
In our daily work with data, we often encounter situations where we don’t have access to all the necessary information. Fortunately, there are methods to fill in the missing pieces and gather sufficient valuable data to make well-informed decisions. One of them involves a mathematical operation of interpolation. When it comes to SQL databases, we can utilize interpolation functions provided by T-SQL. In this article, we will explore SQL functions for approximate interpolation in SQL Server.

Contents
- Understanding interpolation
- SQL functions for approximate interpolation
- Deep dive into APPROX_PERCENTILE_CONT
- Deep dive into APPROX_PERCENTILE_DISC
- Comparing APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC
- Conclusion
Understanding interpolation
Interpolation is a mathematical operation of determining a value from other existing values. More precisely, it stands for determining/inserting a value between two other values. In data science, interpolation mostly refers to the operation of calculating a specific unknown value based on the known values in the range of a given data set.
The accuracy of interpolation results relies on the density and quality of the existing data points, as well as the smoothness and continuity of the known value range. Simply put, having more data leads to more precise interpolation calculations.
However, it’s important to note that attempting to predict values beyond the known range is a separate operation known as extrapolation. It should not be confused with interpolation and should be employed in distinct scenarios.
Interpolation proves valuable for making predictions with limited or incomplete data. It is applied widely across various industries. While it may not guarantee absolute accuracy, modern methods enable interpolation to provide the necessary precision for proper data-driven decisions.
SQL functions for approximate interpolation
SQL (Structured Query Language that allows us to interact with databases), offers some functions – predefined operations that we can use to perform specific calculations or to manipulate data. Among these functions, we find the approximate interpolation functions. In particular, these functions are essential in dealing with data in SQL Server databases.
PERCENTILE_CONT and PERCENTILE_DISC are well-known T-SQL functions used to compute percentiles – they have been introduced in SQL Server 2005, and have been available in all SQL Server versions since.
These functions are accurate, but they have their downsides too. First, computing precise percentiles requires a lot of resources and affects the overall performance. Besides, both PERCENTILE_CONT and PERCENTILE_DISC are window functions, and they aren’t suitable for computing percentiles only once per group, which is a common case.
In SQL Server 2022, an alternative has been introduced – the approximate percentile functions APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC to compute percentiles as approximate ones. Compared to the previous options, new functions are significantly faster and less resource-consuming. On the other hand, these functions deliver approximate values which may not be accurate. However, Microsoft claims the error margin is 1.33% only, so, they are reliable tools for the purpose of computing percentiles.
Let us delve deeper into these new APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC functions.
Deep dive into APPROX_PERCENTILE_CONT
The APPROX_PERCENTILE_CONT function calculates an approximate interpolated value from the set of given values in a group. The calculations are based on percentile value and sort specification. The result is interpolated, which means the returned value may not match any of those values already present in the dataset.
As this function brings approximate results, it may not deliver 100% accurate results either. Still, due to its capacity to handle huge datasets, APPROX_PERCENTILE_CONT can provide acceptable results quickly.
APPROX_PERCENTILE_CONT is widely used in data analysis. Percentiles calculated with its help let us understand how the data is distributed. For instance, the well-known “median” metric is the 50th percentile. The median divides the data into two halves, where one-half of all values are above the median, and another half is below the median. The same goes for other percentiles, such as the 80th percentile – it defines the value that is above 80% of the data.
