
In our fast-changing world, observations of certain events, operations, and processes determine the development of business and implementation of any solutions or ideas. Such observations are captured in the form of data usually stored and processed in a database.
The importance lies not only in designing a database but also in implementing your solution in such a way that you can reverse engineer the database without any documentation or external information apart from the code of the solution. This is also true for the whole information system.
In this article, we are going to describe the operation that is opposite to the database design, more specifically, database reverse engineering exemplified by MS SQL Server. Also, we will provide examples of how to obtain various types of information for reverse engineering.
What is reverse engineering and what is it used for?
Reverse engineering of an information system means obtaining the information on software solution architecture via its implementation, that is via code reproduction.
Let’s start by saying that we have already examined SQL Server database design basics with an example of a database for a recruitment service.
It is often the case that a certain information system has been working for quite a long time, and even after many specialists, who were developing and supporting it, leave the company. However, a part of the documentation was kept very comprehensible for those specialists, and some elements of the information system were not documented at all.
Finally, there comes a time when the information system needs major changes or has to be rewritten. In such a situation, it is necessary to go into much detail in order to understand how the information system is working at the moment. As you are probably aware of, the most relevant information lies in the very code, not in the documentation system. However, it has been only 5 years (approximately) since people started writing proper code. Just as the task estimation came to incorporate documentation on software development/changes, the code became more accurate and relevant. Despite this, when the solution requires urgent improvement or development, the quality and relevance of documentation may still be affected.
When this occurs, we usually obtain relevant information on the software architecture through its implementation, which is code. We call this method reverse engineering.
Sooner or later, any information system needs a database to store and process the ever-growing volume of data so that we can analyze it in various ways and make important business decisions based on the analysis.
In this article, we will talk about this kind of database reverse engineering.
But first, let’s define “DB reverse engineering”.
Database reverse engineering is the process that involves obtaining a database schema through its implementation, that is, through the definition of its objects. If you want to learn more about constructing a data model from an existing database, refer to How to reverse engineer databases.
Reverse Engineering Support for Database Design
The following key elements are considered important in a database for reverse engineering:
- primary keys
- foreign keys (what is referenced)
- uniqueness constraints
While primary keys and uniqueness constraints are almost always present in the object definition as they are vital for proper code operation, foreign keys may be written right in the table definition.
There are several reasons for that, but the most compelling ones are the following:
- A historical factor.
- The foreign keys of a replicated database can affect data exchange performance.
- To boost essential processes related to data modification (since foreign keys require extra time when changing related data).
- Data integrity within foreign keys is not supported at the database level.
The third option is mainly used in real-time systems where even a tiny delay can cause many deaths (transport security, medicine, etc.).
If foreign keys have not been set explicitly in the table definition, then one of the following methods is used:
- Name a field that is a foreign key in such a way that it is clear which field of which table it refers to. For instance, you could use the name of a referenced table field. At the same time, the field contains the name of its table in the name.
For example:
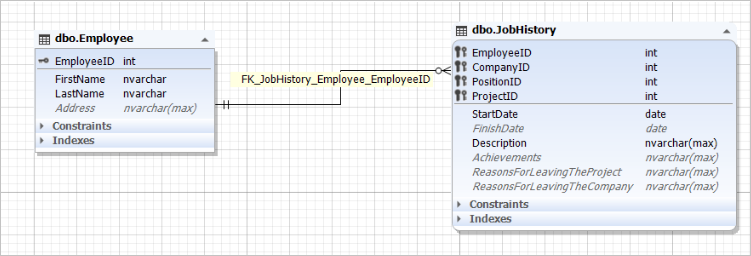
You can see here that the EmployeeID field of the [dbo].[JobHistory] table references the EmployeeID field of the [dbo].[Employee] table.
