")
Quite often there’s a need to create a read-only replica of a SQL Server database. This might be required, for example, for the purpose of separating analytical and operative tasks. The first cause high load on databases and in order to reduce it, the replica of the primary database is created to perform analytical read-only queries.
Usually, these read-only replicas can be created with in-built DBMS tools:
But what if you don’t need the entire database but only a few tables from it? In this case, you can create replication by yourself. And as long as data sampling is the main goal, database replication in one direction (master-to-slave) would be enough. Several methods including SSIS and .NET can be used to perform that kind of replication.
In this article, we will use the JobEmpl recruiting service database to demonstrate how to create database replication in the master-to-slave direction using T-SQL.
Creating SQL Server replication in one direction using T-SQL
To start with, let’s describe the main principle and the algorithm of this replication. During every iteration, we need to compare the data in the selected tables between the Source and the Target databases. This means that we need to enter a unique surrogate key to compare the tables. To speed up the comparison process, we will also need to create an index on that key. And adding a calculated field for every replicated table that calculates CHECKSUM for every row will also be required.
It is also important to pick fixed portions of data, for example, a certain number of rows at a time (per iteration).
Thus, we need to perform the following steps:
- On the source tables, create a REPL_GUID column and a unique REPL_GUID index on it to enforce a one-to-one relationship between source and destination tables. You should also create a calculated CheckSumVal column that will calculate the CHECKSUM value for every row.
- Create a new destination database named Target.
- Synchronize schemas of the replication tables across the Source and Target databases and remove all references to nonexistent objects.
- Disable foreign keys for the Target database.
- Run the replication and monitor how many rows differ between the Source and Target databases.
Let’s now review each step in detail using the JobEmpl database that was created for hiring employees.
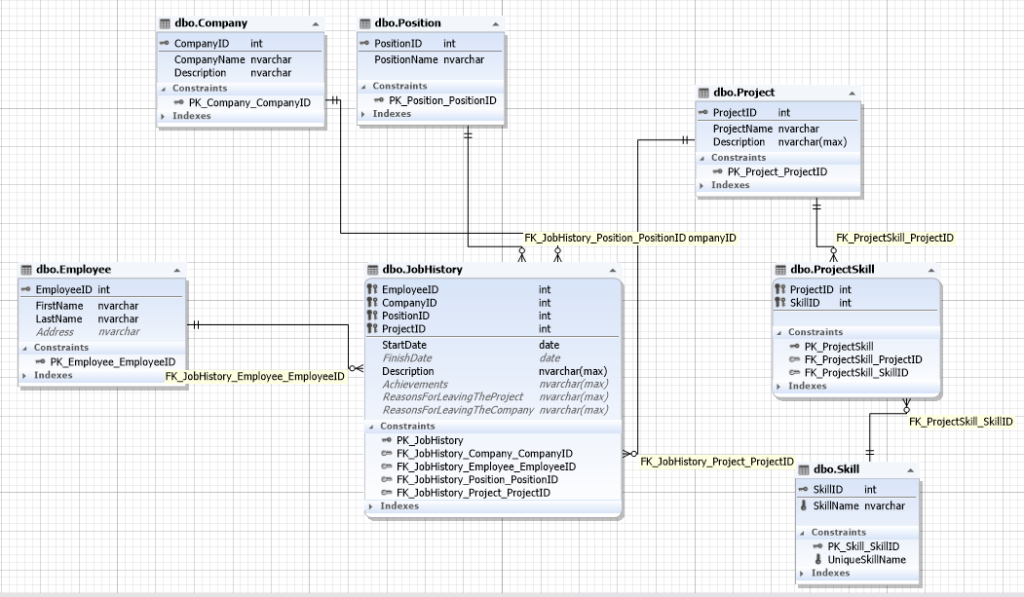
Fig. 1 The schema of a job seekers database
We only need to replicate the Employee and the JobHistory tables.
Then, the 1st step of the mentioned algorithm can be performed with the help of the following script.
USE JobEmpl
GO
SET QUOTED_IDENTIFIER ON;
DECLARE @src NVARCHAR(255) = N'JobEmpl';
DECLARE @sch NVARCHAR(255) = N'dbo';
DECLARE @sql NVARCHAR(MAX);
DECLARE @name NVARCHAR(255);
DECLARE @listcols NVARCHAR(MAX);
CREATE TABLE #cols (
[Name] NVARCHAR(255)
);
SELECT
[Name] INTO #tbl
FROM sys.tables
WHERE [Name] IN (
N'Employee',
N'JobHistory'
);
DECLARE sql_cursor CURSOR LOCAL FOR SELECT
[Name]
FROM #tbl;
OPEN sql_cursor;
FETCH NEXT FROM sql_cursor
INTO @name;
WHILE (@@fetch_status = 0)
BEGIN
DELETE FROM #cols;
SET @sql = N'SET QUOTED_IDENTIFIER ON; select N''COALESCE(CAST([''+col.[name]+N''] AS NVARCHAR(MAX)), N'''''''')'' ' +
N'from [' + @src + N'].sys.columns as col ' +
N'inner join [' + @src + N'].sys.tables as tbl on col.[object_id]=tbl.[object_id] ' +
N'where tbl.[name]=''' + @name + ''' and col.[is_identity]=0';
INSERT INTO #cols ([Name])
EXEC sys.sp_executesql @sql;
SET @listcols = N'';
SELECT
@listcols = @listcols + CAST([Name] AS NVARCHAR(MAX)) + N'+ '
FROM #cols;
SET @listcols = SUBSTRING(@listcols, 1, LEN(@listcols) - 1);
SET @sql=N'SET QUOTED_IDENTIFIER ON; ALTER TABLE ['+@sch+N'].['+@name+N'] ADD [CheckSumVal] AS CHECKSUM('+@listcols+N');'
--PRINT @sql;
EXEC sys.sp_executesql @sql;
SET @sql=N'SET QUOTED_IDENTIFIER ON; ALTER TABLE [dbo].['+@name+N'] ADD [REPL_GUID] [uniqueidentifier] ROWGUIDCOL NOT NULL CONSTRAINT ['+@name+N'_DEF_REPL_GUID] DEFAULT (NEWSEQUENTIALID());';
--PRINT @sql;
EXEC sys.sp_executesql @sql;
SET @sql=N'SET QUOTED_IDENTIFIER ON; CREATE UNIQUE NONCLUSTERED INDEX [indREPL_GUID] ON [dbo].['+@name+N']([REPL_GUID] ASC);';
--PRINT @sql;
EXEC sys.sp_executesql @sql;
FETCH NEXT FROM sql_cursor
INTO @name;
END
CLOSE sql_cursor;
DEALLOCATE sql_cursor;
DROP TABLE #cols;
DROP TABLE #tbl;
From the script, you can see that it has to be run on the source JobEmpl database and you should specify the source database and the schema in @src and @sch variables accordingly. The @sql variable is required for building dynamic SQL, meanwhile, @name is needed for saving the name of the replicated table.
