
The role of data analysis and manipulation in SQL Server is hard to overestimate. By partitioning data effectively, you can handle large datasets and get accurate and relevant results for various analytical and operational tasks. This is when PARTITION BY proves invaluable. In this article, we are going to talk about the theoretical foundations and practical applications of this SQL argument with the help of a convenient IDE — dbForge Studio for SQL Server.
Contents
- Understanding the PARTITION BY clause
- Key applications of PARTITION BY
- Try it yourself with dbForge Studio
- Implementing PARTITION BY in SQL queries
- Deep dive
- Advanced techniques
- Maximizing PARTITION BY in data analysis
- Further learning
- Conclusion

Understanding the PARTITION BY clause
As we usually do in our articles, let us acquaint ourselves with the fundamentals of the PARTITION BY clause before we delve into its intricacies. For an even better understanding, we will also compare it with its counterpart, GROUP BY.
PARTITION BY
PARTITION BY is a clause in SQL used within window functions that perform calculations across a set of rows related to the current row:
SELECT expression, aggregate function ()
OVER (PARTITION BY expression ORDER BY column)
FROM tables
WHERE conditions;Key points:
- It does not reduce the number of rows returned. It calculates values for each row, considering only the rows within the partition.
- It is used within window functions to perform calculations on partitions of data.
- It can be used with various window functions, not just aggregate functions.
GROUP BY
GROUP BY groups rows that have the same values. It is often used with aggregate functions in SQL (like SUM(), COUNT(), AVG(), etc.) to perform calculations on each group.
SELECT expression, aggregate function ()
FROM tables
WHERE conditions
GROUP BY expression;Key points:
- It reduces the number of rows returned by the query, collapsing multiple rows into summary rows.
- It is used with aggregate functions to summarize data.
- It requires an aggregate function to be applied to each group.
Key applications of PARTITION BY
Now that we have already discovered what PARTITION BY is, it is time we move on to cases when it is used:
- Enhancing data analysis with window functions: The clause divides the result set into partitions based on specified criteria, allowing window functions to operate independently within each partition. This way, you can perform advanced analytics and compute aggregated values, ranking, and other analytical tasks within distinct subsets of data.
- Calculating averages: You can use
AVG()withPARTITION BYto calculate averages within distinct groups, such as average sales per region or average temperature per month. - Calculating cumulative totals: You can combine
SUM()withPARTITION BYto calculate cumulative totals within each partition, such as cumulative sales over time or cumulative distance traveled per vehicle. - Ranking and percentiles:
ROW_NUMBER(),RANK(), and NTILE SQL functions combined withPARTITION BYhelp rank data within partitions or determine percentiles within specific groups. - Time series analysis:
PARTITION BYis useful for time series analysis, allowing for calculations such as moving averages, rolling sums, or identifying trends within distinct time intervals. - Top-N analysis:
PARTITION BYfacilitates identifying top or bottom N records within each partition based on specified criteria, such as top-selling products by category. - Data imputation and aggregation: The clause aids in imputing missing values based on partition-specific averages or aggregates, ensuring more accurate analysis and reporting.
- Data partitioning for performance optimization: Partitioning large datasets with
PARTITION BYcan improve query performance by limiting the scope of operations to smaller, manageable subsets of data. - Analyzing hierarchical data:
PARTITION BYassists in hierarchical data analysis by partitioning data at various levels, enabling analytics at each level without interference from other levels.
Try it yourself with dbForge Studio
Even though SQL Server Management Studio (SSMS) is the most popular and familiar tool that allows you to work with SQL Server databases, it is not the only one. Moreover, in the continuously evolving world of database development, administration, and management, new GUIs keep appearing like mushrooms after the rain. How do you choose the tool that is perfect for you in this variety?
