
Users should maintain data consistency to ensure accurate database testing and analysis, especially when generating data in dependent columns. For example, they can use formulas, data generators, or post-scripts to fill in columns based on other columns in the table. However, post-scripts may be complicated and affect database performance.
In the article, we’ll explore how to generate values for the referenced columns using dbForge Data Generator for SQL Server. We’ll also discuss common troubleshooting issues and the ways to resolve them.
dbForge Data Generator is a tool to populate tables with realistic random data using basic demo data generators, such as Python, RegExp, Lorem Ipsum, Text File, Files Folder, Weighted List, and others. In addition, it is part of dbForge SQL Tools, an ultimate suite for simplifying complex database tasks and fostering a more agile development environment that establishes heightened productivity through its intuitive interfaces and advanced functionalities.
Contents
- Understanding the requirements
- Offering a solution using dbForge Data Generator for SQL Server
- Setting up the Data Generator
- Using Python for dependent column calculation
- Addressing NULL values in generated data
- Analyzing server-specific considerations
- Troubleshooting common issues
Understanding the requirements
For demonstration purposes, we create a sample database – Tax – and an empty table – dbo.PurchaseData, to populate it with testing data. The table will contain the PurchasePrice and TaxAmount columns.
-- Create the database
CREATE DATABASE Tax;
-- Create the PurchaseData table in the dbo schema
CREATE TABLE dbo.PurchaseData (
PurchaseID INT PRIMARY KEY IDENTITY(1,1),
PurchasePrice MONEY NOT NULL,
TaxAmount MONEY NOT NULL
);Here is what we’ll do to manage dependencies between columns using the Python generator available in the dbForge tool:
- Generate random values for the PurchasePrice column
- Calculate TaxAmount based by multiplying PurchasePrice by 0.15
- Handle NULL values in the generated columns
Offering a solution using dbForge Data Generator for SQL Server