- Add the description of the field and what it references to the metadata. In MS SQL Server, one usually uses extended properties with the MS_Description key:
EXEC sys.sp_addextendedproperty @name=N'MS_Description'
, @value=N'refers to the field [dbo].[Employee].[EmployeeID]'
, @level0type=N'SCHEMA'
, @level0name=N'dbo'
, @level1type=N'TABLE'
, @level1name=N'JobHistory'
, @level2type=N'COLUMN'
, @level2name=N'EmployeeID';To learn more about database documenting, refer to Documenting MS SQL Server Databases.
Nonetheless, the better option for reverse engineering support would be to introduce foreign keys in the definition of tables. You can keep several foreign keys disabled if necessary.
To disable a foreign key, use the script below:
ALTER TABLE [dbo].[JobHistory]
NOCHECK CONSTRAINT [FK_JobHistory_Employee_EmployeeID];Here, the [FK_JobHistory_Employee_EmployeeID] foreign key linking the EmployeeID field of the [dbo].[JobHistory] table with the EmployeeID field of the [dbo].[Employee] table is disabled for the [dbo].[JobHistory] table.
To sum up, this method allows you to quickly get the database schema from the definitions of its tables.
Obtaining Information for Reverse Engineering
To obtain the information on the database schema, you can refer to the following system views:
- sys.schemas is the information on schemas.
- sys.tables is the information on tables.
- sys.views is the information on views.
- sys.indexes is the information on indexes.
- sys.index_columns is the information on index columns.
- sys.columns is the information on table columns.
- sys.check_constraints is the information on check constraints.
- sys.default_constraints is the information on default constraints.
- sys.key_constraints is the information on primary key or uniqueness constraints.
- sys.foreign_keys is the information on foreign keys.
- sys.types is the information on data types.
- sys.objects is the information on objects.
- some other system views described in System Catalog Views.
To find a complete diagram of system views, use this link.
In addition, system information schema views are used.
Obtaining Information about Primary Keys
You can use the following query to get the list of primary keys:
SELECT
SCHEMA_NAME(tab.schema_id) AS [schema_name]
,pk.[name] AS pk_name
,ic.index_column_id AS column_id
,col.[name] AS column_name
,tab.[name] AS table_name
FROM sys.tables tab
INNER JOIN sys.indexes AS pk
ON tab.object_id = pk.object_id
AND pk.is_primary_key = 1
INNER JOIN sys.index_columns AS ic
ON ic.object_id = pk.object_id
AND ic.index_id = pk.index_id
INNER JOIN sys.columns AS col
ON pk.object_id = col.object_id
AND col.column_id = ic.column_id
ORDER BY schema_name(tab.schema_id),
pk.[name],
ic.index_column_id;We will receive the following output:
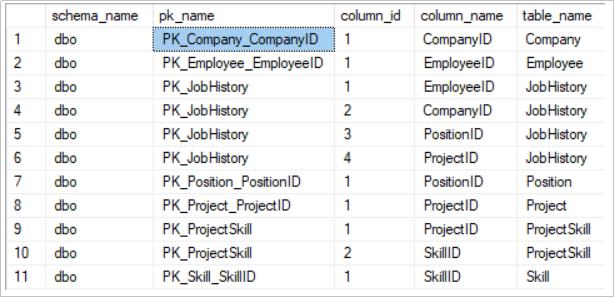
As you see, the output shows the following fields:
- schema_name is the name of the table schema.
- pk_name is the primary key name.
- column_id is the number of table column included in the primary key definition.
- column_name is the table column included in the primary key.
- table_name is the table name for which the primary key is defined.
The following system views are used:
- sys.tables is the information on tables.
- sys.indexes is the information on indexes.
- sys.index_columns is the information on index columns.
- sys.columns is the information on table columns.
