
Are you a user of dbForge tools for SQL Server?
If you are, then we’ve got a great slice of news for you—our entire product line for SQL Server has just been updated, and you’re welcome to get your update right now.
If you are not, you may still want to take a look at all the goodies that come with this release. Our tools come with a hefty free trial, and we gladly invite you to give them a go.
Down with the intros, let’s get started!
Contents
- T-SQL Code Analyzer
- Connectivity
- DevOps & CLI Automation
- Code Completion
- Schema Compare
- Source Control
- Database Diagrams
- SQL Query History
- Documents
- Database Explorer
- Data Generator
- Script Generation
- Data Editor
- Pivot Tables
- Find Invalid Objects
- Search
- Index Manager
- Application Startup Time
T-SQL Code Analyzer
First and foremost, we’d love to tell you about T-SQL Code Analyzer, a comprehensive tool that helps developers and DBAs scrutinize and optimize T-SQL scripts, making sure they conform to precisely defined rules, guidelines, and best practices.
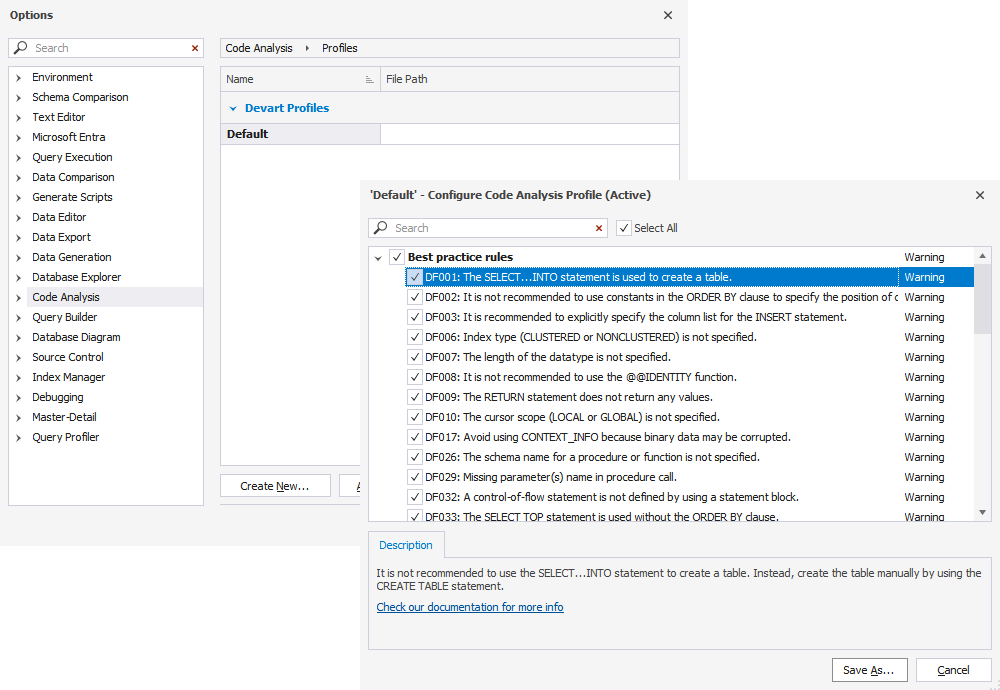
T-SQL Code Analyzer is available in dbForge Studio for SQL Server (updated) and dbForge SQL Complete (newly introduced). You should definitely check it out if you are seeking to improve your T-SQL coding practices and optimize database performance. With the help of the Analyzer, you will easily identify potential issues and performance bottlenecks in your T-SQL scripts; things like inefficient queries and missing indexes will no longer stand in your way.
Connectivity
As you might know, Azure Active Directory has been renamed to Microsoft Entra ID. Now this change is fully reflected in the interface of our tools, namely, in the Database Connection Properties dialog and in Options.
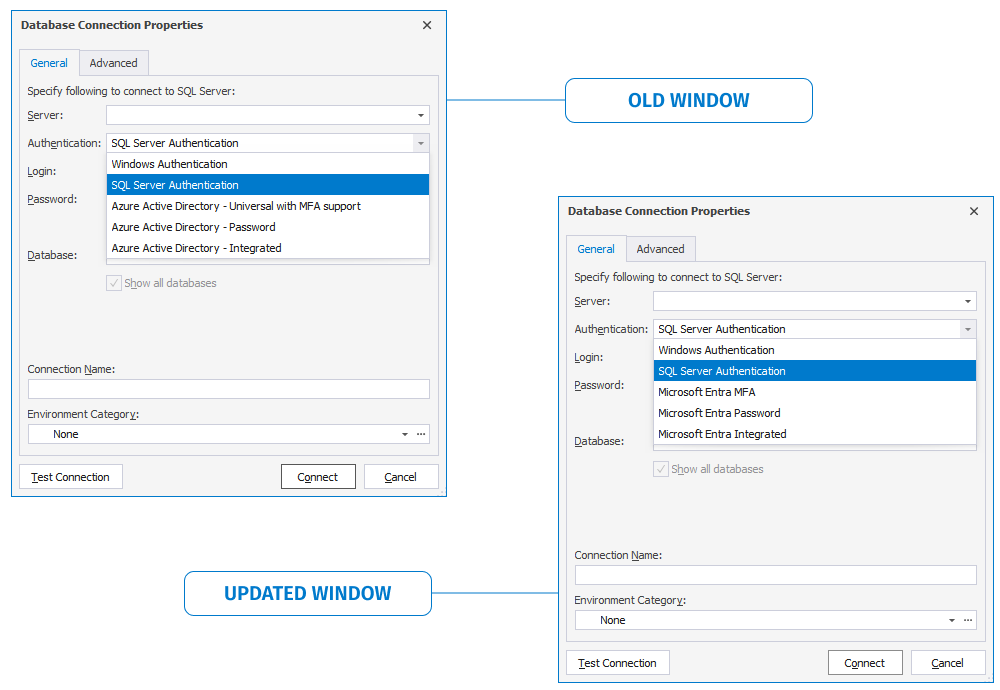
We’ve also expanded the compatibility of our products to include native support for ApsaraDB. Thus there will be no more workarounds or challenges with integrating dbForge tools into your work with databases hosted on Alibaba Cloud.
DevOps & CLI Automation
Next, we have good news for Atlassian Bamboo users. If you have migrated from Bamboo Server to Bamboo Data Center—or if you’re right in the midst of this process—you ought to know that dbForge DevOps Automation for SQL Server (available as part of the SQL Tools bundle) is now fully compatible with Data Center, and you can safely build your CI/CD around them.
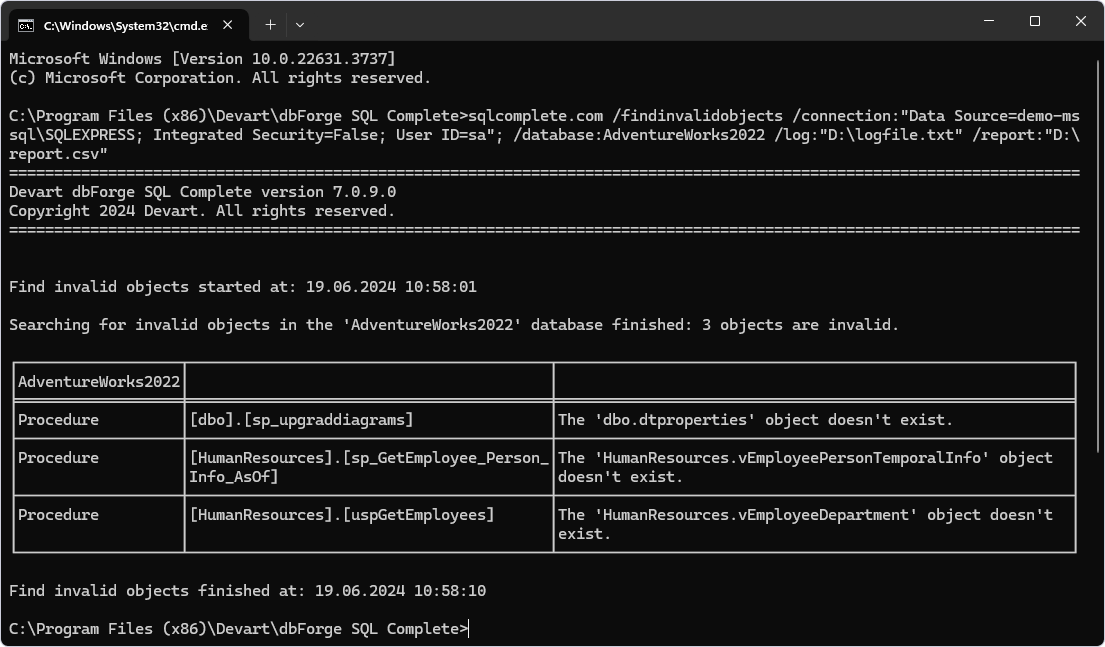
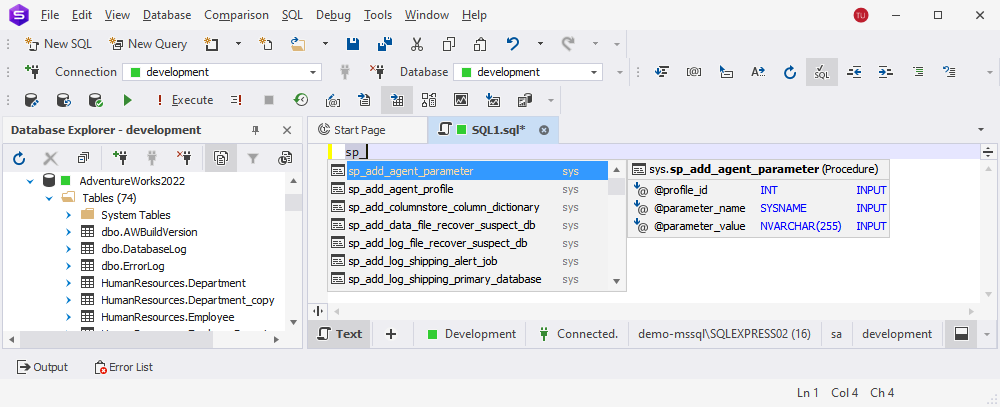
We’ve also got a few new automation features worth your attention. The first of these, available in dbForge SQL Complete, is Find Invalid Objects, which does exactly what it says on the tin; it’s a feature that helps identify and manage invalid database objects in the most efficient way. Now it’s been powered up with CLI automation to reduce manual intervention and thus help you get your job done even faster. Simply run the script against the required database and get the list of invalid objects that hinder its performance.
