
DBA has a number of duties that are primarily targeted at supporting database performance capabilities and data consistency. The administrator can use the CHECKDB command to easily verify data consistency; however, in case they need to find an invalid object in a database schema, some difficulties may occur.
Introduction
Running smooth operations and ensuring data integrity are very important in any database system. One issue that can get in the way is invalid objects present in databases. These are database objects that no longer function properly due to changes made to the database or its components. For example, invalid objects may appear when a referenced object is changed or removed. So, it is a good practice to find invalid objects to maintain the database performance and avoid unexpected issues or even downtime.
In this article, we’ll explain what invalid objects are, how they can affect your database, and how to identify and fix them using scripts or dbForge Edge, an advanced toolset for searching and fixing invalid objects across your database and performing other database-related tasks.
Understanding invalid objects
By invalid, we usually mean different types of objects, such as synonyms, functions, packages, procedures, views, etc., that reference non-existing objects or objects that were changed in some way (e.g., renamed). For instance, you should be careful with synonyms created on objects because when you delete an object, its synonym will get an invalid status. If you recreate an object, its synonym must also be recompiled. When you attempt to use an invalid object, it will throw an error.
You often discover invalid objects when you run preparation scripts, perform data export or import, upgrade, or apply patches. However, a really good way to work with them is to perform regular checks on the presence of mismatched objects before and after you introduce changes or upgrades.
Invalid objects can be rather ambiguous. However, it’s important to remember that some are quite harmless. You can fix them with a simple action or a recompilation, automatically performed by a database when the object is accessed. For instance, there is not much reason to worry about invalid materialized views since they become valid as soon as you add data to the underlying tables.
Encountering persisting issues that should be fixed by dumping data? Check the MySQL Dump Tool for easy backups and recovery.
Alternatively, other objects indicate latent severe issues that cannot be recompiled. This is especially true when the change on the referenced object results in an error in the calling object, thus the latter cannot be recompiled. In both cases, finding the reason and identifying these objects in your database is crucial before further issues can occur. Depending on the database you use, you can choose from the scripts provided below to find invalid objects.
Identifying invalid objects in different databases
Now, let us see how to search for invalid objects in Oracle, SQL Server, and MySQL databases using dbForge Edge, which consists of the Studios: dbForge Studio for Oracle, dbForge Studio for SQL Server, dbForge Studio for MySQL, as well as dbForge Studio for PostgreSQL.
Oracle
Since Oracle is an intricate and interrelated database, some objects reliant on one another often become ‘invalid’. As a rule, they are recompiled automatically on demand. However, this can be very time-consuming, especially regarding complex dependencies. The solution is to find these objects and apply different methods to recompile them.
Let us show you how to get a list of invalid objects in Oracle with the following query:
SELECT owner, object_type, object_name
FROM all_objects
WHERE status = 'INVALID'
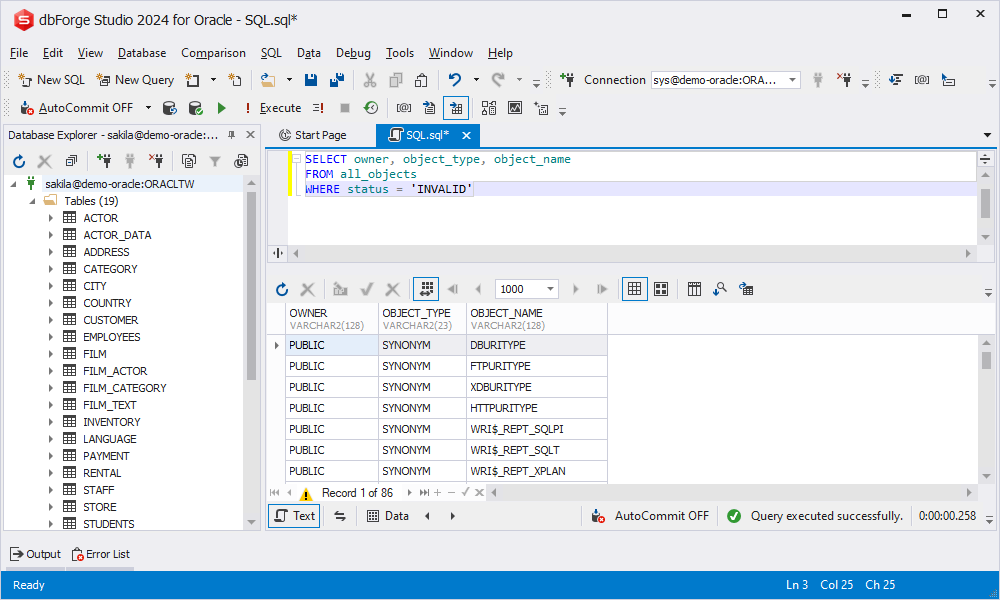
The information you will receive will help you decide on the next step to recompile the objects.