You can obtain similar information with another query:
SELECT
tc.[CONSTRAINT_CATALOG]
,tc.[CONSTRAINT_SCHEMA]
,tc.[CONSTRAINT_NAME]
,tc.[TABLE_NAME]
,ccu.[COLUMN_NAME]
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS tc
INNER JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE AS ccu
ON tc.[CONSTRAINT_NAME] = ccu.[Constraint_name]
WHERE
tc.[CONSTRAINT_TYPE] = 'Primary Key'
ORDER BY tc.[CONSTRAINT_SCHEMA]
, tc.[TABLE_NAME]
, ccu.[COLUMN_NAME];The output is as follows:
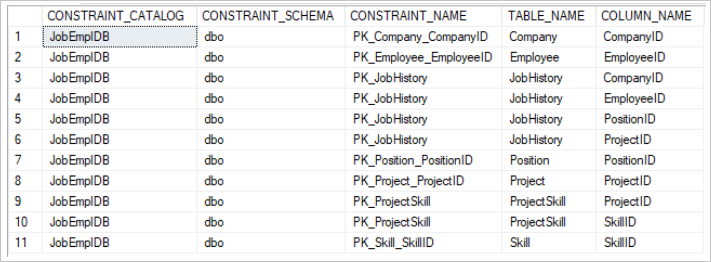
As a result, the output gives the following fields:
- CONSTRAINT_CATALOG is the database.
- CONSTRAINT_SCHEMA is the table schema name.
- CONSTRAINT_NAME is the primary key name.
- TABLE_NAME is the table in which the primary key is defined.
- COLUMN_NAME is the table field included in the primary key.
Here, the following system views from INFORMATION_SCHEMA are used:
- TABLE_CONSTRAINTS are table constraints.
- CONSTRAINT_COLUMN_USAGE is the table columns that take part in constraints.
Obtaining Information about Foreign Keys
To obtain the list of foreign keys, apply the query below:
SELECT
f.name AS ForeignKey
,SCHEMA_NAME(f.SCHEMA_ID) AS SchemaName
,OBJECT_NAME(f.parent_object_id) AS TableName
,COL_NAME(fc.parent_object_id, fc.parent_column_id) AS ColumnName
,SCHEMA_NAME(o.SCHEMA_ID) ReferenceSchemaName
,OBJECT_NAME(f.referenced_object_id) AS ReferenceTableName
,COL_NAME(fc.referenced_object_id, fc.referenced_column_id)
AS ReferenceColumnName
,f.create_date
FROM sys.foreign_keys AS f
INNER JOIN sys.foreign_key_columns AS fc
ON f.OBJECT_ID = fc.constraint_object_id
INNER JOIN sys.objects AS o
ON o.OBJECT_ID = fc.referenced_object_id
ORDER BY SchemaName, TableName, ColumnName, ReferenceSchemaName,
ReferenceTableName, ReferenceColumnName;The result will be as follows:

The output contains the following columns:
- ForeignKey is the name of the foreign key constraint.
- SchemaName is the table schema name that contains the foreign key.
- TableName is the table name that contains the foreign key.
- ColumnName is the referenced table column.
- ReferenceSchemaName is the referenced table schema name.
- ReferenceTableName is the referenced table name.
- ReferenceColumnName is the referenced table column.
- create_date is the date and time of the foreign key creation.
The following system views are used here:
- sys.foreign_keys is the information about foreign keys.
- sys.foreign_key_columns is the information about the table columns included in the foreign keys.
You can also get similar information with a different query:
SELECT
ccu.table_schema AS SourceSchemaName
,ccu.table_name AS SourceTable
,ccu.constraint_name AS SourceConstraint
,ccu.column_name AS SourceColumn
,kcu.table_schema AS TargetSchemaName
,kcu.table_name AS TargetTable
,kcu.column_name AS TargetColumn
FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE AS ccu
INNER JOIN INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS AS rc
ON ccu.CONSTRAINT_NAME = rc.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE AS kcu
ON kcu.CONSTRAINT_NAME = rc.UNIQUE_CONSTRAINT_NAME
ORDER BY SourceSchemaName, SourceTable, SourceColumn,
TargetSchemaName, TargetTable, TargetColumn;The output is as follows:

As a result, the following columns are shown in the output:
- SourceSchemaName is the schema name of the table containing the foreign key.
- SourceTable is the name of the table containing the foreign key.
- SourceConstraint is the name of the foreign key constraint.
- SourceColumn is the referenced table column.
- TargetSchemaName is the referenced table schema name.