Let us learn how to generate the referenced column values using Data Generator for SQL Server. The workflow would be as follows:
- Setting up the Data Generator
- Using Python for dependent column calculation
- Addressing NULL values in generated data
- Analyzing server-specific considerations
Setting up the Data Generator
To begin, download the dbForge Data Generator from the Devart website and install it on your computer. Once done, open the tool and initiate data generation using one of the following ways:
- On the Start Page, click New Data Generation.
- On the standard toolbar, click New Data Generation.
This will open the Data Generator Project Properties dialog, where you can set up generation options.
On the Connection page, select the required connection and the database in which the table you want to populate is located. Note that if you have not established the server connection, you can create a new one by selecting Manage from the Connection list.
On the Options page, set default data generation options and click Open.
The Data Generation document appears, displaying the settings you can configure for the table.
Using Python for dependent column calculation
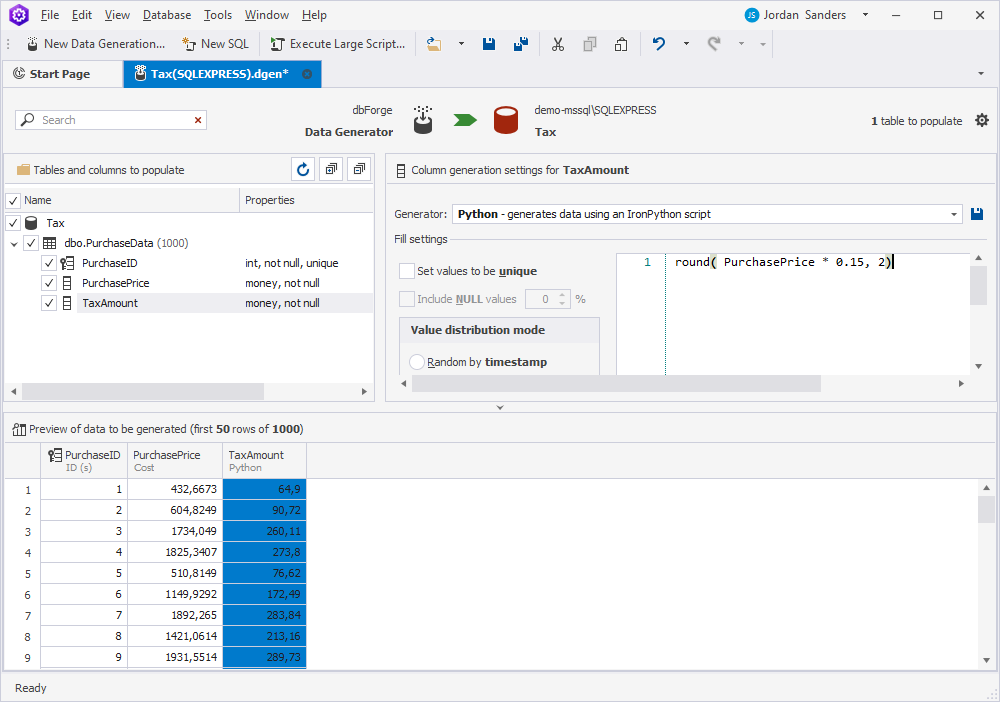
In the Tables and columns to populate tree, select the TaxAmount column. In the Column generation settings for TaxAmount section, select Python from the Generator list. Clear the default text and enter the following expression:
round(PurchasePrice * 0.15, 2)This expression performs the following actions:
- Calculates 15% of the
PurchasePrice. - The
roundfunction rounds the result of the multiplication to represent a monetary amount with two decimal places. 2specifies that the rounding should be to two decimal places.
The TaxAmount column will be automatically re-calculated.
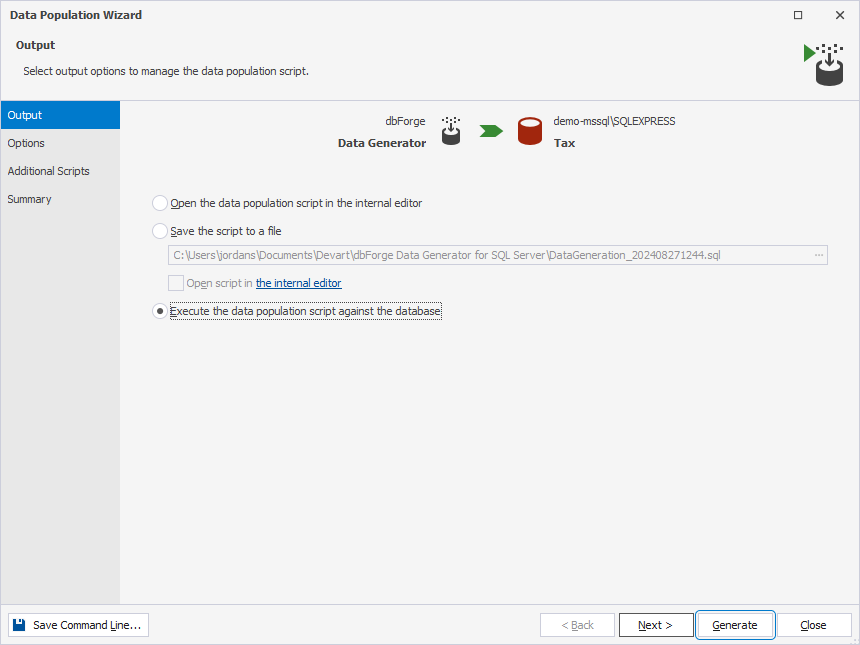
On top of the document, click Populate data to the target database. This will open the Data Population Wizard, where you need to select the Execute the data population script against the database output option and click Generate.
