
To start, let’s give definitions and highlight the difference between PIVOT and UNPIVOT operators in SQL Server.
The PIVOT and UNPIVOT relational operators are used to change a table-valued expression into another table and involve data rotation. Let’s start with the first operator.
We use PIVOT when there is a need to convert table rows into columns. It also enables us to perform aggregations, wherever required, for column values that are expected in the final output. Let’s take this table as an example:
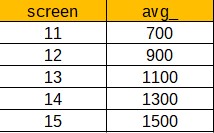
If we pivot it by the first column ‘screen’, we will get the following result:

To achieve this result in SQL Server, you need to run the following script:
SELECT [avg_], [11], [12], [13], [14], [15]
FROM (
SELECT 'average price' AS 'avg_', screen, price FROM laptops) x
PIVOT (AVG(price) FOR screen IN([11], [12], [13], [14], [15])
) pvt;In order to reverse a PIVOT operator, that is, to convert data from column-level back to row-level and get the original table, you can use the UNPIVOT operator. Nevertheless, note that UNPIVOT is not a complete opposite of the PIVOT function. It is only possible if the pivoted table doesn’t contain aggregated data.
PIVOT aggregates data and can merge a bunch of rows into a single row. UNPIVOT doesn’t reproduce the initial table-valued expression result since rows have been merged. Apart from that, null values in the input of UNPIVOT disappear in the output. When the values disappear, it shows that there may have been original null values in the input before the PIVOT operation.
Speaking of the PIVOT operator, dbForge Studio for SQL Server provides a useful function named a pivot table. To clarify, this is a data analysis tool that converts large amounts of data into concise and informative summaries. It enables us to easily rearrange and pivot data to get the layout best for understanding the data relations and dependencies. The greatest advantage of this feature is that it simplifies the aggregation process and the statistical information count. Also, the obtained report can be printed out, exported to various document formats, and e-mailed in the required format.
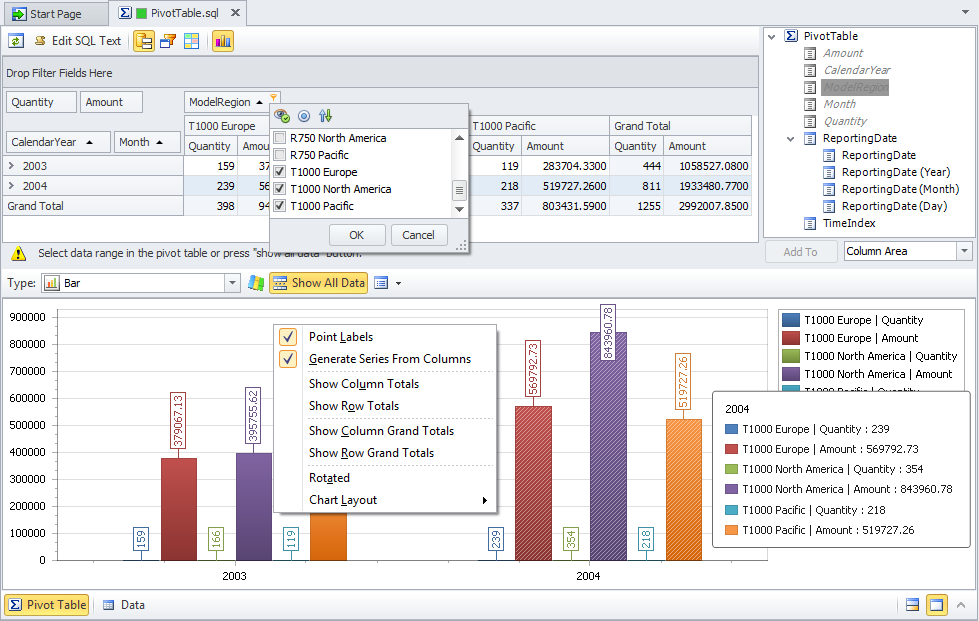
Now, let’s talk more about different implementations of T-SQL UNPIVOT transformations.
Let’s assume we have an aggregated table that contains data about the results of the games played by each player. We have a task to convert columns into rows.
IF OBJECT_ID ('dbo.Players') IS NOT NULL
DROP TABLE dbo.Players;
CREATE TABLE dbo.Players
(
PlayerID INT
, Win INT
, Defeat INT
, StandOff INT
, CONSTRAINT PK_Players PRIMARY KEY CLUSTERED (PlayerID) ON [PRIMARY]
);
INSERT INTO dbo.Players (PlayerID, Win, Defeat, StandOff)
VALUES
(1, 7, 6, 9),
(2, 12, 5, 0),
(3, 3, 11, 1);There are several ways to accomplish this task, so let’s take a look at the execution plans of each of the suggested below implementations. For this, we will use SQL Profiler available in dbForge Studio for SQL Server.
To receive execution plans automatically each time the query is executed, we need to switch to the profiling mode:
It’s also possible to get the query plan without starting its execution. For this, you need to run the Generate Execution Plan command.
Let’s Start!