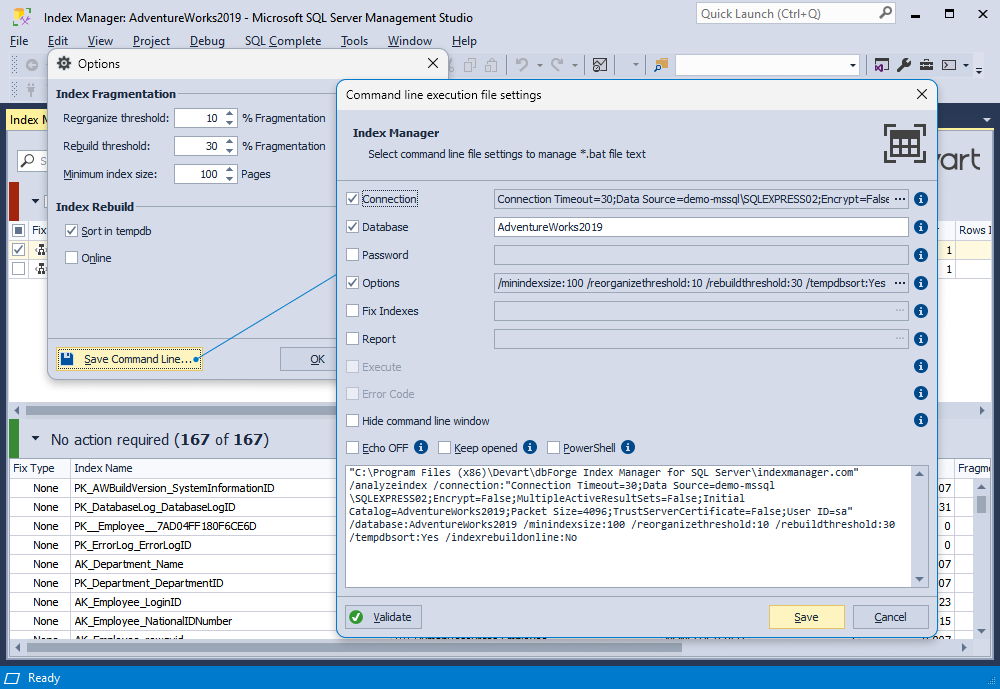
If you’re a user of dbForge Index Manager, you’ll be glad to know that we’ve reduced your routine index defragmentation to just a few clicks. Now you only need to configure it in Options just once, autogenerate a reusable script via Save Command Line, and simply run it from the command line whenever you need to take care of your indexes. Check the following screenshot to see how fast and easy it is.
Last but not least, now you can generate comparison reports from the command line in dbForge Data Compare, dbForge Schema Compare, and dbForge Studio. Similarly to the previous case, you can configure them, generate a comparison script, and run it whenever you want.
Code Completion
Our next stop is a set of handy code prompting enhancements. The first one comprises the newly supported suggestions of non-aggregated columns in GROUP BY statements. With their help, you can quickly add non-aggregated columns after the GROUP BY keyword via a dropdown list, skipping the routine of seeking them out and inserting them manually. Instead, you can either add all the suggested columns from the SELECT List with a single click or add them one by one in the preferred order—as fast and convenient as it can get.
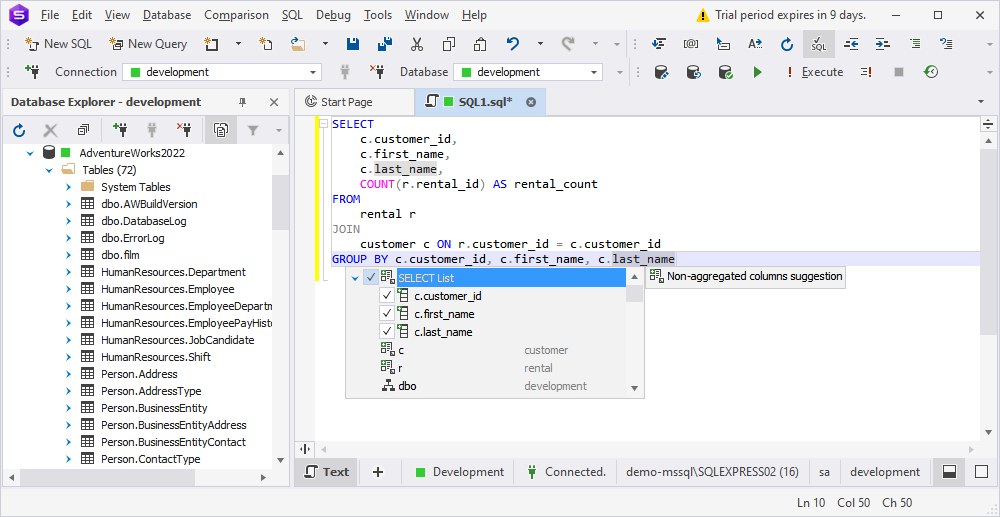
Next, you can view the MSDescription property for the database you’re working with.
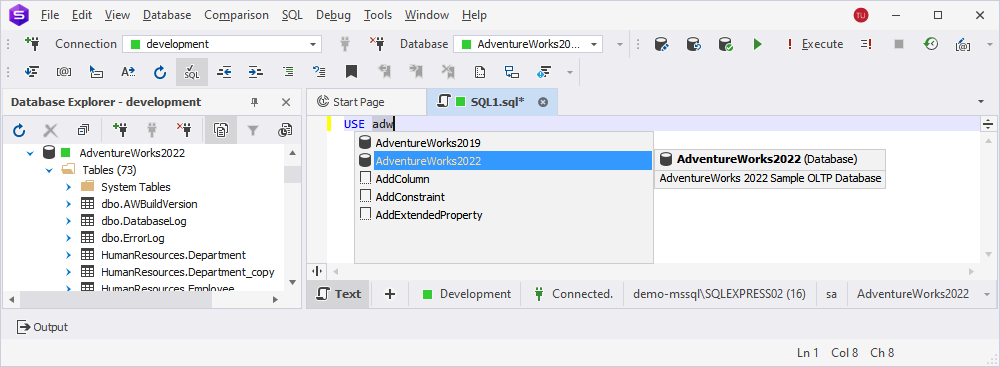
What if you are using graph databases? Then we’ve got a way to simplify your work by adding support for the entire variety of T-SQL graph functions:
- EDGE_ID_FROM_PARTS
- GRAPH_ID_FROM_EDGE_ID
- GRAPH_ID_FROM_NODE_ID
- NODE_ID_FROM_PARTS
- OBJECT_ID_FROM_EDGE_ID
- OBJECT_ID_FROM_NODE_ID
This is what it looks like.
