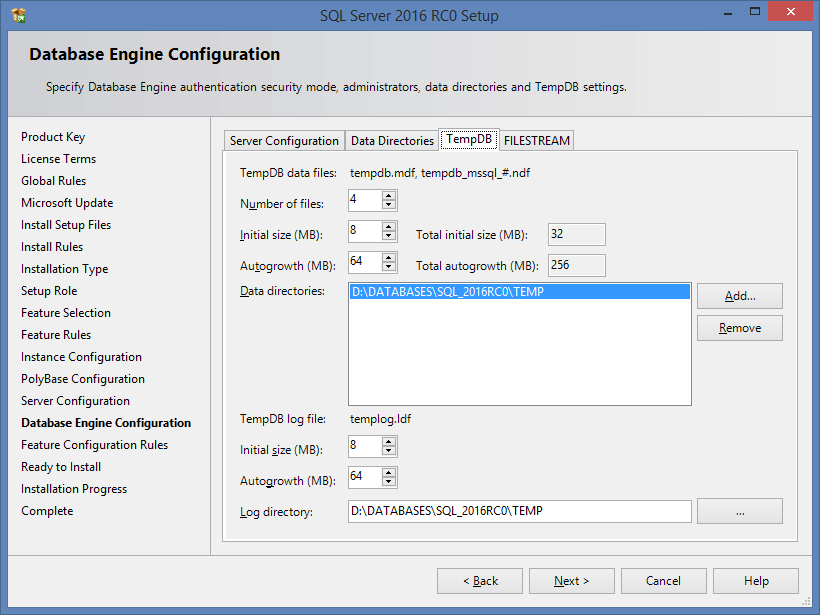
It allows to automatically set up the required number of files and, if required, to distribute them over different discs. But even without it, the Autogrowth parameter will be not 1Mb (as it used to be), but 64Mb by default.
Upon that, the maximal file size is limited to 256Mb. You can increase it, but it is possible only after installation:
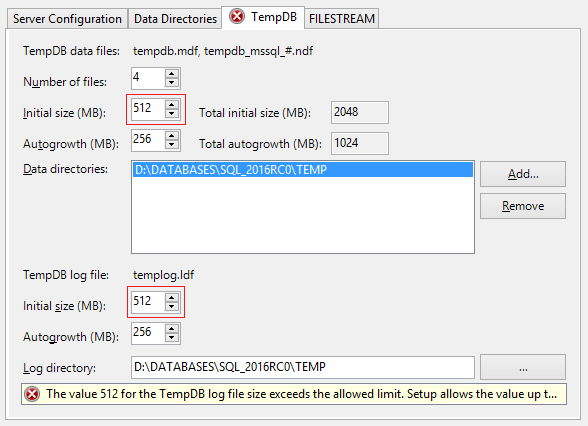
At this point, installation diffs are over. Now, let’s take a look at other changes.
The settings of the model system database have been modified to minimize the number of AutoGrow events:
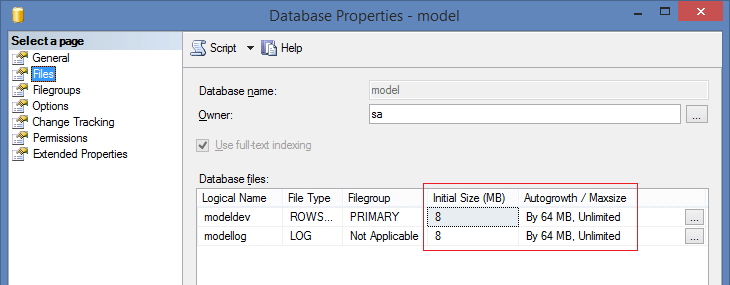
It is also worth mentioning that some TraceFlags on the new SQL Server will be enabled by default…
-T1118
SQL Server reads data from disc by parts 64Kb each (also known as extents). Extent is a group of eight physically consequent pages (8Kb each) of database files.
There are two types of extents: mixed and dedicated. A mixed extent may store pages from different objects. Such behavior allows very small tables to take up the minimum amount of space. But in most cases, tables go beyond 64Kb, and when more than 8 pages are required to store data for one object, the switch to allocation of dedicated extents takes place.
For initial allocation of dedicated extents for an object, TF1118 was provided. It was recommended to enable this trace flag. Therefore, it worked globally for all databases on the server.
