")
Dealing with a disorganized database often means running into duplicate records, mistakes, and sluggish performance. On the other hand, when your data is structured properly, it’s easier to maintain, more reliable, and much faster to work with.
That’s what database normalization does — it cleans up the structure so everything runs smoother and smarter. What is normalization in database? Let’s find out why it’s so essential.
- What is database normalization?
- Key benefits of database normalization
- The process of database normalization
- Database normalization vs. denormalization
- Normalization in SQL (including SQL Server)
- Common mistakes in database normalization
- Best practices for database normalization
- How dbForge Edge can help with database normalization
- Conclusion
What is database normalization?
Database normalization is basically about organizing your data so that it actually makes sense. Instead of cramming everything into one oversized, chaotic table, normalization breaks things down into smaller, connected tables—like sorting your stuff into labeled drawers instead of tossing it all into one big junk drawer.
This approach not only saves space but also makes it way easier to update or delete information without messing things up. It helps keep your data clean, consistent, and accurate over time. Plus, a well-normalized database makes queries faster and reduces the chances of running into errors or duplicates. In short, normalization helps you build a database that’s efficient, reliable, and much less of a headache to manage.
Key principles of database normalization
Normalization of database follows a few straightforward but essential rules to keep your data clean and easy to work with.
First up: each column should have atomic values. That just means every column should hold one single piece of information—not a list, not a mix, just one clear value.
Next, there’s the idea of removing partial dependencies. In tables that use a composite key (a key made of more than one column), every other column should depend on all parts of that key, not just a piece of it.
Finally, normalization helps reduce transitive dependencies. This happens when one column depends on another column that isn’t a key. To avoid confusion and inconsistency, each column in a well-structured table should depend directly on the main key, not on another non-key column.
Key benefits of database normalization
- Keeping your data consistent
Imagine entering a customer’s name once and having it correct everywhere. That’s what normalization helps with—no more confusing mix-ups or different versions of the same info. - Cutting down on duplicate data
Instead of storing the same data over and over (like someone’s phone number in five different places), normalization keeps it in one spot. Less mess, more space. - Making updates easier
If you ever need to change something (like updating a product price), you only have to do it once. Everything stays neat and up to date without chasing down errors.
The process of database normalization
When you build a database, it’s important to keep it organized so you don’t run into problems like duplicate info, messy updates, or confusing reports later. A step-by-step process brings you undeniable advantages and helps clean up your database by breaking it into smaller, more focused tables.
First Normal Form (1NF)
This step is about making sure that each field contains only one piece of information.
Imagine you’re keeping track of students and the courses they take. If you write down “Math, Science” in one box under “Courses,” that’s a no-go. 1NF says: list each course separately. One row for each course the student takes. That way, everything stays clear and easy to read. This is something that is easy to perform even for beginners!
Second Normal Form (2NF)
Once your data follows 1NF, the next step is to remove repeated info that only depends on part of the record.
Say you’ve got a student’s name written every time you list a course they’re taking. Since their name has nothing to do with the course itself, you don’t need to keep writing it over and over. Instead, move the student’s personal info (like name or email) to a separate list, and just reference it when you need it. That’s 2NF—cutting out repetition by grouping related info together.
Third Normal Form (3NF)
Now it’s time to get even more specific in techniques. In 3NF, we make sure every piece of data depends directly on the main subject of the table, not on something else.
For example, if you’re storing someone’s ZIP code and their city, but the city can be figured out just from the ZIP code, then the city doesn’t really belong there. You can move that part elsewhere. This helps avoid mistakes like someone accidentally typing the wrong city for a given ZIP code.
Boyce-Codd Normal Form (BCNF)
Sometimes, 3NF isn’t enough to avoid redundancy. For example, the dependencies that involve non-primary attributes might cause repetition of data, even though they satisfy the requirement that every piece of data is dependent on the main subject of the table.
For instance, you have a table that stores customer addresses, such as customer ID (primary key), city, and ZIP code. Each customer can have only one ZIP code and city, and ZIP codes cannot belong to different cities. This tablesatisfies 3NF, since all non-prime attributes (City, ZIP code) depend directly on the primary key (ID).
However, ZIP code determines City, and ZIP code is not a candidate key (the one that belongs to a minimal set of columns that uniquely identify each row in a table). In this case, only ID is going to be that determinant. As a result, we get redundancy, since every time a customer from New York is added, you need to repeatedly type “New York” for ZipCode 10001. And, If the city name changes (for some reason — maybe administrative updates), you need to update multiple rows.
The Boyce-Codd Normal Form lets you ensure that every determinant used should be a candidate key, which helps avoid such cases.
To satisfy BCNF criteria, we can decompose one table into two, one for City and ZIP code information, and another for ID and ZIP code.
Fourth Normal Form (4NF)
This one’s about not mixing two unrelated types of information in one place.
Let’s say you’re tracking the languages a student speaks and also their hobbies. These two things have nothing to do with each other, but if you list them side by side, you end up with a bunch of weird combinations. To fix this, just keep them in separate lists. One list for languages, one list for hobbies. That’s 4NF.
Fifth Normal Form (5NF)
This is used in more complex situations, like when a product, a supplier, and a region all affect each other in different ways. Trying to cram all of that into one list can get messy.
So in 5NF, you break things down even further—into simple relationships between just two items at a time. Then you can piece them back together when you need the whole picture. It’s like solving a puzzle by sorting the pieces first.
Database normalization use case
Now that you are fully aware of the database normalization process, let’s find out how you can actually use it in a real-world case.
Suppose we have a table that contains store order details, such as order ID, customer information, order details, delivery information, payment methods, order notes, delivery date and time, order date, and discount details.
