
In today’s data-centric society, the quantity and diversity of information are expanding at an unprecedented pace. From social media interactions and financial transactions to scientific research and industrial operations, vast amounts of data are being generated every second. However, amidst this ever-growing sea of data, a crucial distinction must be made between the raw data itself and the underlying metadata that accompanies it.
In this article, we delve deeper into the dichotomy between data and metadata, exploring their distinct roles, interdependence, and significance within the realm of data management.

Contents
- What is data?
- What is metadata?
- Key differences between data and metadata
- Role of metadata in data management
- dbForge Documenter for metadata management
- Conclusion
What is data?
Data refers to raw facts, observations, measurements, or representations of information in various formats, such as numbers, text, images, audio, or video. It serves as the foundation of knowledge and is essential for making informed decisions, conducting research, and gaining insights across various domains.
At its core, data is unprocessed and lacks inherent meaning or context. It represents discrete pieces of information that can be collected from numerous sources. While data itself may appear fragmented and disconnected, its true value lies in the insights and knowledge that can be extracted from it through analysis, interpretation, and contextualization. By applying appropriate techniques and tools, data can be transformed into actionable information, enabling organizations, researchers, and individuals to gain a deeper understanding of patterns, trends, correlations, and relationships within the data.
In other words, data serves as the raw material for information and knowledge. It represents the building blocks that, when properly processed, organized, and analyzed, provide valuable insights and contribute to decision-making, problem-solving, and innovation across various fields.
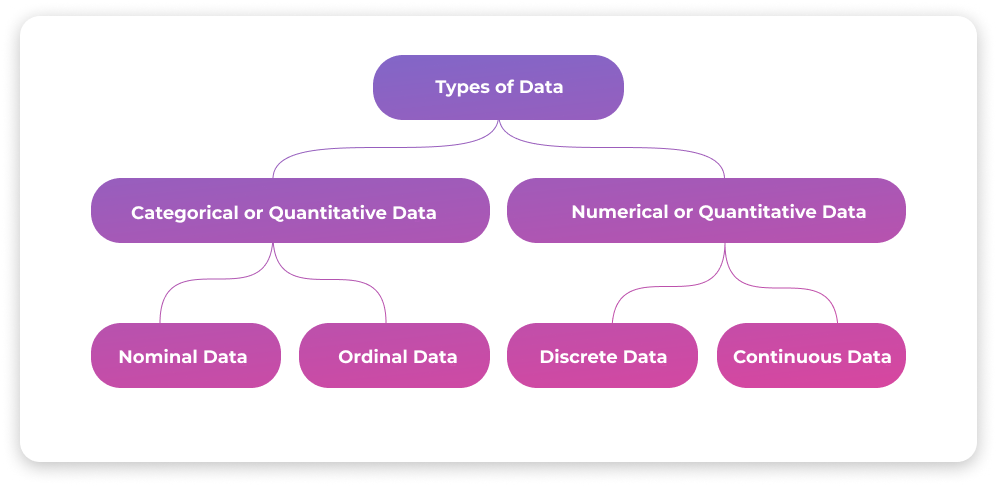
Types of data
Data can be classified into various types based on its characteristics, structure, and representation. Data can be classified in various ways based on a specific context. Let us look at the most general classification of data, used in statistics.
Categorical data, also known as qualitative data, is a type of data that represents characteristics, attributes, or categories rather than numerical values. It provides descriptive information about different groups or categories and is often expressed using labels or names. Categorical data is typically non-numeric and cannot be ordered or measured on a numerical scale.
Categorical data can be further classified into two subtypes:
- Nominal data represents categories without any inherent order or ranking. Each data point in this type is assigned to a specific category or label, and the categories are mutually exclusive. Examples of nominal data include gender (male/female), marital status (single/married/divorced), nationality, or types of fruits (mango, kiwi, orange).
- Ordinal data represents categories that have a natural order or ranking. While the categories in ordinal data can be ranked, the differences between the categories may not be uniform. The relative order or position of each category is significant, but the magnitude of differences between the categories is not well-defined. Examples of ordinal data include satisfaction ratings (very satisfied, satisfied, neutral, dissatisfied, very dissatisfied) or educational levels (elementary, middle school, high school, college, postgraduate).
Numerical data, also known as quantitative data, is a type of data that consists of numerical values or measurements. It represents quantities or amounts and can be subjected to mathematical operations and quantitative analysis. Numerical data is typically collected through measurements, observations, or counting.