If you experience difficulties trying to search for and fix invalid objects manually, dbForge Studio for Oracle may come to your aid as it offers extensive functionality allowing you to reduce the number of errors and rename the objects without breaking dependencies between them. Learn more about how to recompile invalid objects with this tool in the documentation.
SQL Server
SQL Server doesn’t allow finding mismatched objects directly. In most cases, you must execute a script to ensure the object is invalid. This is extremely inconvenient, though.
For that reason, let us create and execute the script that will search for invalid objects:
SELECT
obj_name = QUOTENAME(SCHEMA_NAME(o.[schema_id])) + '.' + QUOTENAME(o.name)
, obj_type = o.type_desc
, d.referenced_database_name
, d.referenced_schema_name
, d.referenced_entity_name
FROM sys.sql_expression_dependencies d
JOIN sys.objects o ON d.referencing_id = o.[object_id]
WHERE d.is_ambiguous = 0
AND d.referenced_id IS NULL
AND d.referenced_server_name IS NULL -- ignore objects from Linked server
AND CASE d.referenced_class -- if does not exist
WHEN 1 -- object
THEN OBJECT_ID(
ISNULL(QUOTENAME(d.referenced_database_name), DB_NAME()) + '.' +
ISNULL(QUOTENAME(d.referenced_schema_name), SCHEMA_NAME()) + '.' +
QUOTENAME(d.referenced_entity_name))
WHEN 6 – or user datatype
THEN TYPE_ID(
ISNULL(d.referenced_schema_name, SCHEMA_NAME()) + '.' + d.referenced_entity_name)
WHEN 10 -- or XML schema
THEN (
SELECT 1 FROM sys.xml_schema_collections x
WHERE x.name = d.referenced_entity_name
AND x.[schema_id] = ISNULL(SCHEMA_ID(d.referenced_schema_name), SCHEMA_ID())
)
END IS NULL
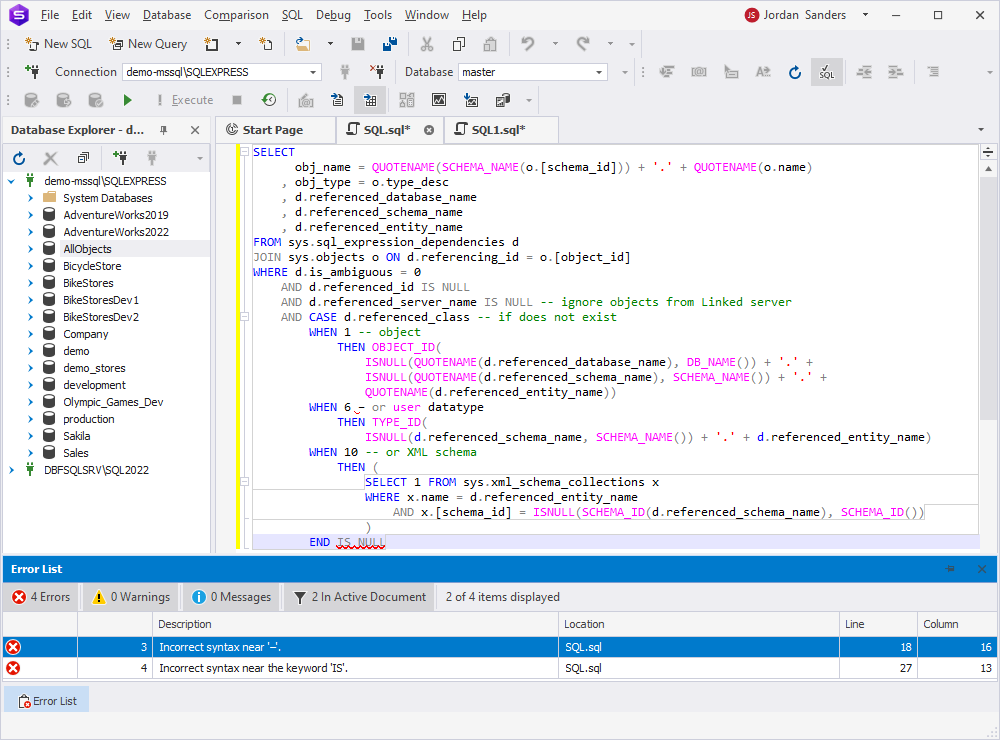
The script is useful for primary analysis. However, it has some gaps. The main problem is that it does not show objects with invalid columns or parameters.