Let us compare dbForge Studio for SQL Server with SSMS so that you can make an informed decision on which solution best aligns with your daily requirements:
| Feature | dbForge Studio for SQL Server | SQL Server Management Studio |
| User-friendly interface | Boasts an intuitive and user-friendly interface, providing a smooth user experience for both beginners and experienced developers. | While powerful, SSMS can have a steeper learning curve, particularly for those new to SQL Server tasks. |
| Advanced functionality | Offers a wide range of advanced features, including a visual query builder, data and schema comparison tools, and advanced SQL editing capabilities. | Provides all the essentials but may lack some of the advanced features available in dbForge Studio. |
| Integrated tools | Comes with integrated tools for schema and data comparison, enabling seamless data synchronization and database management out of the box. | While offering basic tools, SSMS may require auxiliary add-ons to expand its functionality. |
| Data generation | Provides a powerful data generation tool that enables the creation of realistic test data with customizable parameters, offering flexibility in data generation for specific tables and columns. | Incorporates fundamental data generation features but may necessitate additional scripts or tools for advanced and specific data generation requirements. |
| Cross-platform support | Supports Windows, macOS, and Linux, providing flexibility for users on different operating systems. | Is primarily designed for Windows, limiting its accessibility for macOS users. |
Take advantage of dbForge Studio for SQL Server by downloading a free fully-functional 30-day trial version and installing it on your computer. With a huge pack of advanced features and intuitive GUI, this all-in-one tool can maximize productivity and make SQL Server database development, administration, and management process efficient. The Studio can also be of use when it comes to today’s topic, from generating test data to performing advanced operations.
For a more visual comparison of the two solutions, watch the SSMS vs. dbForge Studio for SQL Server – Features Comparison video on the Devart YouTube channel.
Implementing PARTITION BY in SQL queries
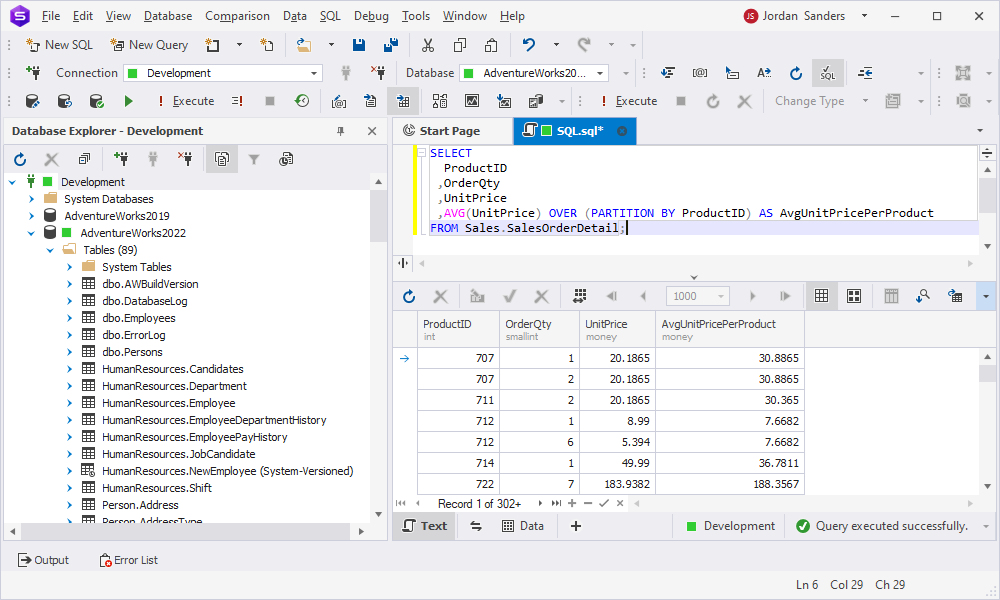
In this section of this article, we are going to try our hand at actually implementing the PARTITION BY clause in an SQL query. We chose the AdventureWorks2022 database for demonstration purposes, namely, the SalesOrderDetail table. In practice, it will look somewhat like the following code:
SELECT
ProductID
,OrderQty
,UnitPrice
,AVG(UnitPrice) OVER (PARTITION BY ProductID) AS AvgUnitPricePerProduct
FROM Sales.SalesOrderDetail;In the syntax above:
- We select the ProductID, OrderQty, and UnitPrice columns from the SalesOrderDetail table.