1. UNION ALL
Previously, SQL Server did not offer an efficient way to convert columns into rows. Because of that many users opted for multiple reading from the same table with a different set of columns united through the UNION ALL statements:
SELECT PlayerID, GameCount = Win, GameType = 'Win'
FROM dbo.Players
UNION ALL
SELECT PlayerID, Defeat, 'Defeat'
FROM dbo.Players
UNION ALL
SELECT PlayerID, StandOff, 'StandOff'
FROM dbo.PlayersThe crucial weakness of this practice is multiple data reading. This happens because UNION ALL will scan the rows once for every subquery, which considerably decreases the efficiency of the query execution.
It is obvious when we look at the execution plan of the following query:
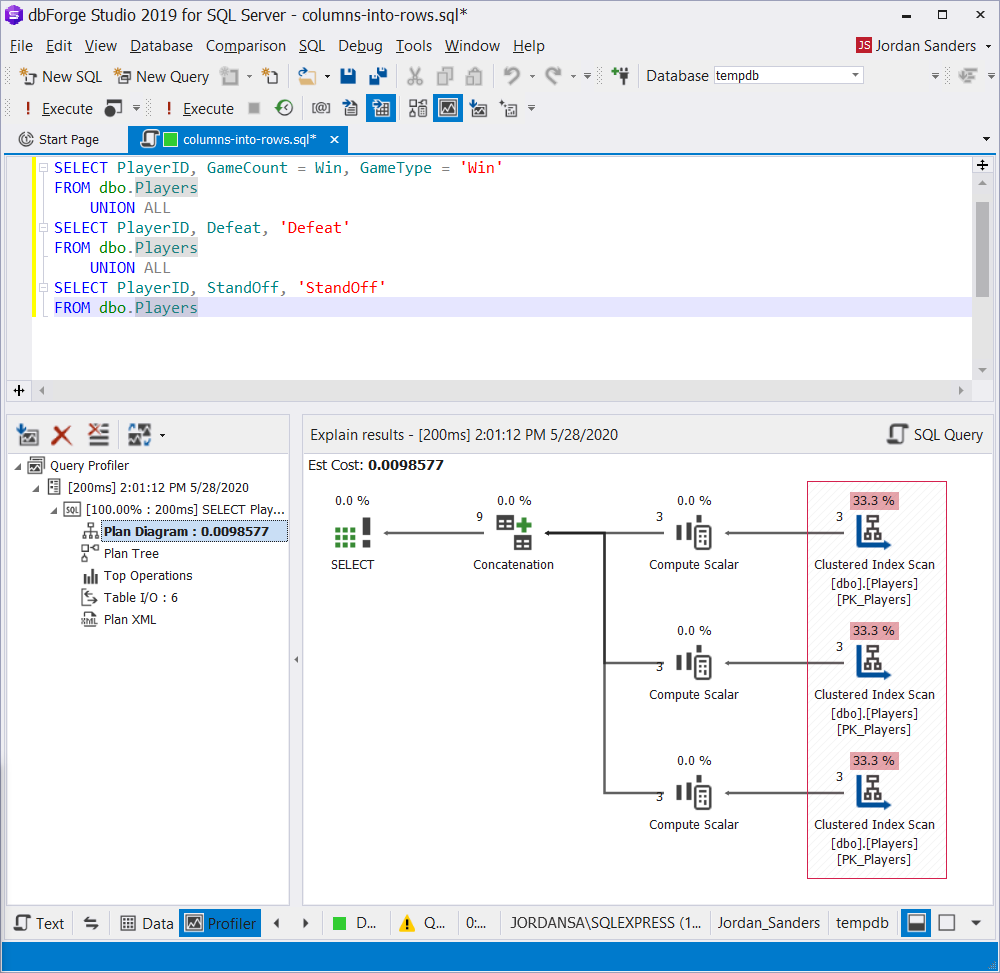
Building a SQL database diagram might be helpful to better understand how you should approaach this task without the risk of losing important colums and rows from focus.
2. UNPIVOT
One of the fastest ways to convert columns into rows is definitely to use the UNPIVOT operator, which was introduced in SQL Server in 2005. Let’s simplify the previous query with this SQL UNPIVOT syntax:
SELECT PlayerID, GameCount, GameType
FROM dbo.Players
UNPIVOT (
GameCount FOR GameType IN (
Win, Defeat, StandOff
)
) unpvtAs a result of the query execution, we get the following execution plan:
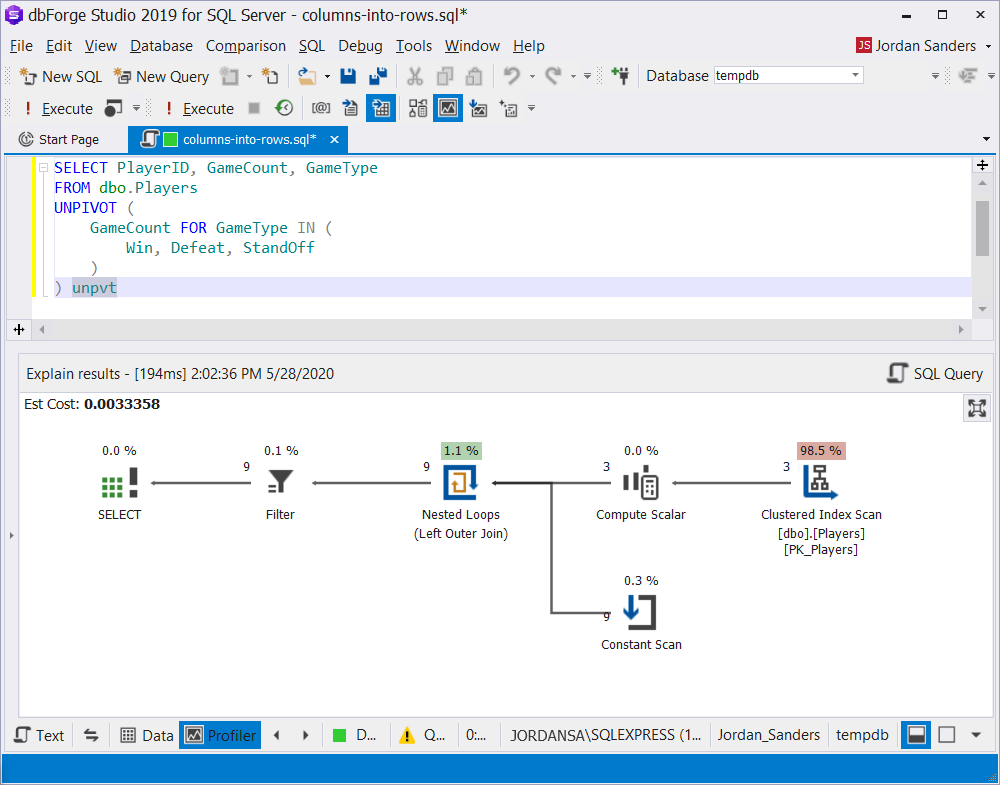
Additionally, to learn how to convert columns to rows in SQL with the UNPIVOT functionality, feel free to watch this video.