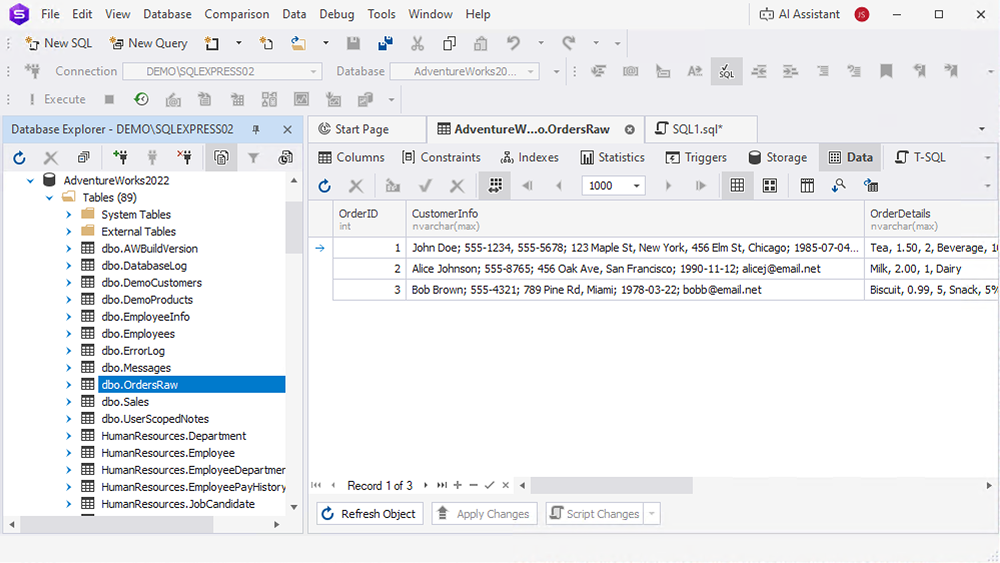
| Order ID | Customer Info | Order Details | Delivery Info | Payment Methods | Order Notes | Order Date | Delivery DateTime | Discounts |
|---|---|---|---|---|---|---|---|---|
| 1 | John Doe; 555-1234, 555-5678; 123 Maple St, New York, 456 Elm St, Chicago; 1985-07-04; [email protected] | “Tea, 1.50, 2, Beverage, 10%; Coffee, 3.00, 1, Beverage” | Pickup; 123 Maple St, New York; 2023-01-05 14:00 | Credit Card, Cash | “Extra napkins” | 2023-01-01 | 2023-01-05 14:00 | 5% on total |
| 2 | Alice Johnson; 555-8765; 456 Oak Ave, San Francisco; 1990-11-12; [email protected] | “Milk, 2.00, 1, Dairy” | Home Delivery; 456 Oak Ave, San Francisco; 2023-01-06 09:00 | Debit Card | “Leave at front door” | 2023-01-02 | 2023-01-06 09:00 | 2% on total |
| 3 | Bob Brown; 555-4321; 789 Pine Rd, Miami; 1978-03-22; [email protected] | “Biscuit, 0.99, 5, Snack, 5%; Tea, 1.50, 3, Beverage; Juice, 2.10, 2, Beverage” | Home Delivery; 789 Pine Rd, Miami; 2023-01-07 18:30 | Cash, Voucher | “Call on arrival” | 2023-01-03 | 2023-01-07 18:30 | No discount |
As you can see, there are different dependencies involved, which lead to redundancy and a lack of data integrity.
Let’s use database normalization to design a database that would be easy to scale and maintain and will organize all the data in the most efficient way.
First Normal Form (1NF)
To bring the table to 1NF, we need to remove all repeating groups and ensure that each field contains only atomic (indivisible) values. We must also ensure that each record has a unique identifier (which we have as the Order ID).
Breaking down the fields:
- Customer Info is split into:
- Customer Name
- Primary Phone
- Optional Mobile Phone
- Addresses with respective cities
- DOB
- Email
- Order Details are split into:
- Item Name
- Price
- Quantity
- Category
- Individual Discount
- Delivery Info is split into:
- Delivery Method
- Delivery Address
- City
- Delivery DateTime
- Payment Methods is split into individual payment methods.
1NF tables
Orders table
| Order ID | Customer ID | Order Date | Delivery Method | Delivery Address | City | Delivery DateTime | Payment Method 1 | Payment Method 2 | Order Notes | Discounts |
| 1 | 1 | 2023-01-01 | Pickup | 123 Maple St | New York | 2023-01-05 14:00 | Credit Card | Cash | Extra napkins | 5% on total |
| 2 | 2 | 2023-01-02 | Home Delivery | 456 Oak Ave | San Francisco | 2023-01-06 09:00 | Debit Card | Leave at front door | 2% on total | |
| 3 | 3 | 2023-01-03 | Home Delivery | 789 Pine Rd | Miami | 2023-01-07 18:30 | Cash | Voucher | Call on arrival | No discount |
Customers table
| Customer ID | Name | Primary Phone | Mobile Phone | Address | City | DOB | |
| 1 | John Doe | 555-1234 | 555-5678 | 123 Maple St, 456 Elm St | New York, Chicago | 1985-07-04 | [email protected] |
| 2 | Alice Johnson | 555-8765 | 456 Oak Ave | San Francisco | 1990-11-12 | [email protected] | |
| 3 | Bob Brown | 555-4321 | 789 Pine Rd | Miami | 1978-03-22 | [email protected] |
Order Items table
| Order ID | Item ID | Item Name | Category | Price | Quantity | Discount |
| 1 | 1 | Tea | Beverage | 1.50 | 2 | 10% |
| 1 | 2 | Coffee | Beverage | 3.00 | 1 | |
| 2 | 1 | Milk | Dairy | 2.00 | 1 | |
| 3 | 1 | Biscuit | Snack | 0.99 | 5 | 5% |
| 3 | 2 | Tea | Beverage | 1.50 | 3 | |
| 3 | 3 | Juice | Beverage | 2.10 | 2 |
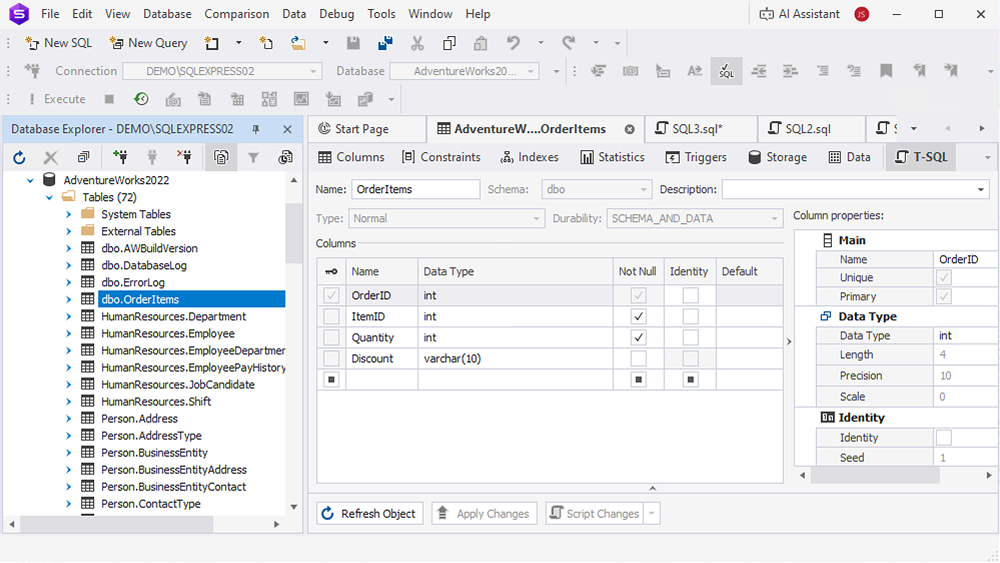
Second Normal Form (2NF)
To bring the tables to the Second Normal Form (2NF), we must remove any partial dependencies, where an attribute is dependent only on part of a composite primary key. 2NF also requires that each table be in 1NF, which we’ve already achieved.