- We use the
AVG()window function along withPARTITION BYto calculate the average unit price for each product. - The
PARTITION BYpartitions the data by the ProductID column, so the average unit price is calculated separately for each product.
Deep dive
Having made our first steps in the practical aspect of the PARTITION BY usage, we are moving on to some more intricate examples: ranking functions. In SQL, they are used to assign a rank to each row within a partition of a result set based on specified criteria. Let us explore examples of ranking functions (ROW_NUMBER, RANK, and DENSE_RANK) used with the PARTITION BY clause.
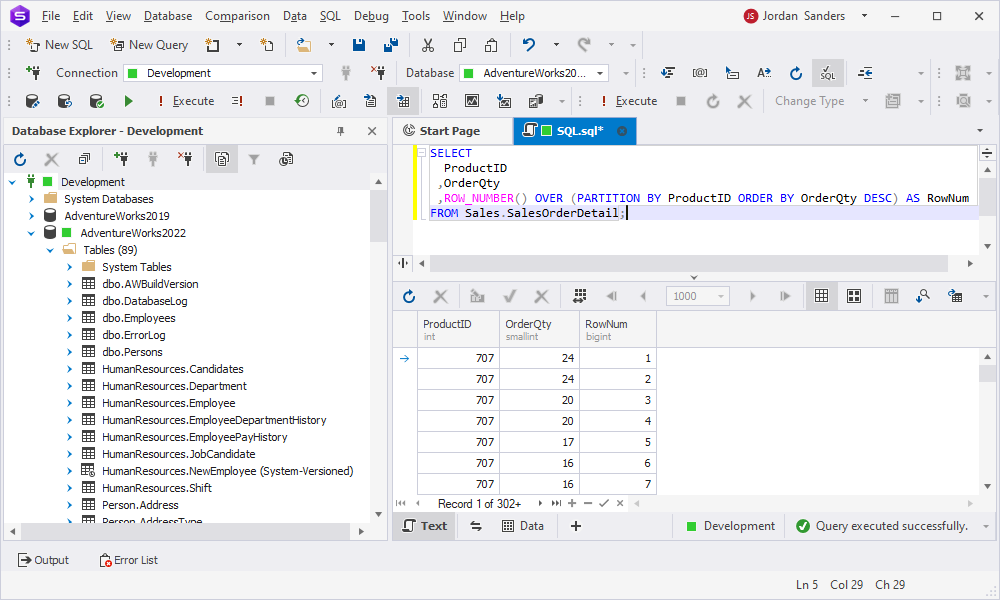
PARTITION BY with ROW_NUMBER
The first exhibit is the ROW_NUMBER() function that assigns a unique sequential integer to each row within a partition, starting from 1 for the first row:
SELECT
ProductID
,OrderQty
,ROW_NUMBER() OVER (PARTITION BY ProductID ORDER BY OrderQty DESC) AS RowNum
FROM Sales.SalesOrderDetail;The query above assigns a number to each row within each partition of ProductID, ordered by OrderQty in descending order.
PARTITION BY with RANK
The RANK() function is up next. It assigns a unique rank to each distinct row within a partition, with gaps in the ranking if there are ties:
SELECT
ProductID
,OrderQty
,RANK() OVER (PARTITION BY ProductID ORDER BY OrderQty DESC) AS Rank
FROM Sales.SalesOrderDetail;As you can see, the tied rows are assigned the same rank, but there are gaps in ranking for the next distinct value.
PARTITION BY with DENSE_RANK
Unlike RANK(), DENSE_RANK does not leave any gaps in ranking.