First, we collect the replicated tables names into the temporary #tbl table. Next, we go through every table name with a cursor and fetch the table name into the @name variable. After that, for every table, a list of columns that are not the IDENTITY type is formed and the result is inserted into the @listcols variable with the “+” sign.
It’s worth mentioning that every table name is, at first, converted with the CAST function to NVACHAR(MAX) type and then the COALESCE function ([<ColumnName>], N’’) is used. It’s done to form a single string from all the column values for every row.
Next, the calculated CheckSumVal field, the REPL_GUID field, and its unique indREPL_GUID index are created.
In our case, we got the following script.
SET QUOTED_IDENTIFIER ON;
ALTER TABLE [dbo].[Employee]
ADD [CheckSumVal] AS CHECKSUM(COALESCE(CAST([FirstName] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([LastName] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([Address] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([CheckSumVal] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([REPL_GUID] AS NVARCHAR(MAX)), N''));
SET QUOTED_IDENTIFIER ON;
ALTER TABLE [dbo].[Employee]
ADD [REPL_GUID] [uniqueidentifier] ROWGUIDCOL NOT NULL CONSTRAINT [Employee_DEF_REPL_GUID] DEFAULT (NEWSEQUENTIALID());
SET QUOTED_IDENTIFIER ON;
CREATE UNIQUE NONCLUSTERED INDEX [indREPL_GUID] ON [dbo].[Employee]([REPL_GUID] ASC);
SET QUOTED_IDENTIFIER ON;
ALTER TABLE [dbo].[JobHistory]
ADD [CheckSumVal] AS CHECKSUM(COALESCE(CAST([EmployeeID] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([CompanyID] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([PositionID] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([ProjectID] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([StartDate] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([FinishDate] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([Description] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([Achievements] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([ReasonsForLeavingTheProject] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([ReasonsForLeavingTheCompany] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([CheckSumVal] AS NVARCHAR(MAX)), N'')+ COALESCE(CAST([REPL_GUID] AS NVARCHAR(MAX)), N''));
SET QUOTED_IDENTIFIER ON;
ALTER TABLE [dbo].[JobHistory] ADD [REPL_GUID] [uniqueidentifier] ROWGUIDCOL NOT NULL CONSTRAINT [JobHistory_DEF_REPL_GUID] DEFAULT (NEWSEQUENTIALID());
SET QUOTED_IDENTIFIER ON;
CREATE UNIQUE NONCLUSTERED INDEX [indREPL_GUID] ON [dbo].[JobHistory]([REPL_GUID] ASC);You can later delete the created tables and indexes from the databases with the help of the following scripts.
DECLARE @name NVARCHAR(255);
DECLARE @sql NVARCHAR(MAX);
CREATE TABLE #tbl (
[name] NVARCHAR(255)
);
INSERT INTO #tbl ([name])
SELECT
[name]
FROM sys.tables
WHERE [name] IN (
N'Employee',
N'JobHistory'
);
DECLARE sql_cursor CURSOR LOCAL FOR SELECT
[name]
FROM #tbl;
OPEN sql_cursor;
FETCH NEXT FROM sql_cursor
INTO @name;
WHILE (@@fetch_status = 0)
BEGIN
SET @sql = N'DROP INDEX [indREPL_GUID] ON [dbo].[' + @name + N'];';
--print @sql
EXEC sys.sp_executesql @sql;
SET @sql = N'ALTER TABLE [dbo].[' + @name + N'] DROP CONSTRAINT [' + @name + N'_DEF_REPL_GUID], COLUMN [CheckSumVal], COLUMN [REPL_GUID];';
--print @sql
EXEC sys.sp_executesql @sql;
FETCH NEXT FROM sql_cursor
INTO @name;
END
CLOSE sql_cursor;
DEALLOCATE sql_cursor;
DROP TABLE #tbl;The replicated tables are also here, and for each of them the indREPL_GUID index, as well as REPL_GUID and CheckSumVal columns, get deleted.
In our case, the following T-SQL code was created.
DROP INDEX [indREPL_GUID] ON [dbo].[Employee];
ALTER TABLE [dbo].[Employee] DROP CONSTRAINT [Employee_DEF_REPL_GUID], COLUMN [CheckSumVal], COLUMN [REPL_GUID];
DROP INDEX [indREPL_GUID] ON [dbo].[JobHistory];
ALTER TABLE [dbo].[JobHistory] DROP CONSTRAINT [JobHistory_DEF_REPL_GUID], COLUMN [CheckSumVal], COLUMN [REPL_GUID];Let’s now create a new JobEmplRead database for receiving data according to the 2nd step of the algorithm, mentioned above. Then, we synchronize schemas for the replicated tables. To perform synchronization, use the DbForge Schema Compare tool: select JobEmpl as the data source and jobEmplRead as the data target.