It is not the case in version 2016. Now, you can set the MIXED_PAGE_ALLOCATION option for each user database:
ALTER DATABASE test SET MIXED_PAGE_ALLOCATION OFF
As for system databases, this option is enabled by default, i.e. nothing has changed:
SELECT name, is_mixed_page_allocation_on FROM sys.databases
The exception has been made for user databases and tempdb:
name is_mixed_page_allocation_on ----------------- --------------------------- master 1 tempdb 0 model 1 msdb 1 DWDiagnostics 0 DWConfiguration 0 DWQueue 0 test 0
Here is a small example:
IF OBJECT_ID('dbo.tbl') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (ID INT DEFAULT 1)
GO
CHECKPOINT
GO
INSERT dbo.tbl DEFAULT VALUES
GO
SELECT [Current LSN], Operation, Context, AllocUnitName, [Description]
FROM sys.fn_dblog(NULL, NULL)
MIXED_PAGE_ALLOCATION = ON:
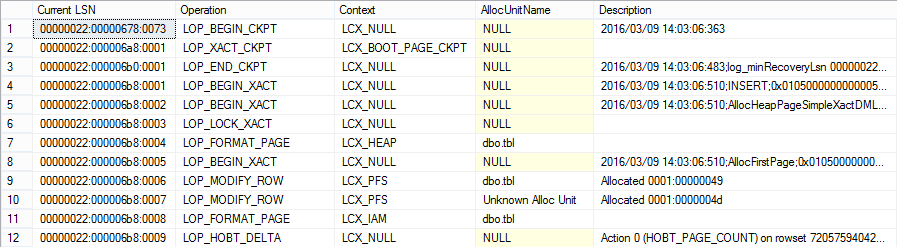
MIXED_PAGE_ALLOCATION = OFF:
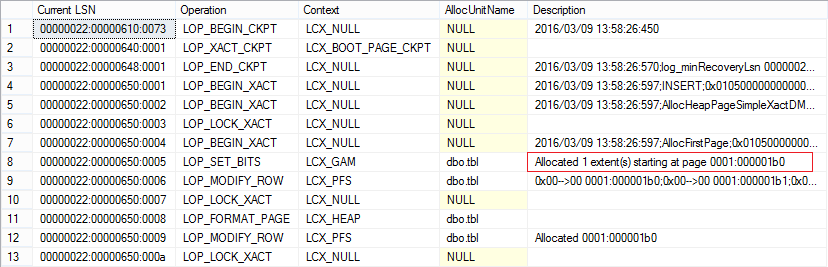
-T1117
Several files can be created within one file system. For instance, it is recommended to create several files for the tempdb database, that can increase system performance in certain scenarios.
Now, let’s put the case where all files being parts of the file group have similar size. One big temporary table is created. File #1 has sufficient space and, naturally, AutoGrow takes place. After a while, similar table is recreated, but insert is performed into file #2, since file #1 is temporary blocked. What will happen in this case? AutoGrow for file #2… and recurrent delay during query execution. For such cases, TF1117 was provided. TF1117 worked globally, and when one file was overloaded, it called AutoGrow for all files within one file group.
Now this trace flag is enabled for tempdb by default and can be set up selectively for user databases:
ALTER DATABASE test
MODIFY FILEGROUP [PRIMARY] AUTOGROW_ALL_FILES
GO
ALTER DATABASE test
MODIFY FILEGROUP [PRIMARY] AUTOGROW_SINGLE_FILE
GO
Let’s take a look at the file size:
USE tempdb
GO
SELECT
name
, physical_name
, current_size_mb = ROUND(size * 8. / 1024, 0)
, auto_grow =
CASE WHEN is_percent_growth = 1
THEN CAST(growth AS VARCHAR(10)) + '%'
ELSE CAST(CAST(ROUND(growth * 8. / 1024, 0) AS INT) AS VARCHAR(10)) + 'MB'
END
FROM sys.database_files
WHERE [type] = 0
name physical_name size_mb auto_grow ---------- --------------------------------------------------- -------- ------------ tempdev D:\DATABASES\SQL_2016RC0\TEMP\tempdb.mdf 8.000000 64MB temp2 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_2.ndf 8.000000 64MB temp3 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_3.ndf 8.000000 64MB temp4 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_4.ndf 8.000000 64MB
Let’s create a temporary database:
IF OBJECT_ID('#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (
ID INT DEFAULT 1,
Value CHAR(8000) DEFAULT 'X'
)
GO
INSERT INTO #t
SELECT TOP(10000) 1, 'X'
FROM [master].dbo.spt_values c1
CROSS APPLY [master].dbo.spt_values c2
There is not enough space to insert data and AutoGrow will take place.
