
Vector databases are rapidly becoming the cornerstone of modern AI applications—and for good reasons.
If you are very familiar with AI technologies like ChatGPT, you have already seen what vectors can do. When you ask ChatGPT a question, such as, “What’s the weather like today?” to provide an accurate answer, the AI would first convert your question into a vector, which implies a series of numbers that capture the intent and context of your sentence. The cool part? Similar meanings will have similar vectors, which is how the AI knows that “What’s the weather like today?” is close in meaning to “Will it rain today?”
Vectors let computers understand not just what you said, but what you meant. This is precisely why storing and searching these vectors in a special kind of database—a vector database—is becoming so important in the AI world.
In this guide, you will learn about what a vector database is, how it works, why it is important, its key features, its architecture, and a lot more.
Let’s get right into it.
Table of contents- What is a vector database?
- How vector databases work
- Why are vector databases important today?
- Key features of vector databases
- Vector database architecture
- Vector databases vs. traditional databases
- Popular vector database systems
- Vector database in .NET
- Conclusion
- Frequently asked questions
What is a vector database?
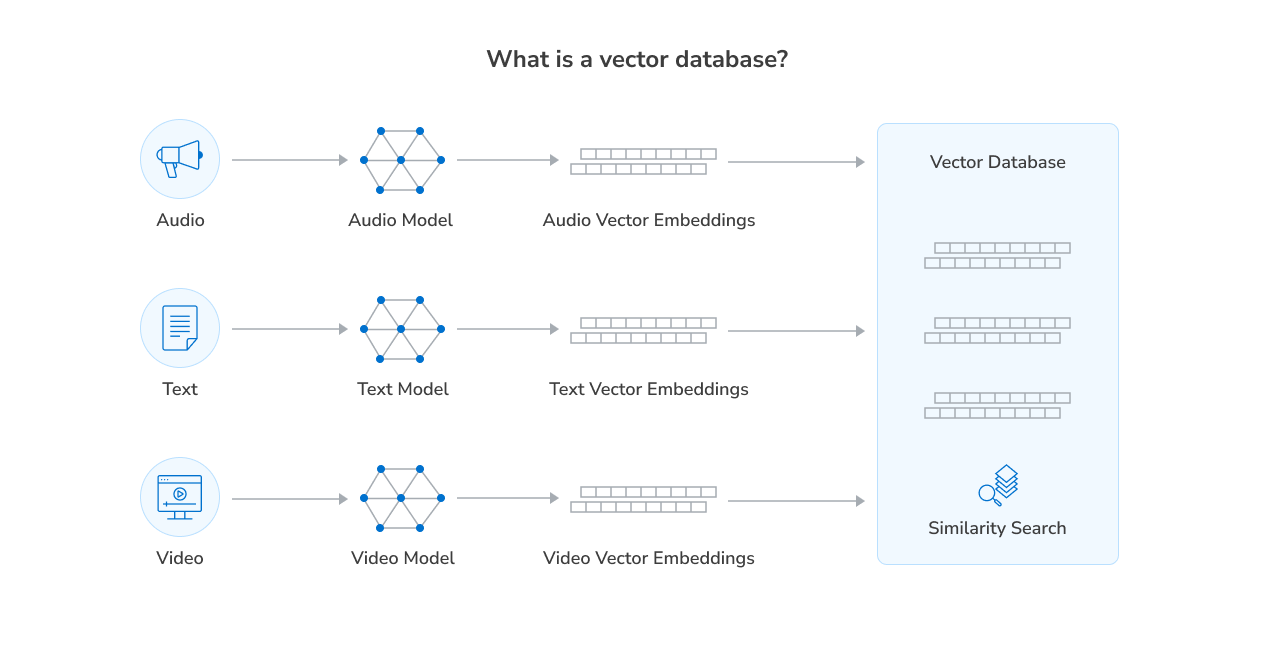
According to Oracle, a “vector database is any database that can natively store and manage vector embeddings and handle the unstructured data they describe, such as documents, images, video, or audio.” This means a vector database is designed to store, index, and search vector embeddings. Vector embeddings are numerical representations of data like text, images, audio, or video. This numerical representation is referred to as a vector.
Vectors are long lists of numbers containing hundreds or even thousands of values, which helps AI and machine learning (ML) to understand the intent behind different types of searches. Unlike traditional relational databases that organize data into structured rows and columns (like a spreadsheet) or NoSQL databases that store unstructured or semi-structured data (like JSON or documents), vector databases are optimized for similarity search. They use algorithms like Approximate Nearest Neighbor (ANN) to perform fast and efficient searches across millions or even billions of high-dimensional vectors.