Review of 1NF tables
Let’s ensure there are no partial dependencies on non-primary key attributes in the data.
Orders table
| Order ID | Customer ID | Order Date | Delivery Method | Delivery Address | City | Delivery DateTime | Payment Method 1 | Payment Method 2 | Order Notes | Discounts |
- Order ID is the primary key
- All attributes depend on the Order ID, not just part of it
| Customer ID | Name | Primary Phone | Mobile Phone | Address | City | DOB |
- Customer ID is the primary key
- All attributes depend on the Customer ID, not just part of it
Order Items table
| Order ID | Item ID | Item Name | Category | Price | Quantity | Discount |
- Order ID and Item ID together form the composite primary key
- The attributes such as Item Name, Category, Price, Quantity, and Discount should ideally depend on both Order ID and Item ID, but currently, attributes like Item Name, Category, and Price are likely dependent only on the Item ID. This needs correction for 2NF
Changes required for 2NF
The Order Items table shows partial dependency: Item Name, Category, and Price depend only on Item ID and not on the combination of Order ID and Item ID. We need to move these to a separate table to eliminate partial dependencies.
Revised tables for 2NF:
Items table (New)
| Item ID | Item Name | Category | Price |
| 1 | Tea | Beverage | 1.50 |
| 2 | Coffee | Beverage | 3.00 |
| 3 | Milk | Dairy | 2.00 |
| 4 | Biscuit | Snack | 0.99 |
| 5 | Juice | Beverage | 2.10 |
Order Items table (Updated)
| Order ID | Item ID | Quantity | Discount |
| 1 | 1 | 2 | 10% |
| 1 | 2 | 1 | |
| 2 | 3 | 1 | |
| 3 | 4 | 5 | 5% |
| 3 | 1 | 3 | |
| 3 | 5 | 2 |
Third Normal Form (3NF)
To bring the tables into the Third Normal Form (3NF), we need to ensure that it is already in Second Normal Form (2NF) and additionally remove any transitive dependencies. A transitive dependency occurs when a non-key attribute depends on another non-key attribute.
Review of current tables in 2NF
Let’s examine each table to identify and remove transitive dependencies.
Orders table
| Order ID | Customer ID | Order Date | Delivery Method | Delivery Address | City | Delivery DateTime | Payment Method 1 | Payment Method 2 | Order Notes | Discounts |
- Customer ID could potentially create a transitive dependency, where attributes like Delivery Address and City might depend on Customer ID instead of Order ID.
Customers table
| Customer ID | Name | Primary Phone | Mobile Phone | Address | City | DOB |
- All attributes depend directly on Customer ID. There doesn’t appear to be a transitive dependency within this table.
Items table
| Item ID | Item Name | Category | Price |
- No apparent transitive dependencies, as each attribute depends only on Item ID.
Order Items table
| Order ID | Item ID | Quantity | Discount |
- No transitive dependencies; all attributes depend directly on the composite key (Order ID and Item ID).
Changes required for 3NF
The potential issue in the Orders table concerning the Delivery Address and City being dependent on Customer ID rather than Order ID suggests that these attributes might better fit within a separate structure linked to customers rather than orders.
Revised tables for 3NF
Delivery Info table (New)
| Customer ID | Delivery Address | City |
| 1 | 123 Maple St | New York |
| 1 | 456 Elm St | Chicago |
| 2 | 456 Oak Ave | San Francisco |
| 3 | 789 Pine Rd | Miami |
Orders table (Updated)
| Order ID | Customer ID | Order Date | Delivery Method | Delivery DateTime | Payment Method 1 | Payment Method 2 | Order Notes | Discounts |
| 1 | 1 | 2023-01-01 | Pickup | 2023-01-05 14:00 | Credit Card | Cash | Extra napkins | 5% on total |
| 2 | 2 | 2023-01-02 | Home Delivery | 2023-01-06 09:00 | Debit Card | Leave at front door | 2% on total | |
| 3 | 3 | 2023-01-03 | Home Delivery | 2023-01-07 18:30 | Cash | Voucher | Call on arrival | No discount |
Boyce-Codd Normal Form (BCNF)
To achieve the Boyce-Codd Normal Form (BCNF), we must ensure that the database is already in Third Normal Form (3NF) and additionally, every determinant (an attribute or set of attributes on which some other attribute fully functionally depends) must be a candidate key. BCNF is particularly focused on resolving anomalies caused by functional dependencies where the determinant is not a candidate key.
Review of current tables for BCNF
Let’s examine each table to check for functional dependencies and ensure that each determinant is a candidate key.
Orders table
| Order ID | Customer ID | Order Date | Delivery Method | Delivery DateTime | Payment Method 1 | Payment Method 2 | Order Notes | Discounts |
- Order ID is the primary key.
- All attributes are functionally dependent on Order ID.
- There are no dependencies where a non-candidate key is a determinant.
Customers table
| Customer ID | Name | Primary Phone | Mobile Phone | DOB |
- Customer ID is the primary key.