Numerical data can be further classified into two subtypes:
- Discrete data represents values that are separate and distinct. It consists of whole numbers or integers and cannot take on intermediate values. Discrete data often arises from counting or enumerating. Examples of discrete data include the number of students in a classroom, the number of cars in a parking lot, or the number of books on a shelf.
- Continuous data represents values that can take on any value within a given range or interval. It can be measured on a continuous scale and often involves fractional or decimal values. Continuous data is obtained through measurements or observations. Examples of continuous data include height, weight, temperature, time, or distance.
The vital role of data
Data plays a pivotal role in our rapidly evolving world, where information holds the key to success. From businesses and research institutions to governments and individuals, the importance of data cannot be overstated.
Informed decision-making: This knowledge, derived from data analysis, helps organizations make informed decisions, identify opportunities, mitigate risks, and gain a competitive edge.
Scientific advancements: Data drives scientific research, enabling discoveries, advancements, and evidence-based conclusions in various fields.
Innovation: By harnessing the power of data, organizations can uncover new possibilities, identify emerging trends, and develop groundbreaking products and services.
Resource allocation: Data helps allocate resources effectively, leading to better resource management and cost reduction.
Economic growth: Data serves as a catalyst for economic growth, enabling businesses and governments to identify opportunities, make informed investments, and drive prosperity.
Competitive advantage: Embracing the power of data gives organizations and individuals a competitive edge.
It is important to recognize that the value of data lies not only in its abundance but also in its quality and integrity. Data must be accurate, reliable, and relevant to generate meaningful insights and drive effective decision-making.
What is metadata?
Metadata refers to “data about data” and provides additional information about the characteristics, context, and structure of a particular dataset, document, or information resource. It describes various attributes of data, such as its origin, format, content, location, quality, and relationships with other data elements. Metadata enhances the understanding, management, and usability of data by providing crucial details that help in its organization, discovery, interpretation, and preservation.
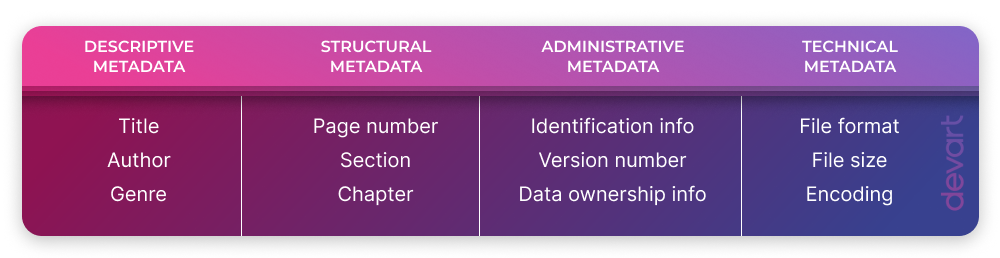
Types of metadata
There are different types of metadata:
- Descriptive metadata: Descriptive metadata provides information about the content, meaning, and context of the data. It includes details such as titles, summaries, keywords, abstracts, and subject classifications. Descriptive metadata helps in locating and identifying relevant data resources.
- Structural metadata: Structural metadata describes the organization, arrangement, and relationships between different components of a dataset or information resource. It provides information on how the data is structured, including the hierarchy, sequence, and interdependencies of its elements.
- Administrative metadata: Administrative metadata contains information related to the administrative aspects of data management. It includes details about data ownership, access rights, security, versioning, provenance, and data management policies. Administrative metadata helps in ensuring proper governance and accountability for data resources.
- Technical metadata: Technical metadata describes the technical characteristics of data, including its file format, size, encoding, resolution, compression, and software dependencies. It helps in understanding the technical requirements and capabilities for accessing, processing, and preserving the data.
Metadata plays a crucial role in various domains, including libraries, archives, scientific research, digital asset management, and data-intensive industries. It facilitates data integration, discovery, interoperability, and reuse. Effective metadata management ensures data quality, facilitates data sharing, and supports accurate interpretation and analysis of data.
