Data comparison is a difficult and resource-intensive process. In the article, we are going to explore algorithms, advantages, and disadvantages of specific data comparison, as well as describe how to compare data between two MySQL databases with dbForge Studio for MySQL.

For convenience, this process can be divided into several steps.
First, you should compare tables from one database on one server with the database on the other server.
You should choose columns for data comparison, and also choose a column that will be the comparison key. The next step is to choose all data or specific parts of the data from these tables. The third and most important step is the comparison of two tables by the selected comparison key itself. During this process, the status of each record is set to “only in source”, “only in target”, “different”, or “equal”.
The final steps of the data comparison process are including records into the synchronization process and then synchronization itself. During these steps, records needed for synchronization are chosen, an update script is created, and after that, the script is executed. You can read a detailed description of the comparison process here or here.
Now, let’s look at the third step (data comparison) thoroughly.
There are several ways you can compare data, and they differ only by the side on which data comparison is performed – either on the server’s side or on the client PC.
Server-side data comparison is performed using the resources of the server
The algorithm of comparison is the following:
1. For each record of each of the two tables, a checksum is calculated;
2. Then the checksum of every record from one table is compared to the checksum of the corresponding record from another table. A conclusion is made about whether the records are equal or different;
3. The comparison result is stored in a temporary table on the server.
Performance indicators:
1. The speed of data comparison directly depends on the server capacity and occupancy;
2. The maximum size of the database for comparison is limited by the resources of the server itself.
Advantages:
1. There is no need to transfer large amounts of data for comparison to the client’s PC through the network. In this way, we save network traffic;
2. The speed of comparison does not depend on the client PC resources;
3. Ability to compare blob data of any size.
Disadvantages:
1. Because of the record checksum calculation algorithm, different data in some cases can result in equal checksums, and the “equal” status will be received instead of the expected “different” status;
2. There is no flexibility in using the synchronization and comparison options;
3. There is no possibility to view record differences and exclude specific records from the synchronization manually;
4. During the synchronization script creation, you should perform data transfer from the server to the client side;
5. The control checksum calculation of a large number of records consumes all server resources;
6. One should provide extra space on the server for the comparison results to be stored in a temporary table.
As we can see, this method of comparison has more disadvantages than advantages, that’s why it’s rarely used.
Data comparison on the client PC is performed using client machine resources, and the server only provides data for comparison. In turn, this comparison method can be divided further into several ways depending on how the comparison information will be stored.
Comparing Data on a local PC when the comparison result is stored in RAM
The comparison algorithm is the following:
1. The server passes all data from both tables to the local PC;
2. Every record of every table is sent to RAM and is compared without checksum calculation;
3. If a record gets “only in source”, “only in target”, or “equal” status, only the comparison key is stored in RAM. If records get the “different” status, they are sent to RAM for storage completely.
Performance indicators:
1. The speed of data comparison directly depends on the client PC resources and on the speed of data transfer through the network;
2. The maximum size of the database for comparison depends on the size of RAM on the client PC and on the degree to which the databases that should be compared are different – the smaller the number of different records, the larger databases can be compared.
Advantages:
1. Minimal server occupancy – the server only performs simple data selection;
2. The simplest algorithm of data comparison (records are sorted on the client side);
3. Flexibility in using the comparison options;
4. Minimal size of the comparison data store;
5. The status of every record for any data is always correct.
Disadvantages:
1. To view records with “only in source”, “only in target”, or “equal” status, an extra data selection is needed;
2. An extra data selection is needed to create a synchronization script;
3. An OutOfMemory Exception may be thrown when there are many data differences in the databases;
4. Possibility to compare blob data the size of which does not exceed the amount of free RAM.
In older versions of our data comparison tools, this comparison method was used. However, after evaluating its pros and cons, we decided to move on to a different algorithm in newer versions.
Comparing Data on a local PC when the comparison result is stored as a cached file on the disk
The algorithm of comparison is the following:
The server passes all data from both tables sorted by comparison key to a local PC. This data is then read by bytes, compared without checksum calculations, and written to a file on the disk.
Performance indicators:
1. The speed of the data comparison directly depends on the client PC resources and on the speed of data transfer through the network;
2. The maximum size of a database to compare is limited by free disk space and does not depend on the degree of data difference in databases.
Advantages:
1. Medium server occupancy – server performs data sorting and selection;
2. To view records and synchronization script creation, extra requests to the server are not necessary;
3. The status for every record is always correct for any data;
4. Possibility to compare blob data of the size equal to the amount of free space available on the disk.
Disadvantages:
1. Complex data comparison algorithm for the records that have a comparison key of the string data type;
2. Complex disk caching algorithm for temporary information storage creation.
We can see that in this case, the only real disadvantage is the implementation difficulty.
How to compare data from two different databases
In dbForge Studio for MySQL, there is Data Compare, a tool that allows you to compare and analyze table data in MySQL databases. Besides, it allows synchronizing data differences to get identical databases.