SELECT
ProductID
,OrderQty
,DENSE_RANK() OVER (PARTITION BY ProductID ORDER BY OrderQty DESC) AS DenseRank
FROM Sales.SalesOrderDetail;Advanced techniques
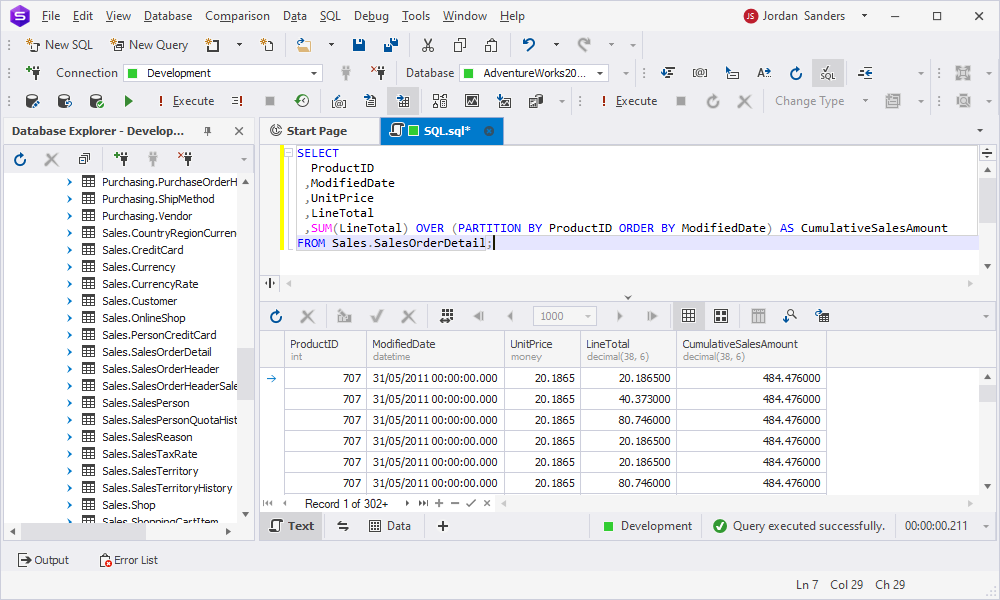
Suppose we want to calculate the cumulative sales amount for each product over time. The SalesOrderDetail table is perfect for this as it contains information about sales orders, including the product IDs and sales amounts.
SELECT
ProductID
,ModifiedDate
,UnitPrice
,LineTotal
,SUM(LineTotal) OVER (PARTITION BY ProductID ORDER BY ModifiedDate) AS CumulativeSalesAmount
FROM Sales.SalesOrderDetail;To fulfill our objective, select the ProductID, ModifiedDate, UnitPrice, and LineTotal columns from the said table. Then, use the SUM() window function along with PARTITION BY to calculate the cumulative sales amount for each product. And finally, add an ORDER BY clause just to sort the results by date.
Maximizing PARTITION BY in data analysis
The powers of the PARTITION BY clause do not end here. In this section, we will explore how to benefit from it while doing advanced data analysis. Gain deeper insights into your data, perform more complex calculations, and uncover hidden patterns and trends for more informed decision-making and more effective strategic planning for your business.
