
In diesem Artikel werden wir untersuchen, wie man SQL-Abfragen optimiert und die Abfrageleistung verbessert, indem man Tipps und Techniken zur Optimierung von SQL-Abfragen verwendet, wie z. B. Ausführungspläne, Indizes, Wildcards u.v.m.

Wenn Unternehmen bei SQL Servern mit Leistungsproblemen konfrontiert sind, konzentrieren sie sich in der Regel auf die Anwendung von Performance-Tuning-Tools und Optimierungstechniken. Diese helfen nicht nur bei der Analyse und Beschleunigung von Abfragen, sondern auch bei der Beseitigung von Leistungsproblemen, der Fehlerbehebung bei schlechter Leistung, der Vermeidung von Chaos oder der Minimierung der Auswirkungen auf SQL Server-Datenbanken.
Inhalt
- Grundlagen der SQL-Abfrageoptimierung
- 12 Tipps zur Abfrageoptimierung für eine bessere Performance
- Tipp 1: Fügen Sie fehlende Indizes hinzu
- Tipp 2: Prüfen Sie auf unbenutzte Indizes
- Tipp 3: Vermeiden Sie die Verwendung mehrerer OR im FILTER-Prädikat
- Tipp 4: Verwenden Sie Platzhalter nur am Ende eines Ausdrucks
- Tipp 5: Vermeiden Sie zu viele JOINs
- Tipp 6: Vermeiden Sie die Verwendung von SELECT DISTINCT
- Tipp 7: Verwenden Sie SELECT-Felder anstelle von SELECT *
- Tipp 8: Verwenden Sie TOP als Beispiel für Abfrageergebnisse
- Tipp 9: Führen Sie die Abfrage außerhalb der Hauptgeschäftszeiten durch
- Tipp 10: Minimieren Sie die Verwendung von Abfragehinweisen
- Tipp 11: Minimieren Sie große Schreibvorgänge
- Tipp 12: Erstellen Sie JOINs mit INNER JOIN (nicht WHERE)
- Bewährte Praktiken zur Optimierung von SQL-Abfragen
- Fazit
Grundlagen der SQL-Abfrageoptimierung
Die Abfrageoptimierung ist ein Prozess, bei dem die effizientesten und optimalsten Methoden und Techniken zur Verbesserung der Abfrageleistung auf Grundlage einer rationellen Nutzung von Systemressourcen und Leistungsmetriken festgelegt werden. Zweck der Abfrageoptimierung ist es, einen Weg zu finden, die Antwortzeit der Abfrage zu verkürzen, den übermäßigen Verbrauch von Ressourcen zu verhindern und eine schlechte Abfrageleistung zu identifizieren.
Im Zusammenhang mit der Abfrageoptimierung ermittelt die Abfrageverarbeitung, wie Daten schneller von SQL Server abgerufen werden können, indem die Ausführungsschritte der Abfrage, Optimierungstechniken und andere Informationen über die Abfrage analysiert werden.
12 Tipps zur Abfrageoptimierung für eine bessere Performance
Mit Hilfe von Überwachungsmetriken kann die Laufzeit von Abfragen bewertet, Leistungsschwächen aufgedeckt und aufgezeigt werden, wie sie verbessert werden können. Dazu gehören z.B. Tools wie SQL Monitor, die dabei helfen, in Echtzeit Leistungsengpässe zu erkennen und datenbankweite Trends zu analysieren.
- Ausführungsplan: Ein SQL Server-Abfrageoptimierer führt die Abfrage Schritt für Schritt aus, durchsucht Indizes, um Daten abzurufen, und bietet einen detaillierten Überblick über die Metriken während der Abfrageausführung.
- Eingabe/Ausgabe-Statistiken: Werden verwendet, um die Anzahl der logischen und physischen Lesevorgänge während der Abfrageausführung zu ermitteln, was den Usern hilft, Probleme mit der Cache-/Speicherkapazität zu erkennen.
