
SQL Server’s filtered index is one of the most effective features for improving query performance and reducing index maintenance. Whether you’re working with big tables that don’t have much data or queries that constantly filter by the same conditions, filtered indexes offer a smart way to focus only on the rows that matter most.
This tutorial explains what filtered indexes in SQL Server are, when to use them, how to create them, and how tools like dbForge Studio for SQL Server make the whole process easier and more effective without needing in-depth knowledge of Transact-SQL (T-SQL). It is designed for developers and database administrators (DBAs) with intermediate to expert knowledge of SQL.
- What is a filtered index in SQL Server?
- When should you use a filtered index?
- How to create a filtered index
- Benefits of using filtered indexes
- Why dbForge Studio for SQL Server is the best tool for index management
- Filtered indexes vs. Standard indexes in SQL Server
- Conclusion
What is a filtered index in SQL Server?
A filtered index in SQL Server is a non-clustered index containing only the rows that meet a specific condition defined by aWHEREclause. TheWHEREclause—also known as a predicate—is the condition that defines which rows the index will include.
While a filtered index focuses only on the relevant rows, a traditional (non-filtered) or standard index covers all rows in the table, regardless of the user’s status.
When should you use a filtered index?
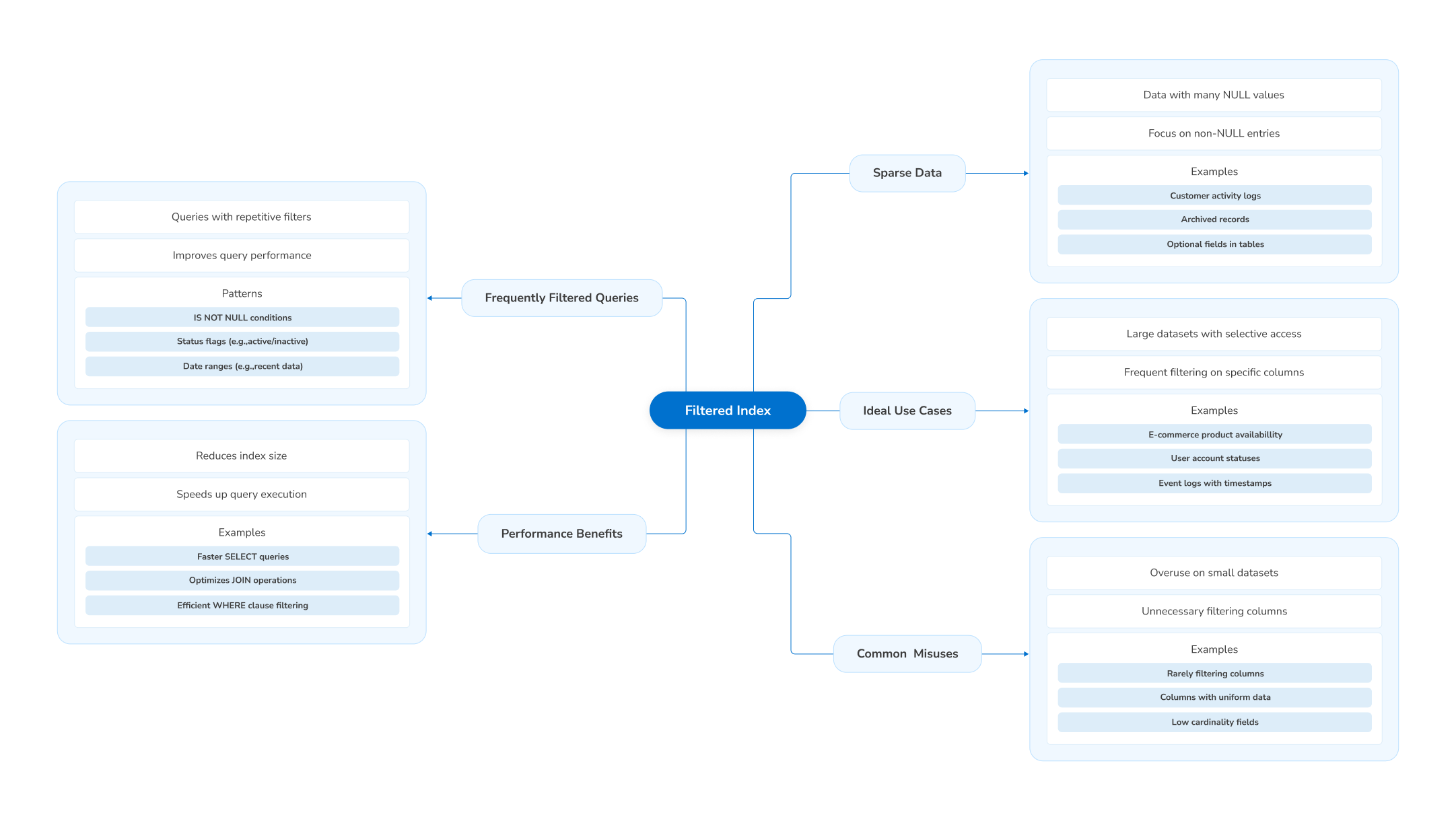
An SQL filtered index is particularly useful for optimizing queries that consistently access a specific subset of data. Here are some of the most common and ideal scenarios for choosing a filtered index:
Sparse data (manyNULLs)
If some of the columns of your table contain manyNULLvalues, you can use an SQL Server filtered index to focus only on the rows with valuable data. For example, you have aLastLoginDatecolumn that’sNULLfor most users. Instead of indexing the entire column, you can index only the rows where LastLoginDate IS NOT NULL.Doing this improves the performance of queries that fetch users who have logged in and skip the irrelevant rows.
Frequently filtered queries
You can also use the SQL Server filtered index to index only the matching rows of regular queries filtered by a specific condition, such as user status, order state, or a logical flag. For example, a sales dashboard that regularly filters orders whereStatus = 'Completed.'Instead of scanning the entire index of all orders, use the SQL Server filtered index to focus on completed orders.
Boolean or status flags