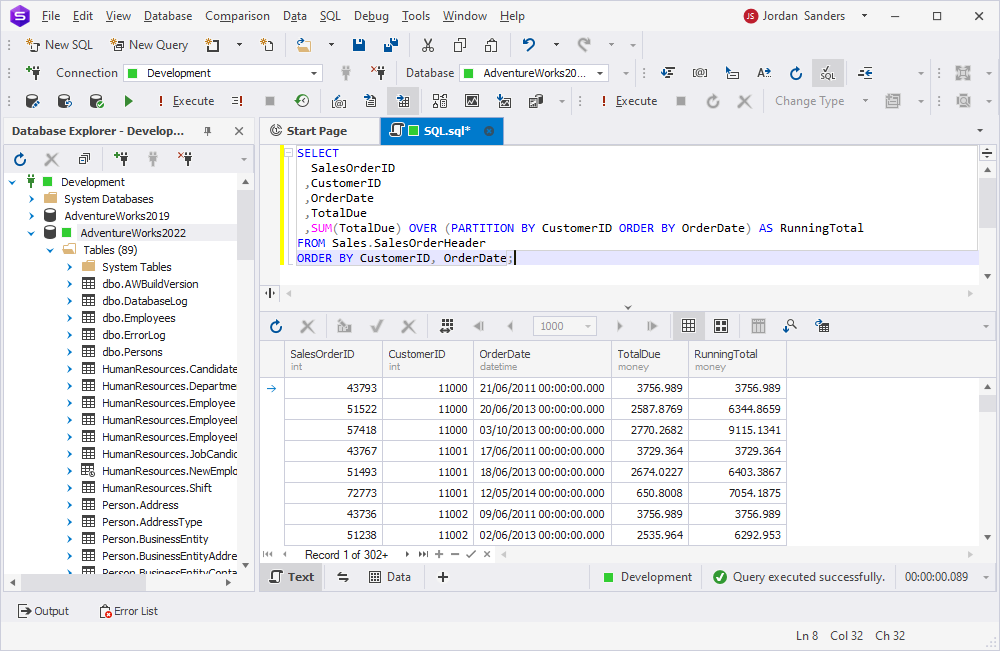
1. Running totals: Track cumulative values over time within specific segments.
SELECT
SalesOrderID
,CustomerID
,OrderDate
,TotalDue
,SUM(TotalDue) OVER (PARTITION BY CustomerID ORDER BY OrderDate) AS RunningTotal
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, OrderDate;Upon executing this query, you will calculate each customer’s total running sales amounts.
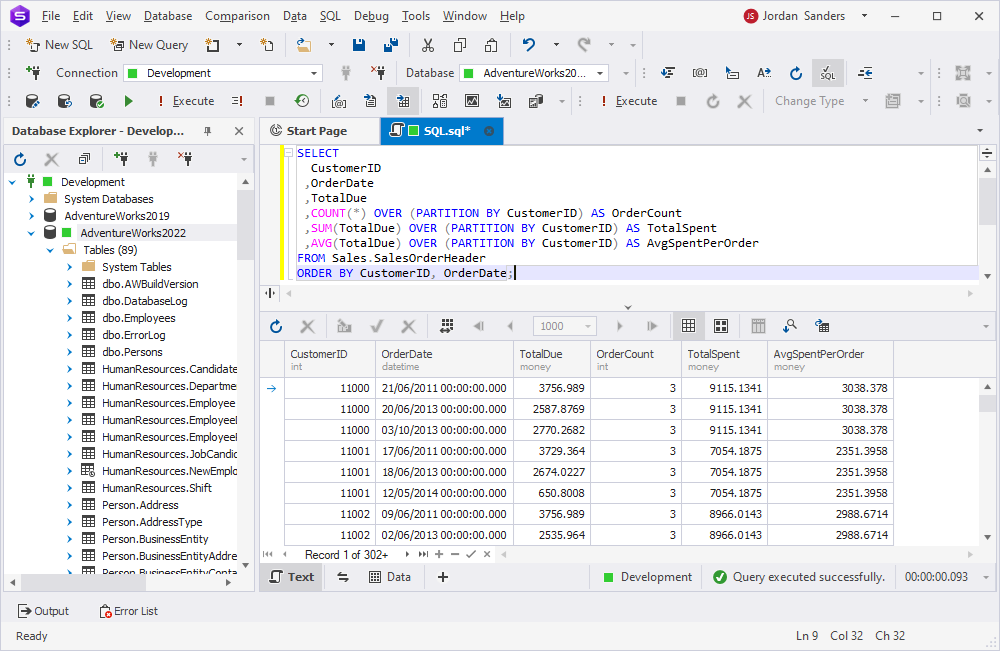
2. Complex metrics calculation: Calculate complex metrics across partitions to get deeper insights.
SELECT
CustomerID
,OrderDate
,TotalDue
,COUNT(*) OVER (PARTITION BY CustomerID) AS OrderCount
,SUM(TotalDue) OVER (PARTITION BY CustomerID) AS TotalSpent
,AVG(TotalDue) OVER (PARTITION BY CustomerID) AS AvgSpentPerOrder
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, OrderDate;The command above calculates the total number of orders, total amount spent, and average amount spent per order for each customer.