AUTOGROW_SINGLE_FILE:
name physical_name size_mb au-to_grow ---------- --------------------------------------------------- ----------- ------------ tempdev D:\DATABASES\SQL_2016RC0\TEMP\tempdb.mdf 72.000000 64MB temp2 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_2.ndf 8.000000 64MB temp3 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_3.ndf 8.000000 64MB temp4 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_4.ndf 8.000000 64MB
AUTOGROW_ALL_FILES:
name physical_name size_mb au-to_grow ---------- --------------------------------------------------- ----------- ------------ tempdev D:\DATABASES\SQL_2016RC0\TEMP\tempdb.mdf 72.000000 64MB temp2 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_2.ndf 72.000000 64MB temp3 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_3.ndf 72.000000 64MB temp4 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_4.ndf 72.000000 64MB
-T2371
Before version 2016, the magic number “20% + 500 records” was used. Here is the example:
USE [master]
GO
SET NOCOUNT ON
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE [test] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [test]
END
GO
CREATE DATABASE [test]
GO
USE [test]
GO
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (
ID INT IDENTITY(1,1) PRIMARY KEY,
Value CHAR(1)
)
GO
CREATE NONCLUSTERED INDEX ix ON dbo.tbl (Value)
GO
INSERT INTO dbo.tbl
SELECT TOP(10000) 'x'
FROM [master].dbo.spt_values c1
CROSS APPLY [master].dbo.spt_values c2
To refresh statistics, we need to modify the following:
SELECT [>=] = COUNT(1) * .20 + 500 FROM dbo.tbl HAVING COUNT(1) >= 500
In this case, it is 2500 rows, not at a time, but in general… this value is cumulative. First of all, let’s execute the following query:
UPDATE dbo.tbl SET Value = 'a' WHERE ID <= 2000
Here is the result:
DBCC SHOW_STATISTICS('dbo.tbl', 'ix') WITH HISTOGRAM
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS ------------ ------------- ------------- -------------------- -------------- x 0 10000 0 1
Statistics is old… Let’s perform one more query:
UPDATE dbo.tbl SET Value = 'b' WHERE ID <= 500
Hurray! Statistics has been updated:
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS ------------ ------------- ------------- -------------------- -------------- a 0 1500 0 1 b 0 500 0 1 x 0 8000 0 1
Now, let’s suppose we have a large table, let’s say 10-20-30 million records. To recalculate statistics, we need to modify a massive range of data or to monitor the statistics update manually.
In SQL Server 2008R2 SP1, TF2371 was introduced. This trace flag understated that magic percent dynamically, depending on general quantity of records:
30k = 18% > 40k = 15% > 100k = 10% > 500k = 5% > 1000k = 3.2%
In SQL Server 2016, TF2371 is enabled by default.
-T8048
If your system includes 8 logical processes and a big number or waits for CMEMTHREAD and short-term blocks are expected:
SELECT waiting_tasks_count
FROM sys.dm_os_wait_stats
WHERE wait_type = 'CMEMTHREAD'
AND waiting_tasks_count > 0
SELECT spins
FROM sys.dm_os_spinlock_stats
WHERE name = 'SOS_SUSPEND_QUEUE'
AND spins > 0
the usage of TF8048 helped to get rid of performance issues. In SQL Server 2016, this trace flag is enabled by default.