CREATE VIEW dbo.vw_View
AS SELECT ID = 1
GO
CREATE PROCEDURE dbo.usp_Procedure
AS BEGIN
SELECT ID FROM dbo.vw_View
END
GO
ALTER VIEW dbo.vw_View
AS SELECT New_ID = 1
GO
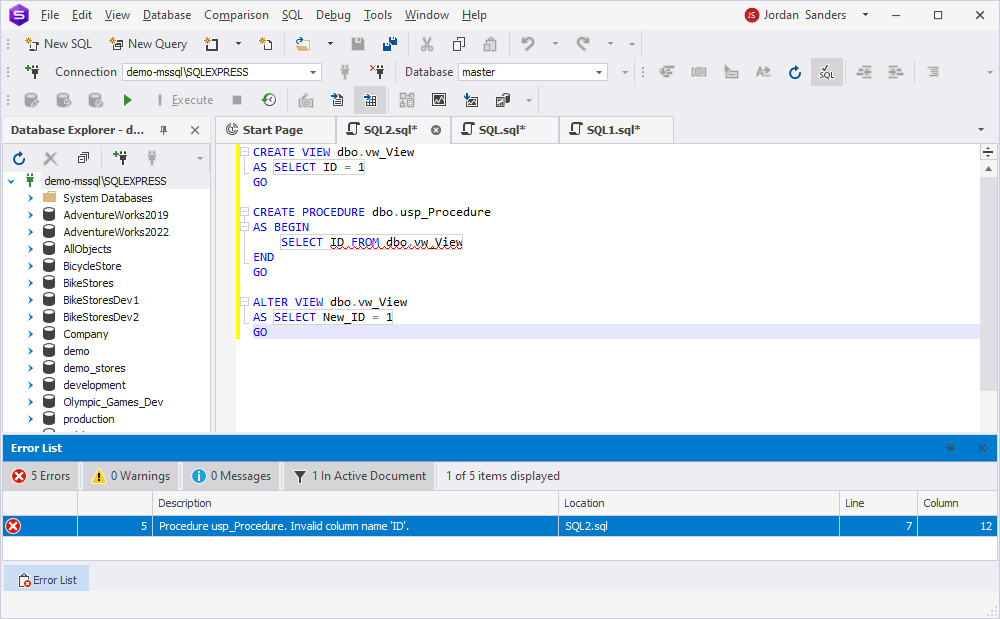
We will get an error while executing the storage procedure:
Msg 207, Level 16, State 1, Procedure usp_Procedure, Line 6
Invalid column name 'ID'.
Moreover, the script will not work on SQL Server 2005. So, we can’t use the provided script as the primary one.
However, SQL Server offers the sp_refreshsqlmodule system procedure. This procedure updates metadata for the specified non-schema-bound stored procedure, user-defined function, view, DML trigger, database-level DDL trigger, or server-level DDL trigger in the current database. Persistent metadata for these objects, such as data types of parameters, can become outdated because of changes made to their underlying objects.
Thus, the sp_refreshsqlmodule procedure throws an error if an object contains invalid columns or properties. The procedure can be called inside a cursor for each object. If there are no invalid objects, the procedure is completed without errors.
However, it is important to remember that script objects may have no dependencies or can contain no invalid objects initially. It is not reasonable to verify such objects. SQL Server will take care of that.
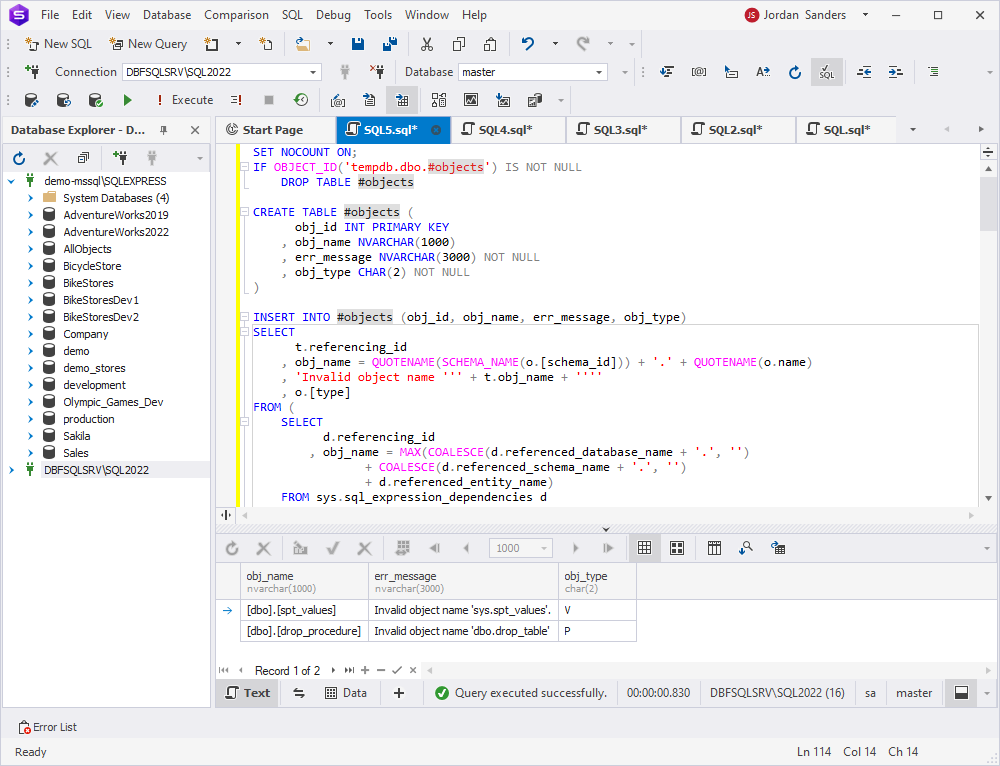
The following script can be used for searching invalid objects:
SET NOCOUNT ON;
IF OBJECT_ID('tempdb.dbo.#objects') IS NOT NULL
DROP TABLE #objects
CREATE TABLE #objects (
obj_id INT PRIMARY KEY
, obj_name NVARCHAR(1000)
, err_message NVARCHAR(3000) NOT NULL
, obj_type CHAR(2) NOT NULL
)
INSERT INTO #objects (obj_id, obj_name, err_message, obj_type)
SELECT
t.referencing_id
, obj_name = QUOTENAME(SCHEMA_NAME(o.[schema_id])) + '.' + QUOTENAME(o.name)
, 'Invalid object name ''' + t.obj_name + ''''
, o.[type]
FROM (
SELECT
d.referencing_id
, obj_name = MAX(COALESCE(d.referenced_database_name + '.', '')
+ COALESCE(d.referenced_schema_name + '.', '')
+ d.referenced_entity_name)
FROM sys.sql_expression_dependencies d
WHERE d.is_ambiguous = 0
AND d.referenced_id IS NULL
AND d.referenced_server_name IS NULL -- ignore objects from Linked server
AND CASE d.referenced_class -- if does not exist
WHEN 1 -- object
THEN OBJECT_ID(
ISNULL(QUOTENAME(d.referenced_database_name), DB_NAME()) + '.' +