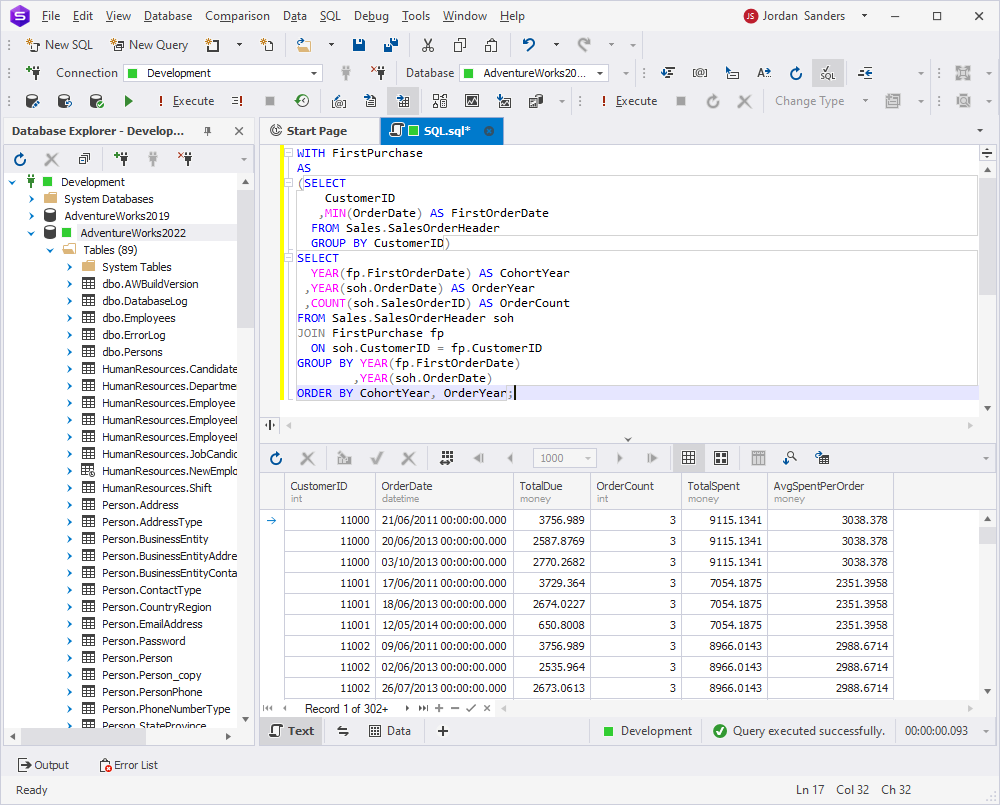
3. Cohort analysis: Track groups of users over time to identify trends.
WITH FirstPurchase
AS
(SELECT
CustomerID
,MIN(OrderDate) AS FirstOrderDate
FROM Sales.SalesOrderHeader
GROUP BY CustomerID)
SELECT
YEAR(fp.FirstOrderDate) AS CohortYear
,YEAR(soh.OrderDate) AS OrderYear
,COUNT(soh.SalesOrderID) AS OrderCount
FROM Sales.SalesOrderHeader soh
JOIN FirstPurchase fp
ON soh.CustomerID = fp.CustomerID
GROUP BY YEAR(fp.FirstOrderDate)
,YEAR(soh.OrderDate)
ORDER BY CohortYear, OrderYear;This query groups customers into cohorts based on the year of their first purchase and tracks their order counts over subsequent years.
Further learning
Conclusion
The PARTITION BY clause serves as a powerful tool in data analysis, allowing users to perform complex calculations and attain detailed insights across diverse datasets. Through hands-on examples and exploration using tools like dbForge Studio, you can gain a deeper understanding of its functionalities and potential. Moreover, dbForge Studio for SQL proves invaluable for tasks involving PARTITION BY, offering a user-friendly interface and robust features. Download its free 30-day trial version to experience its capabilities firsthand and enhance your data analysis skills even further!