- Puffer-Cache: Wird verwendet, um die Speichernutzung auf dem Server zu reduzieren.
- Latenzzeit: Dient der Analyse der Abfrage- oder Operationsdauer.
- Indizes: Dienen der Beschleunigung von Lesevorgängen auf dem SQL Server.
- Speicheroptimierte Tabellen: Dienen der Speicherung von Tabellendaten, um Lese- und Schreibvorgänge zu beschleunigen.
Im Nachfolgenden beschreiben wir die Best Practices zur Leistungsoptimierung von SQL Server und geben Tipps, die Sie beim Schreiben von SQL-Abfragen anwenden können.
Tipp 1: Fügen Sie fehlende Indizes hinzu
Tabellenindizes in Datenbanken helfen, Informationen schneller und effizienter abzurufen.
Wenn Sie in einem SQL Server eine Abfrage ausführen, erstellt der Optimierer einen Ausführungsplan. Wenn er einen fehlenden Index entdeckt, der zur Leistungsoptimierung erstellt werden könnte, schlägt der Ausführungsplan dies im Warnabschnitt vor. Mit diesem Vorschlag informiert er Sie darüber, welche Spalten in der aktuellen SQL-Abfrage indiziert werden sollten und wie die Leistung nach Abschluss der Abfrage verbessert werden kann.
Führen wir den Query Profiler aus, der im dbForge Studio for SQL Server verfügbar ist, um zu sehen, wie er funktioniert.
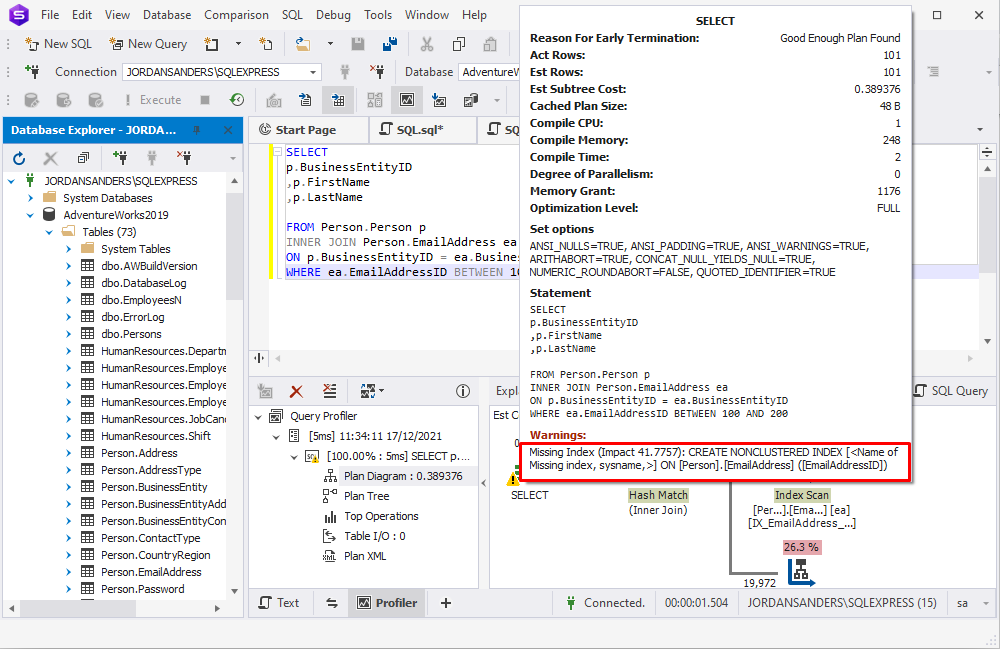
Sie sehen auch, welche Tabellen Indizes benötigen, indem Sie grafische Abfragepläne analysieren. Je dicker der Pfeil zwischen den Operatoren im Abfrageausführungsplan ist, desto mehr Daten werden übertragen. Wenn Sie dicke Pfeile sehen, sollten Sie darüber nachdenken, den zu verarbeitenden Tabellen Indizes hinzuzufügen, um die Menge der durch den Pfeil übertragenen Daten zu verringern.
