
When developers start working on any applications (for both web or desktop versions), they spend a long time worrying about the backend database, its tables, and their relationships, stored procedures, views, etc. Along with this, they also need to consider the data schema which will return from the backend part for the application. For this type of operation, we can use many available frameworks such as DAO, RDO, ADO, ADO.NET, Entity Framework, etc. Out of these different frameworks, developers most commonly use Entity Framework Core or ADO.NET, depending on project requirements. If you’re evaluating lightweight and performance-oriented options, it’s worth understanding the difference between ADO.NET vs Dapper, especially when deciding what fits best for your use case.
So, after reading this article, you will get a clear understanding of the following topics supported with clear examples.
Table of contents
- What is ADO.NET?
- Advantages of ADO.NET
- Overview of ADO.NET Architecture
- What is the Entity Framework?
- Advantages of Entity Framework Core
- When should you use ADO.NET or Entity Framework Core?
- Entity Framework Core architecture
- What is the difference between ADO.NET and Entity Framework Core
- Entity Framework vs ADO.NET comparison table
- Benchmark tests: ADO.NET vs Entity Framework Core performance
- How dotConnect supports ADO.NET and Entity Framework Core
- Conclusion
What is ADO.NET?
ADO.NET was invented by Microsoft as a part of the .NET Framework Component. With the help of this technology, we can access any type of data source through our applications and fetch the data to our C# and VB.NET. ADO.NET is a collection of object-oriented-based classes that provide a rich set of data components and with help of these components, we can create high-performance, reliable, and scalable database-based applications. In the ADO.NET models, it connects to the data source only when the system requires reading or updating the data. It is one of the major impacts on application development. Because, in Client-Server or distributed application, always having a connection resource open all the time is one of the most resource-consuming parts. In reality, we don’t need to connect a data source all the time. We only need to connect with a data source when we are reading and writing the data to a data source.
For a hands-on introduction to using connections, commands, DataReaders, and DataSets, check out this ADO.NET tutorial.
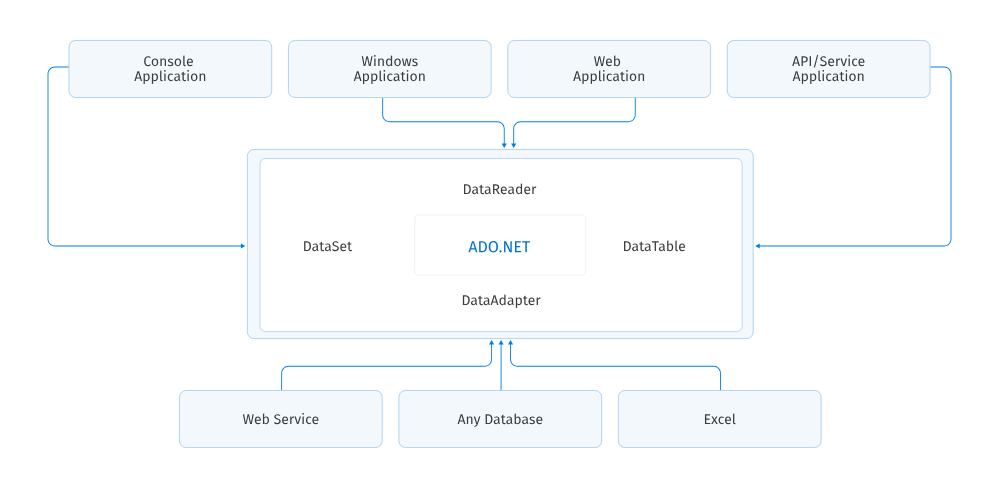
With ADO.NET, we can use SQL queries and stored procedures to perform the read, write, update and delete operation from a data source. We can use the SQL syntax with the help of ADO.NET Command objects and it always returns data in the form of DataReader or DataSet objects. So that, after the connection closes, we can use the DataSet objects to work for the data and after completing the work on our computer, we can connect the data source again when we need to update the data source. A dataset is a container of multiple DataTable Objects and every data table can have a relationship among them. We can access the data source and fill the dataset with the help of data providers. The .NET Framework provides us with three different types of data providers – ADO.NET, OLEDB, and ODBC.