- All attributes depend directly on Customer ID.
- No attribute determines another outside of its dependency on the primary key.
Delivery Info table
| Customer ID | Delivery Address | City |
- Customer ID could be considered a primary key if we assume each customer has a unique delivery address. However, if customers can have multiple delivery addresses, then Customer ID combined with Delivery Address should form a composite key.
- To resolve potential issues, we must ensure that each record in this table can be uniquely identified by the combination of Customer ID and Delivery Address.
Items table
| Item ID | Item Name | Category | Price |
- Item ID is the primary key.
- All attributes are functionally dependent on Item ID.
Order Items table
| Order ID | Item ID | Quantity | Discount |
- Order ID and Item ID form a composite key.
- Quantity and Discount are dependent on this composite key.
Changes for BCNF
Delivery Info table (revised for BCNF): Assuming that customers can have multiple delivery addresses, we should adjust the primary key.
| Customer ID | Delivery Address | City |
- Treat Customer ID and Delivery Address as a composite key.
Fourth Normal Form (4NF)
Moving to the Fourth Normal Form (4NF) involves ensuring that the database is already in Boyce-Codd Normal Form (BCNF) and additionally eliminating any multi-valued dependencies that are not functional dependencies. Multi-valued dependencies occur when one attribute in a table can take on multiple independent values from another attribute, independently of any other attribute.
Review of current tables for 4NF
To ensure tables are in 4NF, we need to confirm that there are no multi-valued dependencies unless they are on a superkey.
Orders table
| Order ID | Customer ID | Order Date | Delivery Method | Delivery DateTime | Payment Method 1 | Payment Method 2 | Order Notes | Discounts |
- Order ID is the primary key.
- All attributes depend on the primary key.
- The potential issue could arise with Payment Method 1 and Payment Method 2 being split as separate attributes rather than part of a single multi-valued attribute.
Customers table
| Customer ID | Name | Primary Phone | Mobile Phone | DOB |
- Customer ID is the primary key.
- No multi-valued dependencies, as all attributes directly depend on the primary key.
Delivery Info table
| Customer ID | Delivery Address | City |
- Composite key: Customer ID and Delivery Address.
- No multi-valued dependencies as City depends on Delivery Address, and all attributes are functionally dependent on the composite key.
Items table
| Item ID | Item Name | Category | Price |
- Item ID is the primary key.
- No multi-valued dependencies, each attribute directly depends on the primary key.
Order Items table
| Order ID | Item ID | Quantity | Discount |
- Composite key: Order ID and Item ID.
- No multi-valued dependencies, as Quantity and Discount depend on the composite key.
Changes for 4NF
Orders table (revised for 4NF)
- To address the issue with payment methods, we should consider normalizing the payment methods into a separate table to eliminate any multi-valued dependency concerns.
Payment Methods table (New)
| Order ID | Payment Method |
| 1 | Credit Card |
| 1 | Cash |
| 2 | Debit Card |
| 3 | Cash |
| 3 | Voucher |
The final listing of all normalized tables, including their data:
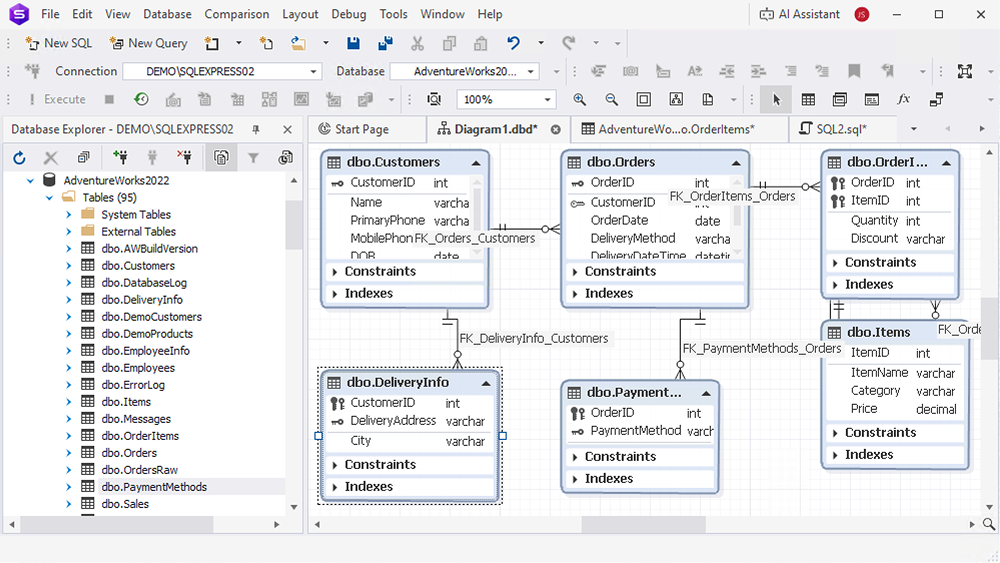
1. Orders table
This table contains order-level details.
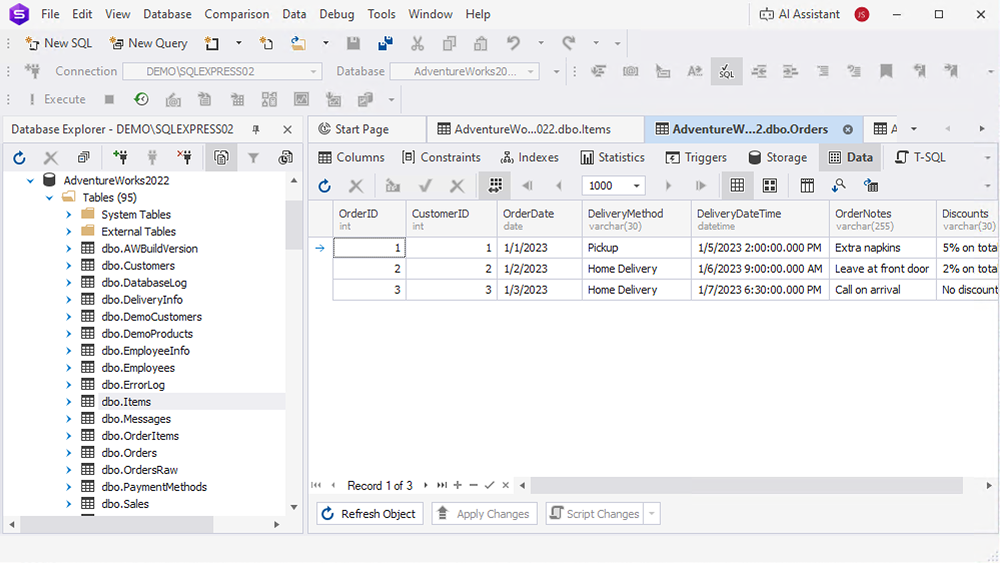
| Order ID | Customer ID | Order Date | Delivery Method | Delivery DateTime | Order Notes | Discounts |
| 1 | 1 | 2023-01-01 | Pickup | 2023-01-05 14:00 | Extra napkins | 5% on total |
| 2 | 2 | 2023-01-02 | Home Delivery | 2023-01-06 09:00 | Leave at front door | 2% on total |
| 3 | 3 | 2023-01-03 | Home Delivery | 2023-01-07 18:30 | Call on arrival | No discount |
2. Customers table
This table holds customer-specific information.