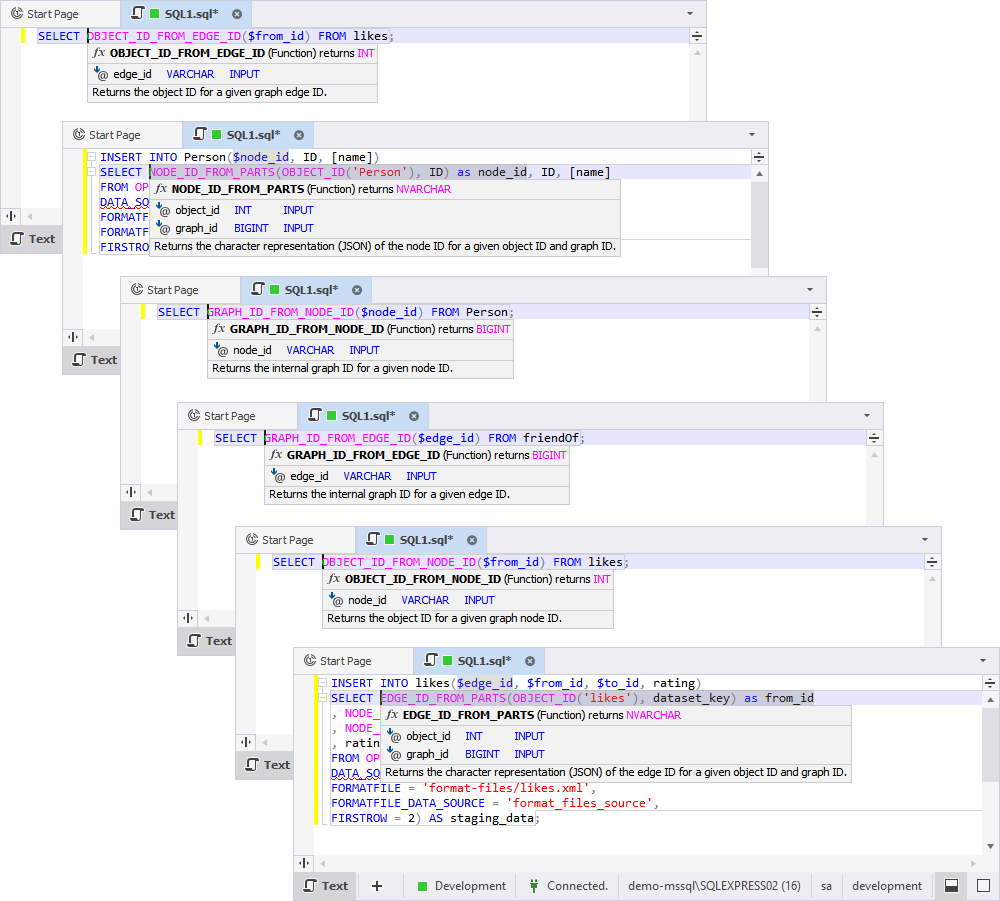
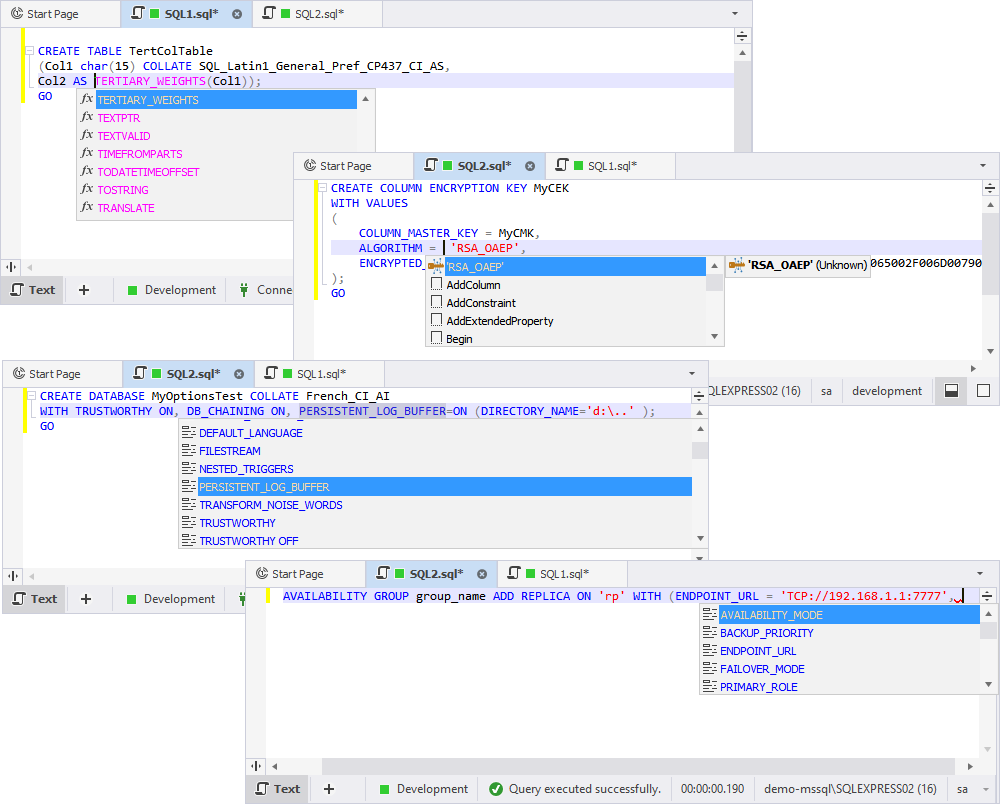
Next, we have added support for the COLUMN MASTER KEY server object.
There’s a handful of other newly supported stuff, including:
- The TERTIARY_WEIGHTS function
- The RSA_OAEP algorithm in CREATE COLUMN ENCRYPTION KEY statements
- The PERSISTENT_LOG_BUFFER construct in CREATE DATABASE statements
- The AVAILABILITY GROUP construct (extended support)
Finally, we have implemented suggestions for implicit procedure execution, ensuring the validity of all stored procedures that may not contain EXEC or EXECUTE.
Schema Compare
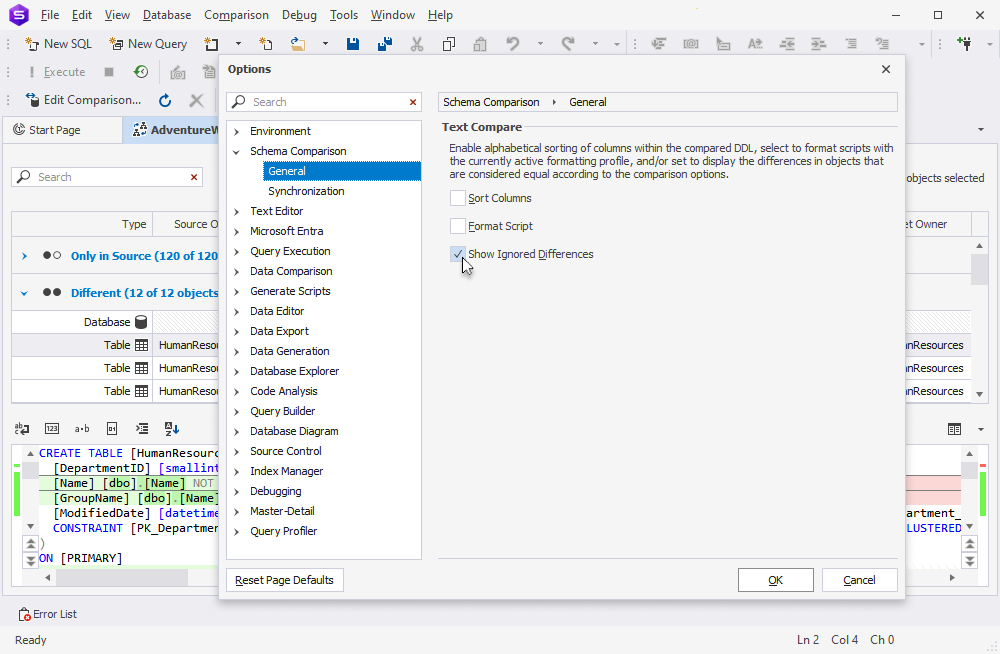
Now let’s proceed to the new features and enhancements awaiting you in Schema Compare. First, we’ve added an option called Show Ignored Differences, which can be enabled by selecting the corresponding checkbox in Options > Schema Comparison > General. Once you enable this option, the application will highlight possible differences in DDL.
When checking differences in a schema comparison document, you can now go to each subsequent difference with a handy shortcut ALT+↓.
Next, we have introduced support for the ADD SENSITIVITY CLASSIFICATION command, which allows you to efficiently tag columns based on data sensitivity levels and information types. That’s good news in terms of data security and compliance—and you no longer need to detect and classify sensitive data manually.
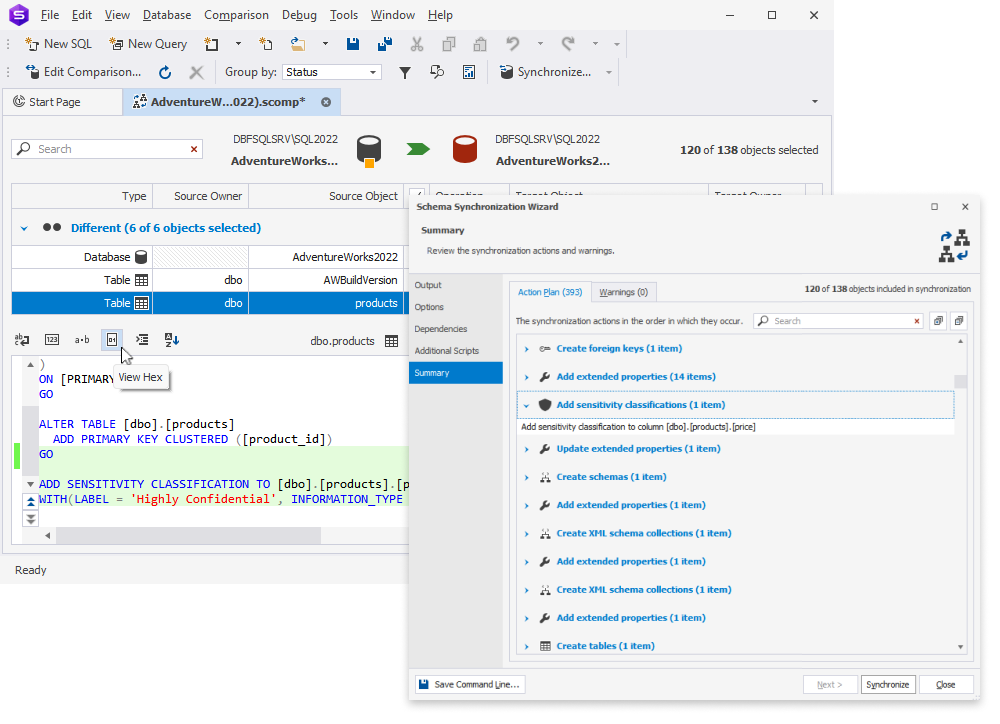
Both Schema and Data Synchronization Wizards now include a new page called Issues; on this page, you can configure the default behavior in case of potential NULL/NOT NULL conflicts that may occur during the synchronization.