3. VALUES
One more point to consider is the possibility to accomplish the given task, which is to convert columns into rows, with the VALUES statement.
The query which uses the VALUES statement will look like this:
SELECT t.*
FROM dbo.Players
CROSS APPLY (
VALUES
(PlayerID, Win, 'Win')
, (PlayerID, Defeat, 'Defeat')
, (PlayerID, StandOff, 'StandOff')
) t(PlayerID, GameCount, GameType)Moreover, the execution plan will be simpler, comparing to UNPIVOT:
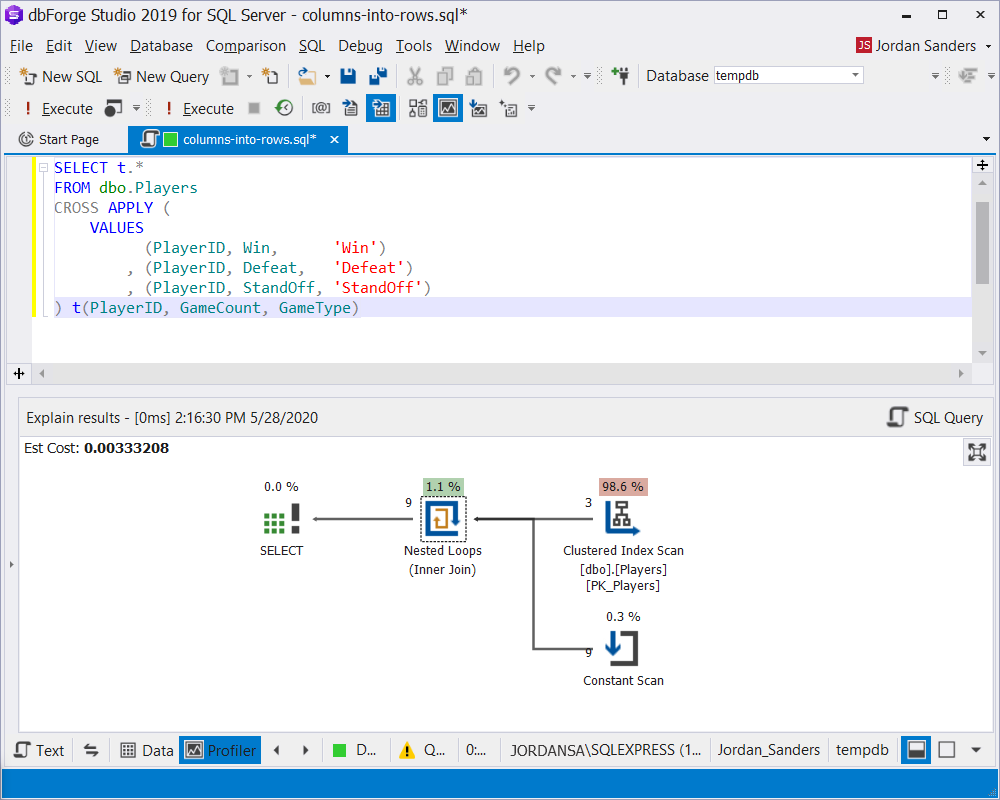
4. Dynamic SQL
Using the dynamic SQL allows creating a general-purpose query for any table on the condition that columns not included in the primary key have a compatible data-type between them:
DECLARE @table_name SYSNAME
SELECT @table_name = 'dbo.Players'
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = '
SELECT *
FROM ' + @table_name + '
UNPIVOT (
value FOR code IN (
' + STUFF((
SELECT ', [' + c.name + ']'
FROM sys.columns c WITH(NOLOCK)
LEFT JOIN (
SELECT i.[object_id], i.column_id
FROM sys.index_columns i WITH(NOLOCK)
WHERE i.index_id = 1
) i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id
WHERE c.[object_id] = OBJECT_ID(@table_name)