Then, click New SQL on the toolbar and execute the SELECT query to verify that the data has been generated:
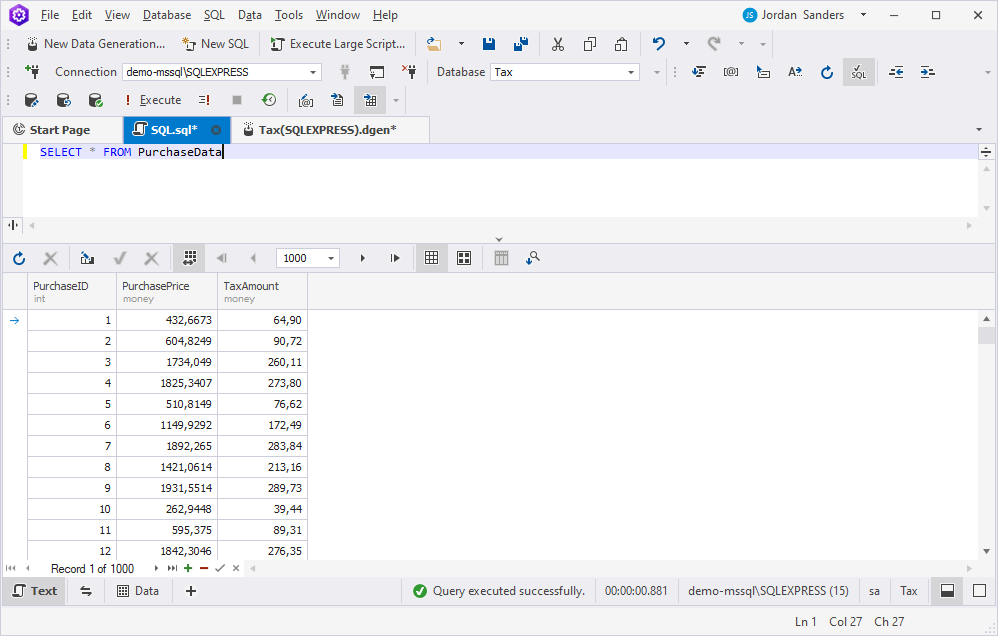
Done! Let us now consider some cases where you may encounter errors when generating data for SQL tables.
Addressing NULL values in generated data
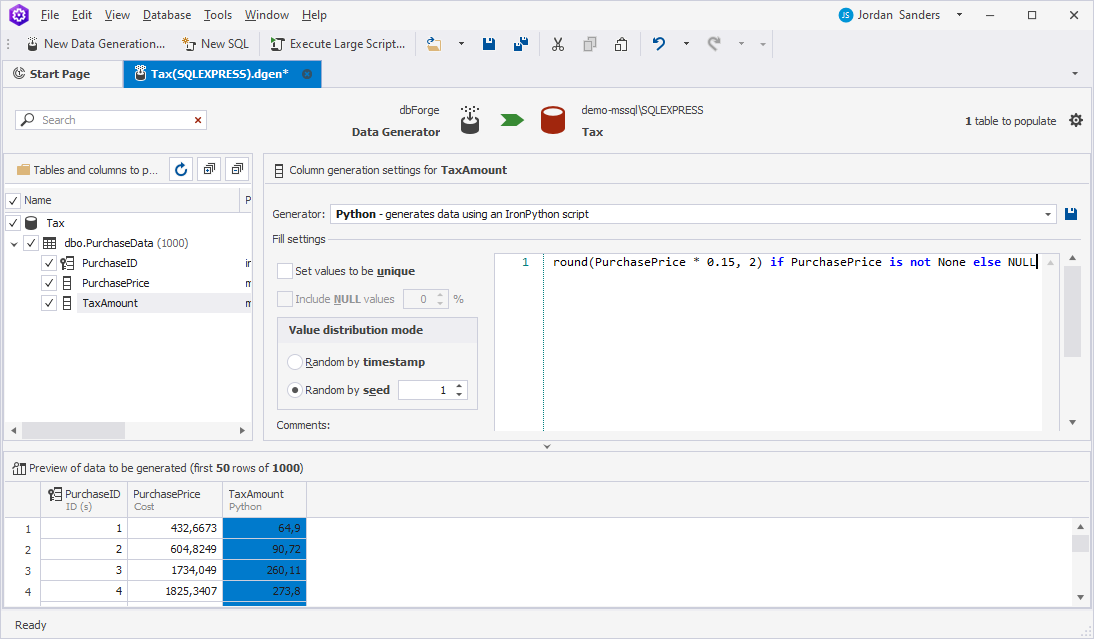
If there is a NULL in the referenced columns, you may get an error. To prevent errors or incorrect results, add the following part to your Python code:
if column_name is not None else NULLwhere column_name is the column name based on which the result will be calculated.