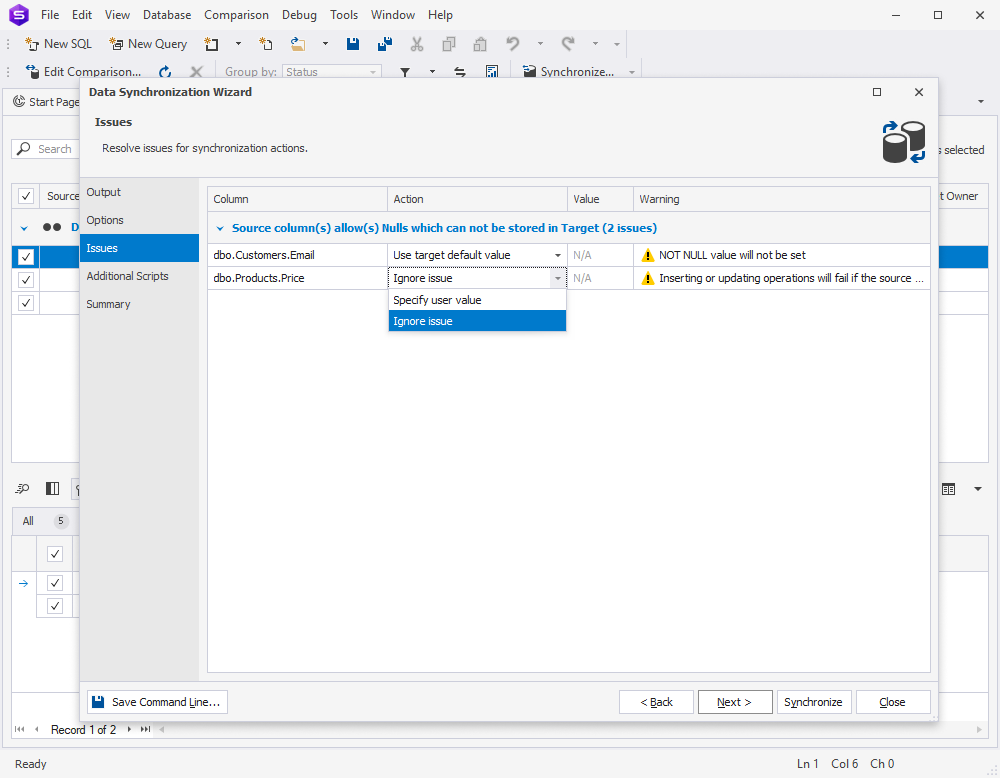
Other new features related to Schema Compare include:
- A new index option STATISTICS_INCREMENTAL
- A new group of options called Sequences, comprising Ignore START WITH in sequences and Ignore MIN VALUE in sequences
- New comparison options: Ignore MIN VALUE, Ignore START WITH, Ignore CYCLE, Ignore INCREMENT BY, and Ignore CACHE
Source Control
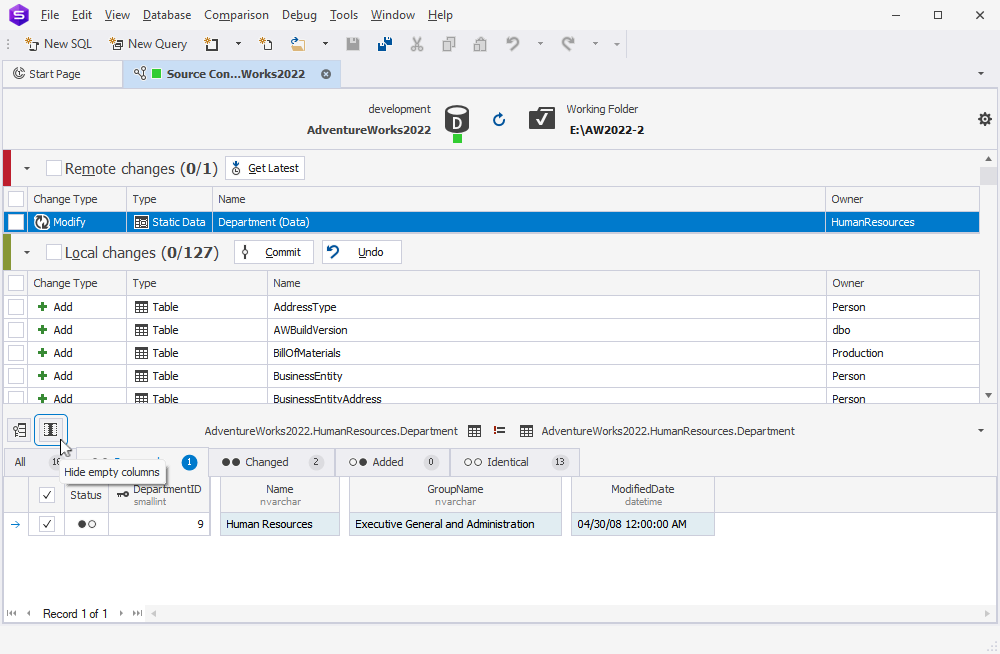
Let’s move on to a few useful enhancements we’ve prepared for you in Source Control. First, we have implemented support for XML and HASH indexes for Azure. Second, you can now freely use the PERSISTED construct for table variables. Third, you have a handy Hide empty columns button in the static data diff grid.
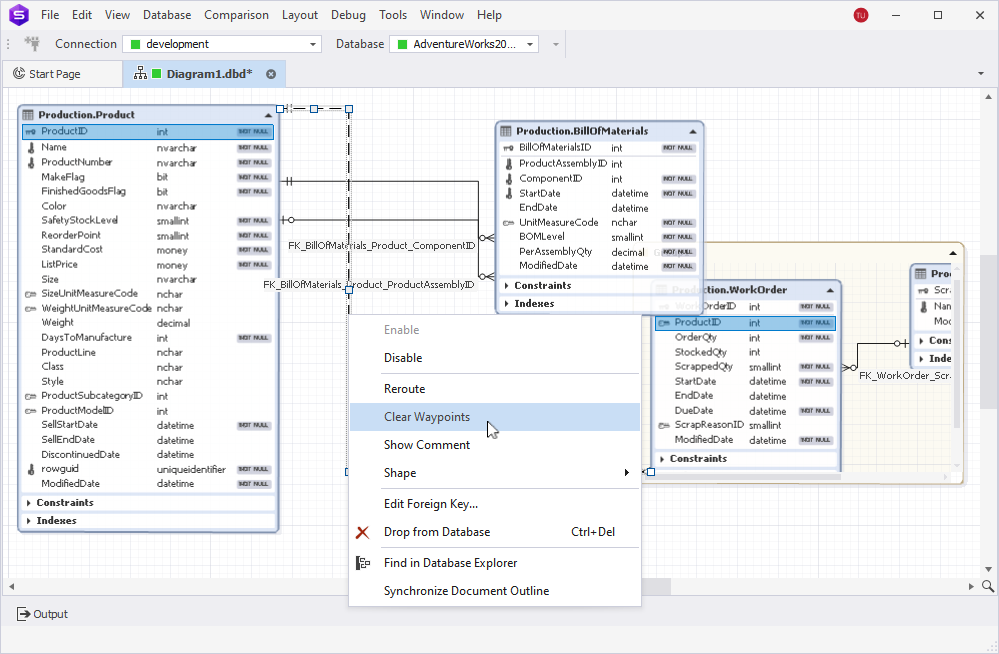
Database Diagrams
If you’re an avid user of database diagrams, you will be pleasantly surprised by their updated design, featuring new element skins, opacity controls, and linear zoom factor. Now your diagrams will be even more engaging visually and much easier to examine.
For your convenience, we have also added handy options like Select All Relations, which selects all relations on your diagram, and Clear Waypoints, which eliminates all waypoints that have been manually created for a selected relation.
SQL Query History
Now a few words about SQL Query History, where we’ve tweaked the interface a bit—namely, redesigned the toolbar with an updated date range selection and a handy new Clear button to help you free your storage by clearing the history.
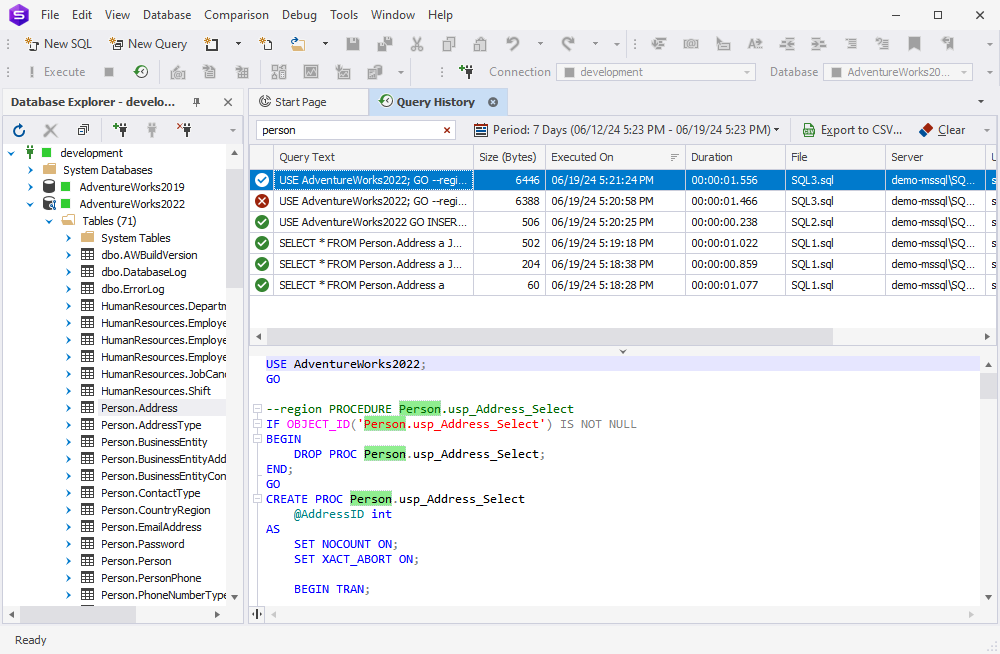
Additionally, following the requests of our users, a reopened Studio now keeps the user-defined layout of columns in SQL Query History.