XML plays a major role in ADO.NET. The ADO.NET model utilizes XML to store the data in the cache and transfer the data among applications. Datasets use XML schemas to store and transfer data among applications. We can even use this XML file from other applications without interacting with the actual dataset. We can use data among all kinds of applications and components because XML is an industry standard; we can transfer data via many protocols, such as HTTP, because of XML’s text-based nature.
Advantages of ADO.NET
ADO.NET provides many advantages over the previous Microsoft-based data access technologies like ADO. Some of the major and important advantages are as follows:
- Single Object-Oriented API – ADO.NET always features a single object-oriented collection of classes. ADO.NET also provides different data providers to work with different types of data sources, but the programming model for all the data providers works in the same way. So, if we implement the ADO.NET for one data provider, then after that if we need to change the data provider or use the other data provider, we do not need to change the entire process, we just need to change the class names and connection strings.
- Managed Code – The ADO.NET classes are managed classes. They take all the advantages of .NET CLR, such as language independence and automatic resource management. All .NET languages access the same API. So if we know how to use these classes in C#, we have no problem using them in VB.NET. Another big advantage is we don’t have to worry about memory allocation and freeing it. The CLR will take care of it for us.
- Deployment – In real life, writing database applications using ODBC, DAO, and other previous technologies and deploying on client machines was a big problem that was somewhat taken care of in ADO except that there are different versions of MDAC. Now you don’t have to think about that. Installing distributable .NET components will take care of it.
- XML Support – Today, XML is an industry-standard format and the most widely used method of sharing data among applications over the Internet. In ADO.NET, data is always cached and transferred in XML format. So that, this data can be shared with the application by components and we can transfer data via different protocols such as HTTP for different types of operations.
- Performance and Scalability – When we are developing any web-based application, we always keep focus on two major concerns i.e. Performance and Scalability. Transferring data from one source to another is always a costly process across the Internet due to connection bandwidth limitations and rapidly increasing traffic. Using disconnected cached data in XML takes care of both of these problems.
- DataReader versus DataSet – The ADO.NET DataReader is used to retrieve data in read-only mode (cannot update data back to a data source) and forward-only mode (cannot read backward/random) data from a database. We create a DataReader by calling Command.ExecuteReader after creating an instance of the Command object.
- LINQ to DataSet – LINQ to DataSet API provides queries capabilities on a cached DataSet object using LINQ queries. The LINQ queries are written in C#.
- LINQ to SQL – LINQ to SQL API provides queries against relational databases without using a middle layer database library.
ADO.NET architecture concept
Microsoft designed ADO.NET in such a way that we can perform different kinds of data source operations in the same fashion. For simplicity, we can categorize ADO.NET components into three categories: disconnect, common or shared, and the .NET data providers. The disconnected components build based on ADO.NET architecture. We can use these classes with or without data providers. For example, we can use a DataTable object with or without providers, and shared or common components are the base classes for all types of data providers. The below ADO.NET architecture diagram demonstrates related to the ADO.NET Component model and how they work together.