| Customer ID | Name | Primary Phone | Mobile Phone | DOB | |
| 1 | John Doe | 555-1234 | 555-5678 | 1985-07-04 | [email protected] |
| 2 | Alice Johnson | 555-8765 | 1990-11-12 | [email protected] | |
| 3 | Bob Brown | 555-4321 | 1978-03-22 | [email protected] |
3. Delivery Info table
This table contains multiple delivery addresses and their corresponding cities for each customer.
| Customer ID | Delivery Address | City |
| 1 | 123 Maple St | New York |
| 1 | 456 Elm St | Chicago |
| 2 | 456 Oak Ave | San Francisco |
| 3 | 789 Pine Rd | Miami |
4. Items table
This table stores item-specific details.
| Item ID | Item Name | Category | Price |
| 1 | Tea | Beverage | 1.50 |
| 2 | Coffee | Beverage | 3.00 |
| 3 | Milk | Dairy | 2.00 |
| 4 | Biscuit | Snack | 0.99 |
| 5 | Juice | Beverage | 2.10 |
5. Order Items table
This table records the relationship between orders and items, including quantities and discounts.
| Order ID | Item ID | Quantity | Discount |
| 1 | 1 | 2 | 10% |
| 1 | 2 | 1 | |
| 2 | 3 | 1 | |
| 3 | 4 | 5 | 5% |
| 3 | 1 | 3 | |
| 3 | 5 | 2 |
6. Payment Methods table
This table manages payment methods for each order.
| Order ID | Payment Method |
| 1 | Credit Card |
| 1 | Cash |
| 2 | Debit Card |
| 3 | Cash |
| 3 | Voucher |
List of the keys
| Table | Key Type | Key Name | Referenced Table | Purpose |
| Customers | Primary Key | CustomerID | – | Uniquely identifies each customer. |
| DeliveryInfo | Primary Key | (CustomerID, DeliveryAddress) | – | Ensures unique delivery addresses for each customer. |
| DeliveryInfo | Foreign Key | CustomerID → Customers.CustomerID | Customers | Links delivery addresses to the corresponding customer. |
| Items | Primary Key | ItemID | – | Uniquely identifies each item. |
| Orders | Primary Key | OrderID | – | Uniquely identifies each order. |
| Orders | Foreign Key | CustomerID → Customers.CustomerID | Customers | Links orders to the customer who placed them. |
| OrderItems | Primary Key | (OrderID, ItemID) | – | Ensures no duplicate item records for the same order. |
| OrderItems | Foreign Key | OrderID → Orders.OrderID | Orders | Links items to their corresponding order. |
| OrderItems | Foreign Key | ItemID → Items.ItemID | Items | Links items in orders to their details in the Items table. |
| PaymentMethods | Primary Key | (OrderID, PaymentMethod) | – | Ensures unique payment methods per order. |
| PaymentMethods | Foreign Key | OrderID → Orders.OrderID | Orders | Links payment methods to their corresponding order. |
List of the relationships
| Relationship | From Table | To Table | Key | Purpose |
| Customer and Orders | Orders | Customers | CustomerID → Customers.CustomerID | Links orders to the customer who placed them. |
| Customer and DeliveryInfo | DeliveryInfo | Customers | CustomerID → Customers.CustomerID | Links delivery addresses to customers. |
| Order and OrderItems | OrderItems | Orders | OrderID → Orders.OrderID | Links ordered items to their parent orders. |
| Item and OrderItems | OrderItems | Items | ItemID → Items.ItemID | Links items purchased to their details. |
| Order and PaymentMethods | PaymentMethods | Orders | OrderID → Orders.OrderID | Links payment methods to their parent orders. |
Original table functional dependencies
| Functional Dependency | Explanation |
| OrderID → Customer Info, Order Date, Delivery Info, Payment Methods, Order Notes, Discounts | All order-level attributes depend on OrderID. |
| Customer Info → Name, Primary Phone, Mobile Phone, DOB, Email | Customer-specific attributes depend only on the customer’s identity (Customer Info). |
| OrderID, Item Name → Price, Quantity, Discount, Category | Item-specific attributes like Price and Category depend on Item Name rather than OrderID. |
| OrderID →→ Payment Methods | Multi-valued dependency exists because orders can have multiple payment methods. |
Normalization stages and dependency removal
| Normalization Stage | Dependency Issue | Solution |
| 1NF | Repeating groups in Customer Info, Order Details, Payment Methods. | Split concatenated fields into atomic values; create separate rows for multiple items and payments. |