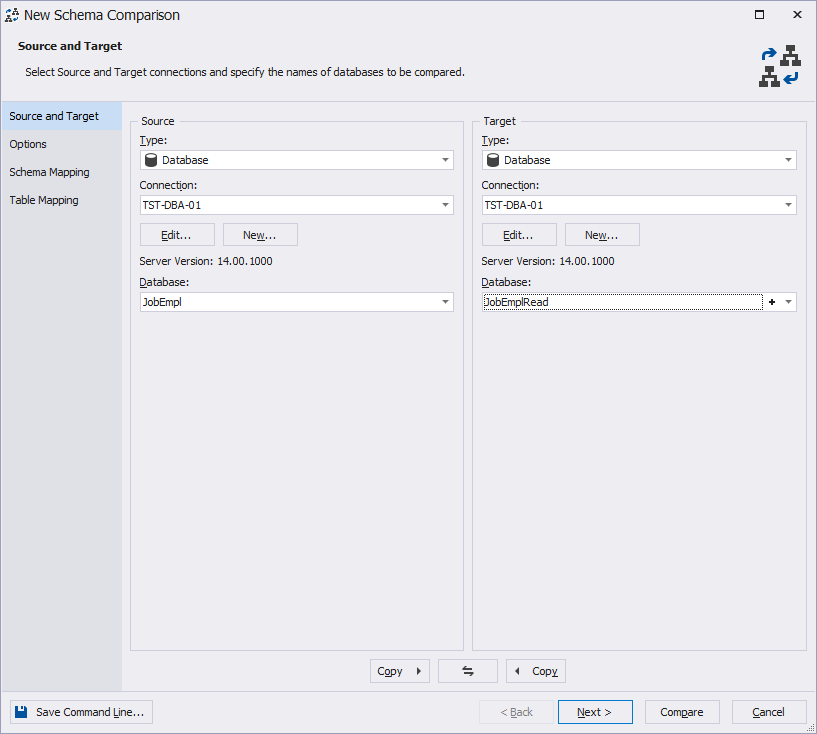
Fig. 2 Databases selection for schema synchronization
Then click Compare. Once the metadata creation process for the comparison is done, select the required tables and start configuring the database synchronization process.
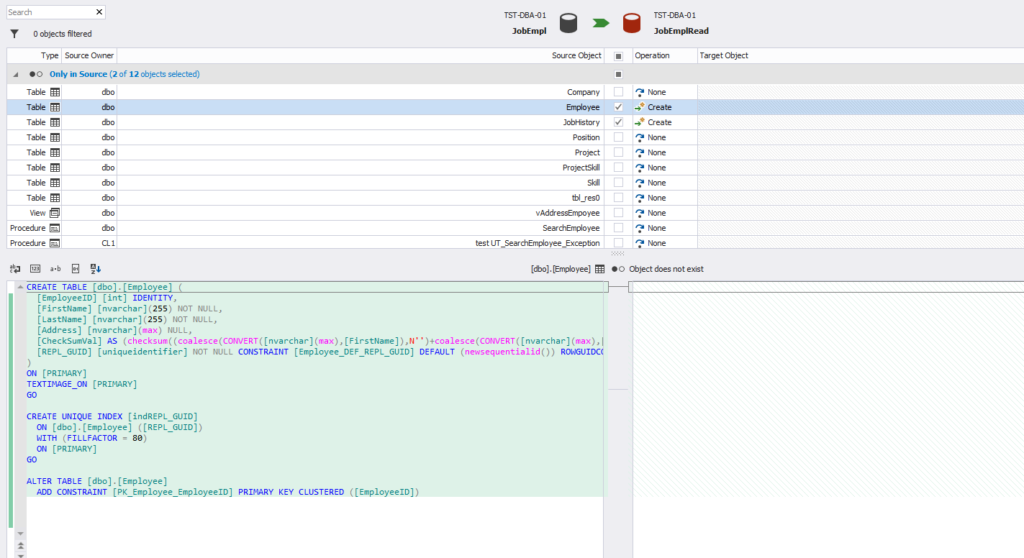
Fig. 3 Selecting tables for schema synchronization
Next, we select the default value – script generation.
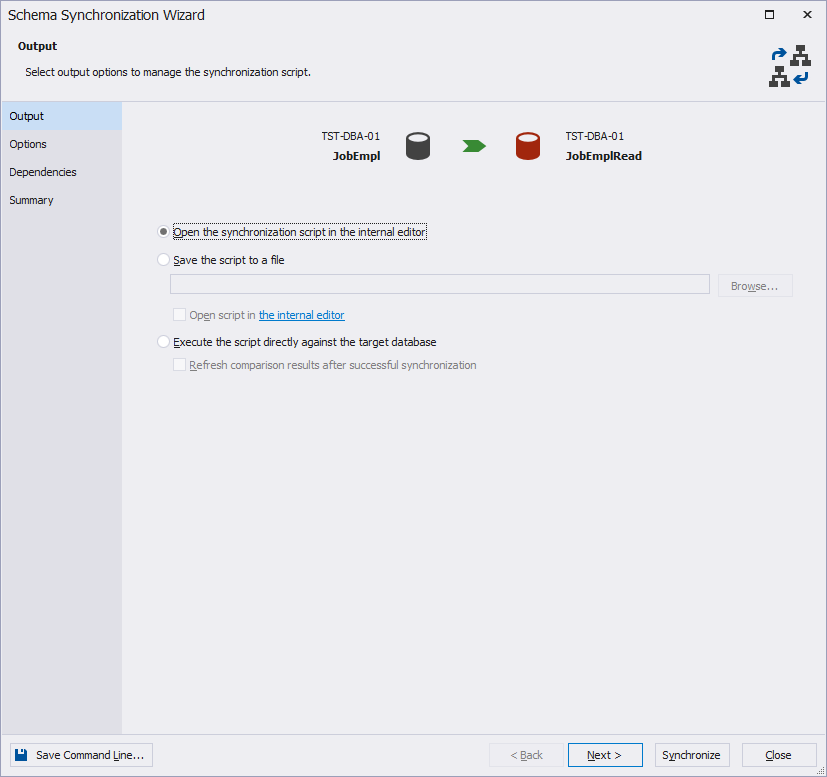
Fig. 4 Selecting script generation as a synchronization output
Let’s now clear the backup creation option.