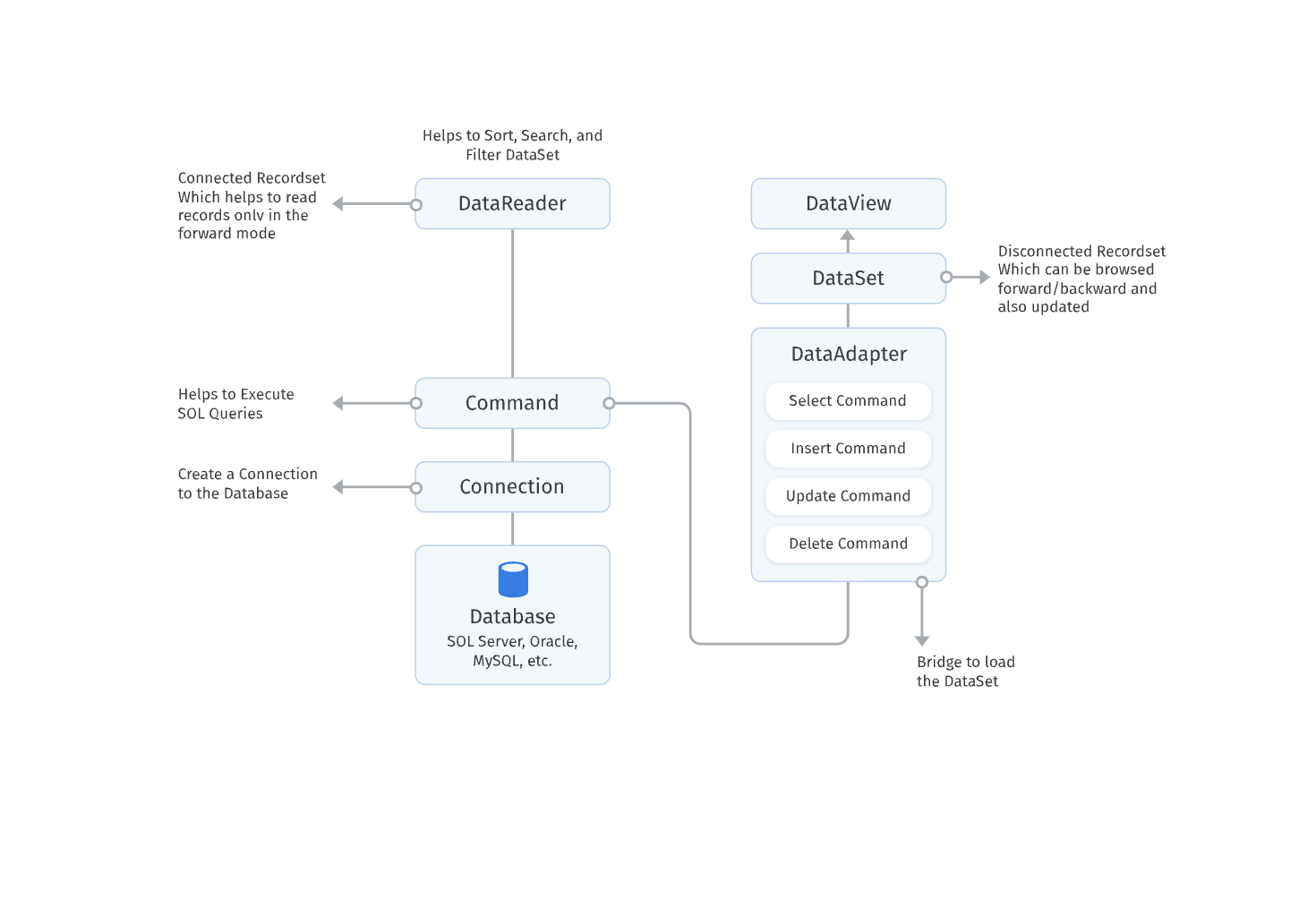
A data provider is a set of factors, similar as Connection, Command, DataAdapter, and DataReader. The Connection is the first element that talks to a data source. With the help of Connection Object, we can establish a connection between the application and the data source. These connection objects work as reference objects in the Command and DataAdapter objects. A Command object executes a SQL query and stored procedures to read, add, update, and cancel data of a data source via a DataAdapter. A DataAdapter is ground between a dataset and the connection. We can use the Command Object to execute any type of SQL Queries and Stored Procedures to fetch data from the database.