ISNULL(QUOTENAME(d.referenced_schema_name), SCHEMA_NAME()) + '.' +
QUOTENAME(d.referenced_entity_name))
WHEN 6 -- or user datatype
THEN TYPE_ID(
ISNULL(d.referenced_schema_name, SCHEMA_NAME()) + '.' + d.referenced_entity_name)
WHEN 10 -- or XML schema
THEN (
SELECT 1 FROM sys.xml_schema_collections x
WHERE x.name = d.referenced_entity_name
AND x.[schema_id] = ISNULL(SCHEMA_ID(d.referenced_schema_name), SCHEMA_ID())
)
END IS NULL
GROUP BY d.referencing_id
) t
JOIN sys.objects o ON t.referencing_id = o.[object_id]
WHERE LEN(t.obj_name) > 4 -- hide valid aliases
DECLARE
@obj_id INT
, @obj_name NVARCHAR(1000)
, @obj_type CHAR(2)
DECLARE cur CURSOR FAST_FORWARD READ_ONLY LOCAL FOR
SELECT
sm.[object_id]
, QUOTENAME(SCHEMA_NAME(o.[schema_id])) + '.' + QUOTENAME(o.name)
, o.[type]
FROM sys.sql_modules sm
JOIN sys.objects o ON sm.[object_id] = o.[object_id]
LEFT JOIN (
SELECT s.referenced_id
FROM sys.sql_expression_dependencies s
JOIN sys.objects o ON o.object_id = s.referencing_id
WHERE s.is_ambiguous = 0
AND s.referenced_server_name IS NULL
AND o.[type] IN ('C', 'D', 'U')
GROUP BY s.referenced_id
) sed ON sed.referenced_id = sm.[object_id]
WHERE sm.is_schema_bound = 0 -- objects without SCHEMABINDING
AND sm.[object_id] NOT IN (SELECT o2.obj_id FROM #objects o2)
AND OBJECTPROPERTY(sm.[object_id], 'IsEncrypted') = 0
AND (
o.[type] IN ('IF', 'TF', 'V', 'TR') --OR o.[type] = 'P' /* Microsoft Connect #656863 */
OR (
o.[type] = 'FN'
AND
-- ignore scalar functions, which are used in DEFAULT/CHECK constraints and COMPUTED columns
sed.referenced_id IS NULL
)
)
OPEN cur
FETCH NEXT FROM cur INTO @obj_id, @obj_name, @obj_type
WHILE @@FETCH_STATUS = 0 BEGIN
BEGIN TRY
BEGIN TRANSACTION
EXEC sys.sp_refreshsqlmodule @name = @obj_name, @namespace = N'OBJECT'
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() != 0
ROLLBACK TRANSACTION
INSERT INTO #objects (obj_id, obj_name, err_message, obj_type)
SELECT @obj_id, @obj_name, ERROR_MESSAGE(), @obj_type
END CATCH
FETCH NEXT FROM cur INTO @obj_id, @obj_name, @obj_type
END
CLOSE cur
DEALLOCATE cur
SELECT obj_name, err_message, obj_type
FROM #objects
The same script for SQL Server 2005:
SET NOCOUNT ON;
IF OBJECT_ID('tempdb.dbo.#objects') IS NOT NULL
DROP TABLE #objects
CREATE TABLE #objects (
obj_name NVARCHAR(1000)
, err_message NVARCHAR(3000) NOT NULL
, obj_type CHAR(2) NOT NULL