How vector databases work
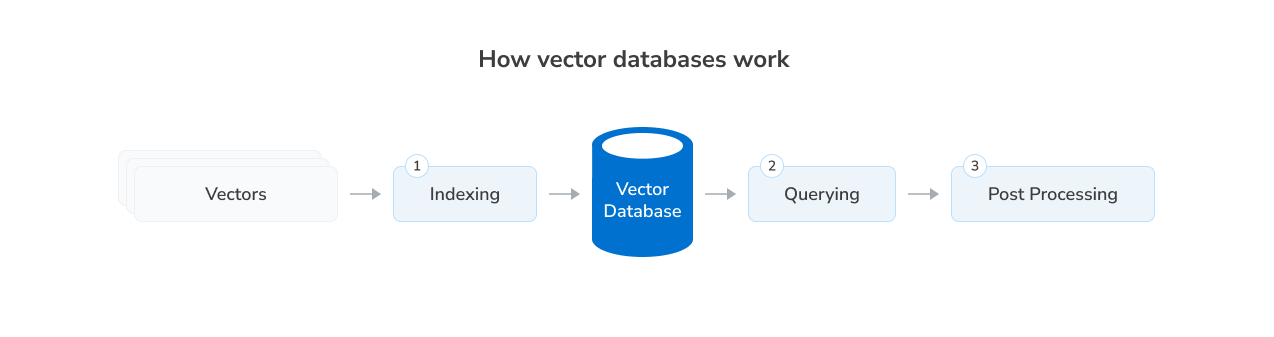
How do vector databases work, and what makes them efficient in today’s database applications? Let’s break this down.
Vector databases are built to perform similarity searches between data. They use a special kind of algorithm to index vectors by how close they are in meaning to other vectors. For instance, when you enter a search query on ChatGPT, the AI system converts your question into a vector. Then the vector database compares the converted vector with the ones it has using similarity metrics like any of the following:
- Cosine similarity: Vector databases use this metric to measure the angle between two vectors to see how close their directions are. This method is particularly useful for comparing two texts that have different keywords but convey the same meaning.
- Euclidean distance: This metric is used to measure the straight-line distance between two vectors. It is ideal for comparing data when the real size or magnitude is important, for example, sensor or image recognition data.
To fast-track this process, vector databases often use ANN algorithms, which find the most similar vectors without having to compare every single one in the database. This technique enables the database to handle high-end tasks like semantic search and personalized recommendations and deliver swift results based on meaning, not just keywords.
Why are vector databases important today?
Today’s AI and machine learning (ML) are evolving at an incredible pace, and vector embedding databases play a key role in the efficiency of these technologies. Here’s how.
Generally, AI and machine learning rely on understanding data in a meaningful way, and this is one of the shortcomings of the traditional database. Traditional databases match data with exact words and numbers, which is not how modern applications work. Vector databases, on the other hand, are purpose-built to handle high-dimensional vector data and perform fast and accurate similarity searches. This functionality makes them the perfect match for the demands of AI and ML technologies.
Below are reasons vector databases stand out in today’s technology.
The rise of vector embeddings in AI
A vector database is the storehouse for the vector embeddings that help modern AI models capture the meaning or features of raw data, especially in fields like natural language processing (NLP) and computer vision.
- In NLP, vector embeddings allow AI to understand that “mobile phone” and “smartphone” are closely related, even if the exact words don’t match.
- In computer vision, these embeddings represent visual features of images, enabling systems to identify similar pictures or detect objects.
Vector embeddings are what make vector search possible. They enable the AI and ML technologies to compare vectors and retrieve results that are semantically similar, not just identical. Without vector databases to store and search through these embeddings efficiently, many AI applications simply wouldn’t scale.
Role in semantic search and recommendations
Vector databases provide answers to search questions using meaning-based search, or semantic search. In a vector database-powered system, when you enter a query like “What are the eco-friendly laptops?” The database can return results like “green tech devices,” even if the words don’t match exactly.
Furthermore, vector databases can suggest products or other content based on user behavior and preferences. For instance, when a user interacts with an app, like browsing products or watching videos, the system turns these activities into embeddings. The vector database then compares the user’s activity embedding with the other embeddings it already has, like other products or videos. Then use this comparison to determine the ones that are most similar to the user’s interaction. This activity is known as a “nearest neighbor” and is efficient for making more personalized recommendations for users, especially in e-commerce applications.