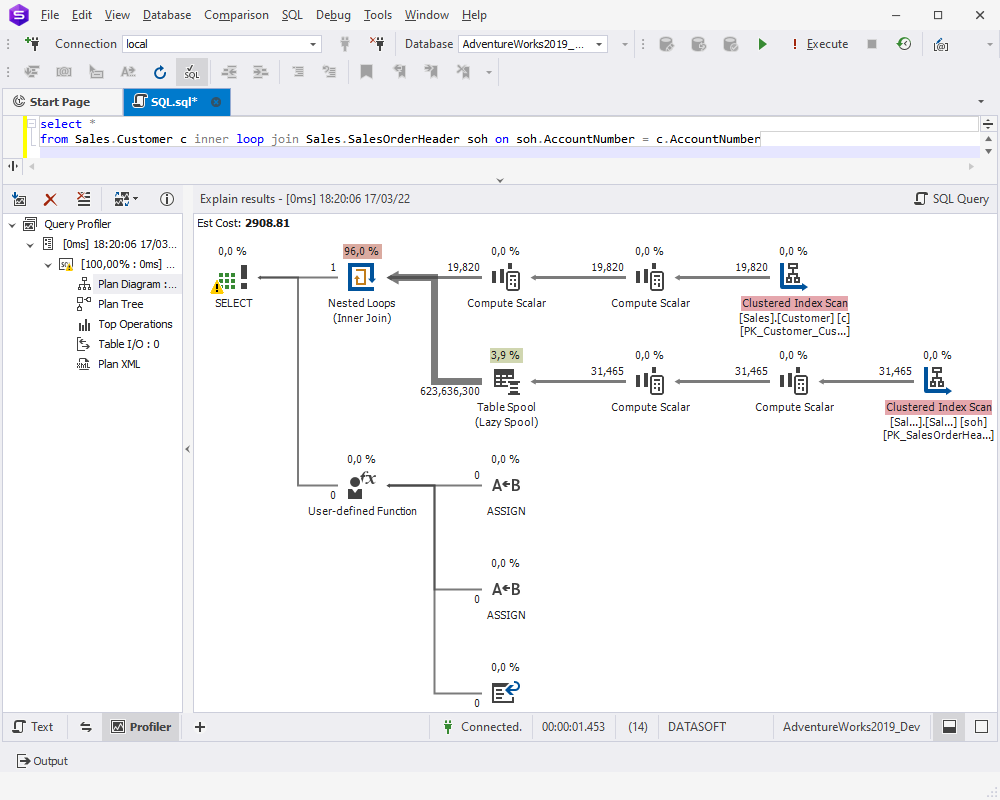
Im Ausführungsplan können Sie auf Table Spool (in unserem Fall Lazy Spool) stoßen, das eine temporäre Tabelle in der tempdb erstellt und diese nach dem Zufallsprinzip füllt. Einfach ausgedrückt wird die Tabelle nur dann durch Lesen und Speichern der Daten gefüllt, wenn einzelne Zeilen vom übergeordneten Operator benötigt werden. Der Index-Spool-Operator arbeitet in gewisser Weise ähnlich: alle Eingabezeilen werden gescannt und eine Kopie jeder Zeile wird in einer versteckten Spool-Datei abgelegt, die in der tempdb-Datenbank gespeichert wird und nur für die Dauer der Abfrage existiert. Danach wird ein Index für die Zeilen erstellt. Sowohl für den Tabellen-Spool als auch für den Index-Spool sind möglicherweise Optimierungen und das Hinzufügen von Indizes für die entsprechenden Tabellen erforderlich.