| 2NF | Partial dependency: Item Name, Price, Category depend only on ItemID. | Move item details to a separate Items table. Update OrderItems to store only quantities and discounts. |
| 3NF | Transitive dependency: Delivery Address and City depend on CustomerID. | Create a DeliveryInfo table to store delivery addresses and cities for each customer. |
| BCNF | Determinant issue: OrderID →→ Payment Methods where Payment Method is not a candidate key. | Create a PaymentMethods table with a composite key (OrderID, PaymentMethod). |
| 4NF | Multi-valued dependency: Multiple payment methods for each OrderID. | Ensure PaymentMethods table resolves multi-valued dependency by storing one method per row. |
ER diagram
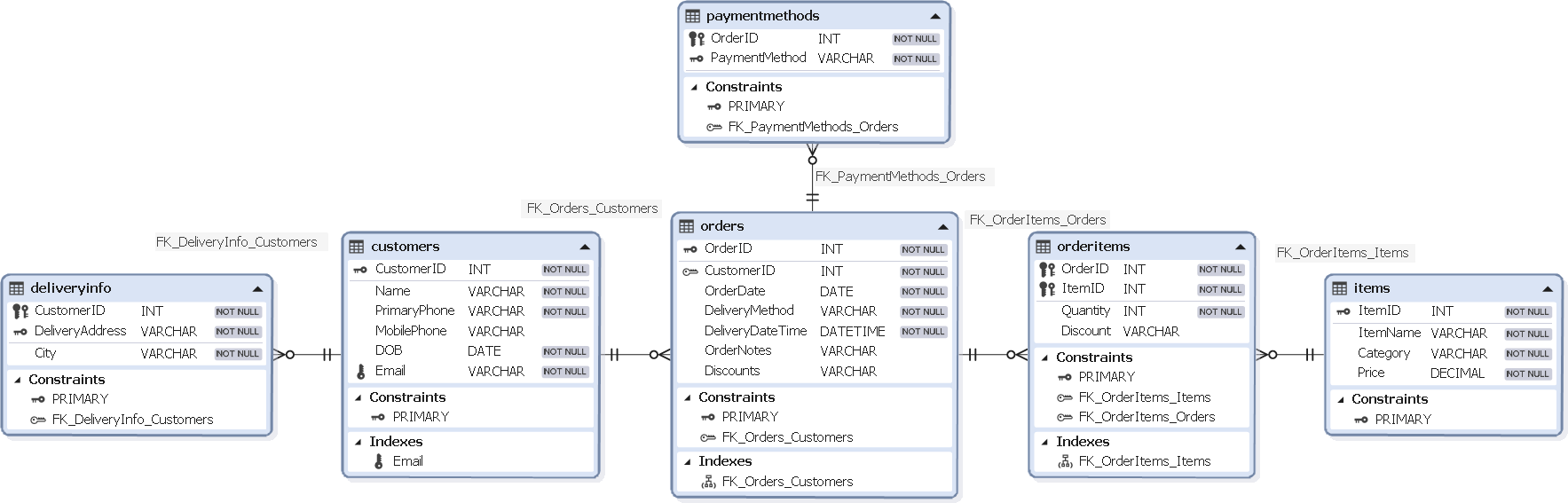
SQL script
-- Customers table
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(50) NOT NULL,
PrimaryPhone VARCHAR(15) NOT NULL,
MobilePhone VARCHAR(15),
DOB DATE NOT NULL,
Email VARCHAR(50) UNIQUE NOT NULL
);
-- Delivery Info table
CREATE TABLE DeliveryInfo (
CustomerID INT,
DeliveryAddress VARCHAR(100) NOT NULL,
City VARCHAR(50) NOT NULL,
PRIMARY KEY (CustomerID, DeliveryAddress),
CONSTRAINT FK_DeliveryInfo_Customers FOREIGN KEY (CustomerID)
REFERENCES Customers(CustomerID)
);
-- Items table
CREATE TABLE Items (
ItemID INT PRIMARY KEY,
ItemName VARCHAR(50) NOT NULL,
Category VARCHAR(30) NOT NULL,
Price DECIMAL(5,2) NOT NULL
);
-- Orders table
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT NOT NULL,
OrderDate DATE NOT NULL,
DeliveryMethod VARCHAR(30) NOT NULL,
DeliveryDateTime DATETIME NOT NULL,
OrderNotes VARCHAR(255),
Discounts VARCHAR(30),
CONSTRAINT FK_Orders_Customers FOREIGN KEY (CustomerID)
REFERENCES Customers(CustomerID)
);
-- Order Items table
CREATE TABLE OrderItems (
OrderID INT,
ItemID INT,
Quantity INT NOT NULL,
Discount VARCHAR(10),
PRIMARY KEY (OrderID, ItemID),
CONSTRAINT FK_OrderItems_Orders FOREIGN KEY (OrderID)
REFERENCES Orders(OrderID),
CONSTRAINT FK_OrderItems_Items FOREIGN KEY (ItemID)
REFERENCES Items(ItemID)
);
-- Payment Methods table
CREATE TABLE PaymentMethods (
OrderID INT,
PaymentMethod VARCHAR(30) NOT NULL,
PRIMARY KEY (OrderID, PaymentMethod),
CONSTRAINT FK_PaymentMethods_Orders FOREIGN KEY (OrderID)
REFERENCES Orders(OrderID)
);
-- Insert Data into Customers table
INSERT INTO Customers (CustomerID, Name, PrimaryPhone, MobilePhone, DOB, Email) VALUES
(1, 'John Doe', '555-1234', '555-5678', '1985-07-04', '[email protected]'),
(2, 'Alice Johnson', '555-8765', NULL, '1990-11-12', '[email protected]'),
(3, 'Bob Brown', '555-4321', NULL, '1978-03-22', '[email protected]');
-- Insert Data into DeliveryInfo table
INSERT INTO DeliveryInfo (CustomerID, DeliveryAddress, City) VALUES
(1, '123 Maple St', 'New York'),
(1, '456 Elm St', 'Chicago'),
(2, '456 Oak Ave', 'San Francisco'),
(3, '789 Pine Rd', 'Miami');
-- Insert Data into Items table
INSERT INTO Items (ItemID, ItemName, Category, Price) VALUES
(1, 'Tea', 'Beverage', 1.50),
(2, 'Coffee', 'Beverage', 3.00),
(3, 'Milk', 'Dairy', 2.00),
(4, 'Biscuit', 'Snack', 0.99),
(5, 'Juice', 'Beverage', 2.10);
-- Insert Data into Orders table
INSERT INTO Orders (OrderID, CustomerID, OrderDate, DeliveryMethod, DeliveryDateTime, OrderNotes, Discounts) VALUES
(1, 1, '2023-01-01', 'Pickup', '2023-01-05 14:00', 'Extra napkins', '5% on total'),
(2, 2, '2023-01-02', 'Home Delivery', '2023-01-06 09:00', 'Leave at front door', '2% on total'),
(3, 3, '2023-01-03', 'Home Delivery', '2023-01-07 18:30', 'Call on arrival', 'No discount');
-- Insert Data into OrderItems table
INSERT INTO OrderItems (OrderID, ItemID, Quantity, Discount) VALUES
(1, 1, 2, '10%'),
(1, 2, 1, NULL),
(2, 3, 1, NULL),
(3, 4, 5, '5%'),
(3, 1, 3, NULL),
(3, 5, 2, NULL);
-- Insert Data into PaymentMethods table
INSERT INTO PaymentMethods (OrderID, PaymentMethod) VALUES
(1, 'Credit Card'),
(1, 'Cash'),
(2, 'Debit Card'),
(3, 'Cash'),
(3, 'Voucher');The final schema consists of separate tables for orders, customers, items, order items, delivery information, and payment methods. This design removed insertion anomalies (new data can be added without affecting unrelated data), update anomalies (data is updated in one place), and deletion anomalies (removing a record does not result in loss of critical data).