If we rewrite the previously used code, we get the following result:
Analyzing server-specific considerations
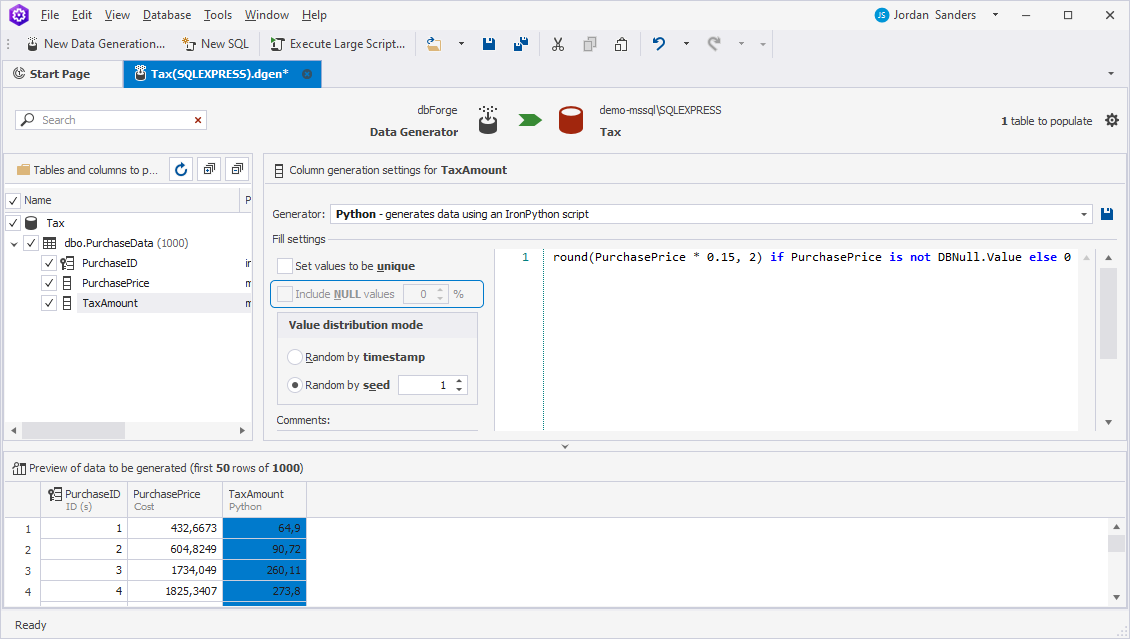
Some servers require inserting 0 instead of NULL in the generated column; otherwise, an error may arise. In this case, we recommend modifying the Python code as follows:
if column_name is not DBNull.Value else 0In dbForge Data Generator, you must also clear the Include NULL values checkbox to turn off the generation of NULL values. So, let us update the Python code in our example:
Troubleshooting common issues
When generating data using a Python generator or any automated tool, you might face issues that prevent the process from working as expected. Let us consider some tips to help you identify and solve these issues for a successful data generation process:
What to do if the proposed solution does not work
- Review error messages and logs produced by the Python script. They may have information about syntax errors, data type mismatches, or constraint violations that caused unexpected behavior.
- Ensure that your Python script can successfully connect to the database. Issues such as incorrect credentials, firewall restrictions, or network problems can impact data generation.
- Run the data generation process on a small subset of data to see if the issue is related to data volume or complexity.
Checking the DDL of the table for column constraints
- Use SQL commands or a database management tool to review the DDL of the target table. For example, search for constraints such as
NOT NULL,UNIQUE,CHECK, orFOREIGN KEYthat might cause data generation failure. - Ensure that the data types used in your Python script match the column definitions in the table.
- Review default values and triggers to verify that they do not interfere with the data you insert.
Ensuring that the database structure supports the desired data generation
- Before starting data generation, validate that the database schema is correctly set up to support the data you want to generate.
- Check that primary keys and unique indexes are correctly defined to avoid duplicate records. Otherwise, the data generation process will fail.
- Update your data generation to include correct foreign key values.
- Consider limitations such as maximum table size, row limits, or available storage space on the server if the table and database cannot handle the volume of data you want to generate.
- Optimize database for generating large datasets.
Conclusion
In summary, we have explored how easily it is to generate the referenced columns with NULL values using dbForge Data Generator. We have also examined some tips you should consider to ensure errorless data generation.
Download dbForge SQL tools and experience how its advanced capabilities can enhance your productivity and database development and management.