In this article, we will discuss some pitfalls related to XML and XQuery that may lead to performance issues.
The following code will generate a test XML file:
USE AdventureWorks2012
GO
IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL
DROP TABLE ##temp
GO
SELECT val = (
SELECT
[@obj_id] = o.[object_id]
, [@obj_name] = o.name
, [@sch_name] = s.name
, (
SELECT i.name, i.column_id, i.user_type_id, i.is_nullable, i.is_identity
FROM sys.all_columns i
WHERE i.[object_id] = o.[object_id]
FOR XML AUTO, TYPE
)
FROM sys.all_objects o
JOIN sys.schemas s ON o.[schema_id] = s.[schema_id]
WHERE o.[type] IN ('U', 'V')
FOR XML PATH('obj'), ROOT('objects')
)
INTO ##temp
DECLARE @sql NVARCHAR(4000) = 'bcp "SELECT * FROM ##temp" queryout "D:\sample.xml" -S ' + @@servername + ' -T -w -r -t'
EXEC sys.xp_cmdshell @sql
IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL
DROP TABLE ##temp
To enable xp_cmdshell, execute the following code:
EXEC sp_configure 'show advanced options', 1 GO RECONFIGURE GO EXEC sp_configure 'xp_cmdshell', 1 GO RECONFIGURE GO
Eventually, we will have a XML file with the following structure:
objects
obj obj_id="245575913" obj_name="DatabaseLog" sch_name="dbo"
i name="DatabaseLogID" column_id="1" user_type_id="56" is_nullable="0" is_identity="1"
i name="PostTime" column_id="2" user_type_id="61" is_nullable="0" is_identity="0"
i name="DatabaseUser" column_id="3" user_type_id="256" is_nullable="0" is_identity="0"
i name="Event" column_id="4" user_type_id="256" is_nullable="0" is_identity="0"
i name="Schema" column_id="5" user_type_id="256" is_nullable="1" is_identity="0"
i name="Object" column_id="6" user_type_id="256" is_nullable="1" is_identity="0"
i name="TSQL" column_id="7" user_type_id="231" is_nullable="0" is_identity="0"
i name="XmlEvent" column_id="8" user_type_id="241" is_nullable="0" is_identity="0"
/obj
...
obj obj_id="1237579447" obj_name="Employee" sch_name="HumanResources"
i name="BusinessEntityID" column_id="1" user_type_id="56" is_nullable="0" is_identity="0"
i name="NationalIDNumber" column_id="2" user_type_id="231" is_nullable="0" is_identity="0"
i name="LoginID" column_id="3" user_type_id="231" is_nullable="0" is_identity="0"
i name="OrganizationNode" column_id="4" user_type_id="128" is_nullable="1" is_identity="0"
i name="OrganizationLevel" column_id="5" user_type_id="52" is_nullable="1" is_identity="0"
i name="JobTitle" column_id="6" user_type_id="231" is_nullable="0" is_identity="0"
i name="BirthDate" column_id="7" user_type_id="40" is_nullable="0" is_identity="0"
...
/obj
...
/objects
Let’s do some tests. What is the most efficient way to download from XML file? IMHO, we can use OPENROWSET:
DECLARE @xml XML SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x SELECT @xml
There is a subtle aspect. The combination of the loading and parsing operations decreases performance. For example, we need to get obj_id values from our test XML file:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@obj_id', 'INT')
FROM cte
CROSS APPLY x.nodes('objects/obj') t(c)
The query takes too much time on my PC:
(495 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 20788, ..., lob logical reads 7817781, ..., lob read-ahead reads 1022368. SQL Server Execution Times: CPU time = 53688 ms, elapsed time = 53911 ms.
Now let’s perform loading and parsing separately:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
SELECT t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj') t(c)
The results are much better in this case:
(1 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 7, ..., lob logical reads 2691, ..., lob read-ahead reads 344. SQL Server Execution Times: CPU time = 15 ms, elapsed time = 51 ms. (495 row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 125 ms.
What was the problem? To answer this question, we need to compare the following execution plans:
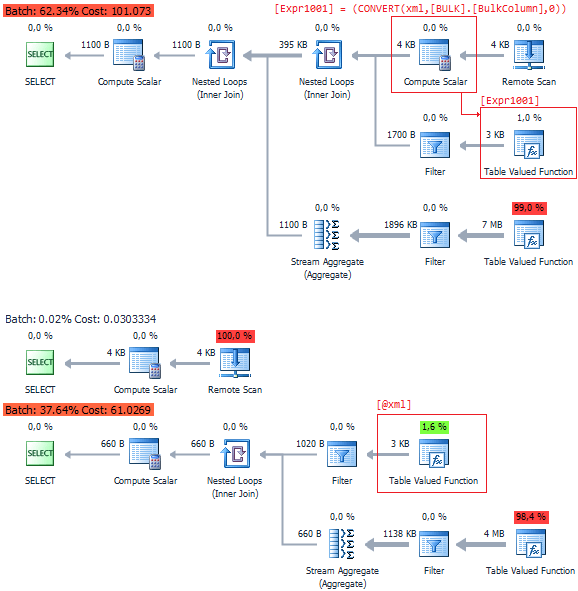
As it turned out, the problem lies in the conversion of types. Thus, you need to pass a parameter to the nodes function in the XML type.
Consider a situation when we need to filter results while parsing. Remember that SQL Server does not optimize function calls to work with XML.
To demonstrate this, I execute the following query. The value function will be executed twice.
SELECT t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj') t(c)
WHERE t.c.value('@obj_id', 'INT') < 0
(404 row(s) affected) SQL Server Execution Times: CPU time = 116 ms, elapsed time = 120 ms.