Documents
Your work with documents in the Studio must be just as perfectly convenient as well. That’s why we have added some options to help you arrange your documents to your preferences.
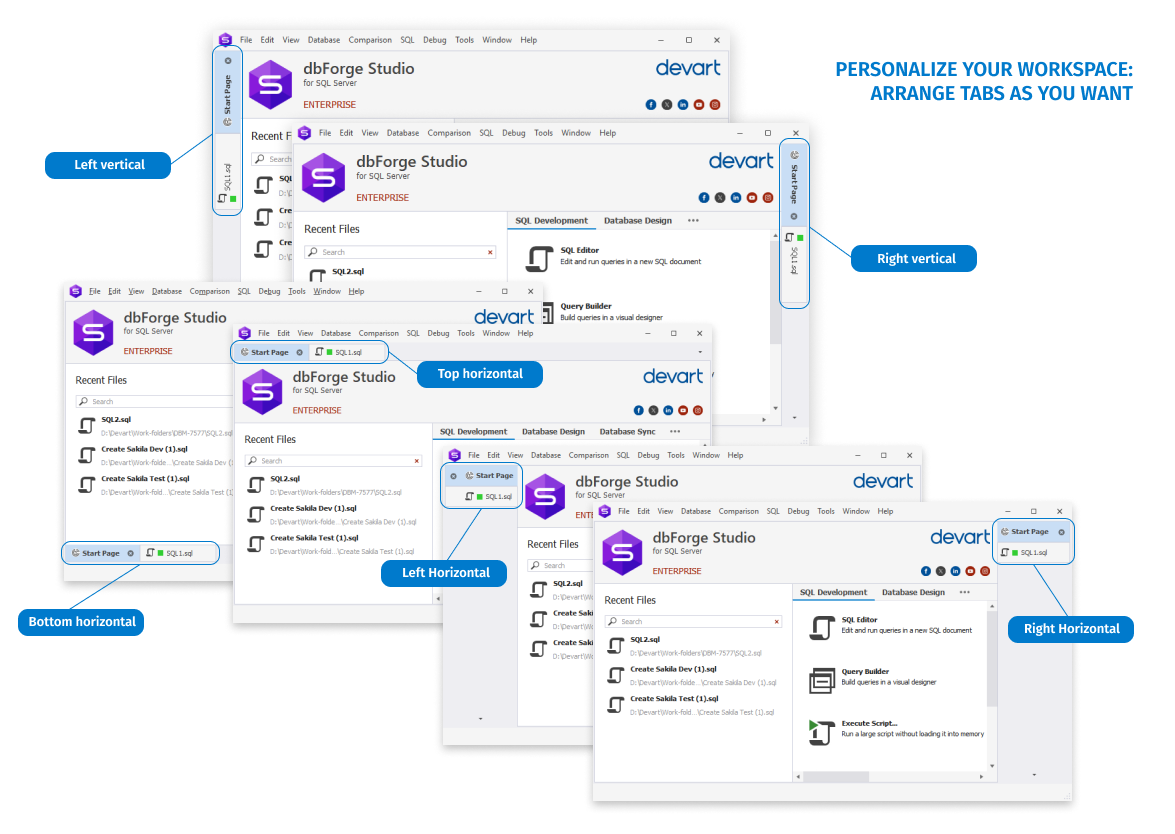
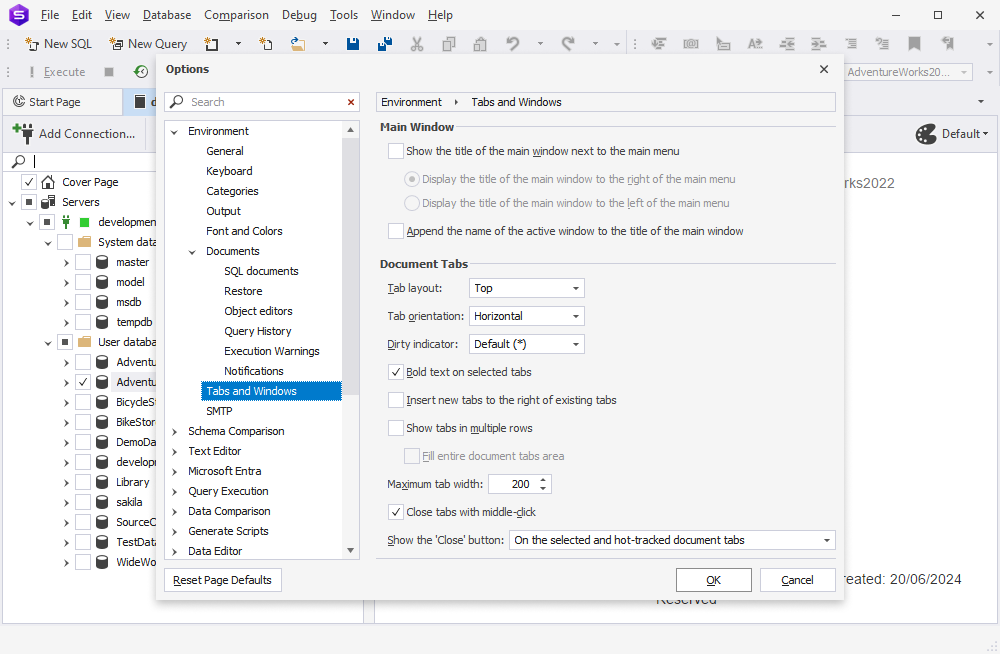
If you go to Options > Environment > Tabs and Windows, you will encounter a few new customization options, which include Tab layout, Show tabs in multiple rows, and Close tabs with middle-click.
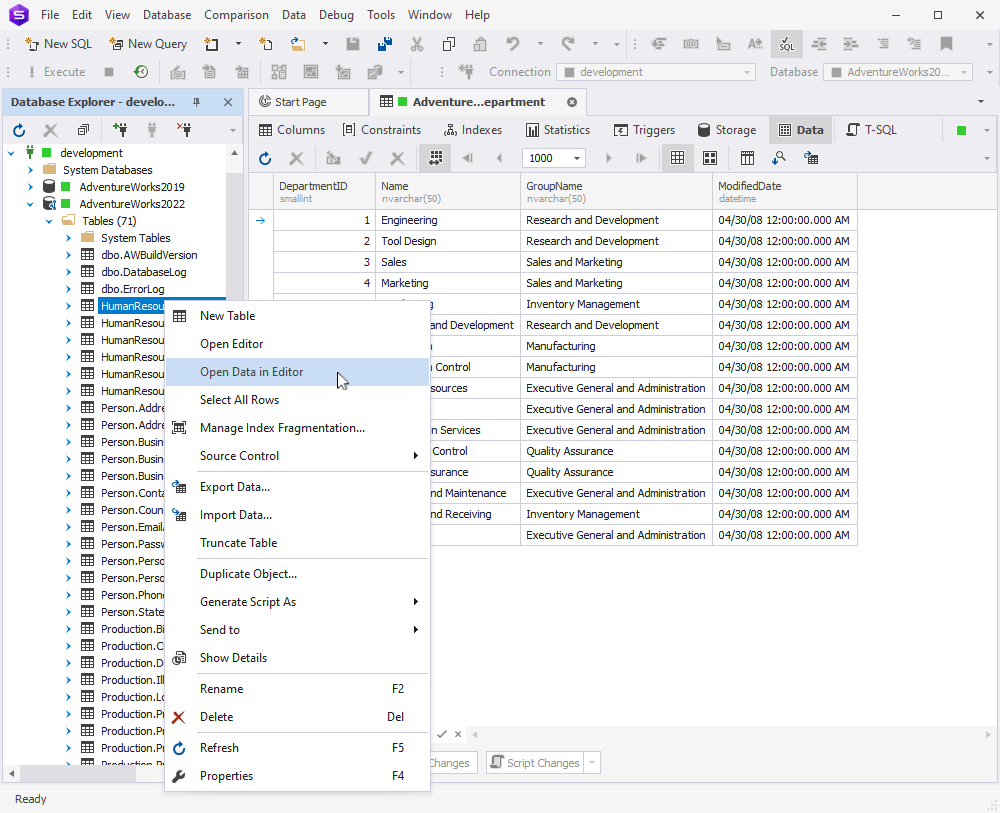
Next, if you right-click a table and select Open Data in Editor from the shortcut menu, the contents of the table will be opened in a document tab that will have the table name.
Finally, here’s a handy new shortcut CTRL+SHIFT+/ to help you instantly comment a selection of code within a line.
