I have always liked simple questions with lots of pitfalls. Here is the one: how do you count the total number of records in a table? At first sight, it’s a snap, but if you dig a little deeper, you can reveal lots of peculiar nuances.
So, let’s start from a simple thing. Do the following queries differ in terms of the end result?
SELECT COUNT(*) FROM Sales.SalesOrderDetail SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail
Most of you will say there is no difference. The given queries will return the identical result, but COUNT will return the value of the INT type, while COUNT_BIG will return the value of the BIGINT type.
If we analyze the execution plan, we will notice the differences, that are often overlooked. When using COUNT, the plan will show the Compute Scalar operation.
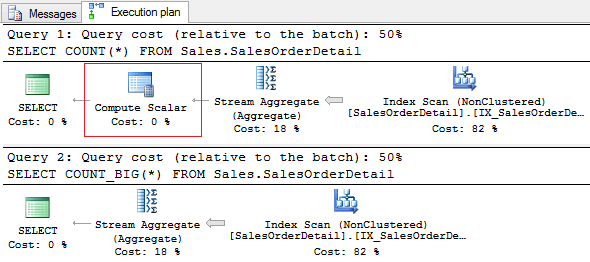
If we take a look at the operator properties, we will see the following:
[Expr1003] = Scalar Operator(CONVERT_IMPLICIT(int,[Expr1004],0))
It happens because COUNT_BIG is used implicitly when calling COUNT, and then the result is converted into INT.
Remember that data type conversion increases the processor load. Many of you may say that this operator is not a big deal in terms of execution. However, there is a thing worth mentioning – SQL Server tends to underestimate the Compute Scalar operators. Nevertheless, the aforesaid example does not require worrying about performance – the truncation of Int64 to Int32 does not require much resources.
I also know people who like using SUM instead of COUNT:
SELECT SUM(1) FROM Sales.SalesOrderDetail
This variant is approximately identical to COUNT – we will also get the excessive Compute Scalar in execution plan:
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
Let’s explode one myth. If you indicate a constant value in COUNT, the query won’t become faster, since the optimizer create identical execution plan for these queries:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail SELECT COUNT_BIG(1) FROM Sales.SalesOrderDetail
Now, let’s dwell on performance issues.
If we use the aforesaid queries, we should use Full Index Scan (or Full Table Scan if it is a heap table) for counting SQL Server records. Anyways, these operations are far from being fast. The best way to get the record count is to use the sys.dm_db_partition_stats or sys.partitions system views (there is also sysindexes, but it has been left for the backward compatibility with SQL Server 2000).
USE AdventureWorks2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
GO
SELECT COUNT_BIG(*)
FROM Sales.SalesOrderDetail
SELECT SUM(p.[rows])
FROM sys.partitions p
WHERE p.[object_id] = OBJECT_ID('Sales.SalesOrderDetail')
AND p.index_id < 2
SELECT SUM(s.row_count)
FROM sys.dm_db_partition_stats s
WHERE s.[object_id] = OBJECT_ID('Sales.SalesOrderDetail')
AND s.index_id < 2
If we compare execution plans, the access to system views is less consuming:
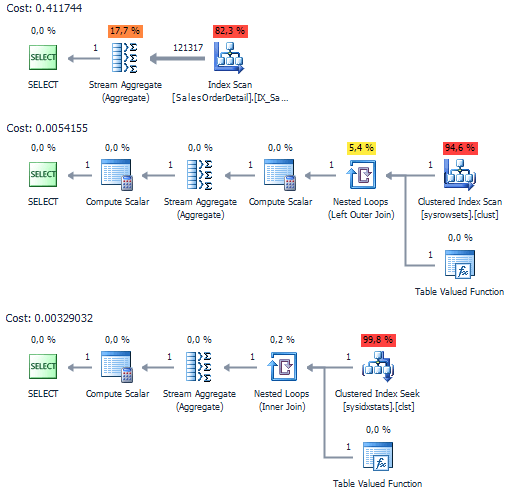
If we test on AdventureWorks, the advantages of system views are not that obvious:
Table 'SalesOrderDetail'. Scan count 1, logical reads 276, ... SQL Server Execution Times: CPU time = 12 ms, elapsed time = 26 ms. Table 'sysrowsets'. Scan count 1, logical reads 5, ... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 4 ms. Table 'sysidxstats'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 2 ms, elapsed time = 1 ms.