Comparison with traditional databases
Traditional relational and NoSQL databases are excellent for structured or document-based data and for retrieving exact matches. But they fall short when it comes to similarity-based search, especially with high-dimensional vector data. As a result, performing nearest neighbor searches over large datasets using conventional SQL queries is slow, inefficient, and not scalable.
A vector store database, on the other hand, uses advanced indexing techniques and ANN algorithms to perform fast and scalable similarity searches across billions of vectors. This makes them a critical component in modern AI/ML pipelines.
Key features of vector databases
Vector databases are not just another type of database; they are purpose-built to handle the demands of AI-powered similarity search. Below are the key features that make them a go-to in modern applications.
Similarity search support
Similarity search is the core feature of any vector database. This functionality implies finding items that are close to a query vector in terms of meaning or features. To perform this, the vector database uses any of the following algorithms and methods:
- Approximate Nearest Neighbor (ANN) algorithms: This includes Hierarchical Navigable Small World (HNSW), Inverted File Index (IVF), or Product Quantization (PQ). They offer fast, scalable search and return results that are close enough to the intent of the users and are ideal for real-time applications where speed matters more than absolute precision.
- Brute-force search methods: These methods calculate the exact distance between vectors. Although the process can be slower and more resource-intensive, the methods are very useful when 100% accuracy is required or when the dataset is small.
Scalability and performance
Vector databases are designed to handle billions of vectors while still delivering low-latency results. To achieve this, the database uses the following index methods:
- Advanced indexing structures (like hierarchical graphs or inverted files) that reduce the number of vectors to compare during similarity search.
- Distributed architecture, which enables horizontal scaling across multiple servers or nodes.
- In-memory processing and batch query optimization, which improve response times even under heavy workloads.
These methods empower vector databases to deliver millisecond-level search speeds, even across massive datasets, making them ideal for real-world applications like e-commerce recommendations, real-time chatbots, or fraud detection systems.
Integration with AI/ML pipelines
Another major strength of vector store databases is their smooth integration with AI and ML workflows. For example:
- Embedding models from frameworks like TensorFlow, PyTorch, Hugging Face, or OpenAI.
- Inference engines that allow real-time vector generation and indexing.
- Data pipelines that continuously feed new data and embeddings into the system.
This seamless compatibility makes vector databases a natural fit for applications that involve real-time learning, adaptive search, or user personalization.
Vector database architecture
Vector database architecture is optimized for swift similarity searches, scalable performance, and seamless AI integration. Here is a breakdown of the database architecture and how it works.
Key components of vector database architecture
At a high level, a vector database consists of the following:
- Storage layer: The vector database has two major storage layers: in-memory (for faster access) and on disk (for larger datasets and cost-efficiency).
- Indexing engine: This part is the core of the vector database similarity search. It uses advanced algorithms to organize and retrieve vectors quickly.
- Query processor: This is the processing unit of the vector database. It transforms user input (like a text prompt or image) into a vector, runs similarity searches, and returns ranked results.
- Integration layer: This component connects with embedding models, AI/ML frameworks, and data pipelines for real-time updates and inference.