- TargetTableName is the referenced table name.
- TargetColumnName is the referenced table column.
The following system views from INFORMATION_SCHEMA are used:
- CONSTRAINT_COLUMN_USAGE indicates the table fields that take part in constraints.
- REFERENTIAL_CONSTRAINTS indicate foreign key constraints.
- KEY_COLUMN_USAGE indicates the table columns included in the keys.
Obtaining Information about Uniqueness Constraints
To get the list of uniqueness constraints, run the following query:
SELECT SCHEMA_NAME(t.[schema_id]) AS [schema_name],
i.[name] AS constraint_name,
t.[name] AS table_name,
c.[name] AS column_name,
ic.key_ordinal AS column_position,
ic.is_descending_key AS is_desc
FROM sys.indexes i
INNER JOIN sys.index_columns ic
ON i.index_id = ic.index_id AND i.[object_id] = ic.[object_id]
INNER JOIN sys.tables AS t
ON t.[object_id] = i.[object_id]
INNER JOIN sys.columns c
ON t.[object_id] = c.[object_id] AND ic.[column_id] = c.[column_id]
WHERE i.is_unique_constraint = 1
ORDER BY [schema_name], constraint_name, column_position;The output is as follows:

Accordingly, the following fields are output:
- schema_name is the table schema name that has the definition of a uniqueness constraint.
- constraint_name is the uniqueness constraint name.
- table_name is the table name that has a definition of uniqueness constraint.
- column_name is the table column included in the uniqueness constraint.
- column_position is the table column position in the definition of uniqueness constraint.
- is_desc means that sorting by table column in the unique index is descending (1 indicates a descending order, 0 indicates an ascending order).
The following system views are used here:
- sys.indexes is the information about indexes.
- sys.index_columns is the information about index columns.
- sys.tables is the information about tables.
- sys.columns is the information on table columns.
Additionally, similar information can be obtained in the following way:
SELECT
tc.[CONSTRAINT_CATALOG]
,tc.[CONSTRAINT_SCHEMA]
,tc.[CONSTRAINT_NAME]
,tc.[TABLE_NAME]
,ccu.[COLUMN_NAME]
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS tc
INNER JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE AS ccu
ON tc.[CONSTRAINT_NAME] = ccu.[Constraint_name]
WHERE
tc.[CONSTRAINT_TYPE] = 'UNIQUE'
ORDER BY tc.[CONSTRAINT_SCHEMA]
, tc.[TABLE_NAME]
, ccu.[COLUMN_NAME];We will obtain the following result:

As a result, we can see the following fields in the output:
- CONSTRAINT_CATALOG is the database.
- CONSTRAINT_SCHEMA is the table schema name.
- CONSTRAINT_NAME is the uniqueness constraint name.
- TABLE_NAME is the table that has a definition of the uniqueness constraint.
- COLUMN_NAME is the table column included in the uniqueness constraint.
The following system views from INFORMATION_SCHEMA are used:
- TABLE_CONSTRAINTS are table constraints.
- CONSTRAINT_COLUMN_USAGE indicates table columns taking part in the constraint.
Obtaining Information about Heaps
It bears reminding that a table without a clustered index is called a heap.
To get a list of heaps, run the following query:
SELECT OBJECT_SCHEMA_NAME(tbl.[object_id]) AS SchemaName ,
OBJECT_NAME(tbl.[object_id]) AS TableName
FROM sys.tables AS tbl
JOIN sys.indexes i ON i.[object_id] = tbl.[object_id]
WHERE i.[type_desc] = 'HEAP'
ORDER BY TableName;There are no heaps in the JobEmplDB database, hence, we need to run this script in another database that has heaps. Take the SRV database as an example. In that case, you can get the following result:
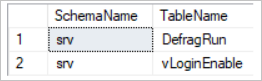
As a result, the output shows the following fields:
- SchemaName is the schema name of the heap.
- TableName is the heap name.
The following system views are used:
- sys.tables is the information about tables.
- sys.indexes is the information about indexes.