SCOPED CONFIGURATION
The new group of settings was introduced at the database level:
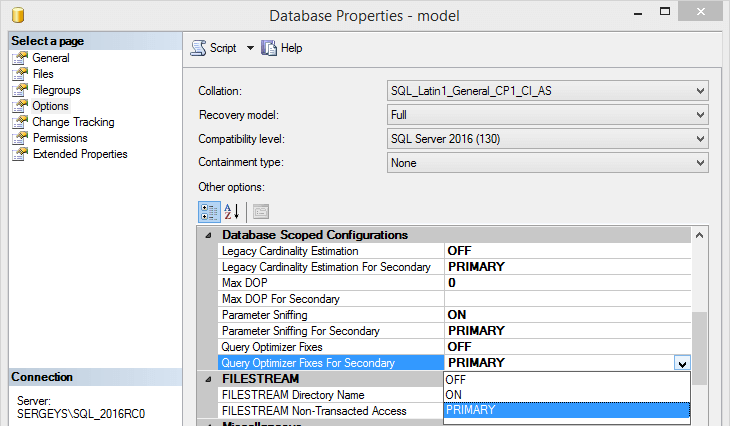
You can get them from the new sys.database_scoped_configurations system view. As for me, I’m delighted with the fact that the parallelism level can be modified not globally as it used to be, but for each database individually:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0
Alternatives for previous versions are:
• enabling of the old Cardinality Estimation (previously you had to enable TF9481 or downgrade the Compatibility Level to 2012)
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ON
• disabling of Parameter Sniffing (previously you had to enable TF4136 or hardcode OPTIMIZE FOR UNKNOWN)
ALTER DATABASE SCOPED CONFIGURATION SET PARAMETER_SNIFFING = OFF
Also, the option to enable TF4199 has been introduced. It includes the massive list of all kinds of optimizations.
ALTER DATABASE SCOPED CONFIGURATION SET QUERY_OPTIMIZER_HOTFIXES = ON
For those who like calling the DBCC FREEPROCCACHE command, the command for cleaning the procedure cache has been provided:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE
Alternative to the command is the following:
DECLARE @id INT = DB_ID() DBCC FLUSHPROCINDB(@id)
I think, that it will be useful to add a query allowing to track the volume of procedure cache with a breakdown into databases:
SELECT db = DB_NAME(t.[dbid]), plan_cache_kb = SUM(size_in_bytes / 1024) FROM sys.dm_exec_cached_plans p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) t WHERE t.[dbid] < 32767 GROUP BY t.[dbid] ORDER BY 2 DESC
Now, let’s consider new functions:
JSON_MODIFY
In RC0, the option to modify JSON with help of the JSON_MODIFY has been added:
DECLARE @js NVARCHAR(100) = '{
"id": 1,
"name": "JC",
"skills": ["T-SQL"]
}'
SET @js = JSON_MODIFY(@js, '$.name', 'Paul') -- update
SET @js = JSON_MODIFY(@js, '$.surname', 'Denton') -- insert
SET @js = JSON_MODIFY(@js, '$.id', NULL) -- delete
SET @js = JSON_MODIFY(@js, 'append $.skills', 'JSON') -- append
PRINT @js
{
"name": "Paul",
"skills": ["T-SQL","JSON"],
"surname":"Denton"
}
STRING_ESCAPE
Also, the STRING_ESCAPE function allowing to screen special characters in text has been added:
SELECT STRING_ESCAPE(N'JS/Denton "Deus Ex"', N'JSON')
------------------------ JS\/Denton \"Deus Ex\"
STRING_SPLIT
What a joy! Finally the STRING_SPLIT function has been delivered! It allows to get rid of previous perversions with XML and CTE:
SELECT * FROM STRING_SPLIT(N'1,2,3,,4', N',')
value --------- 1 2 3 4
But here is one sting: the function works only with a single-character delimiter:
SELECT * FROM STRING_SPLIT(N'1--2--3--4', N'--')
Msg 214, Level 16, State 11, Line 3
Procedure expects parameter ‘separator’ of type ‘nchar(1)/nvarchar(1)’.
In the context of productivity, let’s compare old split methods and new ones:
SET STATISTICS TIME ON
DECLARE @x VARCHAR(MAX) = 'x' + REPLICATE(CAST(',x' AS VARCHAR(MAX)), 500000)
;WITH cte AS
(
SELECT
s = 1,
e = COALESCE(NULLIF(CHARINDEX(',', @x, 1), 0), LEN(@x) + 1),
v = SUBSTRING(@x, 1, COALESCE(NULLIF(CHARINDEX(',', @x, 1), 0), LEN(@x) + 1) - 1)
UNION ALL
SELECT
s = CONVERT(INT, e) + 1,
e = COALESCE(NULLIF(CHARINDEX(',', @x, e + 1), 0), LEN(@x) + 1),
v = SUBSTRING(@x, e + 1, COALESCE(NULLIF(CHARINDEX(',', @x, e + 1), 0), LEN(@x) + 1)- e - 1)
FROM cte
WHERE e 0
OPTION (MAXRECURSION 0)
SELECT t.c.value('(./text())[1]', 'VARCHAR(100)')
FROM
(
SELECT x = CONVERT(XML, '' + REPLACE(@x, ',', '') + '').query('.')