)
DECLARE
@obj_name NVARCHAR(1000)
, @obj_type CHAR(2)
DECLARE cur CURSOR FAST_FORWARD READ_ONLY LOCAL FOR
SELECT
QUOTENAME(SCHEMA_NAME(o.[schema_id])) + '.' + QUOTENAME(o.name)
, o.[type]
FROM sys.sql_modules sm
JOIN sys.objects o ON sm.[object_id] = o.[object_id]
LEFT JOIN (
SELECT s.referenced_major_id
FROM sys.sql_dependencies s
JOIN sys.objects o ON o.object_id = s.[object_id]
WHERE o.[type] IN ('C', 'D', 'U')
GROUP BY s.referenced_major_id
) sed ON sed.referenced_major_id = sm.[object_id]
WHERE sm.is_schema_bound = 0
AND OBJECTPROPERTY(sm.[object_id], 'IsEncrypted') = 0
AND (
o.[type] IN ('IF', 'TF', 'V', 'TR')
OR (
o.[type] = 'FN'
AND
sed.referenced_major_id IS NULL
)
)
OPEN cur
FETCH NEXT FROM cur INTO @obj_name, @obj_type
WHILE @@FETCH_STATUS = 0 BEGIN
BEGIN TRY
BEGIN TRANSACTION
EXEC sys.sp_refreshsqlmodule @name = @obj_name, @namespace = N'OBJECT'
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() != 0
ROLLBACK TRANSACTION
INSERT INTO #objects (obj_name, err_message, obj_type)
SELECT @obj_name, ERROR_MESSAGE(), @obj_type
END CATCH
FETCH NEXT FROM cur INTO @obj_name, @obj_type
END
CLOSE cur
DEALLOCATE cur
SELECT obj_name, err_message, obj_type
FROM #objects
Script execution results are as follows (for a test database):
obj_name err_message obj_type --------------------------------- ------------------------------------------------------------------------------- -------- [dbo].[vw_EmployeePersonalInfo] An insufficient number of arguments were supplied for ‘dbo.GetEmployee’ V [dbo].[udf_GetPercent] Invalid column name ‘Code’. FN [dbo].[trg_AIU_Sync] Invalid column name ‘DateOut’. P [dbo].[trg_IOU_SalaryEmployee] Invalid object name ‘dbo.tbl_SalaryEmployee’. TR [dbo].[trg_IU_ReturnDetail] The object ‘dbo.ReturnDetail’ does not exist or is invalid for this operation. TR [dbo].[ReportProduct] Invalid object name ‘dbo.ProductDetail’. IF
SQL Server doesn’t check an object’s name while creating a synonym. So, a synonym can be created for a non-existing object.
To find all invalid synonyms, you can use the following script:
SELECT QUOTENAME(SCHEMA_NAME(s.[schema_id])) + '.' + QUOTENAME(s.name)
FROM sys.synonyms s
WHERE PARSENAME(s.base_object_name, 4) IS NULL -- ignore objects from Linked server
AND OBJECT_ID(s.base_object_name) IS NULL
If there is a need to add this check to a current script:
...