AND i.[object_id] IS NULL
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + '
)
) unpiv'
PRINT @SQL
EXEC sys.sp_executesql @SQL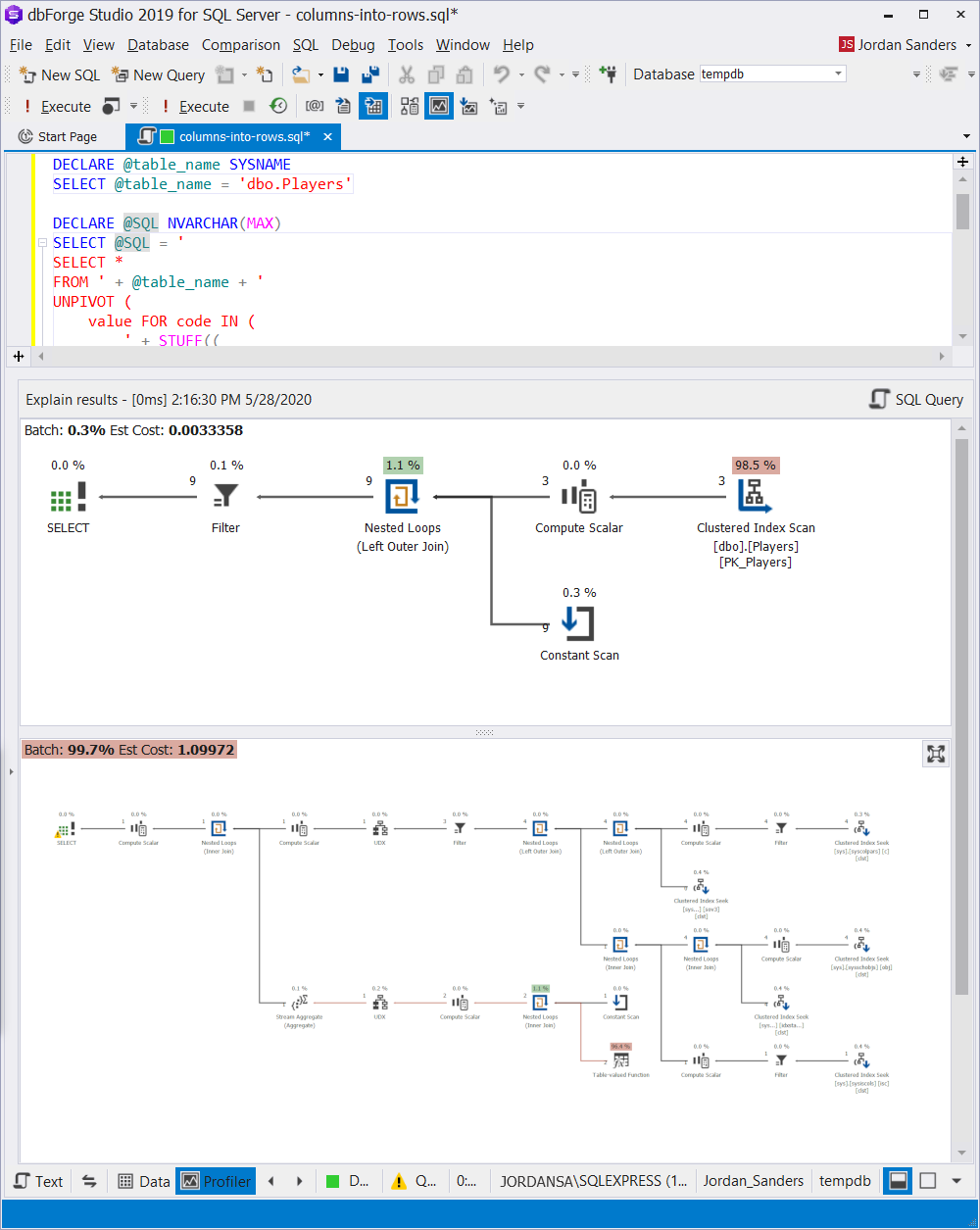
And the result is the following query:
SELECT *
FROM <table_name>
UNPIVOT (
value FOR code IN (<unpivot_column>)
) unpivThis method is not as fast because the automatic generation of the UNPIVOT query requires an additional reading from the system views and rows concatenation via the XML trick.
5. XML
A smarter way to execute dynamic UNPIVOT is by doing a little trick with XML:
SELECT
p.PlayerID
, GameCount = t.c.value('.', 'INT')
, GameType = t.c.value('local-name(.)', 'VARCHAR(10)')
FROM (
SELECT
PlayerID
, [XML] = (
SELECT Win, Defeat, StandOff
FOR XML RAW('f'), TYPE
)
FROM dbo.Players
) p
CROSS APPLY p.[XML].nodes('f/@*') t(c)In the query above, for each row SQL Server has generated a specified XML:
< f Column1="Value1" Column2="Value2" Column3="Value3" ... />Afterwards, the name of the attribute and its value are parsed. In most cases, the use of XML results in a slower execution plan. In our case, that is the price we pay for it to be universal.