Obtaining Key Information about Tables, Views, and Their Fields
To get the key information about tables and their fields, use the following query:
SELECT
SCHEMA_NAME(tbl.[schema_id]) AS [SchemaName]
,tbl.[name] AS [Name]
,col.[name] AS [ColumnName]
,dc.[name] AS [DefaultConstraintName]
,dc.[definition] AS [DefaultDefinition]
,col.[column_id] AS [ColumnNum]
,t.[name] AS [TypeName]
,col.[max_length] AS [TypeMaxLength]
,col.[precision] AS [TypePrecision]
,col.[scale] AS [TypeScale]
,col.[is_nullable] AS [IsNull]
,col.[is_rowguidcol] AS [IsRowGUIDCol]
,col.[is_identity] AS [IsIdentiity]
FROM sys.tables AS tbl
INNER JOIN sys.columns AS col
ON tbl.[object_id] = col.[object_id]
INNER JOIN sys.types AS t
ON col.[user_type_id] = t.[user_type_id]
LEFT OUTER JOIN sys.default_constraints AS dc
ON dc.[object_id] = col.[default_object_id];There are no default values in the JobEmplDB database, so run this script against the SRV database. The following result appears:

As a result, the following columns are output:
- SchemaName is the table schema name.
- Name is the table name.
- ColumnName is the table column name.
- DefaultConstraintName is the default constraint name.
- DefaultDefinition is the default definition of the constraint.
- ColumnNum is the column position number in the table definition.
- TypeName is the name of the table column type.
- TypeMaxLength is the maximum length of the table column type measured in bytes (-1 means that it is not limited by this parameter).
- TypePrecision is the maximum precision of values of this data type if it is numeric, otherwise, it is 0.
- TypeScale is the maximum precision of values of this data type if it is numeric, otherwise, it is 0.
- IsNull shows whether the field can contain the NULL value or not.
- IsRowGUIDCol defines whether the field is the RowGUID type.
- IsIdentity defines whether the field is autoincremented.
The following system views are applied:
- sys.tables is the information about the tables.
- sys.columns is the information about the table fields.
- sys.default_constraints is the information about the default values.
- sys.types is the information about the data types.
These system views have a lot of useful information that you should take into account. But for the sake of simplicity, you will see here only general information about tables, table fields, default field values, and column types.
To get the same information for the views, change sys.tables to sys.views in the query:
SELECT
SCHEMA_NAME(tbl.[schema_id]) AS [SchemaName]
,tbl.[name] AS [Name]
,col.[name] AS [ColumnName]
,dc.[name] AS [DefaultConstraintName]
,dc.[definition] AS [DefaultDefinition]
,col.[column_id] AS [ColumnNum]
,t.[name] AS [TypeName]
,col.[max_length] AS [TypeMaxLength]
,col.[precision] AS [TypePrecision]
,col.[scale] AS [TypeScale]
,col.[is_nullable] AS [IsNull]
,col.[is_rowguidcol] AS [IsRowGUIDCol]
,col.[is_identity] AS [IsIdentiity]
FROM sys.views AS tbl
INNER JOIN sys.columns AS col
ON tbl.[object_id] = col.[object_id]
INNER JOIN sys.types AS t
ON col.[user_type_id] = t.[user_type_id]
LEFT OUTER JOIN sys.default_constraints AS dc
ON dc.[object_id] = col.[default_object_id];The approximate query result is as follows:

You can get similar information using the following script, which outputs the information about both tables and views at the same time:
SELECT
[TABLE_SCHEMA]
,[TABLE_NAME]
,[COLUMN_NAME]
,[ORDINAL_POSITION]
,[COLUMN_DEFAULT]
,[IS_NULLABLE]
,[DATA_TYPE]
,[CHARACTER_MAXIMUM_LENGTH]
,[CHARACTER_OCTET_LENGTH]
,[NUMERIC_PRECISION]
,[NUMERIC_PRECISION_RADIX]
,[NUMERIC_SCALE]
,[DATETIME_PRECISION]
FROM INFORMATION_SCHEMA.COLUMNS;The approximate output is as follows:

You can see the following columns in the result:
- TABLE_SCHEMA is the schema name of the table/view.