Database Explorer
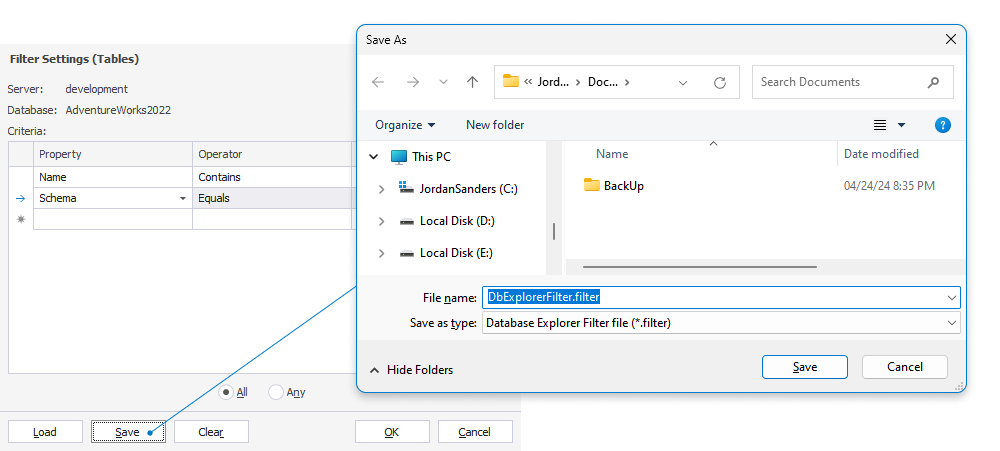
What do we have for you in Database Explorer? Well, first of all, we’ve implemented a solution to the situation when you have lots of nodes and tables in the Explorer, and you need to filter out the stuff you don’t need and keep only the stuff you’re working on. To do that, you could always configure filter settings. But now, things are even better—you can save these filter settings to a file and thus reuse them at any given moment by loading the said file.
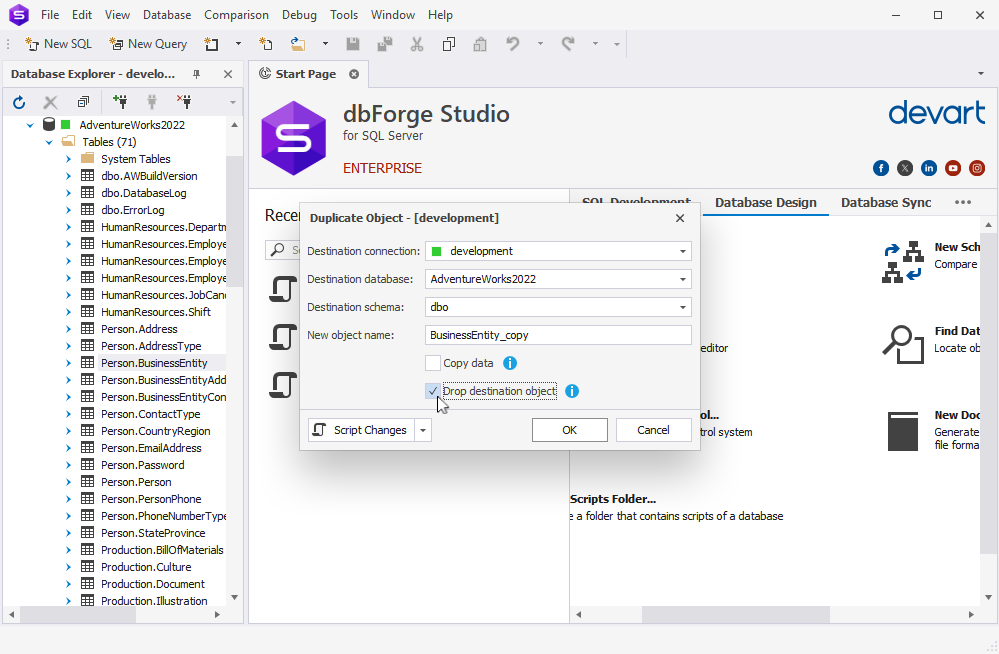
Also, when you duplicate a database object, you’ll see a new option called Drop destination object. When it is turned on, the duplication behavior is as follows: if there is an object with the same name in the target schema, it will be dropped before duplication.
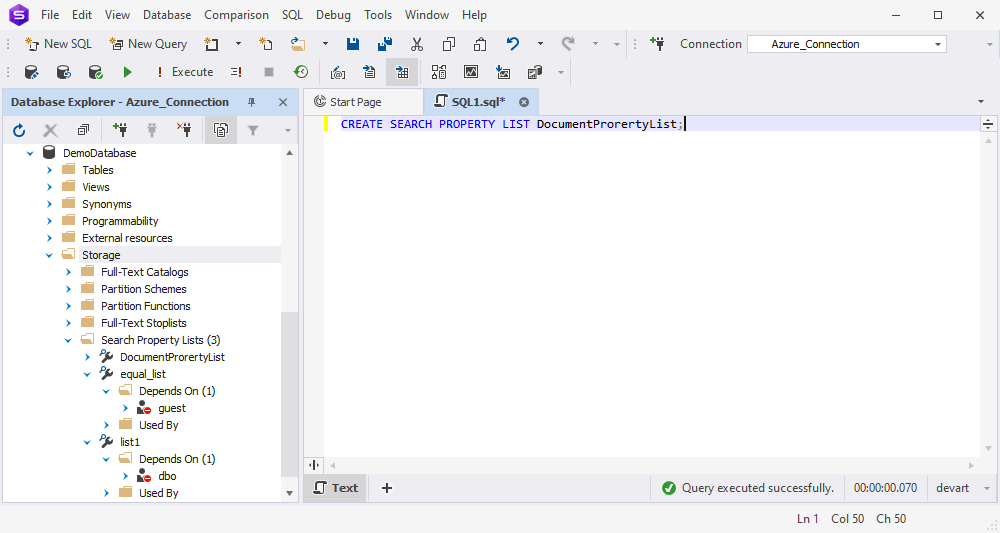
Next, since Search Property Lists are now fully supported by Azure SQL Database, you’ve got them in Database Explorer.
Data Generator
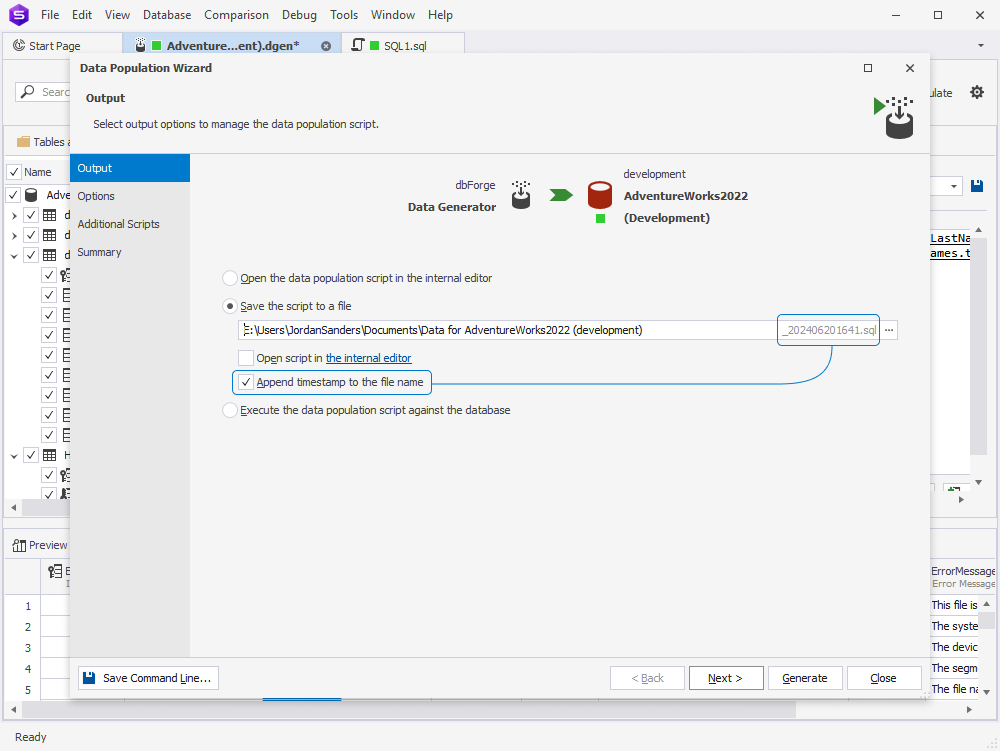
Let’s see what’s new in Data Generator. First off, in Data Population Wizard, you’ve got a new option that appends a timestamp to the name of the file that you save your data population script to.
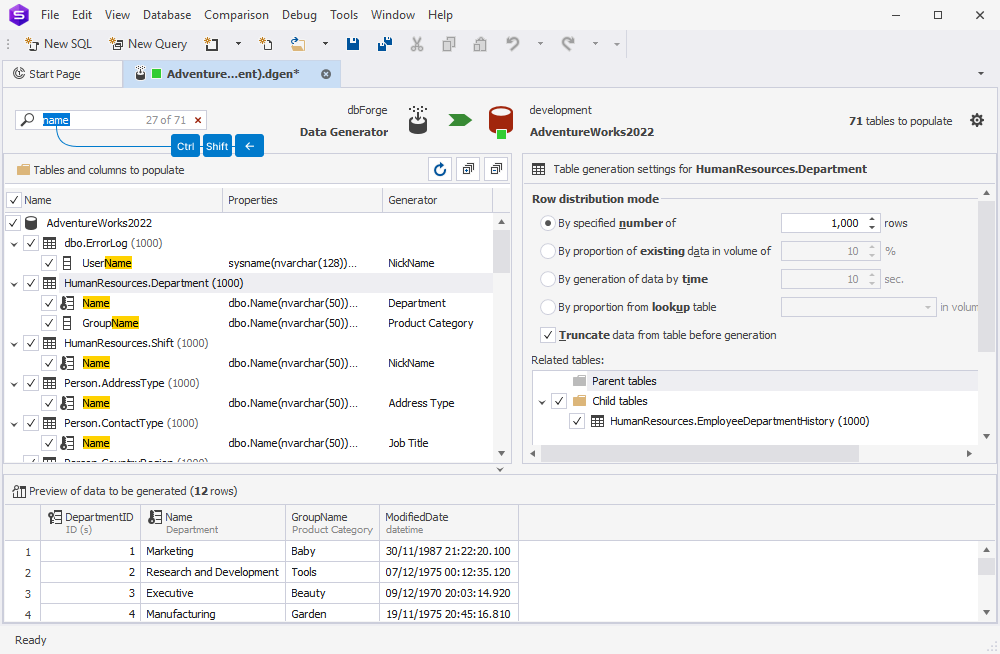
Second, when you look for the required tables and columns via the search box, you can use the following shortcuts:
- CTRL+A – select all text in the search box
- CTRL+← – go to the previous word
- CTRL+→ – go to the next word
- CTRL+SHIFT+← – select the previous word
- CTRL+SHIFT+→ – select the next word
- CTRL+BACKSPACE – delete the previous word
Script Generation
Now, a bit more on script generation. First off, the Studio automatically wraps CRUD templates into named regions.