Primary keys ensure each record is uniquely identifiable, and foreign keys enforce relationships between tables. Data is now stored efficiently, with no duplication, making the database easier to maintain and scale. Queries are simplified and performance is improved by organizing data logically into smaller, related tables.
Database normalization vs. denormalization
What is normalization in database compared to denormalization? Let’s say you’re organizing your stuff. You can either keep everything perfectly sorted in labeled boxes (normalization), or you can group things more loosely so they’re quicker to grab when you need them (denormalization). That’s basically the difference between normalization and denormalization in a database.
So, which one should you choose? It depends on your goal. If you need your data to be clean, accurate, and easy to update, go with normalization. If your app is slow and users are just looking at the data (not updating it), denormalization might help. Some systems even use a mix of both — normalizing some parts and denormalizing others, where performance really matters.
Benefits of denormalization
Denormalization means adding a bit of “organized mess” to your database to make things faster. Sounds weird, right? But sometimes, it actually makes your system work better, especially when speed matters more than perfect organization.
Where does denormalization make sense?
1. You read data way more than you write it
Imagine you have a website or app where people are constantly looking up stuff (like product pages, user profiles, or dashboards), but not changing things often.
If your system is mostly read-heavy (meaning lots of people are viewing data, but not editing it), then denormalization can make those views load faster, because the data is already bundled together in one place, ready to go.
2. You’re running reports and summaries all the time
In business, people love charts, graphs, and dashboards. These tools often run on something called OLAP systems (Online Analytical Processing), which are built for analysis, not updates.
If your database feeds dashboards with sales totals, customer stats, or daily performance metrics, denormalization helps by storing pre-calculated data. That way, the system doesn’t have to do all the math whenever someone opens the dashboard.
3. You want faster performance, even if it means some repetition
Let’s say you have a product and its category listed in two separate places. In a normalized world, the database has to go look up the category each time it shows a product. But in a denormalized setup, you just copy the category name right next to the product.
Yes, it’s repeated — but the app loads quicker because the system doesn’t have to jump between tables.
Normalization in SQL (including SQL Server)
So you’ve got a bunch of data and you’re using SQL or SQL Server to manage it. Great! But now you’re hearing things like “normalize your tables” and wondering what that even means. This is part of DBMS normalization. What is normalization in DBMS? It’s the process of structuring a database to reduce redundancy and improve data integrity. You can do this through management of information in related tables (with example tables) such as separating customer details into a “Customers” table and ordering information into an “Orders” table.
Normalization in SQL is all about keeping your data clean, organized, and free from unnecessary duplicates. Both SQL and SQL Server are designed to help you do this with SQL normal forms using tables, relationships, and constraints — like rules that make sure your data behaves the way it should.
We can easily explain normalization in SQL with examples. How SQL and SQL Server help with normalization?
- Table Design
You create different tables for different types of information. For example, one table for customers, another for orders, and another for products. Each table has its own focus — no mixing and matching. - Relationships
Instead of repeating the same info over and over, you connect your tables. For example, each order “points” to a customer instead of storing all the customer’s info again. - Constraints
You can tell SQL to enforce rules — like making sure an order always connects to a real customer. These rules are called constraints, and they help keep everything in line.
SQL query examples for normalization
What is normalization in SQL? Let’s say we’re building a small store database. This is a small tutorial in clear steps with real SQL database normalization examples.
First Normal Form (1NF)
Rule: No repeating groups. Just one value per field.
Bad idea:
-- Not normalized
CREATE TABLE Customers (
CustomerID INT,
Name VARCHAR(100),
PhoneNumbers VARCHAR(255) -- Stores multiple numbers in one field
);Better (1NF):
-- One phone number per row
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(100)
);
CREATE TABLE CustomerPhones (
CustomerID INT,
PhoneNumber VARCHAR(20),
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);Now, each phone number is separate, and the data is cleaner.
Second Normal Form (2NF)
Rule: No partial dependency on part of the key.
Imagine a table that lists courses students take, along with their name:
-- Not 2NF: student name depends only on StudentID, not the full combo
CREATE TABLE Enrollments (
StudentID INT,
CourseID INT,
StudentName VARCHAR(100)
);Better (2NF):
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
StudentName VARCHAR(100)
);
CREATE TABLE Enrollments (
StudentID INT,
CourseID INT,
FOREIGN KEY (StudentID) REFERENCES Students(StudentID)
);Now, the student’s name lives in just one place.
Third Normal Form (3NF)
Rule: Get rid of columns that don’t depend directly on the primary key.
Imagine a table where we store a customer’s ZIP code and city:
-- Not 3NF: city depends on ZIP code, not customer
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(100),
ZIPCode VARCHAR(10),
City VARCHAR(100)
);Better (3NF):
CREATE TABLE ZIPCodes (
ZIPCode VARCHAR(10) PRIMARY KEY,
City VARCHAR(100)
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(100),
ZIPCode VARCHAR(10),
FOREIGN KEY (ZIPCode) REFERENCES ZIPCodes(ZIPCode)
);Now, if a city changes (rare, but still), you update it in one place only.