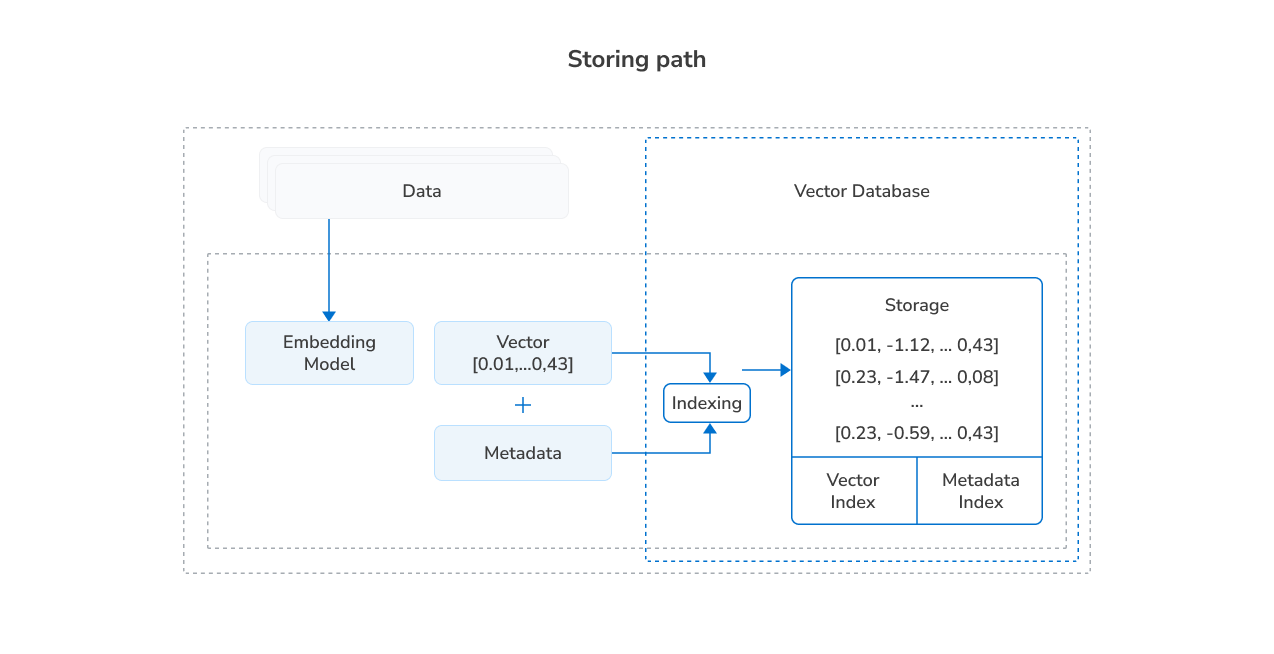
How vectors are stored
Vector databases store vectors in memory and on disk. The choice of which of these storage layers to use is determined by the application use case and hardware.
- In-memory is used for ultra-low-latency search and high-speed access (e.g., in real-time AI apps).
- On disk is used for handling billions of vectors and reducing memory costs.
Note
Some systems use hybrid storage. They keep frequently accessed vectors in memory and the rest on disk.
Indexing methods: HNSW, IVF, PQ & FAISS
Vector databases use specialized indexing techniques that help speed search efficiency. Below is the breakdown of some of the popular indexing methods in vector databases.
- HNSW (Hierarchical Navigable Small World)
HNSW is a graph-based method that creates layers of “neighbor” vectors, enabling fast and accurate approximate searches. It is particularly useful for high-performance and large-scale similarity searches. - IVF (Inverted File Index)
The IVF method clusters the dataset into groups (or “cells”) and narrows the search scope to the most relevant clusters. IVF is excellent for balancing speed and scalability. - PQ (Product Quantization)
This indexing method compresses vectors into smaller representations, allowing large-scale vector storage and faster searches with less memory. - FAISS (Facebook AI Similarity Search)
This is not a database itself, but a popular open-source library used by many vector databases to implement indexing algorithms like IVF and PQ efficiently.
How a similarity search works (step-by-step)
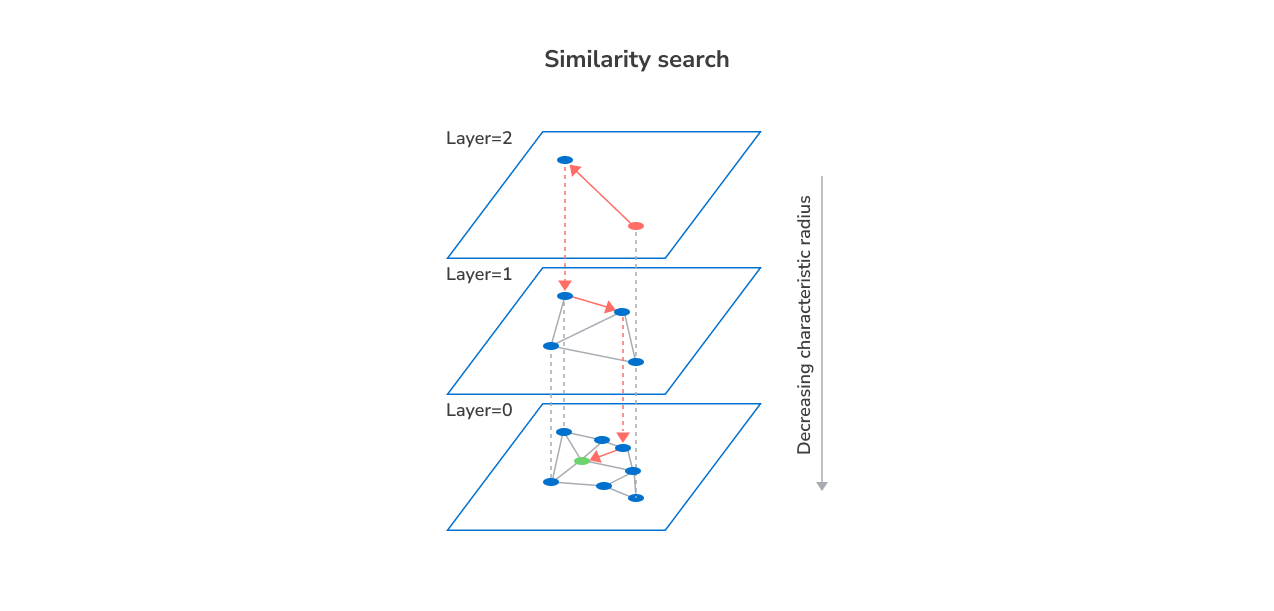
Here’s how the vector database handles similarity searches:
- A user enters a search request (e.g., a question, image, or product).