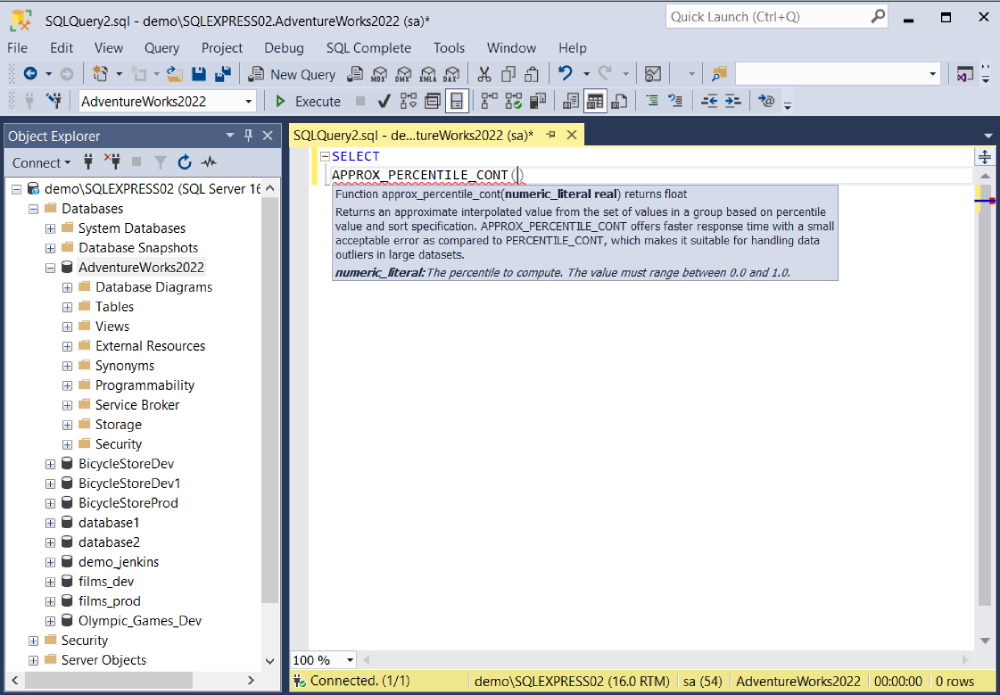
The syntax of APPROX_PERCENTILE_CONT is as follows:
APPROX_PERCENTILE_CONT (numeric_literal)
WITHIN GROUP (ORDER BY order_by_expression);numeric_literal is the required percentile to calculate. Important! This value must be between 0.0 and 1.0.
order_by_expression is the column with the list of numeric values for the percentile calculation. The expression must be of the exact or approximate numeric type – int, bigint, smallint, tinyint, numeric, bit, decimal, smallmoney, money, float, or real. Other data types aren’t allowed. The function ignores NULLs in the data sets.
Now, let’s examine an example. Note that we are using SQL Server Management Studio (SSMS) augmented with the dbForge SQL Complete add-in – this popular integrated coding assistant now supports both the APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC functions.
Assume we need to check the medium hourly rate in the company. To achieve this, we employ the APPROX_PERCENTILE_CONT function:
SELECT
APPROX_PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Rate) AS Medium_Rate
FROM HumanResources.EmployeePayHistory eph;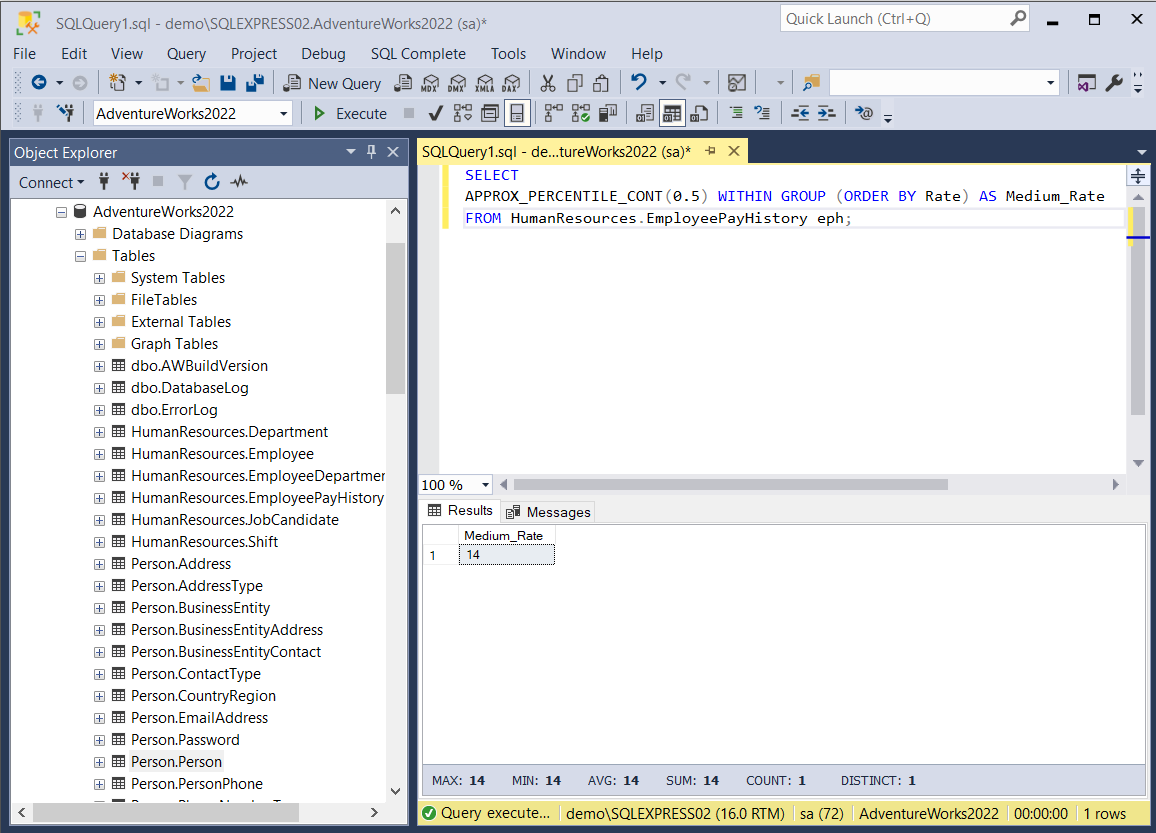
Percentiles are helpful analytical means and can be weighty arguments in decision-making. In fact, plenty of business metrics involve percentiles. That’s why APPROX_PERCENTILE_CONT with its speedy performance and ease of use is beneficial in so many businesses.