SELECT obj_name, err_message, obj_type
FROM #objects
UNION ALL
SELECT
QUOTENAME(SCHEMA_NAME(s.[schema_id])) + '.' + QUOTENAME(s.name) COLLATE DATABASE_DEFAULT
, 'Invalid object name ''' + s.base_object_name + '''' COLLATE DATABASE_DEFAULT
, s.[type] COLLATE DATABASE_DEFAULT
FROM sys.synonyms s
WHERE PARSENAME(s.base_object_name, 4) IS NULL
AND OBJECT_ID(s.base_object_name) IS NULL
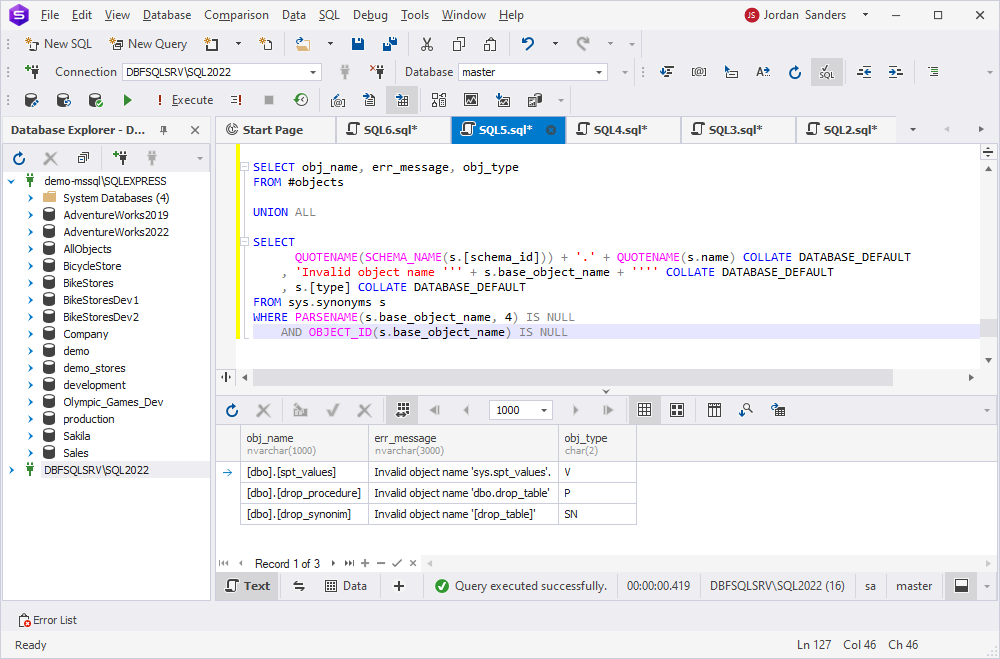
As you can see, metadata is a way to extend the standard functionality of SSMS to perform your day-to-day database tasks.
If this task seems tiresome and requires much effort, you can simplify the process and save a substantial amount of time with SQL Complete, a code completion add-in for SSMS and VS. This powerful functionality allows you to easily detect mismatched objects across multiple databases and generate effective scripts to manage them.
By the way, both SQL Complete and dbForge Studio for SQL Server have advanced functionality with the Find Invalid Objects feature included. The Studio will help you save time and effort searching for invalid objects in one or multiple databases, either using the Find Invalid Objects manager or from the command line.
Find invalid objects in a database using the Studio
To begin, open the Studio. Then, you need to access the Find Invalid Objects manager by using one of the following ways:
- In Database Explorer, right-click the Database node and select Tasks > Find Invalid Objects.
- Go to the Administration tab of the Start Page and select Find Invalid Objects.
- On the ribbon, select Database > Find Invalid Objects.
In the manager that opens, specify the connection, select the required databases, and click Analyze to start searching.
The tool displays a grid of invalid objects, showing the object type, schema, name, and reason for invalidity. Additionally, the invalid object is highlighted in the SQL script generated in the Preview pane at the bottom of the page.
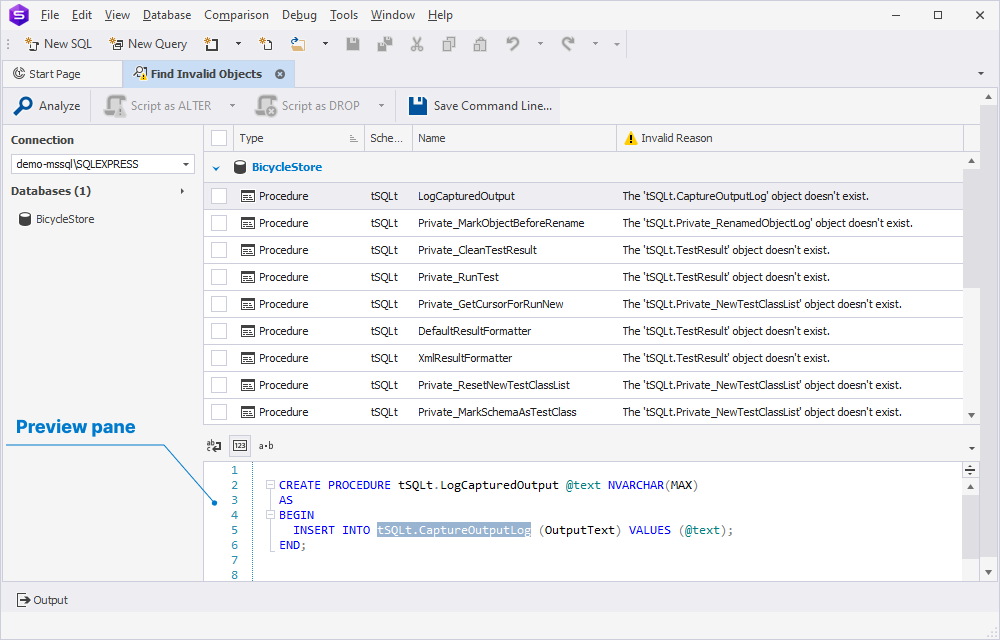
dbForge Studio also provides the Find Invalid Objects CLI feature for identifying and managing invalid database objects efficiently. You can use the built-in Command Line Wizard to convert your search options into command-line syntax and save them as a *.bat file. This allows you to automate the search for invalid objects or schedule it to run from the command line.