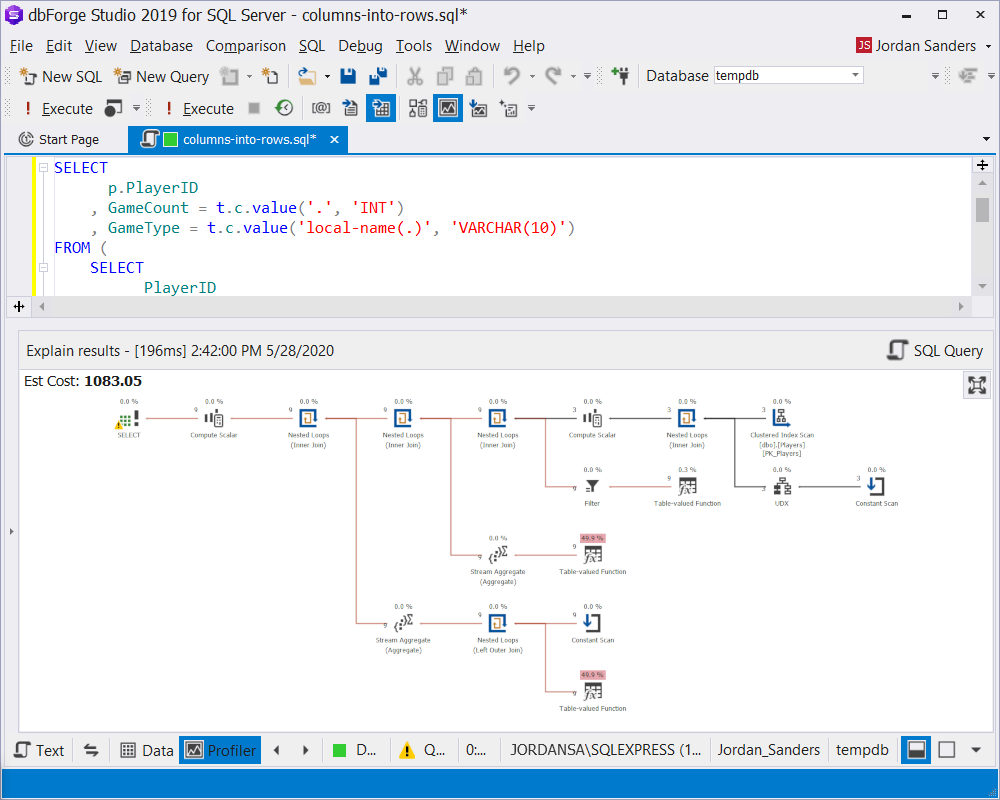
Let’s compare the results by executing the Compare Selected Results command:
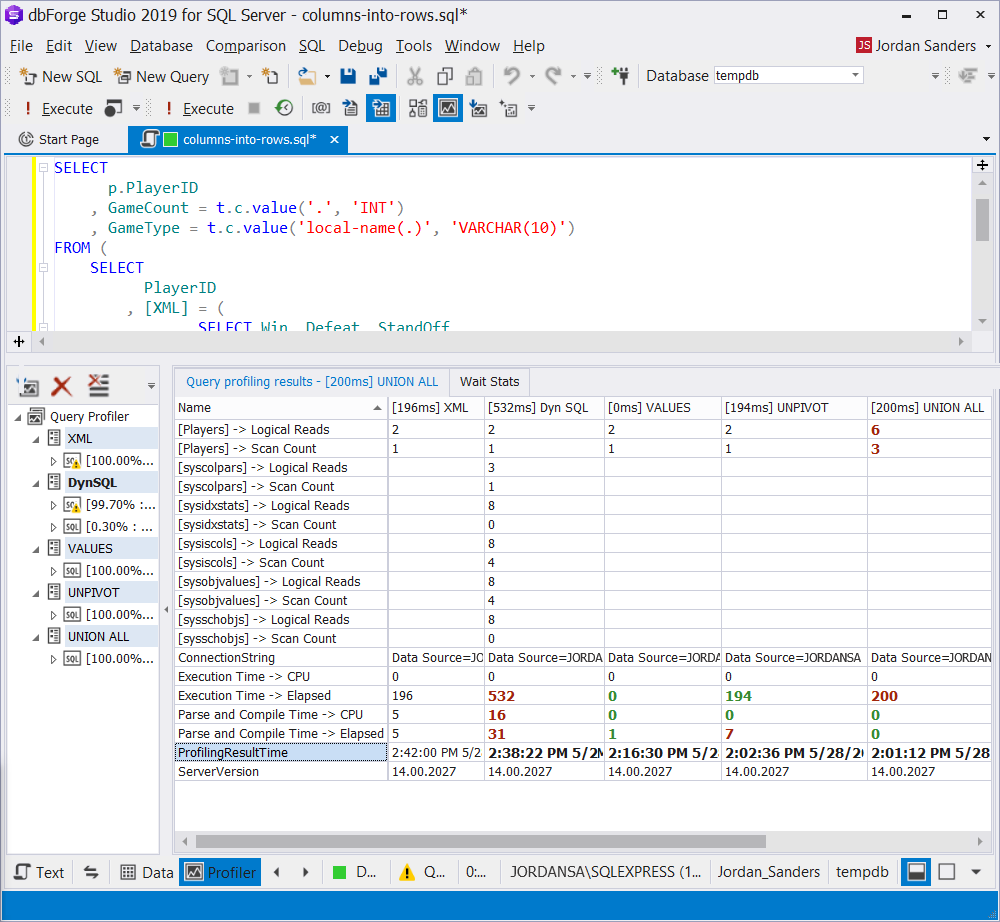
We have to say that there is no obvious difference in the speed of execution of the UNPIVOT and VALUES queries. This is valid for the cases when a simple transformation of columns into rows takes place.