- TABLE_NAME is the name of the table/view.
- COLUMN_NAME is the column name of the table/view.
- ORDINAL_POSITION is the ordinal position of the field in the table/view definition.
- COLUMN_DEFAULT is the default value for the column.
- IS_NULLABLE indicates whether the column can contain NULL values.
- DATA_TYPE is the data type of the field.
- CHARACTER_MAXIMUM_LENGTH is the maximum character length for binary data, character, or text data and images; -1 is for XML data type and big values. The column returns NULL otherwise.
- CHARACTER_OCTET_LENGTH is the maximum length measured in bytes for binary data, character, or text data and images; -1 is for XML data type and big values. The column returns NULL otherwise.
- NUMERIC_PRECISION is the precision of approximate and exact numeric data, integer data, or money data. The column returns NULL otherwise.
- NUMERIC_PRECISION_RADIX is the precision radix of the approximate and exact numeric data, integer data, or money data; otherwise, NULL is returned.
- NUMERIC_SCALE is the scale of the approximate and exact numeric data, integer data, or money data. The column returns NULL otherwise.
- DATETIME_PRECISION is the subtype code for the interval data types like DateTime and ISO. For other types of data, NULL is returned.
In this case, we use the COLUMNS system view from the system information schema views INFORMATION_SCHEMA.
Obtaining Information about Stored Procedures, Functions, and Their Parameters
To get the information about stored procedures and functions, use the following script:
SELECT
s.[name] AS SchemaName
,obj.[name] AS 'ViewName'
,obj.[type]
,obj.Create_date
,sm.[definition] AS 'Definition script'
FROM sys.objects as obj
INNER JOIN sys.schemas as s
ON obj.schema_id = s.schema_id
INNER JOIN sys.sql_modules as sm
ON obj.object_id = sm.object_id
WHERE obj.[type] IN ('P', 'PC', 'FN', 'AF', 'FS', 'FT', 'IF', 'TF');The approximate script result is as follows:
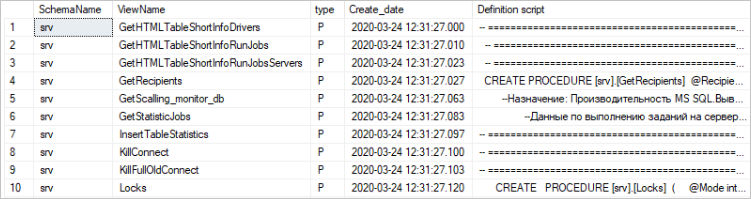
You can see the following columns in the output:
- SchemaName is the schema name of the stored procedure/function.
- ViewName is the name of the stored procedure/function.
- type is the type of stored procedure/function (P is a stored procedure in SQL, PC is an assembly stored procedure (CLR environment), FN is a scalar function in SQL, FS is an assembly scalar function (CLR environment), FT is an assembly function (CLR environment) with a table value, IF is a built-in SQL function with a table value, AF is an aggregate function (CLR environment), TF is a SQL function that returns a table value.
- Create_date is the date and time of the stored procedure/function creation.
- Stored Procedure script is the definition of the stored procedure/function.
The following system views are used:
- sys.objects is the information about objects.
- sys.schemas is the information about schemas.
- sys.sql_modules is the information about the definition of objects.
You can get similar information with the following query:
SELECT
[SPECIFIC_SCHEMA]
,[ROUTINE_NAME]
,[ROUTINE_DEFINITION]
,[ROUTINE_TYPE]
,[CREATED]
,[LAST_ALTERED]
FROM INFORMATION_SCHEMA.ROUTINES;The approximate result of the query is as follows:
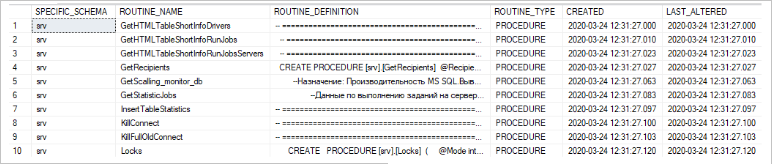
As a result, the output shows the following fields:
- SPECIFIC_SCHEMA is the schema name of the stored procedure/function.