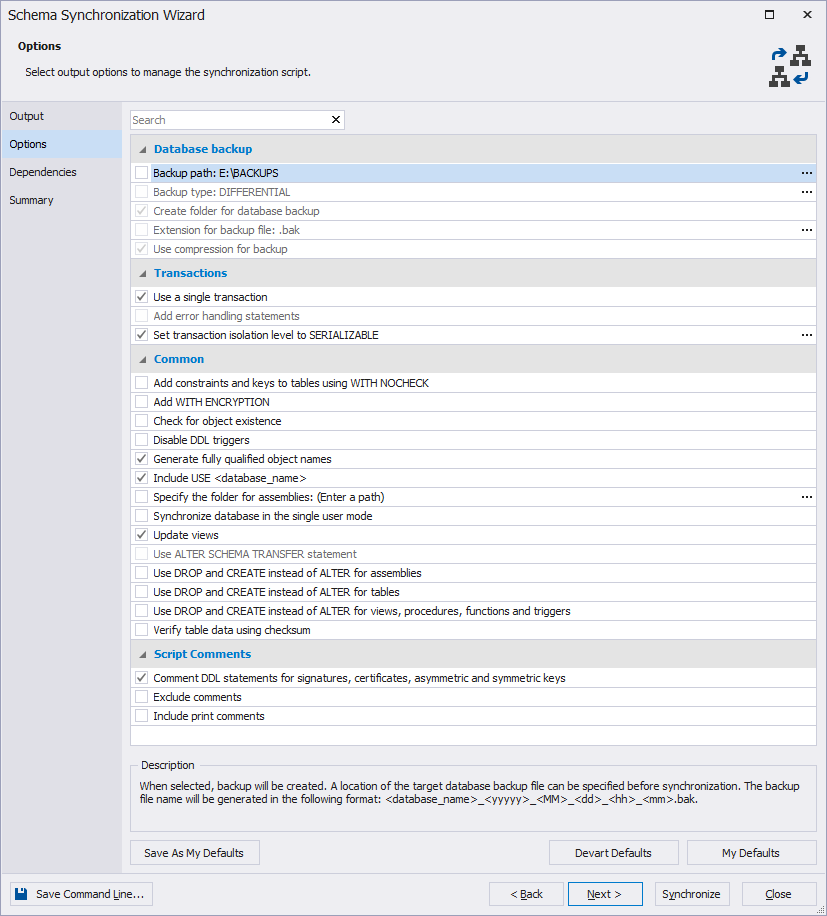
Fig. 5 Unselecting the backup creation option
Next, we uncheck all the dependencies as we don’t need to create other objects. And we will later delete foreign keys manually in a generated schema synchronization script.
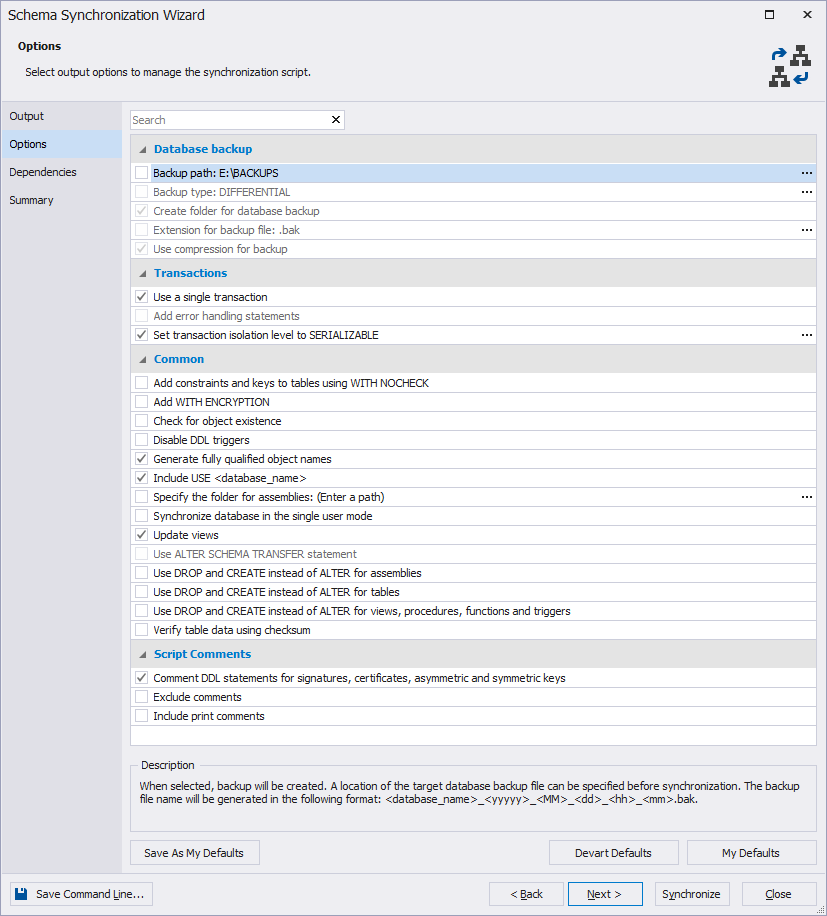
Fig. 6 Unselecting all the dependencies
Now, click Synchronize and ignore the warnings on the Summary tab.