Filtered indexes are also helpful for columns that contain binary flags (likeIsActive,IsDeleted, andIsVerified) or enumerated status values (Status = 'Pending','Approved', etc.). For example, a user management system that frequently queries users whereIsActive = 1. Instead of indexing all users, you can use a filtered index to target only active users.
Partial data workloads
If a particular segment of your data is queried more frequently than the rest, you can use a filtered index in SQL Server for that segment. For example, you have an application that deals with customers from different regions. You can use a filtered index to focus on customers from a high-value region with excellent credit scores.
How to create a filtered index
To create an SQL Server filtered index, you only need to know how to define the syntax for the index and the predicates that match it.
Note
Only SQL Server 2008 and later support filtered indexes.
Syntax overview
The syntax for creating a filtered index is like that of a traditional or non-clustered index in T-SQL. The difference is theWHEREclause added to the syntax to set the condition or predicate for the filtered index. Here is how the syntax for the SQL Server filtered index is defined:
CREATE NONCLUSTERED INDEX index_name
ON table_name (column1 [, column2, ...])
WHERE <predicate>; To complete this:
- Replace index_name with the name of the index, which must be unique within the table.
- Replace table_name with the name of the table on which the index is created.
- Replace column1, column2, … with the column(s) the index covers.
- Replace <predicate> with the filter condition that determines which rows to include in the index.
Note
Filtered indexes can only be created on non-clustered indexes. Non-clustered indexes are those with a separate structure from the actual data rows in a table.
Using the syntax above, here are some examples of SQL Server filtered indexes.
Simple example
This example explains how to create a filtered index for rows with non-null values.
Let’s assume you have a Users table where you collect user login data, and you frequently run queries to check the users who have logged in. Most times, only a few users have done so, while the LastLoginDatecolumn isNULL for others.
Instead of constantly running queries to find the users who have logged in, you can create a filtered index for the rows with non-null values. Here is the syntax to do this:
CREATE NONCLUSTERED INDEX idx_UsersWithLogin
ON Users (LastLoginDate)
WHERE LastLoginDate IS NOT NULL; Queries like this will benefit from this index:
SELECT UserID, UserName
FROM Users
WHERE LastLoginDate IS NOT NULL; In the above query, the SQL Server will scan theWHEREclause and see that it matches the predicate defined in the filtered index (LastLoginDate IS NOT NULL). Rather than scanning the entire table during execution, the server will focus on the matching rows based on the condition specified.