- ROUTINE_NAME is the name of the stored procedure/function.
- ROUTINE_DEFINITION is the definition of the stored procedure/function.
- ROUTINE_TYPE is the object type (PROCEDURE is a stored procedure, FUNCTION is a function).
- CREATED is the date and time of the stored procedure/function creation.
- LAST_ALTERED is the date and time of the last modification of the stored procedure/function.
In this case, we use the ROUTINES system view from the system information schema views INFORMATION_SCHEMA.
To obtain the information on parameters of stored procedures and functions, run the following script:
SELECT
s.[name] AS SchemaName
,obj.[name] AS 'ViewName'
,obj.[type]
,p.[name] AS 'ParameterName'
,p.[parameter_id] AS [ParameterNum]
,p.[is_output] AS [IsOutput]
,p.[default_value] AS [DefaultValue]
,t.[name] AS [TypeName]
,p.[max_length] AS [TypeMaxLength]
,p.[precision] AS [TypePrecision]
,p.[scale] AS [TypeScale]
FROM sys.objects AS obj
INNER JOIN sys.schemas AS s
ON obj.schema_id = s.schema_id
INNER JOIN sys.parameters AS p
ON obj.object_id = p.object_id
INNER JOIN sys.types AS t
ON t.[user_type_id] = p.[user_type_id]
WHERE obj.[type] IN ('P', 'PC', 'FN', 'AF', 'FS', 'FT', 'IF', 'TF');The approximate script result is as follows:
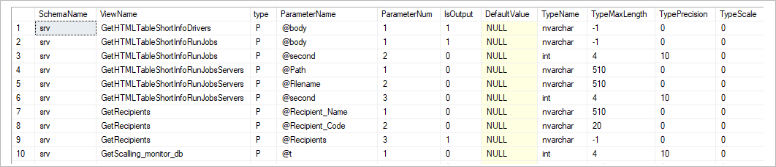
You can see the following fields in the output:
- SchemaName is the schema name of the stored procedure/function.
- ViewName is the name of the stored procedure/function.
- type is the type of the stored procedure/function (P is a stored procedure in SQL, PC is an assembly stored procedure (CLR environment), FN is a scalar function in SQL, FS is an assembly scalar function (CLR environment), FT is an assembly function (CLR environment) with a table value, IF is a built-in SQL function with a table value, AF is an aggregate function (CLR environment), TF is a SQL function that returns a table value.
- ParameterName is the parameter name.
- ParameterNum is the parameter position number in the stored procedure definition.
- IsOutput shows whether it is an output parameter.
- DefaultValue is the default value for the parameter.
- TypeName is the parameter type.
- TypeMaxLength is the parameter maximum length measured in bytes where -1 means that the parameter cannot be applied.
- TypePrecision is the precision for a numeric parameter; otherwise, it is 0.
- TypeScale is the numeric parameter scale; otherwise, it is 0.
The following system views are used:
- sys.objects is the information on objects.
- sys.schemas is the information on schemas.
- sys.parameters is the information parameters.
You can obtain similar information by running the following query:
SELECT
r.[SPECIFIC_SCHEMA]
,r.[ROUTINE_NAME]
,r.[ROUTINE_TYPE]
,p.[PARAMETER_NAME]
,p.[ORDINAL_POSITION]
,p.[PARAMETER_MODE]
,p.[DATA_TYPE]
,p.[CHARACTER_MAXIMUM_LENGTH]
,p.[CHARACTER_OCTET_LENGTH]
,p.[NUMERIC_PRECISION]
,p.[NUMERIC_PRECISION_RADIX]
,p.[NUMERIC_SCALE]
,p.[DATETIME_PRECISION]
FROM INFORMATION_SCHEMA.PARAMETERS AS p
INNER JOIN INFORMATION_SCHEMA.ROUTINES AS r
ON p.[SPECIFIC_SCHEMA] = r.[SPECIFIC_SCHEMA]
AND p.[SPECIFIC_NAME] = r.[ROUTINE_NAME];The approximate query result is as follows:

You can find the following fields in the output:
- SPECIFIC_SCHEMA is the schema name of the stored procedure/function.