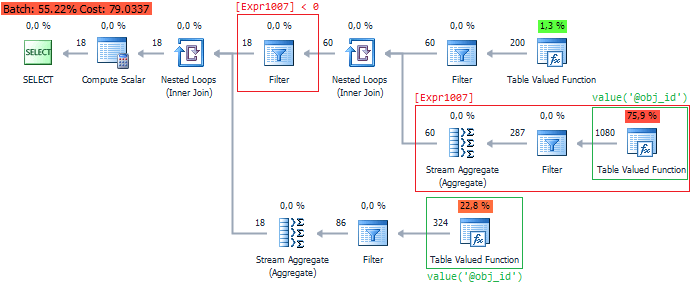
This nuance may reduce performance, so it is recommended to reduce the function calls:
SELECT *
FROM (
SELECT id = t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj') t(c)
) t
WHERE t.id < 0
(404 row(s) affected) SQL Server Execution Times: CPU time = 62 ms, elapsed time = 74 ms.
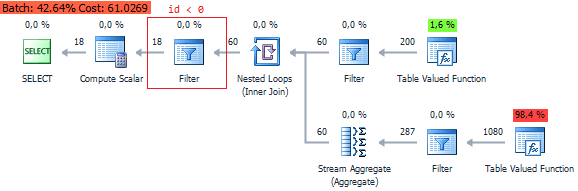
Alternatively, we can filter the following way:
SELECT t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj[@obj_id < 0]') t(c)
(404 row(s) affected) SQL Server Execution Times: CPU time = 110 ms, elapsed time = 119 ms.
There is no significant benefit. Although QueryCost says it all.
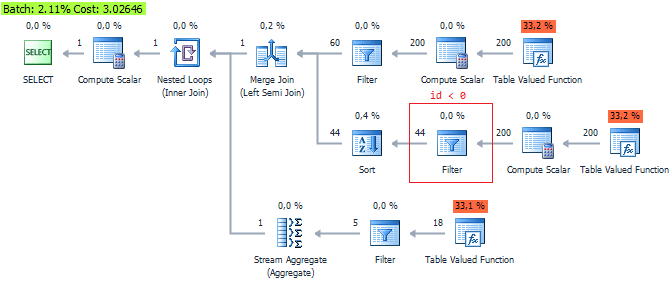
As we can see, the third variant is the most effective… This is an additional argument to use QueryCost that is only internal assessment.
There is one important issue while parsing XML. Execute the following query:
SELECT
t.c.value('../@obj_name', 'SYSNAME')
, t.c.value('@name', 'SYSNAME')
FROM @xml.nodes('objects/obj/*') t(c)
And analyze the execution time:
(5273 row(s) affected) SQL Server Execution Times: CPU time = 66578 ms, elapsed time = 66714 ms.
Why it happens? SQL Server has some problems with reading the parent nodes from child nodes.
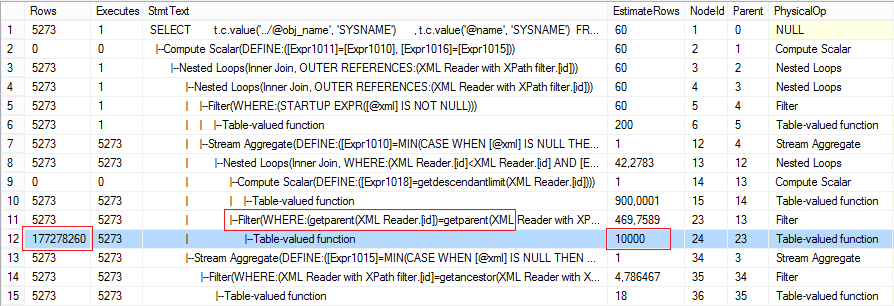
In this case we need to start reading from the parent nodes and move to child nodes with help of CROSS/OUTER APPLY:
SELECT
t.c.value('@obj_name', 'SYSNAME')
, t2.c2.value('@name', 'SYSNAME')
FROM @xml.nodes('objects/obj') t(c)
CROSS APPLY t.c.nodes('*') t2(c2)
(5273 row(s) affected) SQL Server Execution Times: CPU time = 156 ms, elapsed time = 184 ms.
Another interesting situation is when we need to look at two levels above. I didn’t get any problems in this case:
USE AdventureWorks2012
GO
DECLARE @xml XML
SELECT @xml = (
SELECT
[@obj_name] = o.name
, [columns] = (
SELECT i.name
FROM sys.all_columns i
WHERE i.[object_id] = o.[object_id]
FOR XML AUTO, TYPE
)
FROM sys.all_objects o
WHERE o.[type] IN ('U', 'V')
FOR XML PATH('obj')
)
SELECT
t.c.value('../../@obj_name', 'SYSNAME')
, t.c.value('@name', 'SYSNAME')
FROM @xml.nodes('obj/columns/*') t(c)
Additionally, OPENXML doesn’t have any problems with reading parent elements:
DECLARE
@xml XML
, @idoc INT
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
EXEC sys.sp_xml_preparedocument @idoc OUTPUT, @xml
SELECT *
FROM OPENXML(@idoc, '/objects/obj/*')
WITH (
name SYSNAME '../@obj_name',
col SYSNAME '@name'
)
EXEC sys.sp_xml_removedocument @idoc
(5273 row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 137 ms.
You don’t have to think that OPENXML has clear advantages over XQuery. There are enough issues with OPENXML. For instance, if you forget to call sp_xml_removedocument, it may result in memory leaks.
All tests were performed on SQL Server 2012 SP3 (11.00.6020).
Execution plans were taken with help of dbForge Studio.