Let’s examine another task, where we need to find the most frequent outcome of the game for each player.
We’ll try to do this task with the help of the UNPIVOT statement:
SELECT
PlayerID
, GameType = (
SELECT TOP 1 GameType
FROM dbo.Players
UNPIVOT (
GameCount FOR GameType IN (
Win, Defeat, StandOff
)
) unpvt
WHERE PlayerID = p.PlayerID
ORDER BY GameCount DESC
)
FROM dbo.Players pLearn the intricacies of subqueries syntax in detail.
In the execution plan it shows that the bottleneck is the multiple data reading and sorting, which is necessary for organizing the data rows:
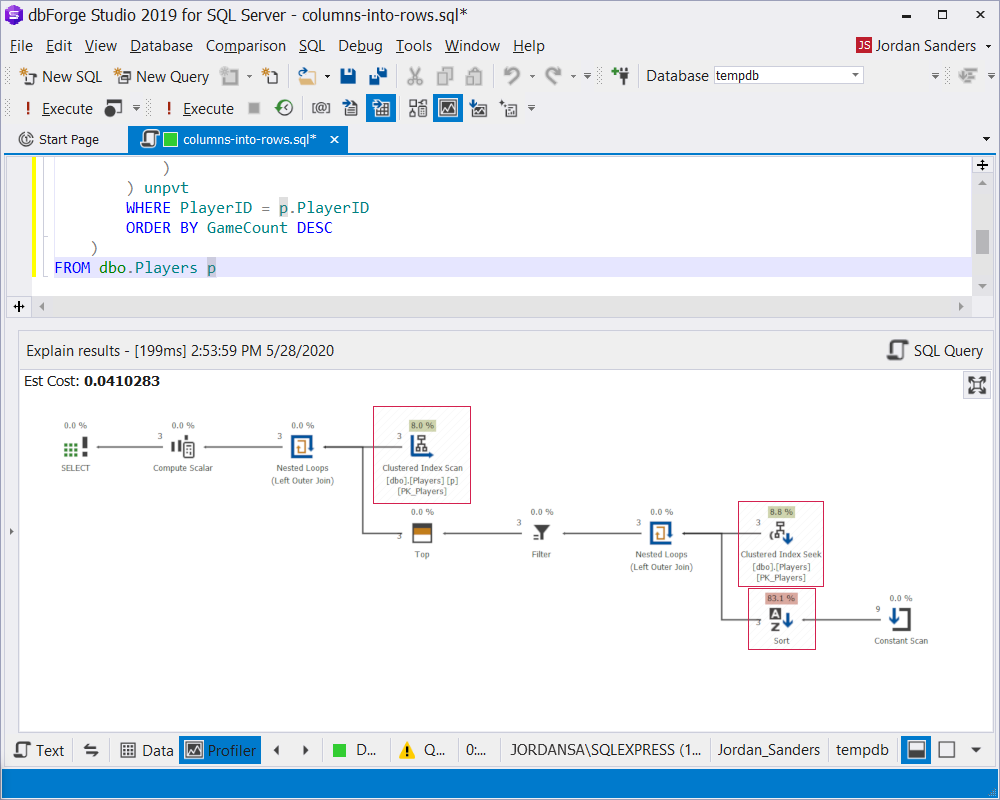
It’s easy to get rid of the multiple data reading if we remember that columns from the external query block can be used:
SELECT
p.PlayerID
, GameType = (
SELECT TOP 1 GameType
FROM (SELECT t = 1) t
UNPIVOT (
GameCount FOR GameType IN (
Win, Defeat, StandOff
)
) unpvt
ORDER BY GameCount DESC
)
FROM dbo.Players pMultiple reading of data was eliminated, but the most resource-consuming operation – sorting is still there:
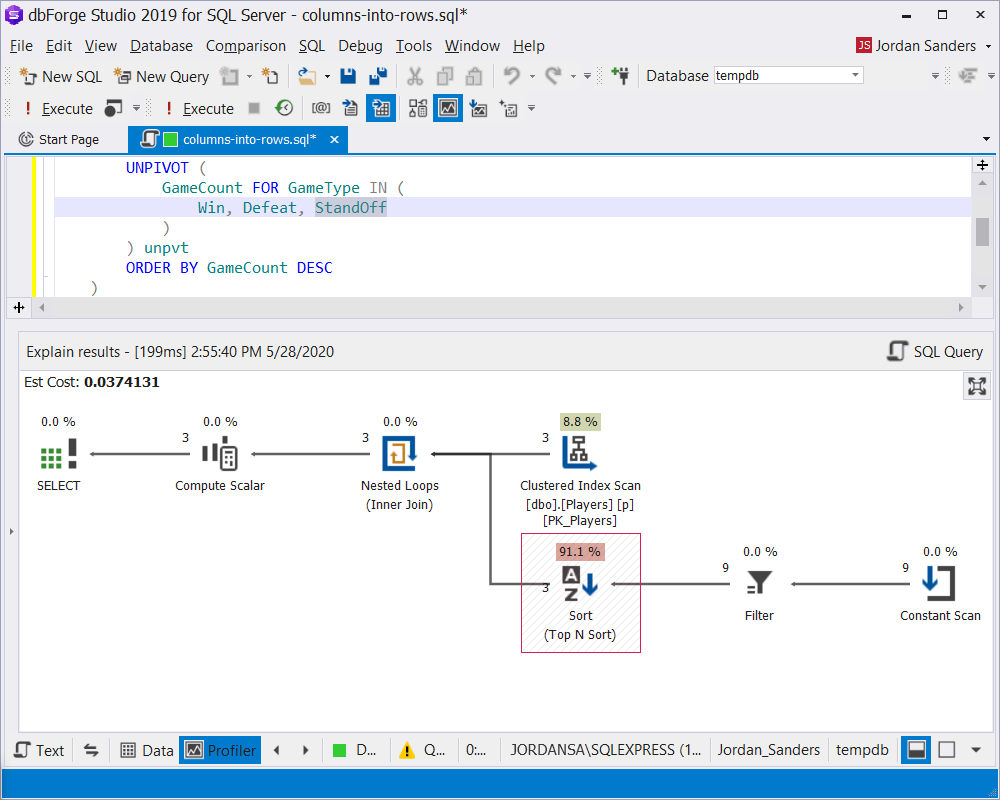
And that is how the VALUES statement behaves during this task:
SELECT
t.PlayerID
, GameType = (
SELECT TOP 1 GameType
FROM (
VALUES
(Win, 'Win')
, (Defeat, 'Defeat')
, (StandOff, 'StandOff')
) t (GameCount, GameType)
ORDER BY GameCount DESC
)
FROM dbo.Players tAs we’ve expected the plan was simplified, however sorting is still present:
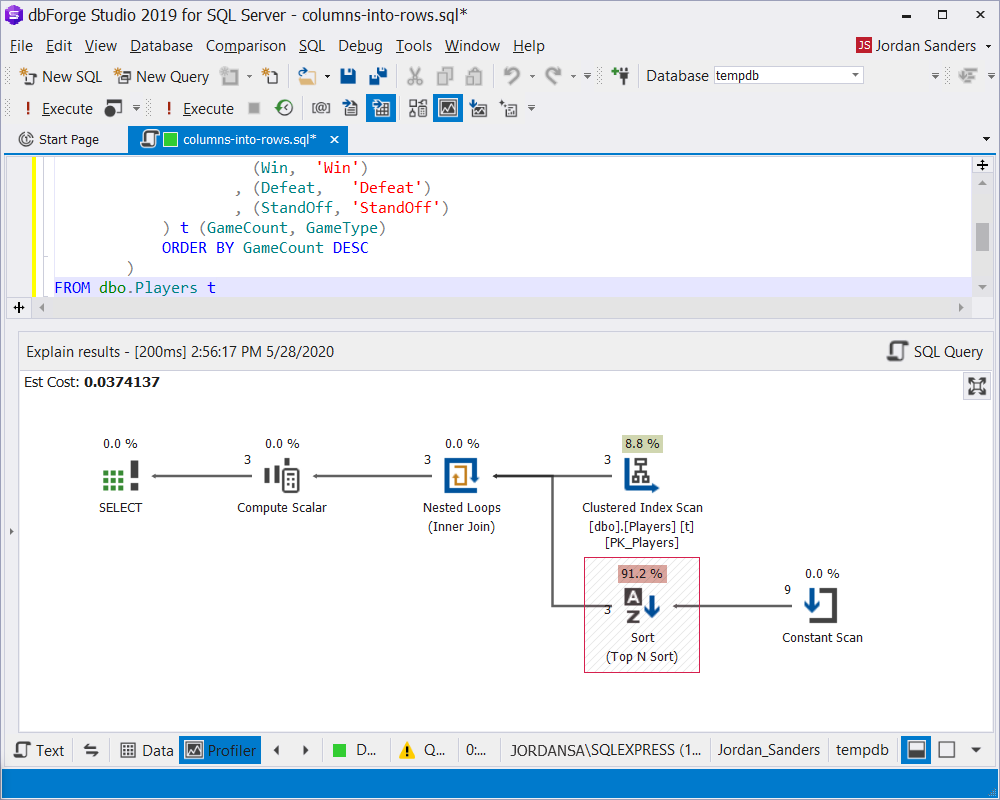
Let’s try to avoid sorting by using the aggregation function:
SELECT
t.PlayerID
, GameType = (
SELECT TOP 1 GameType