Auch verschachtelte Schleifen erfordern möglicherweise Ihre Aufmerksamkeit. Verschachtelte Schleifen müssen indiziert werden, da sie den ersten Wert aus der ersten Tabelle nehmen und nach einer Übereinstimmung in der zweiten Tabelle suchen. Ohne Indizes muss der SQL Server die gesamte Tabelle durchsuchen und verarbeiten, was zeit- und ressourcenaufwändig sein kann.
Beachten Sie, dass der fehlende Index keine 100%ige Garantie für eine bessere Leistung ist. In dem SQL Server können Sie folgende dynamische Verwaltungsansichten verwenden, um einen tiefen Einblick in die Verwendung von Indizes auf Grundlage der Abfrageausführungshistorie zu erhalten:
- sys.dm_db_missing_index_details: Liefert Informationen über den vorgeschlagenen fehlenden Index (Ausnahme: räumliche Indizes).
- sys.dm_db_missing_index_columns: Gibt Informationen über die Tabellenspalten zurück, die keine Indizes enthalten.
- sys.dm_db_missing_index_group_stats: Gibt aggregierte Informationen über die fehlende Indexgruppe zurück, z. B. Abfragekosten, avg_user_impact (informiert Sie darüber, wie sehr die Leistung durch die Erhöhung des fehlenden Index verbessert werden kann) und einige andere Metriken zur Messung der Effektivität.
- sys.dm_db_missing_index_groups: Liefert Informationen über fehlende Indizes, die in einer bestimmten Indexgruppe enthalten sind.
Tipp 2: Prüfen Sie auf unbenutzte Indizes
Es kann vorkommen, dass Indizes zwar vorhanden sind, aber nicht verwendet werden. Einer der Gründe dafür könnte die implizite Datentypkonvertierung sein. Betrachten wir folgende Abfrage:
SELECT
*
FROM TestTable
WHERE IntColumn = '1';Bei der Ausführung dieser Abfrage führt der SQL Server eine implizite Datentypkonvertierung durch, d. h. er konvertiert int-Daten in varchar und führt den Vergleich erst danach aus. In diesem Fall werden die Indizes nicht verwendet. Wie können Sie dies vermeiden? Wir empfehlen die Verwendung der Funktion CAST(), die einen Wert beliebigen Typs in einen bestimmten Datentyp umwandelt. Sehen Sie sich folgende Abfrage an.
SELECT *
FROM TestTableWHERE IntSpalte = CAST(@char AS INT);Schauen wir uns ein weiteres Beispiel an.
SELECT
*
FROM TestTable
WHERE DATEPART(YEAR, SomeMyDate) = '2021';In diesem Fall findet auch eine implizite Datentypkonvertierung statt und die Indizes werden nicht verwendet. Um dies zu vermeiden, können wir die Abfrage wie folgt optimieren:
SELECT
*
FROM TestTable
WHERE SomeDate >= '20210101'AND SomeDate < '20220101'Auch gefilterte Indizes können die Leistung beeinträchtigen. Angenommen, wir haben einen Index für die Tabelle Customer.
CREATE UNIQUE NONCLUSTERED INDEX IX ON Customer (MembershipCode)
WHERE MembershipCode IS NOT NULL;Der Index funktioniert nicht für folgende Abfrage:
SELECT
*
VON Kunde
WHERE MembershipCode = '258410';Um den Index zu nutzen, müssen Sie die Abfrage wie folgt optimieren:
SELECT
*
VON Kunde
WHERE MembershipCode = '258410'AND MembershipCode IS NOT NULL;Tipp 3: Vermeiden Sie die Verwendung mehrerer OR im FILTER-Prädikat
Wenn Sie zwei oder mehr Bedingungen kombinieren müssen, empfiehlt es sich, den OR-Operator nicht zu verwenden oder die Abfrage aufzuteilen – die Suchausdrücke trennen. Der SQL Server kann OR nicht in einer einzigen Operation verarbeiten. Stattdessen wertet er jede Komponente des OR aus, was wiederum die Leistung beeinträchtigen kann.