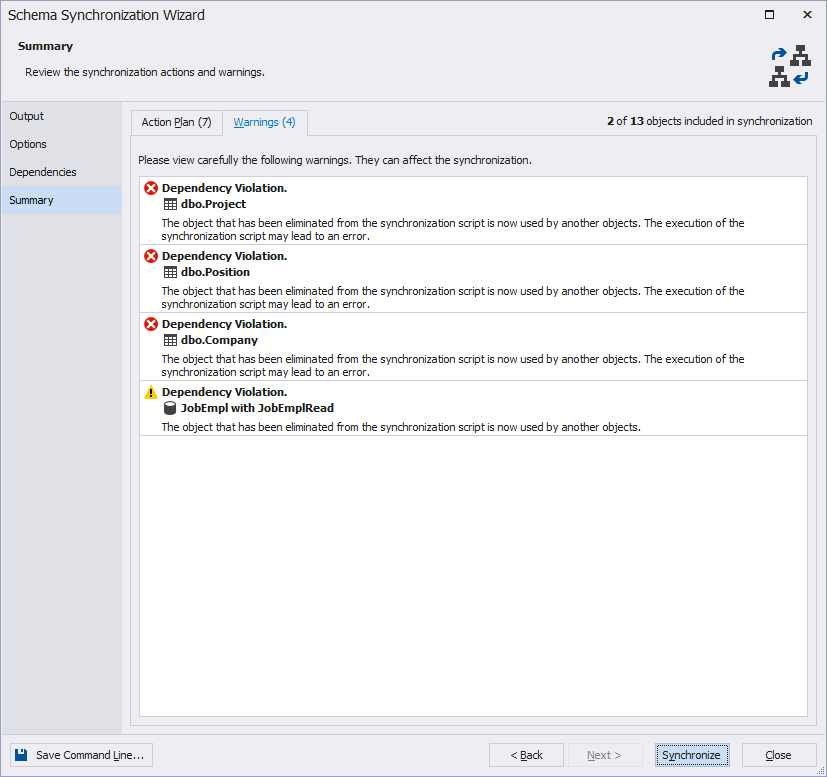
Fig. 7 Warnings
Delete the following foreign keys in the generated script:
- FK_JobHistory_Company_CompanyID
- FK_JobHistory_Position_PositionID
- FK_JobHistory_Project_ProjectID
We need to do this because we didn’t transfer the Company, Position, and Project tables. As a result, we got a script for moving replicated schema tables.
SET CONCAT_NULL_YIELDS_NULL, ANSI_NULLS, ANSI_PADDING, QUOTED_IDENTIFIER, ANSI_WARNINGS, ARITHABORT, XACT_ABORT ON
SET NUMERIC_ROUNDABORT, IMPLICIT_TRANSACTIONS OFF
GO
USE [JobEmplRead]
GO
IF DB_NAME() <> N'JobEmplRead' SET NOEXEC ON
GO
--
-- Set transaction isolation level
--
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
GO
--
-- Start Transaction
--
BEGIN TRANSACTION
GO
--
-- Create table [dbo].[Employee]
--
CREATE TABLE [dbo].[Employee] (
[EmployeeID] [int] IDENTITY,
[FirstName] [nvarchar](255) NOT NULL,
[LastName] [nvarchar](255) NOT NULL,
[Address] [nvarchar](max) NULL,
[CheckSumVal] AS (checksum((coalesce(CONVERT([nvarchar](max),[FirstName]),N'')+coalesce(CONVERT([nvarchar](max),[LastName]),N''))+coalesce(CONVERT([nvarchar](max),[Address]),N''))),
[REPL_GUID] [uniqueidentifier] NOT NULL CONSTRAINT [Employee_DEF_REPL_GUID] DEFAULT (newsequentialid()) ROWGUIDCOL,
CONSTRAINT [PK_Employee_EmployeeID] PRIMARY KEY CLUSTERED ([EmployeeID])
)
ON [PRIMARY]
TEXTIMAGE_ON [PRIMARY]
GO
IF @@ERROR<>0 OR @@TRANCOUNT=0 BEGIN IF @@TRANCOUNT>0 ROLLBACK SET NOEXEC ON END
GO
--
-- Create index [indREPL_GUID] on table [dbo].[Employee]
--
CREATE UNIQUE INDEX [indREPL_GUID]
ON [dbo].[Employee] ([REPL_GUID])
WITH (FILLFACTOR = 80)
ON [PRIMARY]
GO
IF @@ERROR<>0 OR @@TRANCOUNT=0 BEGIN IF @@TRANCOUNT>0 ROLLBACK SET NOEXEC ON END
GO
--
-- Create table [dbo].[JobHistory]
--
CREATE TABLE [dbo].[JobHistory] (
[EmployeeID] [int] NOT NULL,
[CompanyID] [int] NOT NULL,
[PositionID] [int] NOT NULL,
[ProjectID] [int] NOT NULL,
[StartDate] [date] NOT NULL,
[FinishDate] [date] NULL,
[Description] [nvarchar](max) NOT NULL,
[Achievements] [nvarchar](max) NULL,
[ReasonsForLeavingTheProject] [nvarchar](max) NULL,
[ReasonsForLeavingTheCompany] [nvarchar](max) NULL,
[CheckSumVal] AS (checksum(((((((((coalesce(CONVERT([nvarchar](max),[EmployeeID]),N'')+coalesce(CONVERT([nvarchar](max),[CompanyID]),N''))+coalesce(CONVERT([nvarchar](max),[PositionID]),N''))+coalesce(CONVERT([nvarchar](max),[ProjectID]),N''))+coalesce(CONVERT([nvarchar](max),[StartDate]),N''))+coalesce(CONVERT([nvarchar](max),[FinishDate]),N''))+coalesce(CONVERT([nvarchar](max),[Description]),N''))+coalesce(CONVERT([nvarchar](max),[Achievements]),N''))+coalesce(CONVERT([nvarchar](max),[ReasonsForLeavingTheProject]),N''))+coalesce(CONVERT([nvarchar](max),[ReasonsForLeavingTheCompany]),N''))),
[REPL_GUID] [uniqueidentifier] NOT NULL CONSTRAINT [JobHistory_DEF_REPL_GUID] DEFAULT (newsequentialid()) ROWGUIDCOL,
CONSTRAINT [PK_JobHistory] PRIMARY KEY CLUSTERED ([EmployeeID], [CompanyID], [PositionID], [ProjectID])
)
ON [PRIMARY]
TEXTIMAGE_ON [PRIMARY]
GO
IF @@ERROR<>0 OR @@TRANCOUNT=0 BEGIN IF @@TRANCOUNT>0 ROLLBACK SET NOEXEC ON END
GO
--
-- Create index [indREPL_GUID] on table [dbo].[JobHistory]
--
CREATE UNIQUE INDEX [indREPL_GUID]