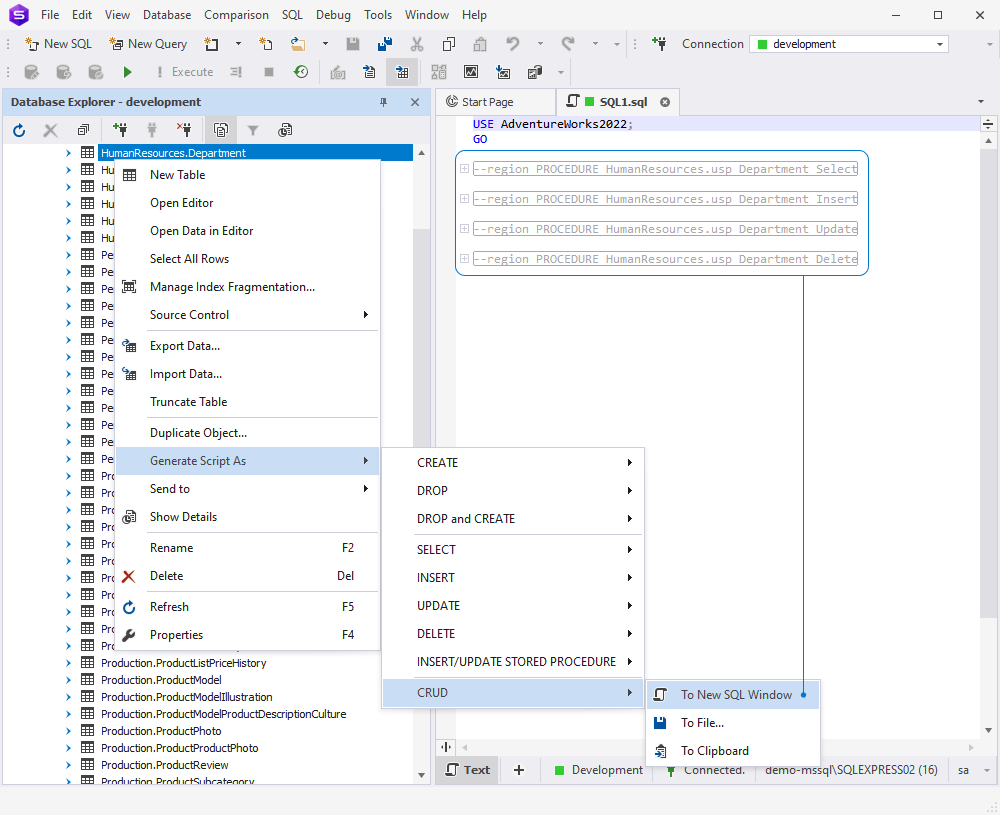
Next, you’ve got a new option to include DML triggers in your scripts via Options > Generate Scripts > General.
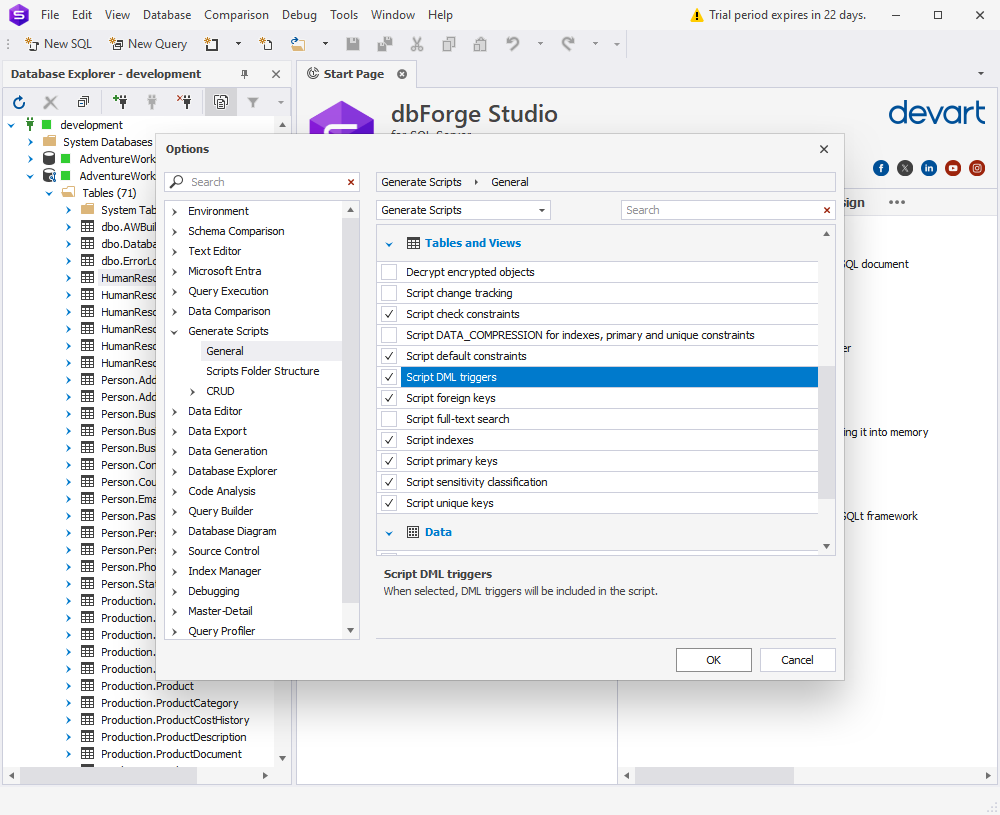
Similarly, you can select a checkbox on the same list to include security permissions.
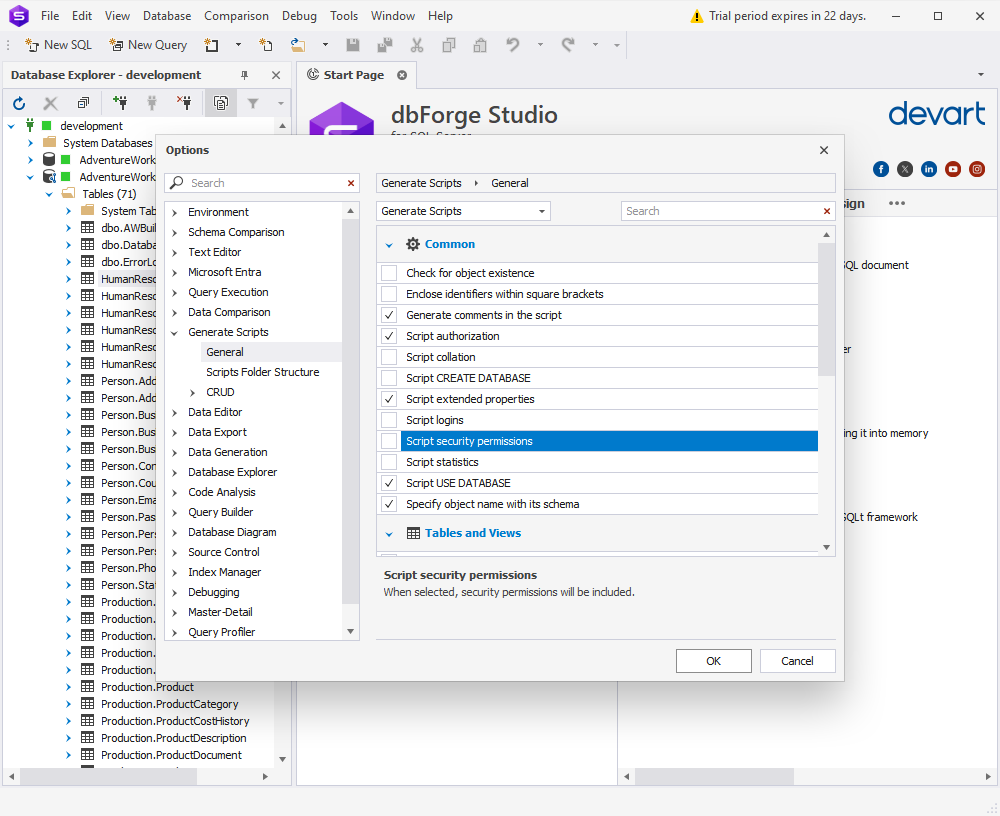
Finally, we’ve added a third option to include authorization in your scripts.