Complex predicate example
This example shows how to use multiple predicates in a filtered index using the AND operator in the syntax.
Let’s assume you frequently query active customers from a specific region in your database, e.g., users withStatus = 'Active'andRegion = 'West.'
To create a filtered query for this functionality, you can use the following syntax:
CREATE NONCLUSTERED INDEX idx_ActiveUsersWest
ON Users (UserName, Email)
WHERE Status = 'Active' AND Region = 'West'; This index filters for a particular subset of data, including active users in the West region. It contains only the rows that match both conditions.
You can use this filtered index for queries like
SELECT UserName, Email
FROM Users
WHERE Status = 'Active' AND Region = 'West'; Benefits of using filtered indexes
Using SQL Server filtered indexes allows you to enjoy the following:
Faster query performance
Since an SQL filtered index only includes a subset of rows that meet a specific condition (predicate), SQL Server scans much less data when executing a query.
For instance, using the simple example from the earlier section, only a few users ever logged in, and theLastLoginDatecolumn for most users isNULL.To see the users who are logged in, you’ll often run a traditional index query like the following:
SELECT UserName, LastLoginDate
FROM Users
WHERE LastLoginDate IS NOT NULL; For this query, the SQL Server would have to scan the entire table to find only the rows whereLastLoginDateis notNULL.
However, if you create a filtered index like this one:
CREATE NONCLUSTERED INDEX idx_LoggedInUsers
ON Users (LastLoginDate)
WHERE LastLoginDate IS NOT NULL; The SQL Server scans only the rows whereLastLoginDate IS NOT NULL. Instead of scanning the entire table like the above traditional index, SQL Server can use this smaller, focused index to find the matching rows, thereby speeding up query execution.
Lower storage requirements
SQL Server filtered indexes are space-efficient because they only keep index entries for the rows that match the specified predicate. This feature makes them much smaller than traditional indexes, which index every row in a column. As a result, disk usage for filtered indexes is lower, and memory and cache work better than traditional indexes, requiring more space.
Low maintenance overhead
Since filtered indexes in SQL Server use a smaller portion of data, the server only updates the index when the indexed subset of rows changes, not every time a row in the table is inserted, updated, or deleted. For example:
If you have a filtered index like
CREATE NONCLUSTERED INDEX idx_ActiveOrders
ON Orders (OrderDate)
WHERE Status = 'Active'; - Only rows where
Status = 'Active'are included. - If an order is inserted with
Status = 'Pending,’ the index is unaffected. - If an
Activeorder is updated toCompleted, SQL Server removes only that row from the index. - This results in fewer writes to the index during data changes and low maintenance costs.