Schauen wir uns folgende Abfrage an:
SELECT
*
FROM USER
WHERE Name = @P
OR login = @P;Wenn wir diese Abfrage in zwei SELECT-Abfragen aufteilen und sie mit dem UNION-Operator kombinieren, kann der SQL Server die Indizes nutzen. Als Resultat wird die Abfrage optimiert.
SELECT * FROM USER
WHERE Name = @P
UNION
SELECT * FROM USER
WHERE login = @P;Tipp 4: Verwenden Sie Platzhalter nur am Ende eines Ausdrucks
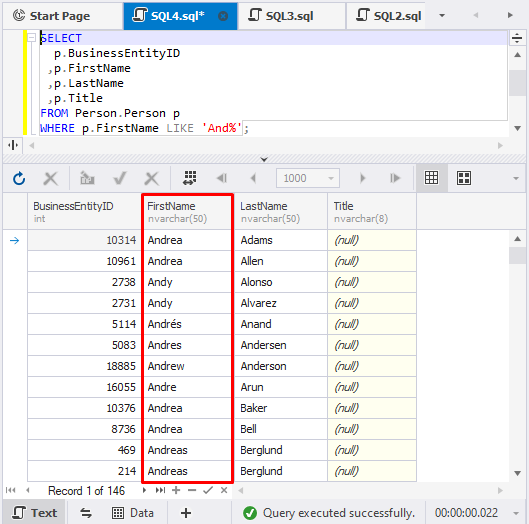
Wildcards dienen als Platzhalter für Wörter und Ausdrücke und können am Anfang/Ende von ihnen eingefügt werden. Um die Datenabfrage schneller und effizienter zu gestalten, können Sie Wildcards in dem SELECT-Befehl am Ende eines Ausdrucks verwenden. z.B.:
SELECT
p. BusinessEntityID
,p. FirstName
,p. LastName
,p. Title
FROM person. person p
WHERE p. LastName LIKE 'And%';Das Ergebnis dieser Abfrage ist eine Kundenliste, deren Vorname der angegebenen Bedingung entspricht, d. h. deren FirstName mit “And” beginnt.
Es kann jedoch vorkommen, dass Sie regelmäßig nach den letzten Symbolen eines Wortes, einer Zahl oder eines Satzes suchen müssen, z.B. nach den letzten Ziffern einer Telefonnummer. In diesem Fall empfehlen wir, eine feststehende Spalte zu erstellen und die Funktion REVERSE() darauf anzuwenden, um die Rückwärtssuche zu erleichtern.
CREATE TABLE dbo.Customer (
id INT IDENTITY PRIMARY KEY
,CardNo VARCHAR(128)
,ReversedCardNo AS REVERSE(CardNo) PERSISTED
)
GO
CREATE INDEX ByReversedCardNo ON dbo.Customer (ReversedCardNo)
GO
CREATE INDEX ByCardNo ON dbo.Customer (CardNo)
GO
INSERT INTO dbo.Customer (CardNo)
SELECT
NEWID()
FROM master.dbo.spt_values sv
SELECT TOP 100
*
FROM Customer c
--searching for CardNo that end in 510c
SELECT
*
FROM dbo.Customer
WHERE CardNo LIKE '%510c'
SELECT
*
FROM dbo.Customer
WHERE ReversedCardNo LIKE REVERSE('%510c')Tipp 5: Vermeiden Sie zu viele JOINs
Wenn Sie einer Abfrage mehrere Tabellen hinzufügen und diese miteinander verknüpfen, kann es das System überlasten. Darüber hinaus kann eine große Anzahl von Tabellen, aus denen Daten abgerufen werden müssen, zu einem ineffizienten Ausführungsplan führen. Bei der Erstellung eines Plans muss der SQL-Abfrageoptimierer ermitteln, wie die Tabellen verbunden werden, in welcher Reihenfolge, wie und wann Filter und Aggregationen anzuwenden sind.