Execution time for the partitioned table with 30 millions records:
Table 'big_test'. Scan count 6, logical reads 114911, ... SQL Server Execution Times: CPU time = 4859 ms, elapsed time = 5079 ms. Table 'sysrowsets'. Scan count 1, logical reads 25, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms. Table 'sysidxstats'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms.
In case you need to check the records availability in a table, the usage of metadata does not deliver any particular advantages (as it has been showed above).
IF EXISTS(SELECT * FROM Sales.SalesOrderDetail)
PRINT 1
IF EXISTS(
SELECT * FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('Sales.SalesOrderDetail')
AND row_count > 0
) PRINT 1
Table 'SalesOrderDetail'. Scan count 1, logical reads 2,... SQL Server Execution Times: CPU time = 1 ms, elapsed time = 3 ms. Table 'sysidxstats'. Scan count 1, logical reads 2,... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 5 ms.
In practical terms, it will be a bit slower, since SQL Server generates a more complicated execution plan for selection from metadata.
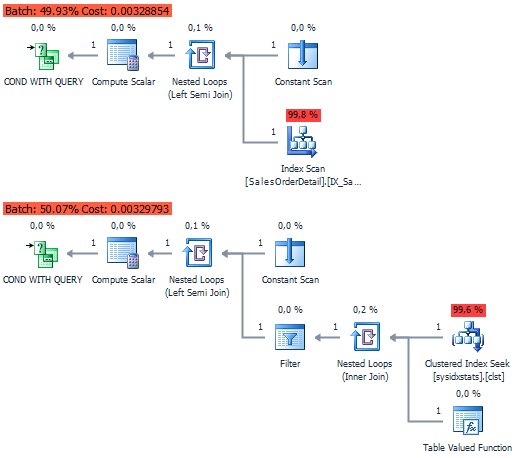
Here is one more case I encountered:
IF (SELECT COUNT(*) FROM Sales.SalesOrderHeader) > 0
PRINT 1
With optimizer, this case can be simplified to the plan we got in EXISTS.
It gets more interesting when we need to count the number of records for all tables at once. In my practice, I encountered several variants.
Variant #1 with applying undocumented procedure, that bypasses all user tables by cursor:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (obj SYSNAME, row_count BIGINT)
GO
EXEC sys.sp_MSForEachTable @command1 = 'INSERT #temp SELECT ''?'', COUNT_BIG(*) FROM ?'
SELECT *
FROM #temp
ORDER BY row_count DESC
Variant #2 – a dynamic SQL that generates the SELECT COUNT(*) queries:
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = STUFF((
SELECT 'UNION ALL SELECT ''' + SCHEMA_NAME(o.[schema_id]) + '.' + o.name + ''', COUNT_BIG(*)
FROM [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + ']'
FROM sys.objects o
WHERE o.[type] = 'U'
AND o.is_ms_shipped = 0
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 10, '') + ' ORDER BY 2 DESC'
PRINT @SQL
EXEC sys.sp_executesql @SQL
Variant #3 – a fast variant for everyday use:
SELECT SCHEMA_NAME(o.[schema_id]), o.name, t.row_count
FROM sys.objects o
JOIN (
SELECT p.[object_id], row_count = SUM(p.row_count)
FROM sys.dm_db_partition_stats p
WHERE p.index_id < 2
GROUP BY p.[object_id]
) t ON t.[object_id] = o.[object_id]
WHERE o.[type] = 'U'
AND o.is_ms_shipped = 0
ORDER BY t.row_count DESC
In spite of all praises I heaped upon system views, there are still some unexpected “pleasures” you may experience when working with them.
I remember an amusing bug – system views were being updated incorrectly during migration from SQL Server 2000 to 2005. The most “lucky” ones were receiving incorrect values of row count in tables from metadata. The restatement was DBCC UPDATEUSAGE.