All data providers share the ADO.NET common components. These components like DataSet, DataView, and DataViewManager always represent the data on behalf of ADO.NET. The DataSet component objects normally use XML Schema to capture and return data between the Applications and the Data Providers. A DataSet is a sub-set of DataTable objects. A DataTable represents a database table. We can represent single or multiple views of a dataset with the help of DataView and DataViewManager objects. In our applications, if required we can directly use a DataView or DataViewManager component with data-bound controls like DataGrid or DataList.
What is Entity Framework Core?
Entity Framework Core (EF Core) is a cross-platform, open-source ORM (Object-Relational Mapper) for .NET applications, developed by Microsoft. It simplifies data access by allowing developers to work with C# objects instead of writing raw SQL queries. This abstraction eliminates the need to interact directly with database tables or columns, making data operations more intuitive and efficient.
As shown in the image below, EF Core sits between the application’s business logic (domain classes) and the database. It automatically maps data between objects and relational tables, handling retrieval, updates, and persistence without manual SQL queries.
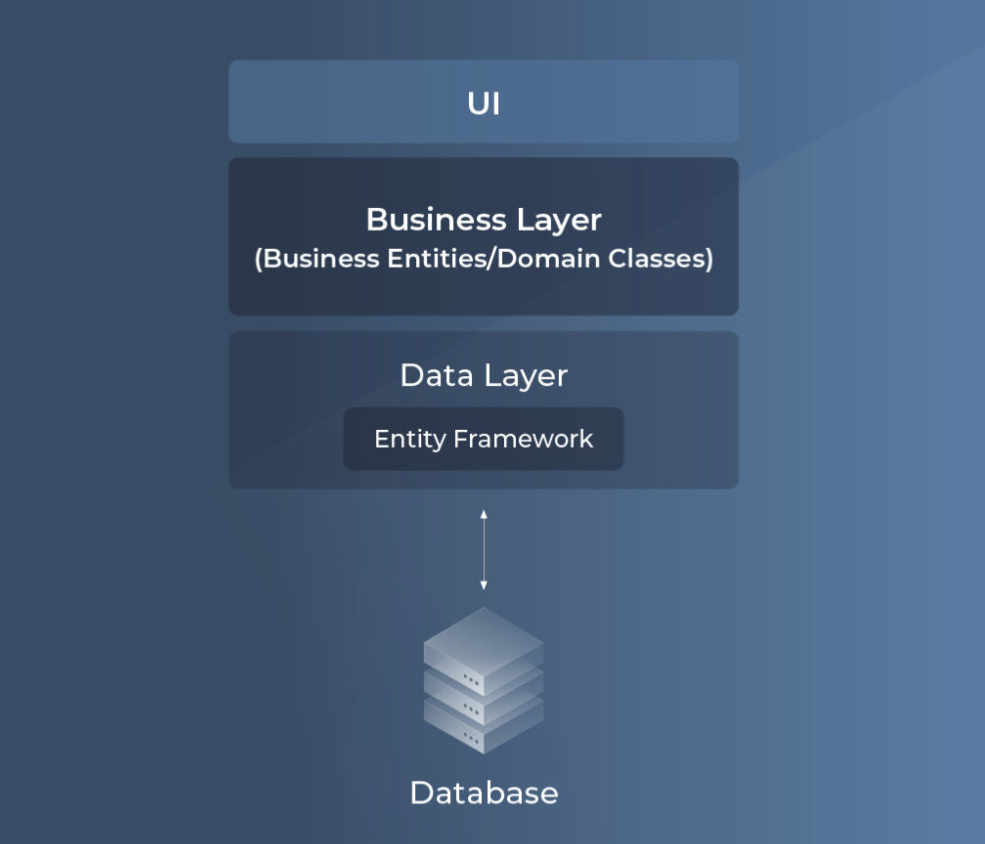
As shown in the image above, Entity Framework Core serves as the bridge between business entities (domain classes) and the database. It facilitates data retrieval by mapping database records to objects and persists changes back to the database when required. This eliminates the need for manual SQL queries, allowing developers to work with data using object-oriented principles.