Die JOIN-Eliminierung ist eine der vielen Techniken zur Erreichung effizienter Abfragepläne. Sie können eine einzelne Abfrage in mehrere separate Abfragen aufteilen, die später zusammengefügt werden können und so unnötige Joins, Unterabfragen, Tabellen, usw. entfernen.
Tipp 6: Vermeiden Sie die Verwendung von SELECT DISTINCT
Der SQL-Operator DISTINCT wird verwendet, um nur eindeutige Werte der Spalte auszuwählen und somit doppelte Werte zu eliminieren. Er hat die folgende Syntax:
SELECT DISTINCT column_name FROM table_name;Dies kann jedoch dazu führen, dass das Tool große Datenmengen verarbeiten muss und die Abfrage dadurch verlangsamt wird. Im Allgemeinen wird empfohlen, die Verwendung von SELECT DISTINCT zu vermeiden und einfach den SELECT-Befehl auszuführen, aber Spalten anzugeben.
Ein weiteres Problem besteht darin, dass häufig unnötigerweise JOINs erstellt werden. Wenn sich die Datenmenge verdoppelt, wird DISTINCT hinzugefügt. Dies geschieht hauptsächlich in einer Leader-Follower-Beziehung, wenn man SELECT DISTINCT ... FROM LEADER JOIN FOLLOWER... anstatt das korrekte
Tipp 7: Verwenden Sie SELECT-Felder anstelle von SELECT *
Der SELECT-Befehl wird verwendet, um Daten aus der Datenbank abzurufen. Bei großen Datenbanken ist es nicht empfehlenswert, alle Daten abzurufen, da dies mehr Ressourcen für die Abfrage eines großen Datenvolumens erfordert.
Wenn wir folgende Abfrage ausführen, rufen wir alle Daten aus der Tabelle “User” ab, z. B. auch die User-AvatarAbb.er. Die Ergebnistabelle wird viele Daten enthalten und zu viel Arbeitsspeicher und CPU-Auslastung benötigen.
SELECT
*
FROM Users;Stattdessen können Sie genau die Spalten angeben, aus denen Sie Daten abrufen möchten und so Datenbankressourcen sparen. In diesem Fall ruft der SQL Server nur die erforderlichen Daten ab und die Abfrage verursacht geringere Kosten.
Beispiel:
SELECT
FirstName
,LastName
,Email
,Login
FROM Users;Wenn Sie diese Daten regelmäßig abrufen müssen, z. B. zu Authentifizierungszwecken, empfehlen wir die Verwendung von Abdeckungsindizes, deren größter Vorteil darin besteht, dass sie alle für die Abfrage erforderlichen Felder enthalten, die Abfrageleistung erheblich verbessern und bessere Ergebnisse garantieren können.
CREATE NONCLUSTERED INDEX IDX_Users_Covering ON Users
INCLUDE (FirstName, LastName, Email, Login)Tipp 8: Verwenden Sie TOP als Beispiel für Abfrageergebnisse
Der Befehl SELECT TOP wird verwendet, um die Anzahl der Datensätze zu begrenzen, die die Datenbank zurückgegeben soll. Um sicherzustellen, dass Ihre Abfrage das gewünschte Ergebnis liefert, können Sie diesen Befehl verwenden, um mehrere Zeilen abzurufen.
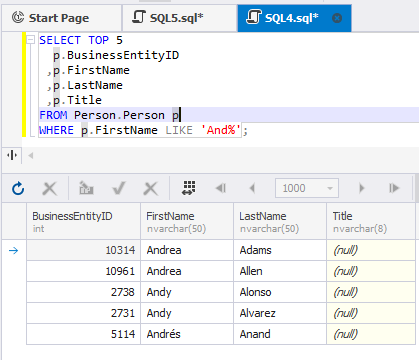
Nehmen Sie z.B. die Abfrage aus dem vorigen Abschnitt und definieren Sie die Grenze von 5 Datensätzen in der Ergebnismenge.