FROM (
VALUES
(Win, 'Win')
, (Defeat, 'Defeat')
, (StandOff, 'StandOff')
) t (GameCount, GameType)
WHERE GameCount = (
SELECT MAX(Value)
FROM (
VALUES (Win), (Defeat), (StandOff)
) t(Value)
)
)
FROM dbo.Players tNow the execution plan looks like this:
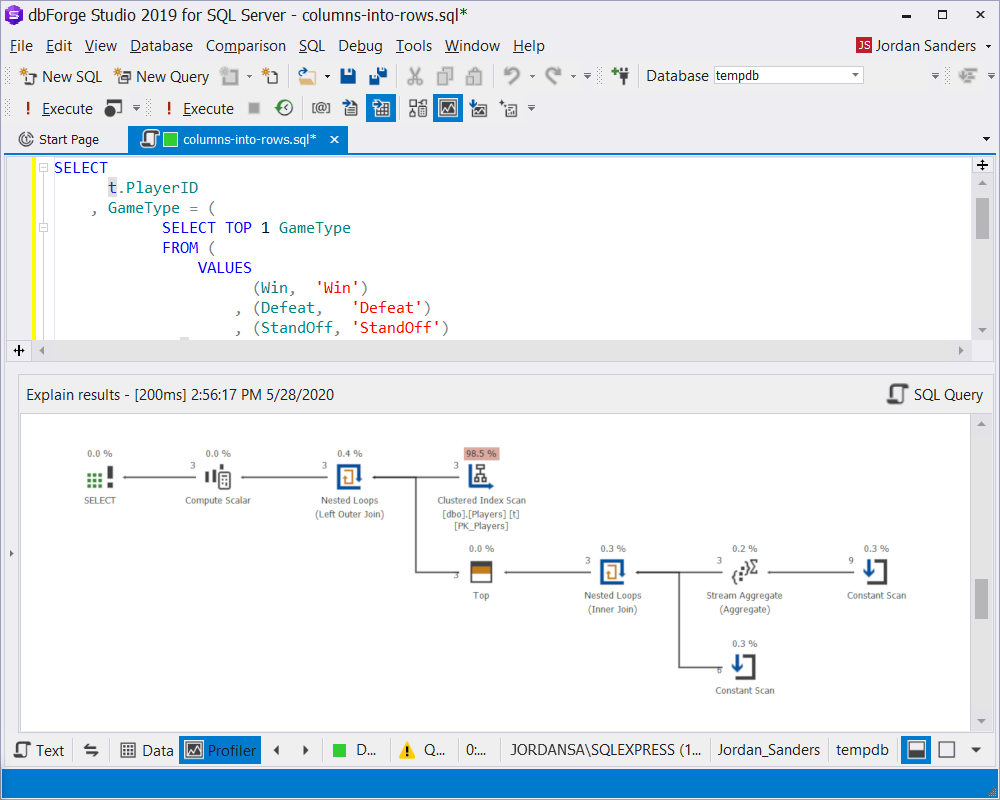
Hurrah! We have managed to get rid of sorting.
Conclusion
When we need to carry out a simple conversion of columns into rows in SQL Server, it is better to use UNPIVOT or VALUES structures.
If, after the conversion, the received data rows should be used for aggregation or sorting, then we had better use the VALUES structure, which, in most cases, results in more efficient execution plans.
For the tables where different structure types might occur, and the number of columns is unrestricted, it is recommended to use XML, which, unlike the dynamic SQL, can be used inside the table functions.
A step-by-step analysis of the execution plan with the help of SQL Profiler in dbForge Studio for SQL Server allows detecting bottlenecks in the query’s performance.
Hi Sergey Syrovatchenko , how do I use you example to reverse the unpivot method/s to go back to pivot ?
Please help me with the below query, I want column_Name to be displayed in rows and and Table_Name and database are grouped as all the column for a table will be displayed in single row:
IF OBJECT_ID(‘Tempdb.dbo.#temptbl’, ‘u’) IS NOT NULL
DROP TABLE #temptbl
Create Table #tempTbl
(
Database_Name nvarchar(100),
Table_Name nvarchar(100),
Column_Name nvarchar(100)
)
Insert Into #tempTbl