- The system uses an ML model like BERT or OpenAI embeddings to convert the user’s query into a vector.
- The vector database collects the vector (representing the user’s query) and uses an algorithm (like HNSW or IVF) to compare it with stored vectors and find the most similar ones.
- It then applies similarity metrics (e.g., cosine similarity or Euclidean distance) to rank the closest matches.
- The system returns the top results that are most similar in meaning or content to the user’s query.
This optimized, modular architecture allows vector databases to power advanced use cases in semantic search, recommendations, AI assistants, and computer vision, all at scale.
Vector databases vs. traditional databases
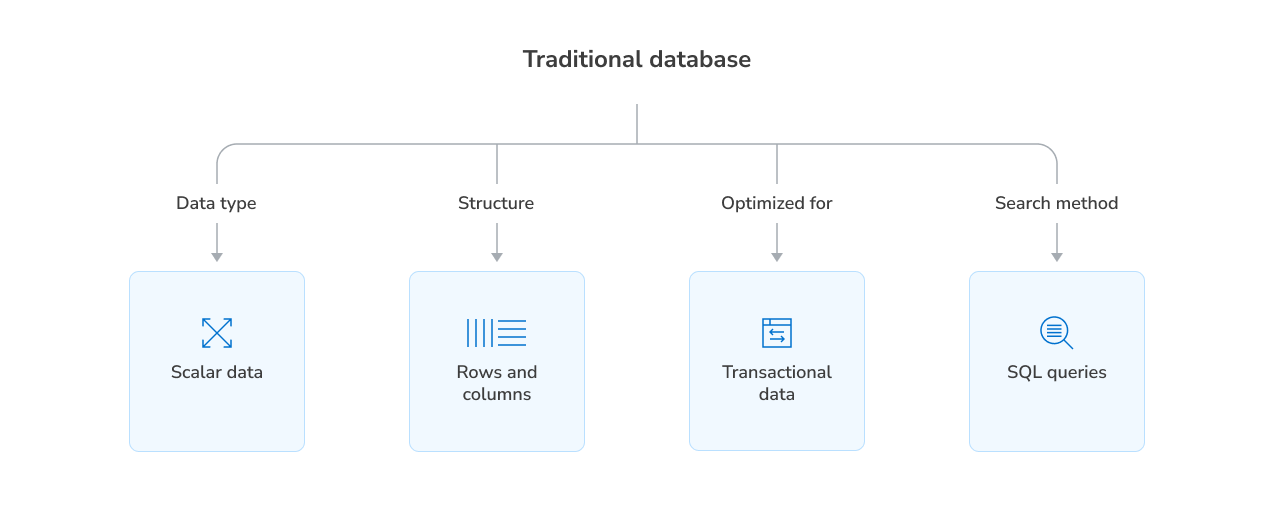
Traditional databases—whether relational (SQL) or NoSQL—are designed to store structured data and retrieve exact matches or perform range queries. They work well for applications like user management, inventory systems, and transactional records. However, when it comes to similarity search in high-dimensional vector space, they hit performance and scalability limits.