ON [dbo].[JobHistory] ([REPL_GUID])
WITH (FILLFACTOR = 80)
ON [PRIMARY]
GO
IF @@ERROR<>0 OR @@TRANCOUNT=0 BEGIN IF @@TRANCOUNT>0 ROLLBACK SET NOEXEC ON END
GO
--
-- Create foreign key [FK_JobHistory_Employee_EmployeeID] on table [dbo].[JobHistory]
--
ALTER TABLE [dbo].[JobHistory] WITH NOCHECK
ADD CONSTRAINT [FK_JobHistory_Employee_EmployeeID] FOREIGN KEY ([EmployeeID]) REFERENCES [dbo].[Employee] ([EmployeeID])
GO
IF @@ERROR<>0 OR @@TRANCOUNT=0 BEGIN IF @@TRANCOUNT>0 ROLLBACK SET NOEXEC ON END
GO
--
-- Commit Transaction
--
IF @@TRANCOUNT>0 COMMIT TRANSACTION
GO
--
-- Set NOEXEC to off
--
SET NOEXEC OFF
GO
Run this script in the JobEmplRead database.
Thus, we’ve completed step 3 of our algorithm: synchronized tables schema across the JobEmpl and JobEmplRead databases and deleted all references to nonexistent objects.
Let’s use the following script for monitoring.
DECLARE @src NVARCHAR(255) = N'JobEmpl';
DECLARE @trg NVARCHAR(255) = N'JobEmplRead';
DECLARE @sch NVARCHAR(255) = N'dbo';
DECLARE @sql NVARCHAR(MAX);
DECLARE @name NVARCHAR(255);
CREATE TABLE #res (
[TblName] NVARCHAR(255)
,[Count] INT
);
SELECT
[name] INTO #tbl
FROM sys.tables
WHERE [name] IN (
N'Employee',
N'JobHistory'
);
DECLARE sql_cursor CURSOR LOCAL FOR SELECT
[name]
FROM #tbl;
OPEN sql_cursor;
FETCH NEXT FROM sql_cursor
INTO @name;
WHILE (@@fetch_status = 0)
BEGIN
SET @sql = N'SELECT ''' + @name + N''' AS [TblName], COUNT(*) as [Count] ' +
N'FROM [' + @src + N'].[' + @sch + N'].[' + @name + N'] AS src WITH(READUNCOMMITTED) FULL OUTER JOIN ' +
N'[' + @trg + N'].[' + @sch + N'].[' + @name + N'] AS trg WITH(READUNCOMMITTED) ON src.[REPL_GUID]=trg.[REPL_GUID] ' +
N'WHERE (src.[REPL_GUID] IS NULL) OR (trg.[REPL_GUID] IS NULL) OR (src.[CheckSumVal]<>trg.[CheckSumVal])';
--print @sql;
INSERT INTO #res ([TblName], [Count])
EXEC sys.sp_executesql @sql;
FETCH NEXT FROM sql_cursor
INTO @name;
END
CLOSE sql_cursor;
DEALLOCATE sql_cursor;
DROP TABLE #tbl;
SELECT
*
FROM #res
ORDER BY [TblName] ASC;
DROP TABLE #res;Here we have FULL OUTER JOIN statements creation and the return of the tables list and the number of distinctive rows, including nonexisting and lacking rows.
In our case, we get the following result.
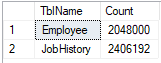
Fig. 8 The number of distinctive rows in replicated tables
The following script was generated for comparison.
SELECT 'Employee' AS [TblName], COUNT(*) as [Count]
FROM [JobEmpl].[dbo].[Employee] AS src WITH(READUNCOMMITTED)
FULL OUTER JOIN [JobEmplRead].[dbo].[Employee] AS trg WITH(READUNCOMMITTED) ON src.[REPL_GUID]=trg.[REPL_GUID]
WHERE (src.[REPL_GUID] IS NULL) OR (trg.[REPL_GUID] IS NULL) OR (src.[CheckSumVal]<>trg.[CheckSumVal])
SELECT 'JobHistory' AS [TblName], COUNT(*) as [Count]
FROM [JobEmpl].[dbo].[JobHistory] AS src WITH(READUNCOMMITTED)
FULL OUTER JOIN [JobEmplRead].[dbo].[JobHistory] AS trg WITH(READUNCOMMITTED) ON src.[REPL_GUID]=trg.[REPL_GUID]
WHERE (src.[REPL_GUID] IS NULL) OR (trg.[REPL_GUID] IS NULL) OR (src.[CheckSumVal]<>trg.[CheckSumVal])It’s worth noting that to reduce blockings, the transaction isolation level is Dirty Read.
Let’s unite the 4th and the 5th steps of our algorithm into the following single script.