To open the Command Line Wizard, click Save Command Line on the toolbar. In the wizard, specify the options for generating the batch file and performing the search. Then, click Validate to verify the script. To save the file, click Save and specify the path to the file.
After creating the batch file, you can execute it from the command line using the /findinvalidobjects cmdlet command.
Start with opening the Command Prompt or terminal. Then, navigate to the installation folder of dbForge Studio for SQL Server using the cd command. Note that the default installation folder is C:\Program Files\Devart\dbForge Studio for SQL Server.
To proceed, specify the following command:
dbforgesql.com /findinvalidobjects /connection:"Data Source=server_name; Integrated Security=False; User ID=username"; /database:database_namewhere logfile.txt is a path to the log file the operation will create after completion, and report.csv is a path to the report file the operation will generate after completion.
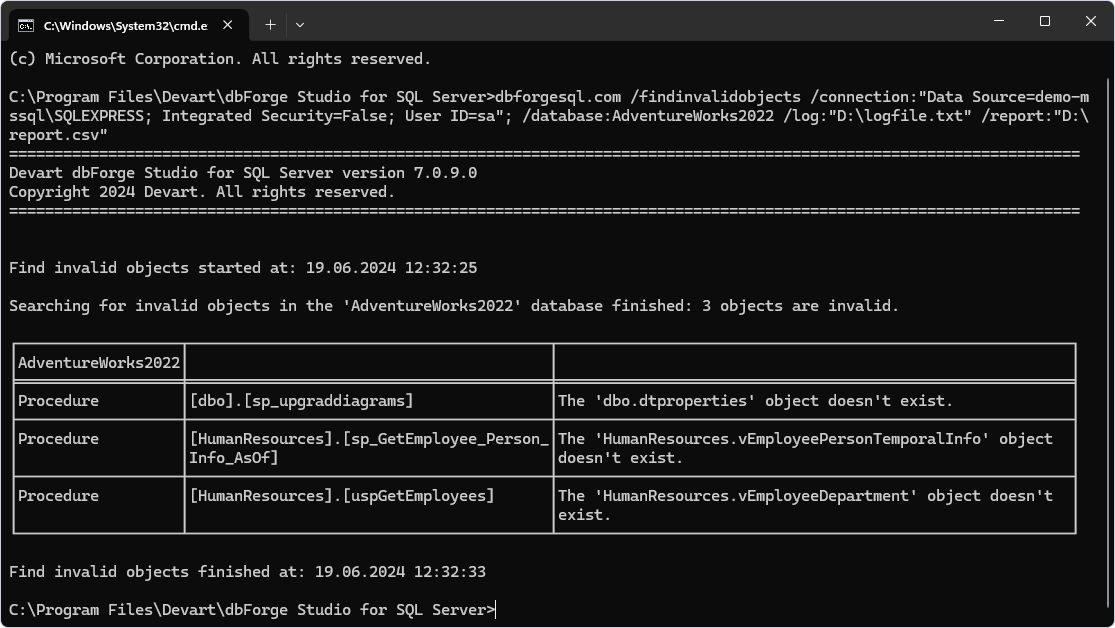
That’s it! The search for invalid objects has been done.
MySQL
Now, let’s take a closer look at how to find invalid objects in MySQL databases using the MySQL Database Refactoring Tool, which is available in dbForge Studio for MySQL. The tool helps you search through a MySQL database schema to identify and recompile invalid objects, such as functions, procedures, triggers, and views. It also allows you to preview code changes and rename aliases.
Open the Studio, navigate to the main Database menu, and select Tasks >Find Invalid Objects. Alternatively, right-click the database in Database Explorer and select Tasks> Find Invalid Objects.
The Find Invalid Objects manager opens. Here, you need to choose the connection and database through which you want to search for invalid objects. To proceed, click Analyze.
The results are displayed as a grid, where you can see the invalid object, its name, and why it is considered invalid. In addition, the tool highlights the invalid object in the code below the grid.