SELECT TOP 5
p.BusinessEntityID
,p.FirstName
,p.LastName
,p.Title
FROM Person.Person p
WHERE p.FirstName LIKE 'And%';Mit dieser Abfrage werden nur 5 Datensätze abgerufen, die der Bedingung entsprechen:
Tipp 9: Führen Sie die Abfrage außerhalb der Hauptgeschäftszeiten durch
Eine weitere SQL-Tuning-Technik besteht darin, die Ausführung von Abfragen außerhalb der Stoßzeiten zu planen, insbesondere wenn Sie mehrere SELECT-Abfragen aus großen Tabellen ausführen müssen oder komplexe Abfragen mit verschachtelten Unterabfragen, Schleifenabfragen, usw. Wenn Sie eine umfangreiche Abfrage für eine Datenbank ausführen, sperrt SQL Server die Tabellen, in denen Sie arbeiten, um die gleichzeitige Nutzung von Ressourcen durch verschiedene Anwendungen zu verhindern. Das bedeutet, dass andere User nicht in der Lage sind, mit diesen Tabellen zu arbeiten. Die Ausführung umfangreicher Abfragen zu Stoßzeiten führt also nicht nur zu einer Überlastung des Servers, sondern auch dazu, dass der Zugriff anderer User auf bestimmte Datenmengen eingeschränkt wird. Einer der beliebtesten Mechanismen, um dies zu vermeiden, ist die Verwendung des WITH (NOLOCK). Er ermöglicht es dem User, die Daten abzurufen, ohne von den Sperren betroffen zu sein. Der größte Nachteil der Verwendung von WITH (NOLOCK) besteht darin, dass es zu einer Verunreinigung der Daten kommen kann. Wir raten Ihnen, die Snapshot-Isolation vorzuziehen, die durch die Verwendung der Zeilenversionierung Datensperren vermeidet und garantiert, dass jede Transaktion einen konsistenten Snapshot der Datenbank sieht.
Tipp 10: Minimieren Sie die Verwendung von Abfragehinweisen
Wenn Sie mit Leistungsproblemen konfrontiert sind, können Sie Abfragehinweise zur Optimierung von Abfragen verwenden. Sie werden in T-SQL-Befehlen angegeben und veranlassen den Optimierer, den Ausführungsplan auf der Grundlage dieses Hinweises auszuwählen. Zu den Abfragehinweisen gehören normalerweise NOLOCK, Optimize For und Recompile. Sie sollten ihre Verwendung jedoch sorgfältig abwägen, denn manchmal können sie unerwartete Nebeneffekte haben oder sogar die Geschäftslogik unterbrechen, wenn Sie versuchen, das Problem zu lösen. So schreiben Sie beispielsweise einen zusätzlichen Code für die Hinweise, der nach einiger Zeit nicht mehr anwendbar oder veraltet sein kann. Das bedeutet, dass Sie Hinweise immer überwachen, verwalten, prüfen und auf dem neuesten Stand halten sollten.
Tipp 11: Minimieren Sie große Schreibvorgänge
Das Schreiben, Ändern, Löschen oder Importieren großer Datenmengen kann die Abfrageleistung beeinträchtigen und sogar die Tabelle blockieren, wenn Daten aktualisiert und manipuliert, Indizes oder Prüfbeschränkungen zu Abfragen hinzugefügt, Trigger verarbeitet werden müssen, usw. Darüber hinaus erhöht das Schreiben großer Datenmengen die Größe der Protokolldateien. Große Schreibvorgänge stellen also kein großes Leistungsproblem dar, aber Sie sollten sich ihrer Folgen bewusst und auf unerwartetes Verhalten vorbereitet sein.
Eine der besten Methoden zur Optimierung der SQL Server-Leistung ist die Verwendung von Dateigruppen, mit denen Sie Ihre Daten auf mehrere physische Festplatten verteilen können. Auf diese Weise können mehrere Schreibvorgänge gleichzeitig und damit wesentlich schneller verarbeitet werden.