You can use these same principles of database normalization examples in SQL Server too. SQL Server lets you do more, like designing diagrams, setting up indexes for faster searching, and writing stored procedures. But at the core, normalization in SQL Server all starts with a smart, normalized table structure.
Common mistakes in database normalization
SQL database normalization helps keep your database tidy and easy to manage, but it’s also easy to mess up if you’re not careful:
1. Skipping normalization altogether
Some folks just throw all their data into one big table, including names, orders, addresses, product details — everything becomes jumbled together. Sure, it might work for a small project, but it quickly becomes a mess.
You end up repeating the same data over and over. Also, it’s harder to make updates without causing mistakes
2. Not going far enough
Sometimes, people apply only the first normal form (1NF) and stop there, thinking they’re done. But there could still be duplicate info or weird dependencies hiding in the table.
Fix it by taking the time to understand and apply 2NF and 3NF to normalization in SQL.
3. Over-normalizing
Breaking your data into too many tiny tables can make things harder, not better. You’ll spend more time writing complex queries just to get a simple result.
Sometimes it’s okay to repeat small bits of data if it makes your app faster and easier to use.
4. Ignoring performance
Normalization in SQL is great for keeping data clean, but it can slow things down if not done carefully. If your database has to jump across too many tables to find something, performance can take a hit.
Tip: Make SQL data normalization for clarity, but test for speed. Denormalize some parts if you need faster results (especially in read-heavy apps like dashboards).
Best practices for database normalization
Normalization in SQL helps you organize your database so it’s clean, clear, and easy to manage. But like organizing anything—your room, your tools, your kitchen—there’s a smart way to do it, and there’s a way that can make life harder than it needs to be.
1. Understand what you’re storing (and why)
Before you even start creating tables, think about what kind of data you have and how it’s used. Ask yourself:
- What’s the core info I need to keep?
- Which pieces of data repeat?
- How are things connected?
2. Start with the first three normal forms
Don’t worry about fancy, advanced stuff like 4NF or 5NF right away. Just focus on the basics:
- 1NF: Keep one value per cell (no lists or combined info)
- 2NF: Make sure everything in a table depends on the full primary key
- 3NF: Remove fields that don’t directly depend on the main thing in the table.
3. Use foreign keys to keep data connected
When you split data into multiple tables, make sure they stay linked using foreign keys.
For example, if you separate customers and orders, orders should include the customer’s ID to stay connected.
4. Don’t over-normalize
Yes, it’s possible to go too far. If your database ends up with dozens of tiny tables and every simple query needs five joins… that’s a red flag.
Ask yourself:
- Am I breaking this up because it’s helpful, or just following rules too strictly?
- Is this extra table actually useful?
Sometimes, a little redundancy is okay if it keeps things simpler or faster.
5. Keep performance in mind
SQL normalization keeps data tidy, but if users have to wait too long to see something, it’s a problem.
- Avoid too many joins in critical queries
- Consider denormalizing parts of your database if speed becomes an issue (e.g., storing total prices or repeated names to save time).
You can always clean it up later if it gets messy — performance should feel smooth first.
How dbForge Edge can help with database normalization
Trying to keep your database clean and well-organized? dbForge Edge can be a big help, especially if you’re new to SQL normalization or just want to save time and avoid mistakes.
It’s an all-in-one tool built for developers and database admins (DBAs) who work with SQL databases.
dbForge Edge makes normalization in database simple:
- Build visually: Use drag-and-drop tools to create tables and links — no need to write SQL from scratch to build database design.
- Clean up data: Spot and fix duplicate or messy data by organizing it into proper tables.
- Write smart SQL: Easily write and test queries to control how your data works together.
- See the big picture: View your whole database as a diagram to find and fix issues fast.
Want to see how it works? You can download a free trial and try it out with your own project. It’s a great way to learn, explore, and make your database life a lot easier.
Conclusion
If you’ve made it this far — nice job! By now, you should have a solid idea of what normalization in database is all about and why it matters. We talked about how normalization helps keep your data clean and consistent and improve the overall performance and structure of your database
And let’s not forget how much easier this whole process becomes when you have the right tool. dbForge Edge takes the stress out of normalization by letting you:
- Visualize your database design
- Create and manage tables and relationships
- Write and test SQL queries in one place
- Spot problems before they become real headaches.
If you’re building or fixing a database, don’t do it all by hand. Try dbForge Edge and see how smooth your workflow becomes. Download the free trial and give it a go!
FAQ
How does normalization in SQL Server differ from other database systems?
Normalization principles are universal and apply across all relational databases, including SQL Server, MySQL, PostgreSQL, and Oracle.
What are the benefits of applying SQL data normalization to a large database?
Using data normalization for a database leads to reduced data redundancy, improved data integrity, more efficient updates and deletes, optimized storage, and better scalability.
What are the common errors to avoid when implementing database normalization in SQL?
The most common errors in database normalization often come from over-normalization, as splitting tables too much can lead to complex joins and poor performance. Another mistake is ignoring business logic and using poor key design with unclear primary and foreign key relationships, which leads to orphaned records or update issues.
Can dbForge Edge assist in visualizing SQL normalization for database design?
Yes, dbForge Edge includes tools that make normalization and schema design much easier, letting you visualize table relationships and dependencies to support normalization decisions, identify normalization issues across environments using schema and data comparison, spot redundancy or transitive dependencies in datasets, and refactor the database.
How can I integrate dbForge Edge with my existing SQL database to streamline the normalization process?
dbForge Edge provides multiple tools to assist you with database normalization. To start using it on an existing SQL Server database, you must connect it to dbForge Studio for SQL Server, which comes as part of it. To do it, click New Connection on the Database menu and wait for the Database Connection Properties dialog box to open. On the General tab, specify the connection details: Server and Authentication mode. Next, provide credentials for the database you plan to work with: user login, password, and database name. Select the Environment category and specify a connection name if you want to create a custom name for the connection. When all the connection details are provided, you can either verify them by clicking Test Connection or click Connect to set it up and start using dbForge Edge for database normalization.
How does normalization in a database help avoid redundancy?
Normalization in a database can help organize data into related tables and eliminate duplicate information, so that each value is stored only once. When using this technique, you ensure relationships are defined through foreign keys, avoiding the need to repeat data. As a result, this approach reduces inconsistencies and helps avoid redundancy.