Why dbForge Studio for SQL Server is the best tool for index management
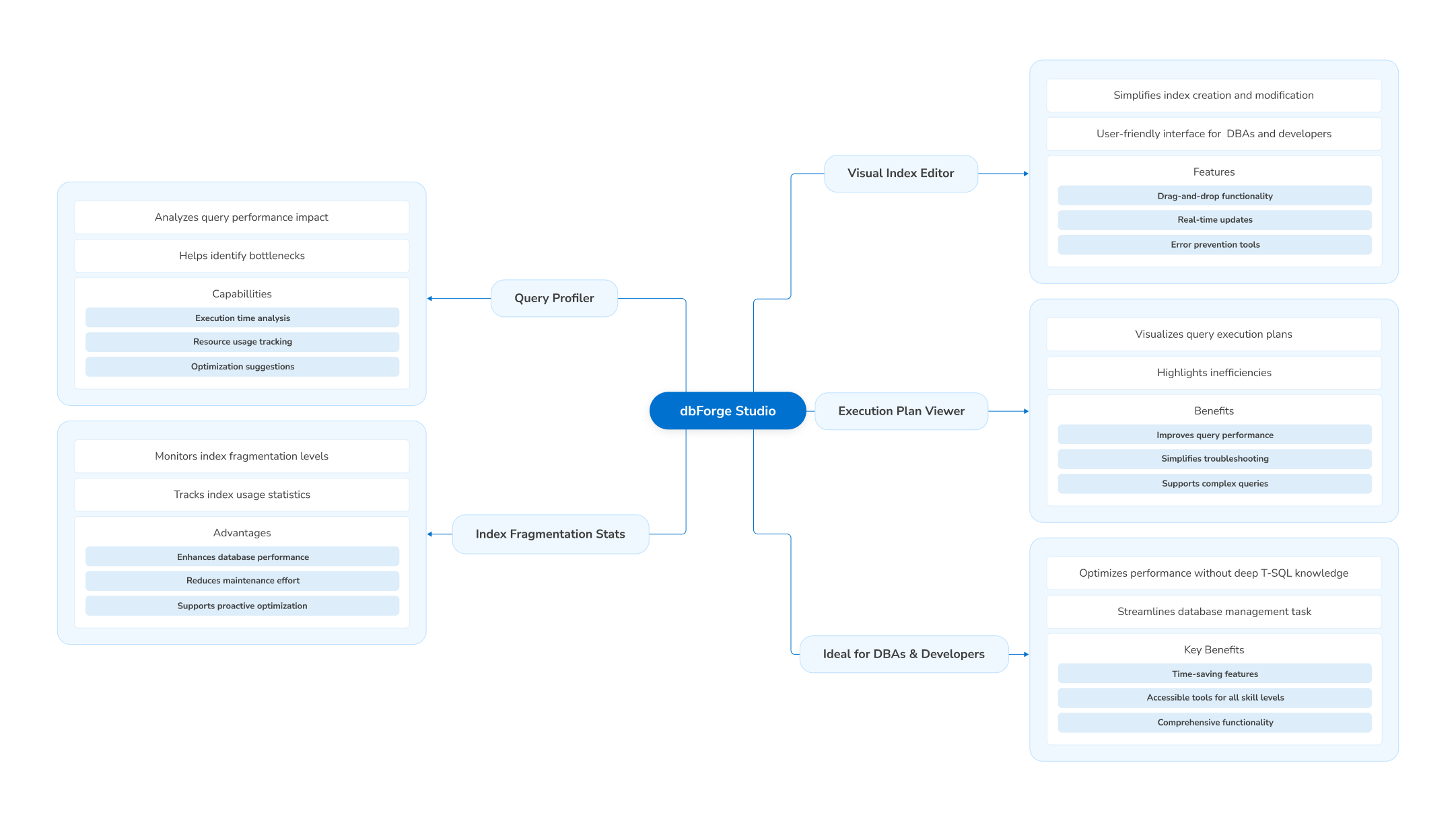
So far, you have learned that using SQL Server filtered indexes is one of the best ways to speed up queries and improve index maintenance. However, managing filtered indexes manually with T-SQL can be time-consuming, complex, and error-prone. This is where dbForge Studio for SQL Server steps in as a robust SQL Server IDE and intuitive solution. Whether you’re a DBA, developer, or analyst, dbForge Studio makes index management easier, faster, and more accurate, without needing to write or debug complex T-SQL.
Let’s explore some features that make dbForge Studio a go-to.
Visual index editor
dbForge Studio’s visual index editor removes the struggle of memorizing index syntax or double-checking for errors. The easy-to-use interface lets you do the following easily:
- Create, modify, or drop indexes.
- Choose the index type (clustered, non-clustered, or filtered), columns, and the columns to use in the filtered index.
- Apply filtered conditions using an editor.
- Instantly preview the generated T-SQL before execution.
Query profiler to analyze performance impact
Before adding or modifying an index, it’s important to know how the changes will affect query performance. The built-in query profiler in dbForge Studio allows you to perform the following:
- Analyze execution statistics for your queries (reads, writes, duration, CPU time).
- Compare before-and-after results when adding or modifying indexes.
- Identify bottlenecks that can be fixed through index optimization.