Deep dive into APPROX_PERCENTILE_DISC
APPROXIMATE PERCENTILE_DISC is another function introduced in SQL Server 2022 that counts percentile values. However, it does not count a new value but returns one of the elements from the data set given instead.
As in the case of APPROX_PERCENTILE_CONT, the approximation aspect means that this function can run much faster than the “old” PERCENTILE_DISC, and it consumes fewer resources, but the results brought it may not be 100% accurate. Still, APPROX_PERCENTILE_DISC is precise enough to be employed in calculations, especially for large data sets.
The syntax of APPROX_PERCENTILE_DISC is as follows:
APPROX_PERCENTILE_DISC (numeric_literal)
WITHIN GROUP (ORDER BY order_by_expression);As you can see, the syntax is similar to the one we examined in the previous section. Similar to APPROX_PERCENTILE_CONT, the APPROX_PERCENTILE_DISC function includes the following parameters:
numeric_literal is the percentile we need to calculate. In the query, we use the range between 0.0 and 1.0 for the calculations (0.1 for the 10th percentile, 0.2 for the 20th percentile, etc.)
order_by_expression is the list of values used to calculate the percentile. The values must be of the numeric data types only – int, bigint, smallint, tinyint, bit, smallmoney, and money. Decimal and float data types are not allowed. Also, the function ignores NULLs.
Take a look at the example below. Our objective is to identify the median value and quartiles higher and lower than the median value for the orders. Here we prefer getting distinct values within the existing range of data points, so we use the APPROX_PERCENTILE_DISC function:
SELECT
APPROX_PERCENTILE_DISC (0.25) WITHIN GROUP (ORDER BY SubTotal) AS Quartile_1,
APPROX_PERCENTILE_DISC (0.5) WITHIN GROUP (ORDER BY SubTotal) AS Median,
APPROX_PERCENTILE_DISC (0.75) WITHIN GROUP (ORDER BY SubTotal) AS Quartile_3
FROM
Sales.SalesOrderHeader;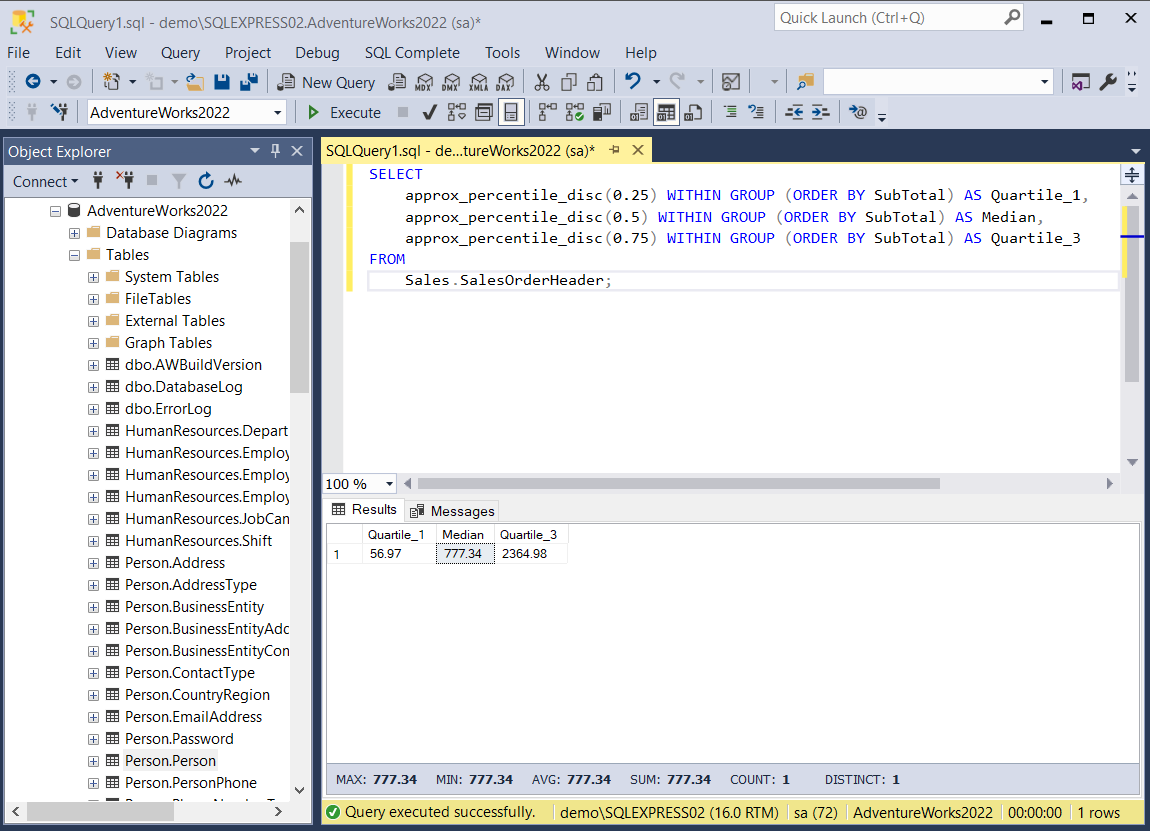
The performance of APPROX_PERCENTILE_DISC brings results that are accurate enough to be used in decision-making. At the same time, this function performs much faster. Thus, it is a proper substitute for the PERCENTILE_DISC function in calculations.
Comparing APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC
Comparing APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC
APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC are newer aggregate functions in Microsoft SQL Server, though they’ve existed in other database systems like PostgreSQL and Oracle for some time. While traditional examples of aggregate functions in SQL include SUM, AVG, MIN, and MAX, these two percentile functions expand the toolkit by enabling approximate distribution analysis across large datasets.