Advantages of Entity Framework Core
Now, let’s explore Entity Framework Core advantages and how it works. It offers significant improvements over earlier Microsoft-based data access technologies like ADO.NET. Some of the key benefits include:
- Modeling – Uses POCO (Plain Old CLR Objects) to define entity models that map to database tables, allowing a code-first approach without requiring an EDMX file.
- Querying – Supports LINQ-to-Entities for querying data, translating expressions into database-specific SQL. Also allows executing raw SQL queries for advanced database operations.
- Change Tracking – Automatically tracks modified properties in entity instances, ensuring that only changed data is updated in the database.
- Saving Data – Executes INSERT, UPDATE, and DELETE operations, applying changes when SaveChanges() or SaveChangesAsync() is called.
- Concurrency Control – Implements optimistic concurrency to prevent overwriting conflicts when multiple users modify data simultaneously.
- Transaction Management – Supports automatic transactions for consistent database operations and allows custom transaction handling when needed.
- Built-in Conventions – Uses a convention-over-configuration approach to reduce setup time, with Fluent API and Data Annotations available for customization.
- Migrations – Provides built-in migration commands via the .NET CLI or NuGet Package Manager Console, enabling database schema changes without manual SQL scripts.
- Caching – Implements first-level caching within a DbContext instance, preventing redundant queries. EF Core does not include second-level caching by default.
With these capabilities, EF Core streamlines database operations while maintaining flexibility and scalability, making it a preferred ORM for modern .NET applications.
When should you use ADO.NET or Entity Framework Core?
Choosing the right technology depends on your application’s performance needs, maintainability, and scalability. While ADO.NET provides fine control over database operations, Entity Framework Core (EF Core) offers a more developer-friendly ORM approach.
When to use ADO.NET?
ADO.NET is the best choice in the following scenarios:
- High-performance applications that require low latency and direct database access.
- Large-scale data processing where precise control over queries and stored procedures is necessary.
- Legacy systems already built on ADO.NET, making migration to ORM unnecessary.
- Scenarios requiring direct SQL execution, such as working with bulk inserts, transactions, and stored procedures.
When to use Entity Framework Core?
EF Core is a better fit if:
- Minimizing manual SQL queries accelerates development.
- Cross-database compatibility is required, as EF Core supports multiple providers.
- An object-oriented approach to data management is preferable to writing raw SQL.
- Scalability and maintainability are priorities, with LINQ and entity tracking simplifying data access.
Hybrid approaches: Using ADO.NET and Entity Framework Core together
A hybrid approach is beneficial in scenarios where:
- EF Core is used for general CRUD operations and rapid development.
- ADO.NET is used for performance-critical database tasks, such as bulk data operations and transaction-heavy workloads.
- dotConnect is leveraged to provide optimized database connectivity for both ADO.NET and EF Core.