To start comparing data, on the Comparison menu, click New Data Comparison. In the wizard that opens, select the source and target databases you want to compare.
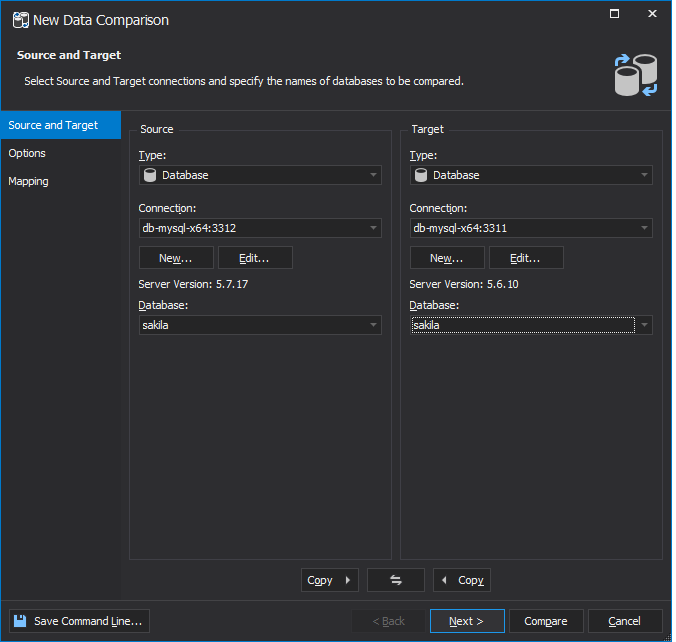
On the Options tab, you can customize the default comparison with additional options. On the Mapping tab, the Data Compare tool automatically selects columns with a primary or unique key as comparison keys. If needed, you can set comparison keys manually, however, in such cases, key repetition may occur which can cause conflicted records after comparison. Such records are not compared. Once done, click Compare.
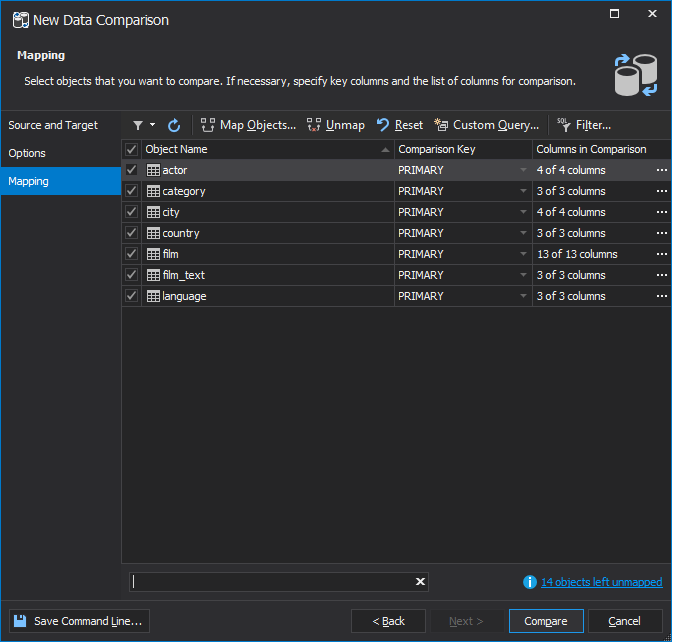
After you compared data, you can view the data comparison result in a Data Comparison document displaying top and bottom grids. On the top grid, you can view a number of rows being different, identical, existing only in Target or only in Source for each compared table or view. On the bottom grid, you can view the corresponding data records of the selected database object in the top grid.
For example, if a comparison key for a compared pair of records is found in the source database but is absent in the target one, the Data Compare tool considers such records being Only in Source. If the key is found in the target database, the records get the Only in Target status. If a comparison key is found in both databases, the tool compares columns without primary or unique keys and, based on the result, considers the records either Identical or Different. You can review data differences in every compared table and decide which records should be synchronized and which of them should be excluded from the synchronization.