Select DB_Name() , sys.schemas.NAME + ‘.’ + sys.tables.NAME, sys.columns.name FROM sys.tables
INNER JOIN sys.schemas ON sys.tables.schema_id = sys.schemas.schema_id
Inner Join sys.columns On sys.tables.object_id = sys.columns.object_id
Go
Select * from #tempTbl
I’m having a Table called Test_Pivot which looks like
F_SN F_Title F_Data
1001 TRX RRN 301807460001.00
1001 DATE TIME 18:07 ,30/04/2015
1001 AUTH CODE
1001 AMOUNT 0.22
1001 SCHEME NAME SPAN
1001 RESULT DECLINED
1011 TRX RRN 301920050002.00
1011 DATE TIME 19:20 ,30/04/2015
1011 AUTH CODE
1011 AMOUNT 0.01
1011 SCHEME NAME MASTERCARD
1011 RESULT DECLINED
The output should look like this:
TRX RRN DATE TIME AUTH CODE AMOUNT SCHEME NAME RESULT
301807460001.00 18:07 ,30/04/2015 0.22 SPAN DECLINED
301920050002.00 19:20 ,30/04/2015 0.01 MASTERCARD DECLINED
Hi Ahmed,
Please clarify your question!
Thank you.
Hi,
How did you get the query profiler results shown in image 06? What tool did you use?
Thanks for the comment. This is a built-in feature in dbForge Studio profiler
Can dbForge Studio profile monitor the query’s tempdb and memory usage?
Hi Kai, you mean spills into tempdb? If yes, in this case we have identical functionality as in SSMS. In future it’s planned to expand this functionality.
I tried 2 differents way with using UNPIVOT and CROSS APPLY with VALUES and my results on 41,894,370 of rows is UNPIVOT is better but not very much
Using UNPIVOT 31:38 minutes
Using CROSS APPLY with VALUES 33:26 minutes
CROSS APPLY spent 3 minutes more than UNPIVOT
My SQL is : Microsoft SQL Server Enterprise (64-bit) version : 11.0.5532.0