Data Editor
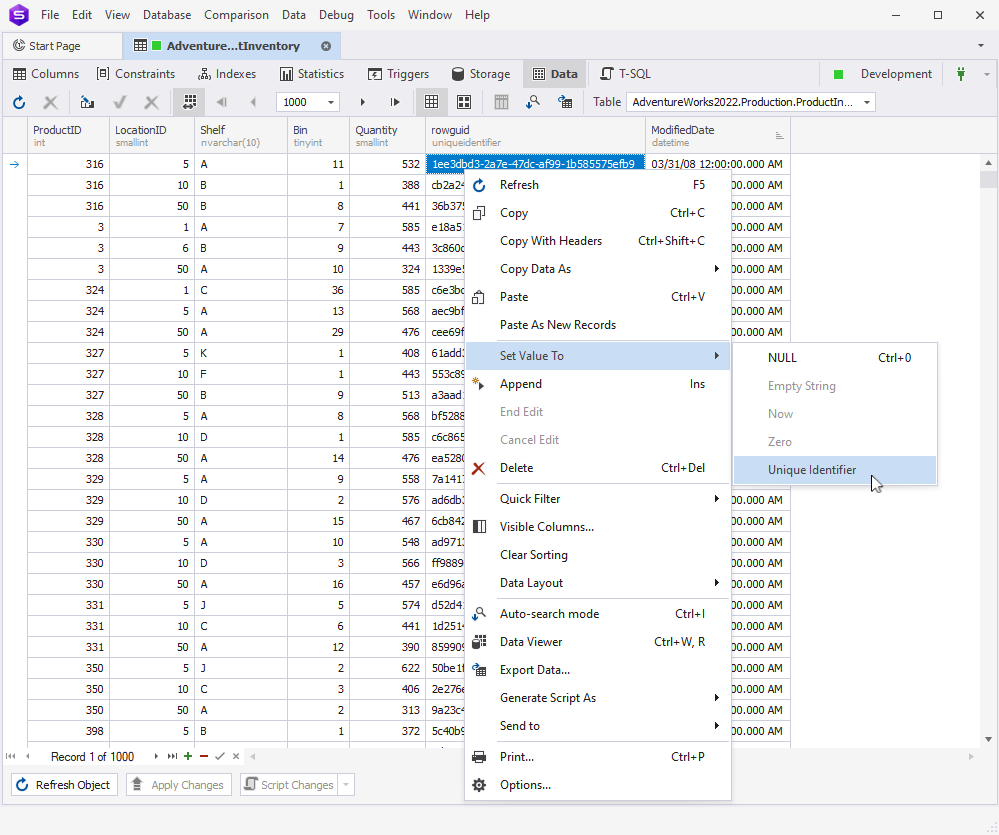
In Data Editor, you’ve got a new option to quickly set a cell value to a unique identifier from the shortcut menu.
Pivot Tables
Following the requests of our users, we’ve upgraded our Chart Designer to a newer, more advanced version with an improved appearance.
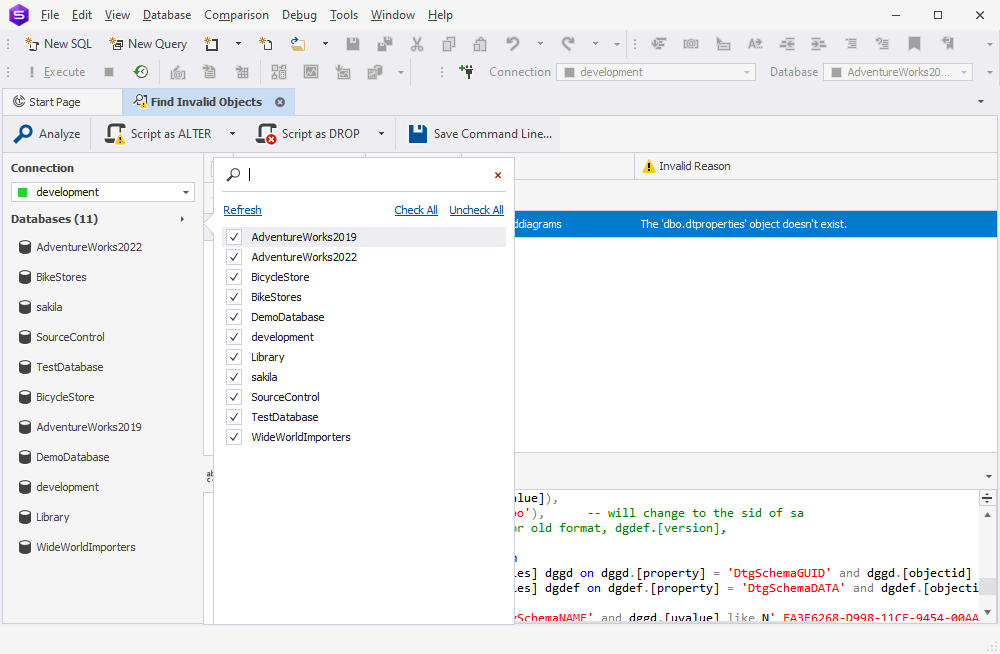
Find Invalid Objects
When browsing databases in Find Invalid Objects, you can quickly Check All/Uncheck All databases on the list with the corresponding new buttons.
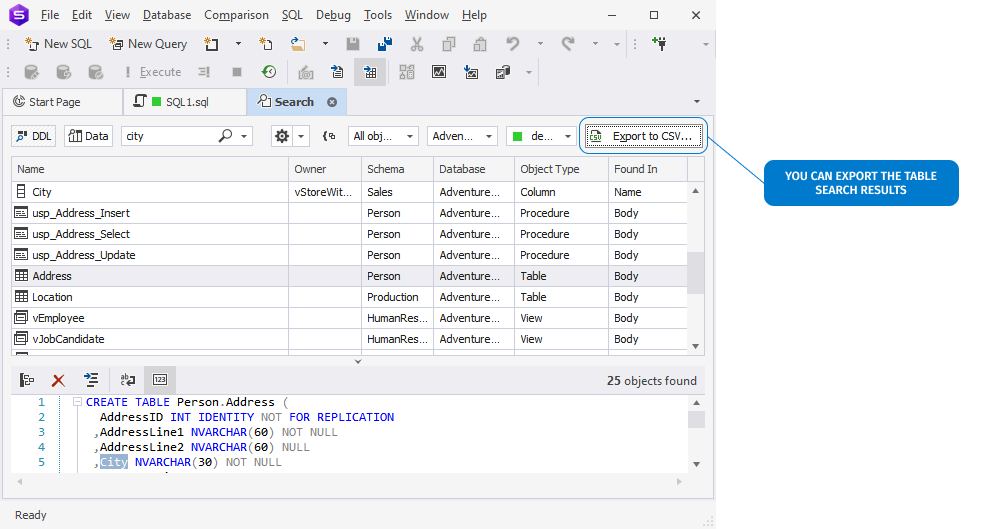
Search
In Search, we have added a button to export your search results to CSV.
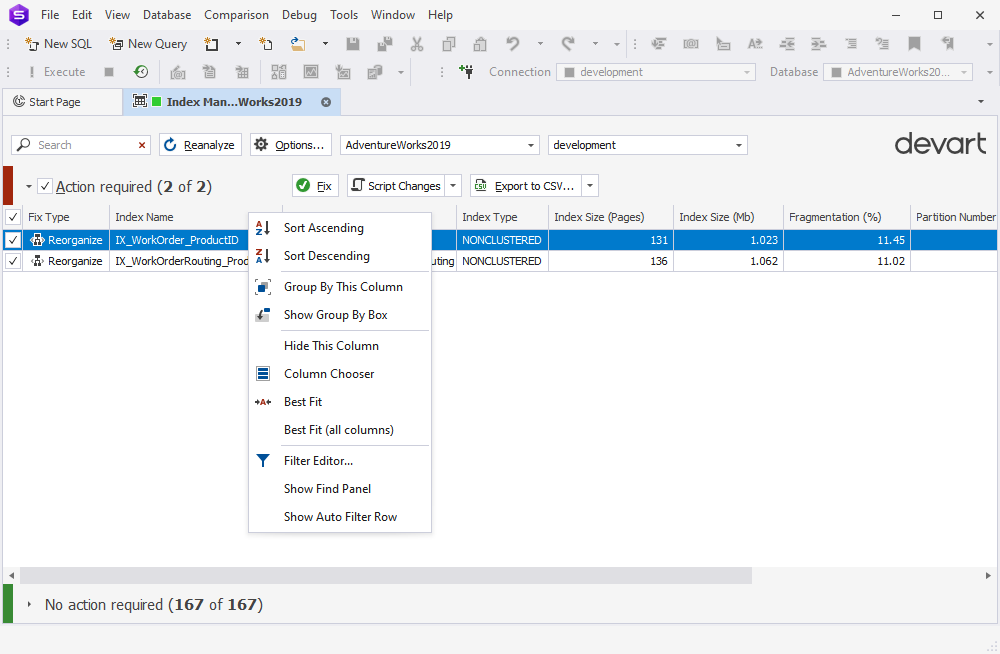
Index Manager
In Index Manager, we have implemented our standard shortcut menu that will help you quickly arrange, sort, group, and filter entries in the grid.
Application Startup Time
The final new feature for today is that now, besides the startup timestamp, you can check the actual time it took the Studio to start.
Get the updated dbForge Studio for SQL Server, dbForge SQL Tools, and dbForge Edge today!
Although this post mostly focuses on dbForge Studio for SQL Server as our flagship all-in-one IDE, some of the described new features and enhancements duly appear in the corresponding apps and SSMS add-ins from our dbForge SQL Tools bundle. So if you’re looking to augment SSMS without switching to any alternative products, the updated SQL Tools might be just what you need, with a nice 30-day trial to get some firsthand experience with their power. And if you’re already using SQL Tools, the update is already waiting for you. We’ll be glad to hear your feedback and new feature suggestions.
One last thing we’d like to mention today is that you can get the updated dbForge Studio for SQL Server as part of dbForge Edge, our multidatabase bundle that covers SQL Server, MySQL, MariaDB, Oracle, PostgreSQL, and a slew of other databases and cloud services with four definitive Studios that will make your daily database management easy and comfortable. Don’t take our word for it—get dbForge Edge for a free 30-day trial and see for yourself.