USE [JobEmplRead]
GO
SET QUOTED_IDENTIFIER ON;
DECLARE @count INT = 100000;
DECLARE @src NVARCHAR(255) = N'JobEmpl';
DECLARE @trg NVARCHAR(255) = N'JobEmplRead';
DECLARE @sch NVARCHAR(255) = N'dbo';
DECLARE @sql NVARCHAR(MAX);
DECLARE @name NVARCHAR(255);
DECLARE @upd_listcols NVARCHAR(MAX);
DECLARE @ins_listcols NVARCHAR(MAX);
DECLARE @listcols NVARCHAR(MAX);
CREATE TABLE #cols (
[Name] NVARCHAR(255)
);
CREATE TABLE #fk_list (
[TblName] NVARCHAR(255)
,[Name] NVARCHAR(255)
);
DECLARE @ParmDefinition NVARCHAR(500);
SELECT
[Name] INTO #tbl
FROM sys.tables
WHERE [Name] IN (
N'Employee',
N'JobHistory'
);
INSERT INTO #fk_list ([TblName], [Name])
SELECT
t.[Name]
,fk.[Name]
FROM sys.foreign_keys AS fk
INNER JOIN sys.tables AS tbl
ON fk.[parent_object_id] = tbl.[object_id]
INNER JOIN #tbl AS t
ON t.[Name] = tbl.[Name];
--select * from #fk_list;
IF (EXISTS (SELECT TOP (1)
1
FROM #fk_list)
)
BEGIN
SELECT
N'SET QUOTED_IDENTIFIER ON; ALTER TABLE [' + [TblName] + N'] NOCHECK CONSTRAINT [' + [Name] + N']; ' AS [Script] INTO #script_fk_off
FROM #fk_list;
--select *
--from #script_fk_off;
DECLARE sql_cursor0 CURSOR LOCAL FOR SELECT
[Script]
FROM #script_fk_off;
OPEN sql_cursor0;
FETCH NEXT FROM sql_cursor0
INTO @sql;
WHILE (@@fetch_status = 0)
BEGIN
--print @sql;
EXEC sys.sp_executesql @sql;
FETCH NEXT FROM sql_cursor0
INTO @sql;
END
CLOSE sql_cursor0;
DEALLOCATE sql_cursor0;
DROP TABLE #script_fk_off;
END
DECLARE sql_cursor CURSOR LOCAL FOR SELECT
[Name]
FROM #tbl;
OPEN sql_cursor;
FETCH NEXT FROM sql_cursor
INTO @name;
WHILE (@@fetch_status = 0)
BEGIN
DELETE FROM #cols;
SET @sql = N'SET QUOTED_IDENTIFIER ON; select N''[''+col.[name]+N'']'' ' +
N'from [' + @src + N'].sys.columns as col ' +
N'inner join [' + @src + N'].sys.tables as tbl on col.[object_id]=tbl.[object_id] ' +
N'where tbl.[name]=''' + @name + ''' and col.[is_identity]=0 and (col.[name] not in (''CheckSumVal'', ''REPL_GUID''))';--+''' and [is_identity]=0';
INSERT INTO #cols ([Name])
EXEC sys.sp_executesql @sql;
SET @upd_listcols = N'';
SELECT
@upd_listcols = @upd_listcols + N'trg.' + CAST([Name] AS NVARCHAR(MAX)) + N' = src.' + CAST([Name] AS NVARCHAR(MAX)) + N', '
FROM #cols;
SET @upd_listcols = SUBSTRING(@upd_listcols, 1, LEN(@upd_listcols) - 1);
DELETE FROM #cols;
SET @sql = N'SET QUOTED_IDENTIFIER ON; select N''[''+col.[name]+N'']'' ' +
N'from [' + @src + N'].sys.columns as col ' +
N'inner join [' + @src + N'].sys.tables as tbl on col.[object_id]=tbl.[object_id] ' +
N'where tbl.[name]=''' + @name + ''' and (col.[name] <> ''CheckSumVal'')';--+''' and [is_identity]=0';
INSERT INTO #cols ([Name])
EXEC sys.sp_executesql @sql;
SET @listcols = N'';
SELECT
@listcols = @listcols + CAST([Name] AS NVARCHAR(MAX)) + N', '
FROM #cols;
SET @listcols = SUBSTRING(@listcols, 1, LEN(@listcols) - 1);
DELETE FROM #cols;
SET @sql = N'SET QUOTED_IDENTIFIER ON; select N''src.[''+col.[name]+N'']'' ' +
N'from [' + @src + N'].sys.columns as col ' +
N'inner join [' + @src + N'].sys.tables as tbl on col.[object_id]=tbl.[object_id] ' +
N'where tbl.[name]=''' + @name + ''' and (col.[name] <> ''CheckSumVal'')';--+''' and [is_identity]=0';
INSERT INTO #cols ([Name])
EXEC sys.sp_executesql @sql;
SET @ins_listcols = N'';
SELECT
@ins_listcols = @ins_listcols + CAST([Name] AS NVARCHAR(MAX)) + N', '
FROM #cols;
SET @ins_listcols = SUBSTRING(@ins_listcols, 1, LEN(@ins_listcols) - 1);
SET @ParmDefinition = N'@count int';
SET @sql = N'SET QUOTED_IDENTIFIER ON; DECLARE @is_identity BIT = 0;
declare @tbl_id int;
SELECT TOP (1)
@tbl_id = [object_id]
FROM [' + @trg + N'].sys.objects
WHERE [name] = ''' + @name + N''';
SET @is_identity =
CASE
WHEN (EXISTS (SELECT TOP (1)
1
FROM [' + @trg + N'].sys.columns
WHERE [object_id] = @tbl_id
AND [is_identity] = 1)
) THEN 1
ELSE 0
END;
IF (@is_identity = 1) SET IDENTITY_INSERT [' + @trg + N'].[dbo].[' + @name + N'] ON;
--BEGIN TRAN
;MERGE TOP (@count)
[' + @trg + N'].[dbo].[' + @name + N'] AS trg
USING [' + @src + N'].[dbo].[' + @name + N'] AS src
ON src.[REPL_GUID] = trg.[REPL_GUID]
WHEN MATCHED AND (src.[CheckSumVal]<>trg.[CheckSumVal])
THEN UPDATE
SET ' + @upd_listcols + N'
WHEN NOT MATCHED BY TARGET
THEN INSERT (' + @listcols + N')
VALUES (' + @ins_listcols + N')
WHEN NOT MATCHED BY SOURCE
THEN DELETE;
--ROLLBACK TRAN
IF (@is_identity = 1) SET IDENTITY_INSERT [' + @trg + N'].[dbo].[' + @name + N'] OFF;';
--PRINT @sql;
--begin tran
EXEC sys.sp_executesql @sql
,@ParmDefinition
,@count = @count;
--rollback tran
FETCH NEXT FROM sql_cursor
INTO @name;
END
CLOSE sql_cursor;
DEALLOCATE sql_cursor;
DROP TABLE #cols;
DROP TABLE #fk_list;
DROP TABLE #tbl;First, all foreign keys for the replicated table are disabled in the JobEmplRead database. Then with the MERGE statements data is copied in portions. In our case, we have 100 000 rows per iteration. This script comprises a single iteration and executes the following T-SQL code.