With SQL Server 2005 SP1, this bug has been fixed and everything seemed to be quite okay. However, I faced the same problem once more when restoring a backup from SQL Server 2005 SP4 to SQL Server 2012 SP2. I couldn’t reproduce it on real environment, that’s why I tricked optimizer a bit:
UPDATE STATISTICS Person.Person WITH ROWCOUNT = 1000000000000000000
Let’s consider a simple example.
Execution of the most tame query began to take longer than usual:
SELECT FirstName, COUNT(*) FROM Person.Person GROUP BY FirstName
Viewing query plan revealed completely inadequate value of EstimatedNumberOfRows:
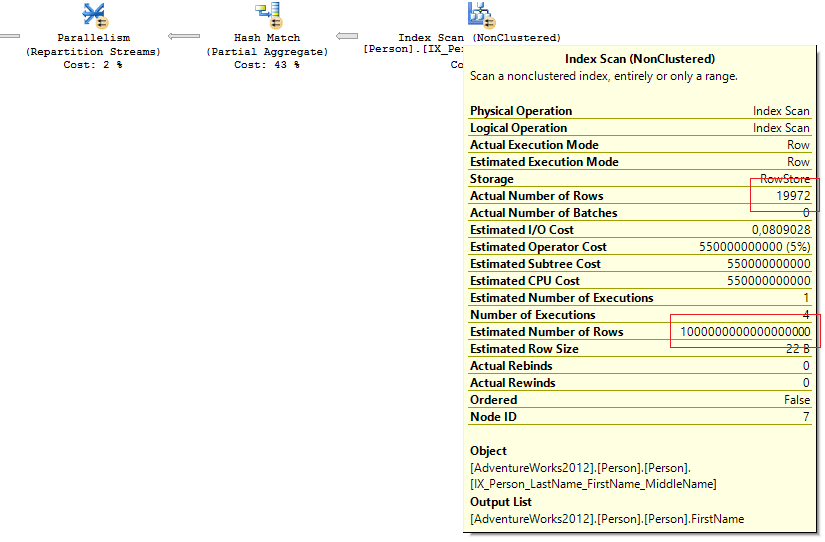
Then, I viewed the clustered index statistics:
DECLARE @SQL NVARCHAR(MAX)
DECLARE @obj SYSNAME = 'Person.Person'
SELECT @SQL = 'DBCC SHOW_STATISTICS(''' + @obj + ''', ' + name + ') WITH STAT_HEADER'
FROM sys.stats
WHERE [object_id] = OBJECT_ID(@obj)
AND stats_id < 2
EXEC sys.sp_executesql @SQL
Everything was all right.

As for the aforementioned system views,
SELECT rowcnt
FROM sys.sysindexes
WHERE id = OBJECT_ID('Person.Person')
AND indid < 2
SELECT SUM([rows])
FROM sys.partitions p
WHERE p.[object_id] = OBJECT_ID('Person.Person')
AND p.index_id < 2
well, they were far from being okay:
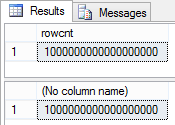
The query did not contain predicates for filtering, and the optimizer chose Full Index Scan. During Full Index/Table Scan, the optimizer takes the expected number of rows from metadata instead of statistics (I’m not quite sure whether it always happens).
It’s no secret that SQL Server generates execution plan on the basis of Estimated number of rows and counts the memory required for its execution. The incorrect evaluation may lead to occupation of excessive memory.