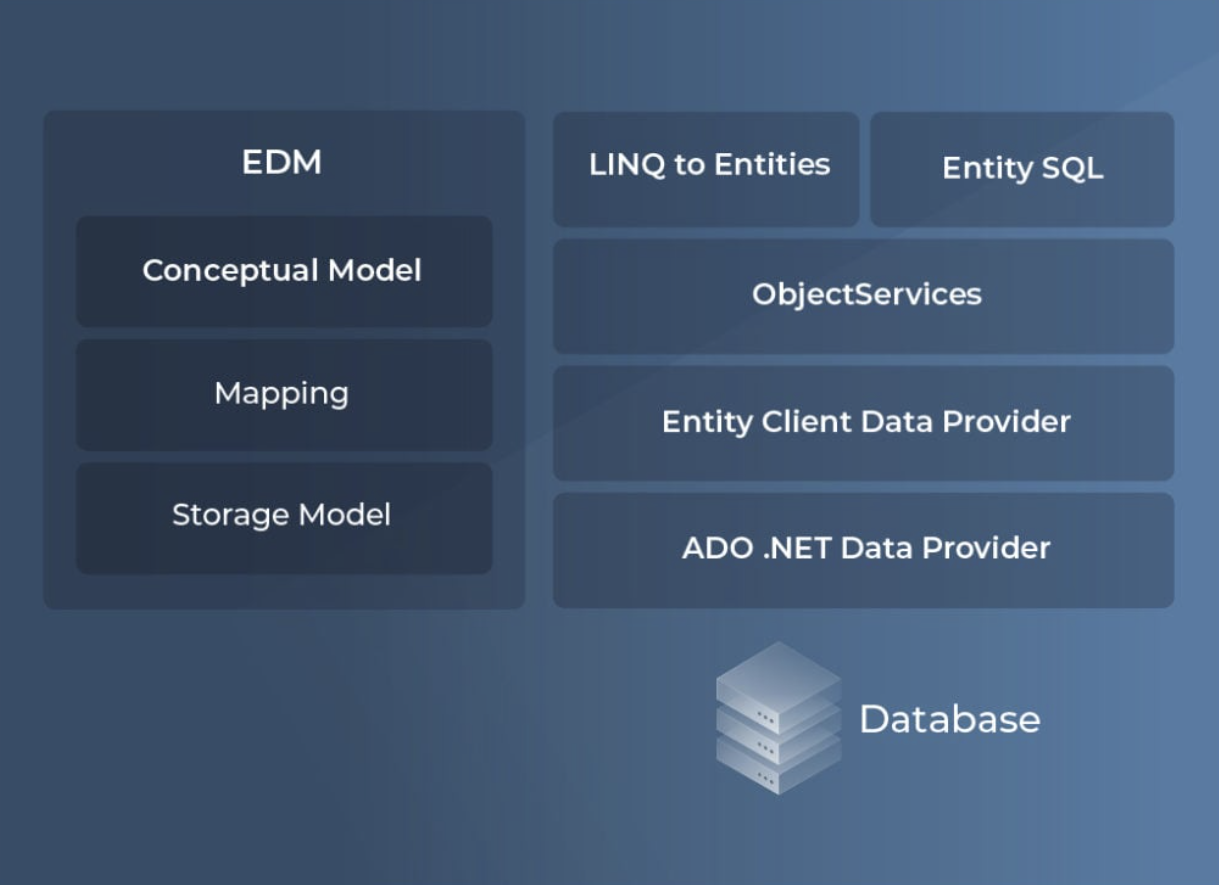
Entity Framework Core architecture
Let’s give a short overview of the different components available under the Entity Framework Core architecture:
- POCO Entities – EF Core uses Plain Old CLR Objects (POCOs) to define entity models, mapping them directly to database tables using Fluent API or Data Annotations.
- DbContext & DbSet – The DbContext class acts as the main entry point for querying and saving data. It contains DbSet<T> properties that represent database tables as collections of entities.
- LINQ-to-Entities (L2E) – Developers use LINQ queries to retrieve, filter, and manipulate data. EF Core translates these LINQ expressions into SQL queries optimized for the underlying database provider.
- Change Tracking – EF Core automatically tracks modifications to entity instances, ensuring only necessary changes are persisted to the database.
- Transactions & Concurrency Control – EF Core supports automatic transactions and uses Optimistic Concurrency Control to prevent data conflicts.
- Database Providers – EF Core is database-agnostic, supporting SQL Server, PostgreSQL, MySQL, SQLite, and more. It communicates with databases through custom EF Core database providers.
- Migration & Schema Management – EF Core allows schema changes using Migrations, enabling database creation, updates, and modifications via CLI or NuGet Package Manager.