) a
CROSS APPLY x.nodes('i') t(c)
SELECT *
FROM STRING_SPLIT(@x, N',')
The execution results are the following:
(CTE) SQL Server Execution Times: CPU time = 18719 ms, elapsed time = 19109 ms. (XML) SQL Server Execution Times: CPU time = 4672 ms, elapsed time = 4958 ms. (STRING_SPLIT) SQL Server Execution Times: CPU time = 2828 ms, elapsed time = 2941 ms.
Live Query Statistics
Another great thing is that new version of SSMS has the option to track query execution in a real-time mode:
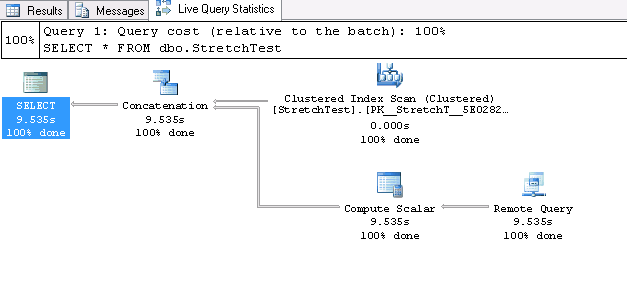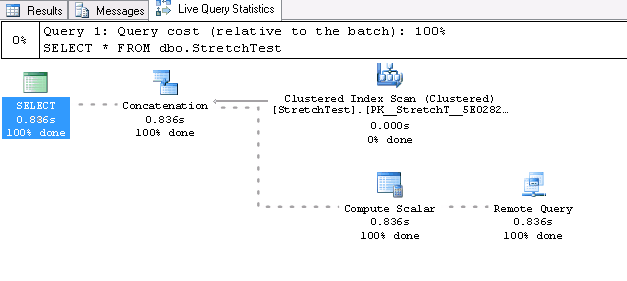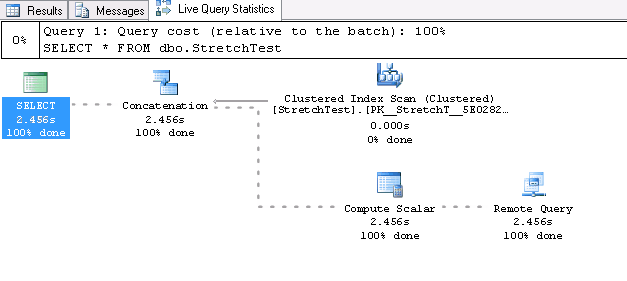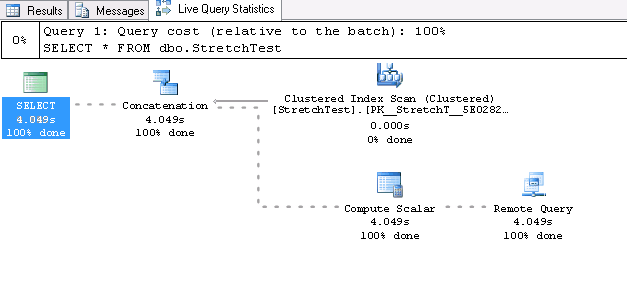
This functionality is supported by not only SQL Server 2016, but by SQL Server 2014 as well. On the metadata level, this functionality is implemented through the sys.dm_exec_query_profiles query:
SELECT
p.[sql_handle]
, s.[text]
, p.physical_operator_name
, p.row_count
, p.estimate_row_count
, percent_complete = 100 * p.row_count / p.estimate_row_count
FROM sys.dm_exec_query_profiles p
CROSS APPLY sys.dm_exec_sql_text(p.[sql_handle]) s
This goodie is quite cool. I know that Devart has already started to develop similar functionality in dbForge Studio.
To maintain readability of this overview, I withdrew some new features of SQL Server (Temporal Tables, Dynamic Data Masking and improvements in In-Memory), and intend to add them after the release of RTM version.
So, there we have it… Thank you for your attention.