Durch Komprimierung und Datenaufspaltung kann die Leistung ebenfalls optimiert und die Kosten für große Schreibvorgänge minimiert werden.
Tipp 12: Erstellen Sie JOINs mit INNER JOIN (nicht WHERE)
Der INNER JOIN-Befehl gibt alle übereinstimmenden Zeilen aus verbundenen Tabellen zurück, während die WHERE-Bedingung die resultierenden Zeilen auf der Grundlage der angegebenen Bedingung filtert. Das Abrufen von Daten aus mehreren Tabellen auf der Grundlage der WHERE-Bedingung wird als NON-ANSI JOINs bezeichnet, während INNER JOIN zu den ANSI JOINs gehört.
Für den SQL Server macht es keinen Unterschied, wie Sie die Abfrage mit ANSI- oder mit NON-ANSI-Joins schreiben. Es ist nur viel einfacher, Abfragen zu verstehen und zu analysieren, die mit ANSI-Joins geschrieben wurden. Sie können deutlich sehen, wo sich die JOIN-Bedingungen und die WHERE-Filter befinden, ob Sie irgendwelche JOIN- oder Filterprädikate übersehen haben, ob Sie die erforderlichen Tabellen verbunden haben, usw.
Sehen wir uns an einem konkreten Beispiel an, wie eine SQL-Abfrage mit INNER JOIN optimiert werden kann. Wir werden Daten aus den Tabellen HumanResources.Department und HumanResources.EmployeeDepartmentHistory abrufen, in denen die AbteilungsIDs gleich sind. Führen Sie zunächst den SELECT-Befehl mit dem Typ INNER JOIN aus:
SELECT
d.DepartmentID
,d.Name
,d.GroupName
FROM HumanResources.Department d
INNER JOIN HumanResources.EmployeeDepartmentHistory edh
ON d.DepartmentID = edh.DepartmentIDVerwenden Sie dann die WHERE-Bedingung anstelle von INNER JOIN, um die Tabellen im SELECT-Befehl zu verbinden:
SELECT
d.Name
,d.GroupName
,d.DepartmentID
FROM HumanResources.Department d
,HumanResources.EmployeeDepartmentHistory edh
WHERE d.DepartmentID = edh.DepartmentIDBeide Abfragen liefern folgendes Ergebnis:
Bewährte Praktiken zur Optimierung von SQL-Abfragen
Die Leistungsoptimierung von SQL Servern und die Optimierung von SQL-Abfragen sind einige der wichtigsten Aspekte für Datenbankentwickler und -administratoren. Sie müssen die Verwendung bestimmter Operatoren, die Anzahl der Tabellen in einer Abfrage, die Größe einer Abfrage, ihren Ausführungsplan, Statistiken, die Ressourcenzuweisung und andere Leistungsmetriken sorgfältig berücksichtigen. All diese Punkte können die Abfrageleistung verbessern und optimieren oder verschlechtern.
Für eine bessere Abfrageleistung empfehlen wir die Anwendung der im Artikel vorgestellten Tipps und Techniken, wie z. B. Ausführen von Abfragen außerhalb der Hauptgeschäftszeiten, Erstellung von Indizes, Abrufen von Daten für bestimmte Spalten, Anwendung der richtigen Filter, Verknüpfungen und Operatoren sowie das Vermeiden einer Überlastung von Abfragen.
Fazit
In diesem Artikel haben wir eine Reihe von Techniken und Tipps zur Verbesserung der Leistung behandelt. Wir hoffen, dass sie Ihnen helfen, eventuelle Leistungsprobleme zu vermeiden.
Außerdem empfehlen wir Ihnen, eine kostenlose, voll funktionsfähige 30-Tage-Testversion von dbForge Studio for SQL Server auszuprobieren, um effektiv mit SQL-Abfragen zu arbeiten.