- Raw SQL Support – While EF Core primarily relies on LINQ, it also allows executing raw SQL queries when necessary for performance optimization.
This architecture makes EF Core more lightweight, flexible, and efficient than previous versions, making it the preferred ORM for modern .NET applications.
The following figure shows the overall architecture of the Entity Framework Core.
To expand your possibilities, you can use this powerful Entity Framework Designer that automates the process.
What is the difference between ADO.NET and Entity Framework Core
In this chapter, we will explore the differences between traditional ADO.NET and Entity Framework Core. While both technologies enable database interactions, ADO.NET provides direct control over SQL execution, whereas EF Core abstracts database operations through an ORM approach. Despite their shared purpose, ADO.NET and EF Core differ significantly in performance, flexibility, and ease of use. Below are some of the key ADO.NET and Entity Framework Core differences.
Performance
- ADO.NET is faster because it connects directly to the database without ORM overhead.
- EF Core translates LINQ queries into SQL, which adds some overhead but improves maintainability.
- ADO.NET is ideal for high-performance applications, while EF Core balances performance with ease of use.
Flexibility
- ADO.NET provides full control over queries, allowing developers to optimize SQL execution manually.
- EF Core abstracts database operations, making data access simpler but less flexible.
- EF Core supports raw SQL execution, but ADO.NET remains the better choice for stored procedures and complex queries.
Development speed
- ADO.NET requires manual coding for database interactions, increasing development time.
- EF Core generates models and relationships automatically, reducing effort in setting up the data access layer.
- EF Core is preferred for rapid development, while ADO.NET is better for fine-tuned, custom data access solutions.
Code maintainability
- Debugging ADO.NET requires tracking database queries manually.
- EF Core maintains entity relationships using Fluent API and Data Annotations, simplifying code structure.
- EF Core supports automatic schema migrations, making long-term maintenance easier.
Both ADO.NET and Entity Frameworks have similar but quite different features. We offer a clear comparison table to make the process of comparison easier and to answer numerous questions about them (e.g., “Does Entity Framework use ADO.NET?” etc.).
Entity Framework vs ADO.NET comparison table
Below, we highlight the differences between Entity Framework vs. ADO.NET, let’s explore.
| SI No | ADO.NET | Entity Framework |
|---|---|---|
| 1 | ADO.NET establishes a direct connection between relational or non-relational systems and applications. | Entity Framework provides an object-relational mapping framework over ADO.NET architecture. |
| 2 | It is directly connected to the database. | For Entity Framework, it first translates the LINQ query into raw SQL queries and then executes that query to the database. |
| 3 | ADO.NET provides complete control over the data access layer, allowing the creation of classes and methods from scratch. | It automatically creates the data model classes and their related database context class. |
| 4 | Debugging in ADO.NET is cumbersome as it requires navigating from the application layer to the database layer. | Entity Framework provides a clear relationship between different data model classes. |
| 5 | More flexible in terms of raw SQL queries and procedures because it offers greater control over the database. | Entity Framework is less flexible because it always depends on LINQ queries, which return the data entity model class type. |
Takeaway:
The difference between Entity Framework and ADO.NET comes down to performance vs. convenience. ADO.NET offers direct control and faster execution, while Entity Framework simplifies data management but adds overhead.
Benchmark tests: ADO.NET vs Entity Framework Core performance
Performance is critical in database operations, particularly in applications that handle large datasets, real-time processing, or transaction-heavy workloads. To understand ADO.NET vs Entity Framework performance, we refer to a benchmarking study conducted by Exception Not Found, which tested various query execution times under controlled conditions.
The benchmark tests measured execution times for three types of queries:
- Fetching a player by ID (single-row retrieval)
- Retrieving all players for a team (multi-row retrieval)
- Fetching teams for a sport, including all players (complex relational query)
The results were as follows:
| Technology | Player by ID | Players for Team | Teams for Sport |
| ADO.NET | 0.013 ms | 1.03 ms | 8.84 ms |
| EF | 0.77 ms | 3.57 ms | 113.45 ms |
Key observations:
- ADO.NET demonstrated the fastest performance in simple queries, such as fetching a player by ID, with an average execution time of 0.013 ms.