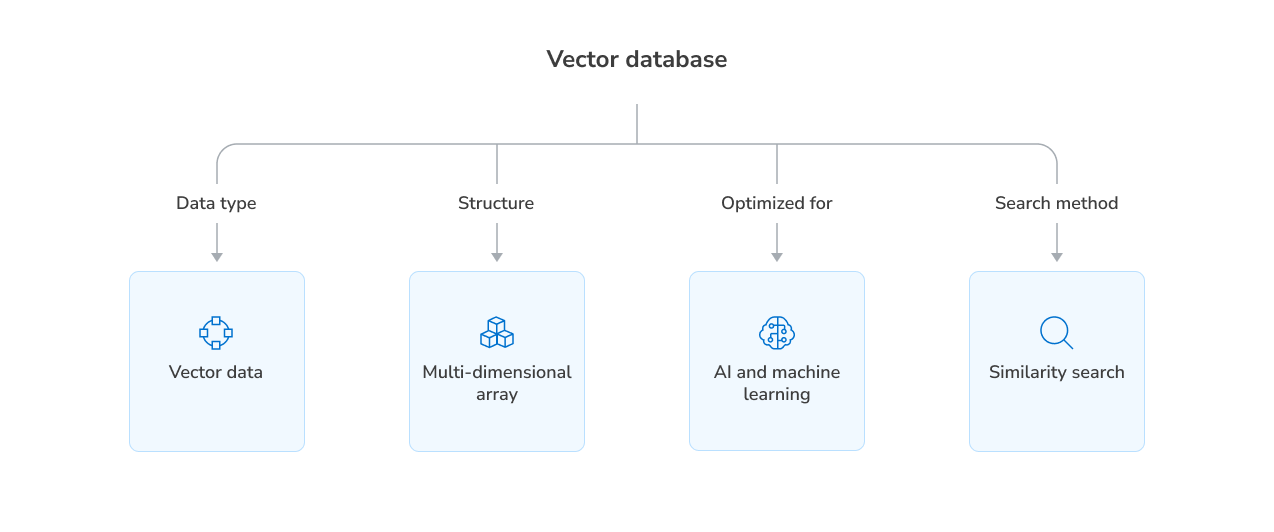
Here’s how vector databases compare to traditional databases:
| Feature | Traditional databases | Vector databases |
|---|---|---|
| Data type | Structured (rows, columns, documents) | High-dimensional vectors |
| Query type | Exact match, range, joins | Similarity search (nearest neighbors) |
| Search efficiency | Poor for vector comparisons | Optimized for fast, approximate search |
| Indexing | B-trees, hash indexes | ANN algorithms (HNSW, IVF, PQ) |
| Scalability | Limited for high-dimensional data | Scales to billions of vectors |
| Use cases | Transactions, reporting, CRUD apps | AI, ML, semantic search, recommendations |
Popular vector database systems
With the increasing use of AI and ML in virtually all industries, several vector databases have emerged to meet different needs. Below are four of the most widely used vector database systems and their explanations.
Pgvector
Pgvector is an extension for PostgreSQL that brings vector search capabilities into the database environment. It allows developers to store vector embeddings as native data types and run similarity queries using cosine similarity, Euclidean distance, or inner product. Pgvector is especially useful for teams already working with PostgreSQL who want to incorporate basic vector search into their existing infrastructure without adopting an entirely new system.
Weaviate
Weaviate is a fully open-source vector database built specifically for AI-native applications. What makes Weaviate special is its close connection with top embedding models from OpenAI, Cohere, and Hugging Face. Also, it is perfect for tasks like neural search, personalized recommendations, and retrieval-augmented generation (RAG) for large language models. Weaviate supports both RESTful APIs and GraphQL and includes built-in modules for automatic vectorization, simplifying end-to-end AI workflows.
Faiss
Designed by Meta (Facebook AI Research), not as a full-featured database, Faiss still excels as a high-performance library for rapid similarity search in massive vector databases. It is widely used for its speed, scalability, and support for GPU acceleration and is quite popular in machine learning research and production environments that need to handle billions of vectors efficiently. Additionally, Faiss integrates seamlessly with Python and is often embedded into larger AI and analytics pipelines.
Chroma
Chroma is a lightweight, open-source vector store that has quickly gained popularity for small-scale LLM projects and rapid prototyping. It’s often used in retrieval-augmented generation (RAG) pipelines thanks to its simplicity and tight integration with frameworks like LangChain. Additionally, Chroma is designed to easily run locally, making it a go-to choice for developers building experimental AI tools or local chatbots with vector-based memory.