SET QUOTED_IDENTIFIER ON;
ALTER TABLE [JobHistory] NOCHECK CONSTRAINT [FK_JobHistory_Employee_EmployeeID];
SET QUOTED_IDENTIFIER ON; DECLARE @is_identity BIT = 0;
declare @tbl_id int;
SELECT TOP (1)
@tbl_id = [object_id]
FROM [JobEmplRead].sys.objects
WHERE [name] = 'Employee';
SET @is_identity =
CASE
WHEN (EXISTS (SELECT TOP (1)
1
FROM [JobEmplRead].sys.columns
WHERE [object_id] = @tbl_id
AND [is_identity] = 1)
) THEN 1
ELSE 0
END;
IF (@is_identity = 1) SET IDENTITY_INSERT [JobEmplRead].[dbo].[Employee] ON;
--BEGIN TRAN
;MERGE TOP (@count)
[JobEmplRead].[dbo].[Employee] AS trg
USING [JobEmpl].[dbo].[Employee] AS src
ON src.[REPL_GUID] = trg.[REPL_GUID]
WHEN MATCHED AND (src.[CheckSumVal]<>trg.[CheckSumVal])
THEN UPDATE
SET trg.[FirstName] = src.[FirstName], trg.[LastName] = src.[LastName], trg.[Address] = src.[Address]
WHEN NOT MATCHED BY TARGET
THEN INSERT ([EmployeeID], [FirstName], [LastName], [Address], [REPL_GUID])
VALUES (src.[EmployeeID], src.[FirstName], src.[LastName], src.[Address], src.[REPL_GUID])
WHEN NOT MATCHED BY SOURCE
THEN DELETE;
--ROLLBACK TRAN
IF (@is_identity = 1) SET IDENTITY_INSERT [JobEmplRead].[dbo].[Employee] OFF;This script should be run automatically at an interval specified in advance. For example, it can be run every minute or even more frequently depending on the analytics needs.
The number of distinctive rows has to be smaller after several iterations.
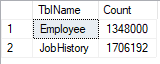
Fig. 9 The change in the number of distinctive rows
Remember that to enable foreign keys in the disabled tables you should run the following script.
USE [JobEmplRead]
GO
DECLARE @sql NVARCHAR(MAX);
CREATE TABLE #fk_list (
[TblName] NVARCHAR(255)
,[Name] NVARCHAR(255)
);
SELECT
[Name] INTO #tbl
FROM sys.tables
WHERE [Name] IN (
N'Employee',
N'JobHistory'
);
INSERT INTO #fk_list ([TblName], [Name])
SELECT
t.[Name]
,fk.[Name]
FROM sys.foreign_keys AS fk
INNER JOIN sys.tables AS tbl
ON fk.[parent_object_id] = tbl.[object_id]
INNER JOIN #tbl AS t
ON t.[Name] = tbl.[Name];
--select * from #fk_list;
IF (EXISTS (SELECT TOP (1)
1
FROM #fk_list)
)
BEGIN
SELECT
N'ALTER TABLE [' + [TblName] + N'] CHECK CONSTRAINT [' + [Name] + N']; ' AS [Script] INTO #script_fk_on
FROM #fk_list;
--select *
--from #script_fk_on;
DECLARE sql_cursor0 CURSOR LOCAL FOR SELECT
[Script]
FROM #script_fk_on;
OPEN sql_cursor0;
FETCH NEXT FROM sql_cursor0
INTO @sql;
WHILE (@@fetch_status = 0)
BEGIN
--print @sql;
EXEC sys.sp_executesql @sql;
FETCH NEXT FROM sql_cursor0
INTO @sql;
END
CLOSE sql_cursor0;
DEALLOCATE sql_cursor0;
DROP TABLE #script_fk_on;
END
DROP TABLE #fk_list;
DROP TABLE #tbl;In our case, the following script will be generated and executed.
ALTER TABLE [JobHistory] CHECK CONSTRAINT [FK_JobHistory_Employee_EmployeeID];Keep in mind that you can’t enable foreign keys on the replicated tables while the replication is running until all data is copied.
Conclusion
We have reviewed one of the ways to implement the process of replicating tables in one direction from the source to the destination.
This approach and scripts can be applied to any database. But of course, those scripts have to be modified depending on the specifics of the replicated tables. For example, modification might be required if the tables have calculated fields.
SQL Complete was the main tool to help me build those scripts. The tool also allows code formatting as well as renaming objects and all their references.