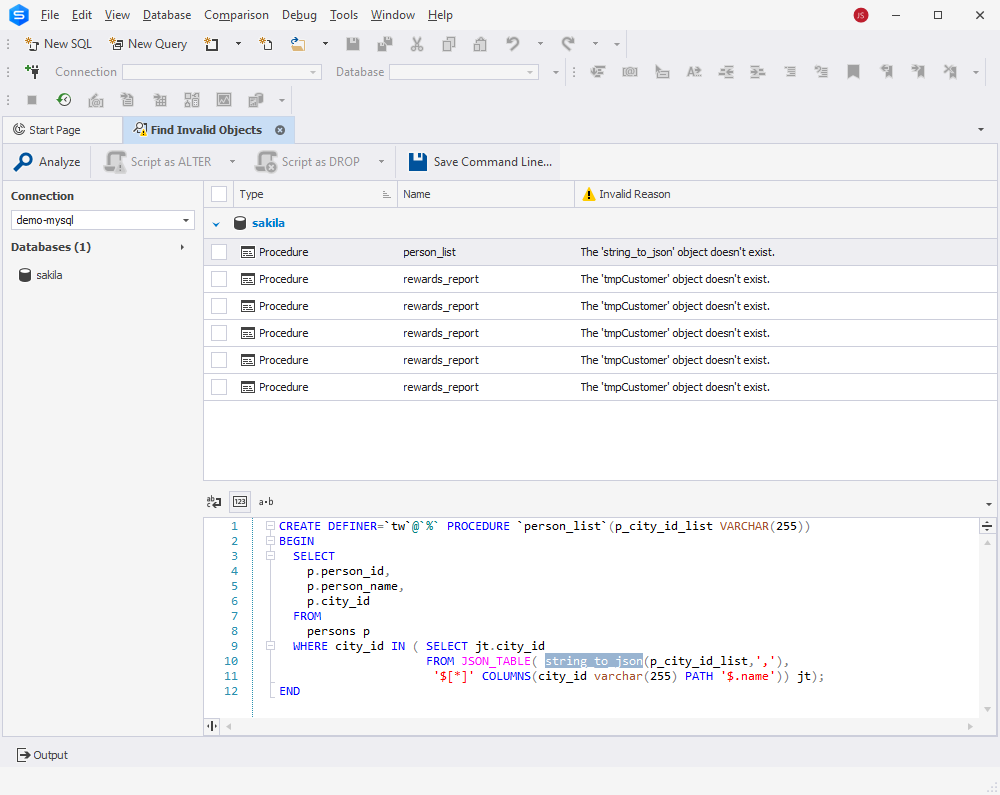
You can also generate an ALTER or DROP script for the selected invalid object in a new SQL document or copy it to the clipboard.
To automate the search for invalid objects, simply open the Command Prompt or terminal and run the /findinvalidobjects command:
dbforgemysql.com /findinvalidobjects [/option_name1[:value | [parameter1:value parameter2:value ..]] /option_name2 ..]Replace the placeholders with your actual data. For more information, see Finding Invalid Objects.
Want to learn more about ways to improve your workflows and reduce troubleshooting time? Explore debugging MySQL stored routines within dbForge Studio for MySQL.
dbForge Edge for database management
In this article, we used the Studios that are part of dbForge Edge, an ultimate toolset that optimizes the workflow of software and database developers. This unified solution can meet the needs of DBAs, analysts, and DevOps engineers who work with different database systems on a regular basis. dbForge Edge offers a wide range of powerful features and functionalities, including:
- Cross-platform support for multiple database systems, including SQL Server, Oracle, MySQL, MariaDB, and PostgreSQL.
- A feature-rich toolset that covers all important aspects of database management. From database design to query building, data comparison and synchronization, and performance analysis and optimization tools, it has everything you need to efficiently manage your database structures and ensure data integrity and consistency.
- Enhanced Find Invalid Objects feature that allows users to quickly identify and fix invalid objects in their databases in the GUI or from the command line. This feature will streamline your workflow and improve your productivity.
- Automation of the search for invalid objects in DevOps workflows with the Find Invalid Objects cmdlet. This allows development teams to automate the detection of issues that might cause failures, and thus improve performance and deployments.
So, the feature of this cross-platform suite to find and manage invalid objects, combined with its support for DevOps automation, makes it a useful tool for database administrators and developers who want to maintain high standards of database performance and reliability.
Conclusion
When working with a database, it is common practice to have a number of invalid objects that hinder your work and cause errors. The important thing to do is to find and validate them at the proper time. In this article, we have taken you through some of the most important things to know about invalid objects in Oracle and SQL databases and provided scripts that will assist you in identifying them. We also want to highlight that if you experience difficulties, there are automated ways to work with, identify, and fix invalid objects provided at Devart and other companies.
Good script. There is a mistake IF XACT_STATE() 0 should be IF XACT_STATE() 0.
The script to find all invalid synonyms gave me this error though “Implicit conversion of char value to char cannot be performed because the collation of the value is unresolved due to a collation conflict.”
Tola, thanks for the note. Try to add
COLLATE DATABASE_DEFAULTThanks for this great article.
there is a little mistake in the script.
Wrong
IF XACT_STATE() 0
ROLLBACK TRANSACTION
Correct
IF XACT_STATE() = 0
ROLLBACK TRANSACTION
Done. M. Lembke, thanks for your note.
Great script! Trying to Copy a DB and got error “Invalid Object Name ‘xxxxxx’. I was scratching my head for hours trying to figure out how to find this Invalid Object name. This script did the trick.
Sometimes the script lists ‘inserted’ or ‘deleted’ aliases as invalid object.