- ROUTINE_NAME is the name of the stored procedure/function.
- ROUTINE_TYPE is the object type (PROCEDURE is the stored procedure, FUNCTION is the function).
- PARAMETER_NAME is the parameter of the stored procedure/function.
- ORDINAL_POSITION is the parameter ordinal position in the definition of the stored procedure/function.
- PARAMETER_MODE is the input (INOUT) or output (IN) parameter.
- DATA_TYPE is the data type.
- CHARACTER_MAXIMUM_LENGTH is the maximum character length for binary data, character or text data, and images, -1 is for XML data type and big values. The column returns NULL otherwise.
- CHARACTER_OCTET_LENGTH is the maximum length measured in bytes for binary data, character or text data, and images, -1 is for XML data type and big values. The column returns NULL otherwise.
- NUMERIC_PRECISION is the precision of approximate and exact numeric data, integer data, or money data. The column returns NULL otherwise.
- NUMERIC_PRECISION_RADIX is the precision radix of approximate and exact numeric data, integer data, or money data, otherwise, NULL is returned.
- NUMERIC_SCALE is the scale of approximate and exact numeric data, integer data, or money data. The column returns NULL otherwise.
- DATETIME_PRECISION is the subtype code for the interval data types like DateTime and ISO. For other types of data, NULL is returned.
We use the PARAMETERS and ROUTINES system views from the system information schema views INFORMATION_SCHEMA.
Obtaining Information about Other Objects and Data
To avoid excessive wordiness in this article, we won’t provide the scripts to obtain the whole information about all database object types. Yet, it should be noted that the above-mentioned scripts allow obtaining key information about all basic types of database objects.
However, it is often the case that one needs to get information from the extended properties of database objects and also about other objects types like synonyms, sequences, statistics, and others).
For instance, you can obtain the information on database triggers using the following script:
SELECT
t.name AS TriggerName
,t.parent_class_desc
,t.type AS TrigerType
,t.create_date AS TriggerCreateDate
,t.modify_date AS TriggerModifyDate
,t.is_disabled AS TriggerIsDisabled
,t.is_instead_of_trigger AS TriggerInsteadOfTrigger
,t.is_ms_shipped AS TriggerIsMSShipped
,t.is_not_for_replication
,s.name AS SchenaName
,ob.name AS ObjectName
,ob.type_desc AS ObjectTypeDesc
,ob.type AS ObjectType
,sm.[DEFINITION] AS 'Trigger script'
FROM sys.triggers AS t --sys.server_triggers
LEFT OUTER JOIN sys.objects AS ob
ON t.parent_id = ob.object_id
LEFT OUTER JOIN sys.schemas AS s
ON ob.schema_id = s.schema_id
LEFT OUTER JOIN sys.sql_modules sm
ON t.object_id = sm.OBJECT_ID;The following system views are used in the query:
- sys.triggers is the information about triggers.
- sys.objects is the information about objects.
- sys.schemas is the information about schemas.
- sys.sql_modules is the information about object definition.
To learn more about how to obtain information from the extended properties, refer to the article Documenting MS SQL Server Databases.
Conclusion
To sum up, the main focus of this article has been on database reverse engineering. Throughout the article, we have done our best to provide the readers with the key information considering this topic in the context of MS SQL Server. We started by defining reverse engineering and explaining its purpose, proceeded with its main elements, and finally, provided numerous examples of how to obtain various types of information for reverse engineering, including primary and foreign keys, uniqueness constraints, heaps, tables, views, and many other objects.
Look upon the functionality of the Database Diagram tool in dbForge Studio for SQL Server, which you can use for database design.