Here is the result of incorrect evaluation of row count:
session_id query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb ---------- ---------------- -------------------- -------------------- -------------------- -------------------- 56 11331568390567 769552 769552 6504 6026
The problem has been resolved in a fairly straightforward way:
DBCC UPDATEUSAGE(AdventureWorks2012, 'Person.Person') WITH COUNT_ROWS DBCC FREEPROCCACHE
After the query recompilation, things settled into shape:
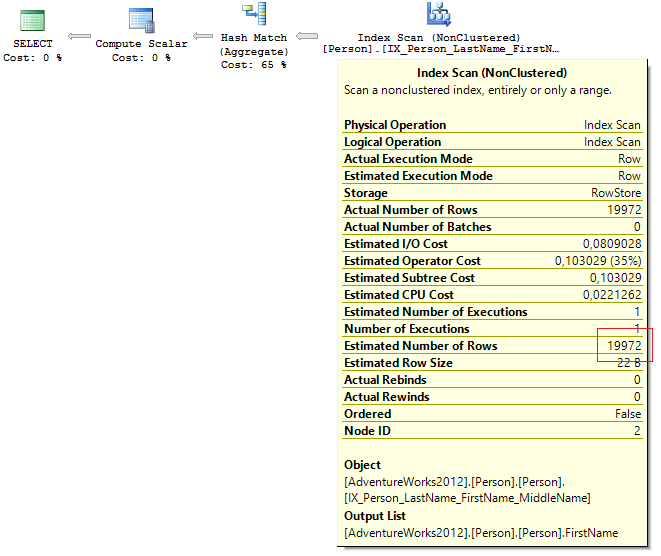
session_id query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb ---------- ------------------- -------------------- -------------------- -------------------- -------------------- 52 0,291925808638711 1168 1168 1024 952
If system views do not serve as a magic wand anymore, what else can we do? Well, we can fall back on the old school practice:
SELECT COUNT_BIG(*) FROM ...
But, I would not rely much on the result during intensive insertion into table. Much less, the “magic” NOLOCK hint still does not guarantee the correct value:
SELECT COUNT_BIG(*) FROM ... WITH(NOLOCK)
As a matter of fact, we need to execute the query under the SERIALIZABLE isolation level to get the correct number of records in the table. Alternatively, we can use the TABLOCKX hint.
SELECT COUNT_BIG(*) FROM ... WITH(TABLOCKX)
In result, we get the exclusive lock of the table for the time of query execution. What is better? The answer is – decide for yourself. My choice is metadata.
It gets yet more interesting, when you need to count the number of rows by condition:
SELECT City, COUNT_BIG(*) FROM Person.[Address] --WHERE City = N'London' GROUP BY City
If there are no frequent insert-delete operations in the table, we can create an indexed view:
IF OBJECT_ID('dbo.CityAddress', 'V') IS NOT NULL
DROP VIEW dbo.CityAddress
GO
CREATE VIEW dbo.CityAddress
WITH SCHEMABINDING
AS
SELECT City, [Rows] = COUNT_BIG(*)
FROM Person.[Address]
GROUP BY City
GO
CREATE UNIQUE CLUSTERED INDEX IX ON dbo.CityAddress (City)
For these queries, the optimizer will generate identical plan based on the clustered index of the view:
SELECT City, COUNT_BIG(*) FROM Person.[Address] WHERE City = N'London' GROUP BY City SELECT * FROM dbo.CityAddress WHERE City = N'London'
Here are the execution plans with and without an indexed view:
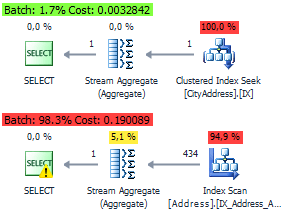
In this post, I wanted to show that there are no ideal solutions for every day of your life. You should act as the occasion requires in every particular case.
All tests have been performed on SQL Server 2012 SP3 (11.00.6020).
Execution plans have been taken from SSMS 2014 and dbForge Studio for SQL Server.
Conclusion
When I need to count the number of table rows, I use metadata – it is the fastest way. Do not be afraid of the old bug case I described.
If there is a need to quickly count the number of rows from a perspective of some field or by condition, I try using indexed views or filtered indexes. It all depends upon the situation.
When a table is small or when productivity issue is not put at stake, the old-school SELECT COUNT(*)… will be the best option.

Nice information. Thanks a lot for explaining.
Thanks, but what if we want to search on certain column in tbl Sales.SalesOrderDetail i.e. where SalesOrderDetail.Date =’01/01/2016
thanks ‘
In this case you need create an indexed view:
CREATE VIEW Sales.vw_SalesOrderDetail
WITH SCHEMABINDING
AS
SELECT [Date], [Rows] = COUNT_BIG(*)
FROM Sales.SalesOrderDetail
GROUP BY [Date]
GO
CREATE UNIQUE CLUSTERED INDEX IX ON Sales.vw_SalesOrderDetail ([Date])
GO
SELECT [Rows]
FROM Sales.vw_SalesOrderDetail
WHERE [Date] = ‘20160101’