Key differences between data and metadata
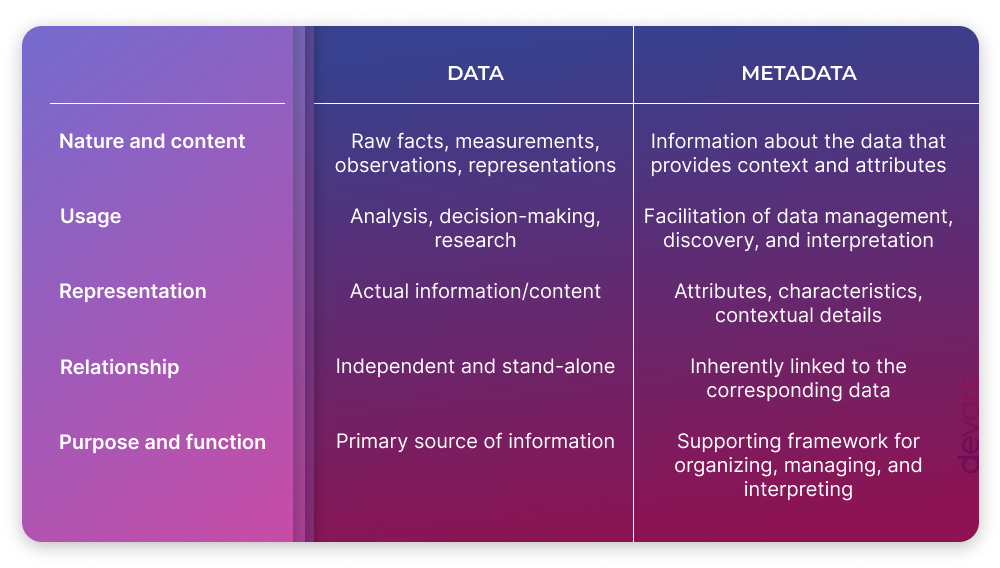
Data and metadata are two distinct concepts that play integral roles in managing and understanding information. Understanding their key differences is essential for effective data management and interpretation. Here are the key distinctions between data and metadata:
- Nature and content:
- Data refers to the raw facts, measurements, observations, or representations collected or generated in various formats. It consists of the actual information being captured, such as numbers, text, images, or audio.
- Metadata, on the other hand, represents information about the data. It provides context, describes attributes, and adds meaning to the data. Metadata helps to understand the characteristics, structure, relationships, and other properties associated with the data.
- Purpose and function:
- Data serves as the primary source of information and provides the substance for analysis, interpretation, and decision-making. It is the core material that needs to be processed and understood to extract insights and knowledge.
- Metadata, in its turn, serves as a supporting framework for organizing, managing, and interpreting the data. It provides additional information about the data to enhance its usability, discoverability, and interpretation.
- Representation:
- Data represents the actual information or content being conveyed. It can be numerical values, text strings, images, or any other form of digital representation.
- Metadata represents the attributes and characteristics of the data. It describes aspects such as the data source, format, structure, relationships, creation date, and other contextual details.
- Relationship:
- Data exists independently and can stand alone as individual pieces of information.
- In contrast, metadata is inherently linked to the corresponding data. It provides information about the data, establishing a relationship and connection between the metadata and the underlying data.
- Usage:
- Data is used for analysis, decision-making, research, and various other purposes specific to the domain or application.
- Metadata is used to facilitate data management, discovery, interpretation, and understanding. It aids in locating, organizing, and interpreting the data effectively.
Role of metadata in data management
Metadata plays a critical role in data management, providing essential information about the characteristics, context, and structure of data. It serves as a guiding framework that enhances the understanding, organization, and usability of data resources. Here are some key roles that metadata plays in effective data management:
Data discovery and identification
Metadata helps users discover and identify relevant data resources. By providing descriptive information about the data, such as titles, keywords, summaries, or subject classifications, metadata enables users to search, locate, and assess the suitability of data for their specific needs.
Data organization and structure
Metadata aids in organizing and structuring data. It describes the relationships, dependencies, and hierarchy of data elements, helping to establish a logical and coherent structure. Metadata ensures that data is appropriately organized, facilitating efficient data storage, retrieval, and integration.
Data quality and integrity
Metadata includes information about data quality, validation checks, and provenance. It helps assess the accuracy, completeness, and reliability of data resources. By documenting data quality measures and validation processes, metadata supports data governance, data quality assurance, and data cleansing initiatives.
Data interpretation and contextualization
Metadata provides context and meaning to data, aiding in its interpretation and understanding. By capturing information about data sources, formats, units of measurement, and transformations applied, metadata helps users interpret data correctly and apply appropriate analysis techniques.