Both functions calculate percentiles over a defined range of values, working directly on the input data and returning estimated results without user-defined precision. Despite their similarities, key differences determine when to use one over the other.
The table below outlines their distinct features and ideal use cases.
APPROX_PERCENTILE_CONT vs. APPROX_PERCENTILE_DISC
| APPROX_PERCENTILE_CONT | APPROX_PERCENTILE_DISC | |
| Data type | Continuous data. The function accepts exact or approximate numeric type to calculate percentile. | Discrete data. The function accepts only numeric data types to calculate the percentile value. |
| Interpolation | Uses interpolation to calculate the percentile value that falls between two data points – that value may not exist in the input data set initially. | Does not use interpolation. It returns an existing value from the data set – the smallest value that is higher or equal to the desired percentile. |
| Use cases | Is used for the continuous distribution data where an interpolated result is needed. | Is used for the discrete data where an actual data point result is required. |
In general, the usage of APPROX_PERCENTILE_CONT or APPROX_PERCENTILE_DISC depends on the nature of the data and the specific requirements. The most essential factor is whether you need an exact value or an interpolated value. If your goals suggest interpolation – then refer to APPROX_PERCENTILE_CONT. Otherwise, stick with APPROX_PERCENTILE_DISC.
Conclusion
The APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC functions are powerful tools for statistical and data analysis. Despite being approximations, they deliver high accuracy, sufficient for real-world applications, and are widely used across various domains — from finance to healthcare, from market research to engineering — enabling data analysts and decision-makers to make appropriate conclusions and predictions.
Starting with SQL Server 2022, APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC are fully supported by the database management system. You can utilize them when querying your databases, enabling faster and more efficient retrieval of necessary information.
Furthermore, support for these functions has been ensured in the latest version of SQL Complete. If you employ this add-in to enhance the capabilities of SSMS, you can rest assured that you’ll have access to APPROX_PERCENTILE_CONT and APPROX_PERCENTILE_DISC, along with the myriad features that SQL Complete offers to streamline your SQL development workflow.
If you are already using SQL Complete, make sure to update it to the latest version, which is free of charge. If you are considering using it, you can take advantage of a fully functional trial of SQL Complete, available for 14 days. This trial allows you to thoroughly test all the tool’s capabilities and evaluate its suitability for your needs.