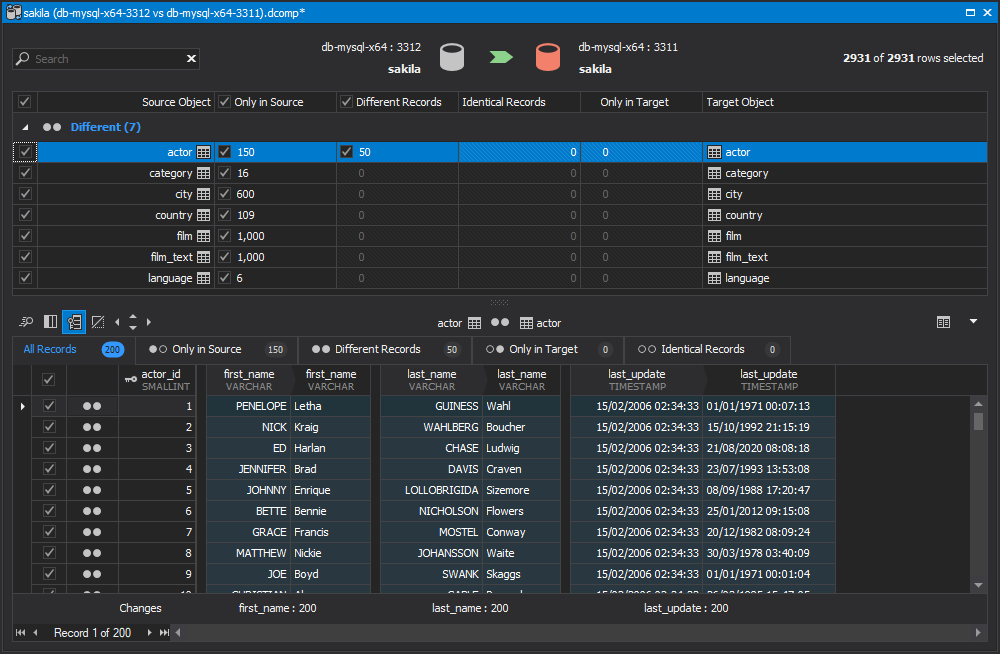
After comparing data, you can synchronize it to the target database. To start synchronizing, click Synchronize data to the target database.
In the Data Synchronization wizard that opens, you can generate a synchronization script to review how the target database will be changed after synchronization. For example, you can open the script in the editor, save it for later use, or immediately execute it against the target database.
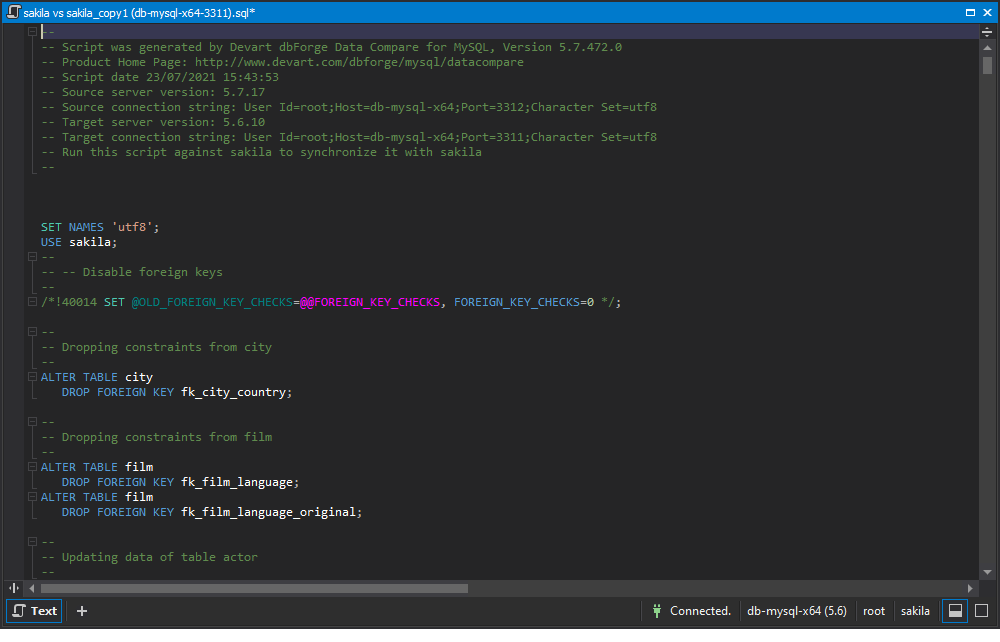
For records with the Different status (which have comparison keys in the source and target databases, but their data is different), the tool generates the sсript with INSERT statements. The same is done for records with the Only in Source status (they have a comparison key only in the source database). For the Only in Target records, the Data Compare tool generates the script with DELETE statements. Identical records or ones with repeated comparison keys are not included in the script.
Conclusion
In the article, we reviewed three different data comparison algorithms:
- Server-side data comparison using the server’s resources
- Local data comparison with comparison results stored in RAM
- Local data comparison with comparison results stored as a cached file on the disk
All these methods have different strengths and weaknesses, but we can still assess their usefulness by comparing their respective advantage/disadvantage ratios. As you can see, the last algorithm has the greatest ratio. That’s why we implemented it in all the latest versions of our comparison tools:
- dbForge Data Compare for SQL Server
- dbForge Data Compare for MySQL
- dbForge Data Compare for Oracle
- dbForge Data Compare for PostgreSQL
In addition, we demonstrated how to compare data and detect differences between two MySQL databases with dbForge Data Compare for MySQL built into dbForge Studio for MySQL.