Data access and security
Metadata includes information about access rights, security measures, and data usage restrictions. It helps manage data access permissions, ensuring that sensitive or confidential data is appropriately protected. Metadata also assists in maintaining data privacy and compliance with regulatory requirements.
Data integration and interoperability
Metadata facilitates data integration by specifying data mappings, transformations, and standards. It enables the harmonization and interoperability of diverse data sources by providing information about data formats, data models, and data exchange protocols. Metadata ensures that different data sources can be combined and utilized effectively.
Data lifecycle management
Metadata supports data lifecycle management by documenting the history, versions, and evolution of data resources. It aids in tracking changes, managing data updates, and preserving data provenance. Metadata provides information about data retention policies, archival procedures, and disposal guidelines, ensuring proper data lifecycle management.
Collaboration and knowledge sharing
Metadata promotes collaboration and knowledge sharing by enabling data discovery, understanding, and reuse. It assists in sharing data across teams, departments, or organizations by providing clear descriptions and standardized metadata formats. Metadata fosters efficient collaboration, accelerates research, and encourages data sharing practices.
dbForge Documenter for metadata management
To unlock the true value of your data, it is crucial to have proper names, descriptions, and classification. Without effective metadata management, your data may become difficult to use or even worthless. That’s where dbForge Documenter for SQL Server comes in.
dbForge Documenter allows you to describe your database schema with metadata, including tables, columns, and relationships. By documenting and organizing this vital information, you can gain a clear understanding of your data model.
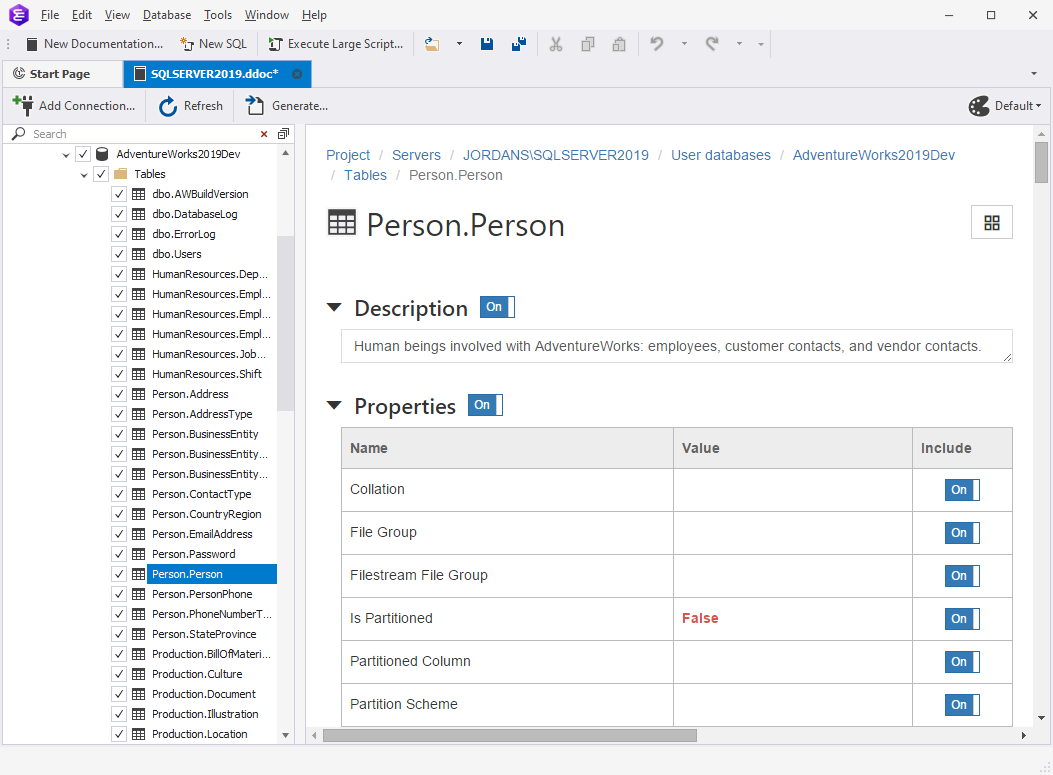
With dbForge Documenter, you can visualize the data model, making it easier to comprehend and navigate. The tool enables you to create comprehensive documentation that can be shared with everyone in your organization. This documentation empowers both technical and non-technical users to engage in self-service data discovery and analysis.
dbForge Documenter excels at preserving and documenting the metadata of all your database objects. It captures and retains crucial information such as descriptions, properties, and other attributes associated with each object within your database.