Execution plan viewer
In SQL Server, understanding execution plans for advanced performance tuning is crucial, but reading them in SQL Server Management Studio can be daunting. dbForge Studio simplifies this with a powerful execution plan viewer that performs the following:
- Displays graphical execution plans for any query
- Highlights expensive operations like table scans and lookups
- Allows you to assess if the optimizer is truly using your filtered index
Index fragmentation and usage statistics
Indexes can degrade over time due to fragmentation and changing data patterns. dbForge Studio helps you stay ahead by providing you with the following:
- A complete overview of index fragmentation levels across databases and tables.
- Usage statistics that show how often each index is used, helping you decide what to keep, rebuild, or remove.
- One-click options to rebuild or reorganize indexes based on fragmentation limits.
Ideal for DBAs and developers
Whether you’re managing a production system or developing a new application, dbForge Studio provides the tools to:
- Speed up index creation without deep knowledge of T-SQL.
- Find performance issues tied to indexing strategies quickly.
- Ensure filtered indexes are maintained, monitored, and optimized over time.
With its visual tools, performance analysis, and intelligent insights, dbForge Studio for SQL Server is essential for maintaining SQL Server database performance. It is perfect both for filtered indexes and standard or traditional indexes.
Filtered indexes vs. Standard indexes in SQL Server
Here’s a side-by-side comparison between filtered and standard indexes to help you understand their functionality and which is best for your scenario.
| Feature/Aspect | Filtered Index | Standard Index |
|---|---|---|
| Scope | Applies only to rows matching a filter condition | Applies to all rows in the indexed table |
| Index Size | Smaller | Larger |
| Performance Impact | Faster for targeted queries | Better for general-purpose queries |
| Query Requirements | Query must match the filter condition | No special query structure required |
| Storage Usage | Reduced disk space | Higher disk usage |
| Maintenance Overhead | Lower due to fewer rows | Higher maintenance across all data |
| Use Case | Sparse columns, conditional filtering | Columns frequently searched or joined |
| Introduced in Version | SQL Server 2008 | Available in all versions |
| Created With | CREATE INDEX … WHERE | CREATE INDEX … |
| Best Tool to Manage | dbForge Studio for SQL Server | dbForge Studio for SQL Server |
Conclusion
SQL Server filtered indexes are one of the most effective techniques for optimizing query performance. When implemented correctly, they enhance query performance and are especially useful in scenarios involving sparse data, status-based filtering, and null exclusion.
However, without the right tools, maintaining filtered indexes can become overwhelming. This is why dbForge Studio for SQL Server is your best bet. With its incredible visual interface and index health monitoring, dbForge Studio for SQL Server simplifies index management. It allows you to focus on performance without getting lost in the details of T-SQL.
Try it out today and take full control of your SQL Server environment.
FAQs
What is a filtered index in SQL Server?
A filtered index is a non-clustered index that includes only the rows that satisfy a WHERE condition.
What does filtered mean in SQL?
In SQL, “filtered” typically refers to limiting the rows returned or indexed based on a condition.
What are the different types of indexes in SQL?
- Clustered index: Stores the actual table data in the order of the index key. Each table can have only one clustered index.
- Non-clustered index: Stores the index separately from the table data and includes pointers to the actual rows. A table can have multiple non-clustered indexes.
- Unique index: Ensures that all the values in the indexed column(s) are unique and there is no duplicate data.
- Filtered index: Includes only rows meeting a specific condition (using a
WHEREclause).
- Full-text index: Supports fast and efficient full-text searches on large text-based columns, such as finding words or phrases inside documents.
- XML index: Optimizes queries on XML data stored in XML columns by indexing the internal structure of the XML.
- Spatial index: Speed up operations on spatial data types like geometry and geography (used for maps, locations, etc.).
- Columnstore index: Stores data in columns instead of rows, improving performance for large data warehouse queries and analytics.
How to get filtered data in SQL?
Use the WHERE clause in your SQL query to filter rows based on conditions.
What is the difference between filtering and grouping?
Filtering limits rows based on conditions (WHERE), while grouping aggregates rows based on column values (GROUP BY).