Each of these systems offers different strengths, so choosing the right one depends on your project’s scale, architecture, and integration preferences.
Vector database in .NET
Vector databases are a game-changer in .NET applications. .NET developers can use this database to build AI-driven systems that move beyond delivering results based on keywords to matching based on meaning. With support for tools like Milvus, Weaviate, FAISS, and OpenAI embeddings, the .NET ecosystem is well-positioned to take advantage of this new class of data storage.
Below are the most impactful vector database use cases in .NET.
Semantic search engines
The semantic search functionality in vector databases is an excellent feature that .NET developers can maximize. With this feature, developers can build search engines that return more relevant results using OpenAI or Azure OpenAI embeddings. For example, in a legal tech platform built to store legal documents as vector embeddings, when a user searches for “laws related to digital privacy,” the system retrieves files containing similar ideas—even if they don’t include the exact phrase—like “GDPR compliance in tech firms” or “user data protection statutes.” This functionality improves the efficiency of the system.
AI chatbots and assistants
Modern AI chatbots built into .NET applications often rely on retrieval-augmented generation (RAG) to deliver more accurate and context-aware responses.
Here’s where it gets intriguing.
The RAG technique used in these .NET applications works with vector databases to fetch relevant information before passing it to a language model like GPT. For instance, when a user asks a question, the chatbot converts it into a vector, searches for relevant content using a vector database, and then generates a response using that retrieved context. This process lets the chatbot and AI assistant generate accurate, informed, and real-time responses for customer support, enterprise Q&A, and virtual assistant solutions.
Fraud detection & anomaly detection
Anomaly detection is non-negotiable in financial and cybersecurity systems. However, with vector databases built into these systems, the system can compare user behavior, transaction patterns, or access logs as embeddings. If a new action falls far outside the “normal” vector space—based on metrics like Euclidean distance—it’s flagged as potential fraud or an anomaly. This vector-based approach enhances accuracy and reduces false positives compared to rule-based systems.
Personalized recommendations
The semantic search feature of the vector databases in .NET application can effectively perform personalized recommendations. Here is how this works.
Since vector databases carry out semantic search by finding similar items, the .NET application can monitor and store users’ interactions with the platform as embeddings. The vector database then finds similar items based on the stored embeddings and uses the result to deliver highly personalized recommendations. This functionality is especially useful in e-commerce platforms, video streaming services, and online learning systems.
Healthcare genomics
In healthcare and biotech, especially in genomics, vector databases can help convert massive amounts of DNA and other important data into embeddings for faster analysis. For instance, a genomics research tool built in .NET integrates with Milvus to store embeddings of DNA sequences. When a researcher uploads a new sequence, the system finds similar genetic patterns linked to known conditions.
This approach allows the system to quickly identify genetic variants, support personalized medicine, and improve outcomes in clinical research.
Conclusion
Vector databases are changing how systems store and search data. They provide systems with more unique and innovative ways of searching for information. Unlike traditional databases that use exact matches for user searches, vector databases use meaning-based results. This shift empowers .NET developers to build applications with a more innovative approach to semantic search, AI assistants, anomaly detection, and personalized recommendations.
Furthermore, with the evolution of AI and machine learning in modern software, vector databases are no longer nice-to-haves; they’re necessary parts of the data stack.
FAQ
1. What is a vector database, and why is it important for AI?
A vector database is a specialized system designed to store and search vector embeddings—numerical representations of things like text, images, or user actions. It offers key features like semantic search, personalized recommendation, and integration with generative AI. Semantic features in a vector database allow AI to understand context and meaning rather than just keywords or exact matches.
2. What are HNSW, IVF, and PQ in vector databases?
HNSW, IVF, and PQ are indexing strategies used in vector databases to make similarity search fast and scalable. HNSW (Hierarchical Navigable Small World) is a graph-based method that helps quickly navigate to similar vectors. IVF (Inverted File Index) clusters similar vectors together, so only a small subset needs to be searched. PQ (Product Quantization) compresses vectors to reduce storage and improve speed. These techniques are vital for handling large-scale AI workloads.
3. How are vector databases used in real-world applications?
Vector databases power many AI-driven applications. They enable systems to understand and retrieve results based on meaning rather than exact matches. In fraud detection, vector databases compare transaction patterns to detect anomalies, and in healthcare, they’re used to analyze genomic data.