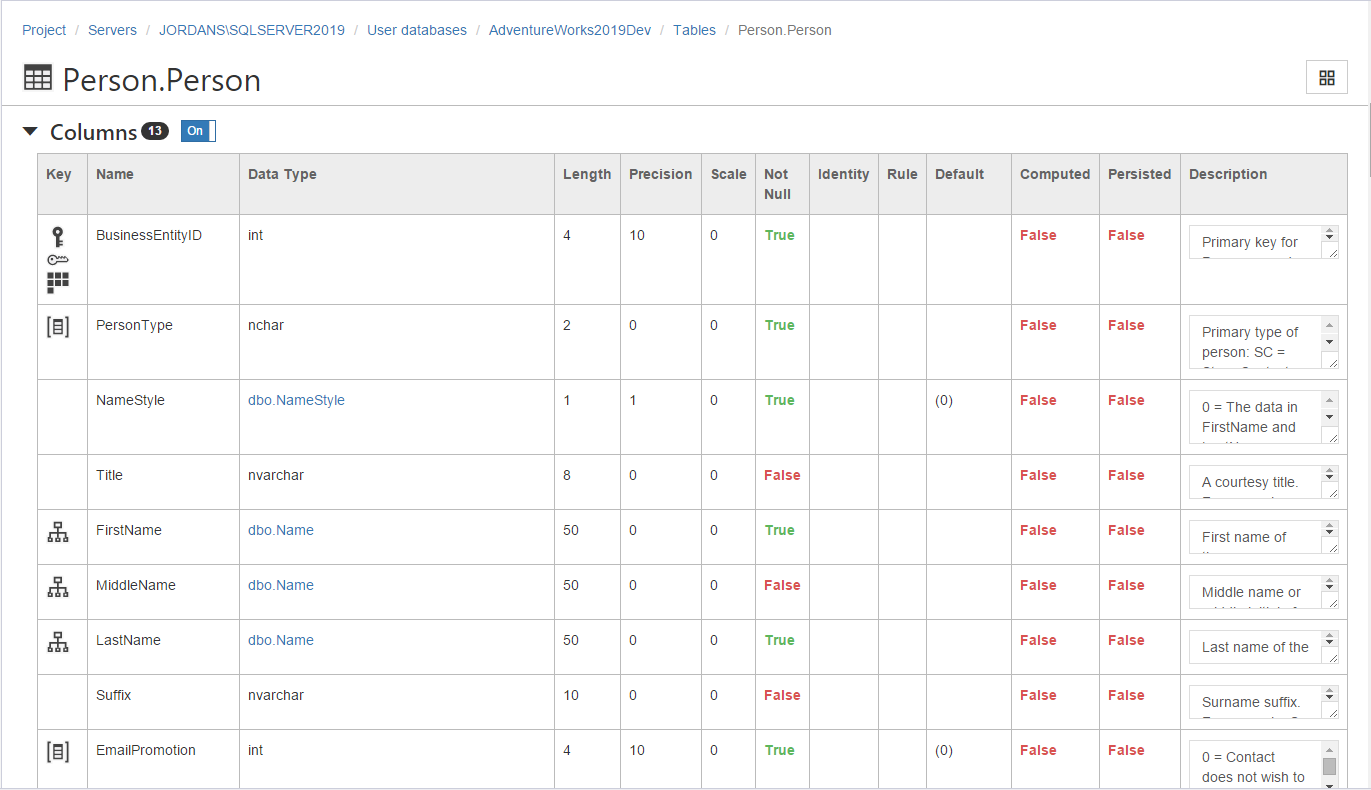
You can learn more about the features and capabilities of dbForge Documenter for SQL Server here.
Conclusion
By recognizing the importance of metadata, organizations can unlock the full potential of their data. Metadata management enables data discovery, organization, quality assurance, and interpretation. It facilitates collaboration, data integration, and knowledge sharing, empowering users to harness the power of their data resources.
To simplify and streamline metadata management, we recommend trying dbForge Documenter. With its comprehensive features for capturing, documenting, and preserving metadata, dbForge Documenter is a valuable tool for any organization seeking to enhance their data management practices.
Take advantage of the opportunity to download and try dbForge Documenter for a 30-day free trial.