- Entity Framework was significantly slower across all query types, particularly in complex queries like “Teams for Sport,” averaging 113.45 ms.
Note: These benchmarks are based on specific test conditions and may vary depending on the application’s context and environment.
How dotConnect supports ADO.NET and Entity Framework Core
dotConnect is a database connectivity solution built on ADO.NET, designed to provide smooth integration with various relational databases. It supports both traditional ADO.NET operations and modern ORMs like Entity Framework Core, allowing developers to balance performance, maintainability, and cross-database compatibility.
Key aspects of dotConnect’s integration:
- Built on ADO.NET Architecture – dotConnect uses standard ADO.NET classes while extending functionality with additional features like advanced connection pooling and performance optimizations.
- Supports Entity Framework Core – Works as a database provider for EF Core, ensuring compatibility with LINQ-to-Entities, change tracking, and transactions while maintaining database flexibility.
- Multi-Database Compatibility – Provides support for multiple database systems, including SQL Server, PostgreSQL, MySQL, Oracle, and SQLite, offering a unified approach to data access.
- Entity Developer (ED) for ORM Modeling – Includes Entity Developer, a powerful tool for modeling and managing EF Core and ADO.NET entity relationships, reducing manual configuration.
By utilizing dotConnect, developers gain a flexible, high-performance data access solution that integrates smoothly with ADO.NET and EF Core while providing additional capabilities for efficient database operations.
Try dotConnect today and experience seamless database connectivity tailored to your development needs!
Conclusion
So, which is better—ADO.NET or Entity Framework Core? If you need more control over SQL commands and want to work closely with raw SQL queries, ADO.NET is a solid choice. If faster development and cleaner code maintainability are your priorities, Entity Framework Core stands out. In practice, many developers combine both—using Entity Framework for standard CRUD operations and ADO.NET for reporting or bulk data handling.
Ultimately, the choice depends on your project needs and performance goals. For a more lightweight alternative, it’s also worth considering how Dapper fits in. Check out this comparison of Dapper vs ADO.NET to help you decide what works best for your application.
FAQ
Should ADO.NET or Entity Framework Core be used?
The choice depends on the application’s priorities. ADO.NET is the go-to solution for high-performance scenarios, offering direct SQL access and full control over database operations. In contrast, EF Core simplifies development and improves maintainability through its ORM abstraction.
A hybrid approach often works best—utilizing EF Core for standard CRUD operations while using ADO.NET for bulk inserts, complex queries, and transaction-heavy tasks.
Is ADO.NET outdated?
ADO.NET remains widely used in enterprise applications where performance and control are critical. Microsoft continues to support it and serves as the foundation for tools like Dapper, dotConnect, and LinqConnect.
Does Entity Framework Core introduce performance overhead?
Yes, EF Core adds overhead due to query translation and change tracking. However, optimizations like compiled queries (AsNoTracking()) and indexing can reduce impact. The trade-off between ease of development and performance is acceptable for most applications.
Can ADO.NET and Entity Framework Core be used together?
Yes, and many applications do. EF Core internally uses ADO.NET, and both can be combined—EF Core for ORM-based data access and ADO.NET for raw SQL performance. Many also integrate Dapper for optimized query execution.
How does dotConnect enhance database performance?
dotConnect optimizes ADO.NET and EF Core by improving connection pooling, query execution, and ORM capabilities. It adds:
- Faster database access through connection pooling.
- Optimized query execution for high-performance applications.
- Extended ORM support for EF Core, NHibernate, and LinqConnect.
- Multi-database compatibility with SQL Server, PostgreSQL, MySQL, and Oracle.
