
On June 1, SQL Server 2016 was released. It brought a large number of novelties into normal development, including the long-announced Stretch Database technology that allows migrating data from SQL Server dynamically to Azure.
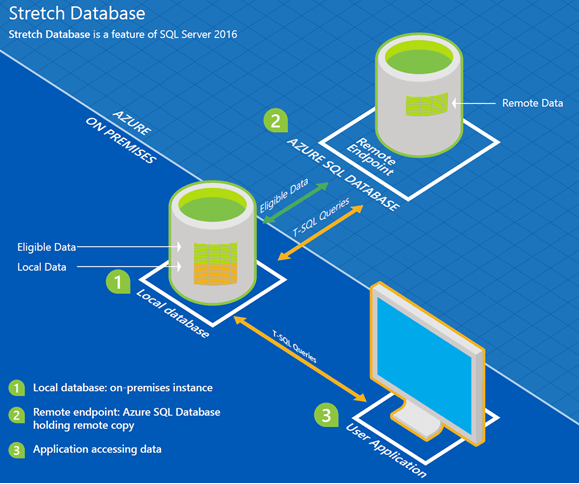
From the marketing point of view, Stretch Database has been well promoted. Reasonable arguments were stating that with the growth of historical data the complexity and cost of its maintenance grows as well. As a rational solution to the problem, the automatic migration of obsolescent archival data to the cloud was introduced. Frankly speaking, I enjoyed the idea.
As from SQL Server 2016 RC0, I began testing the Stretch Database technology on two projects I’m helping to develop. The first one is TMetric, a free time tracker with OLTP load, and the second one is an internal project with DW load.
Let’s go into Stretch Database through a simple example. The first thing to do is to allow using Stretch Database since this functionality is disabled on the server by default:
EXEC sys.sp_configure 'remote data archive' , '1' GO RECONFIGURE GO
There is no need to reload the server. Next, let’s create a test database:
USE [master]
GO
IF DB_ID('StretchDB') IS NOT NULL BEGIN
ALTER DATABASE StretchDB SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE StretchDB
END
GO
CREATE DATABASE StretchDB /* COLLATE Cyrillic_General_CI_AS */
GO
USE StretchDB
GO
CREATE TABLE dbo.ErrorLog (
LogID INT IDENTITY PRIMARY KEY
, PostTime DATETIME NOT NULL DEFAULT GETDATE()
, UserName NVARCHAR(100) NOT NULL
, ErrorMessage NVARCHAR(MAX) COLLATE Ukrainian_BIN NOT NULL
)
GO
INSERT INTO dbo.ErrorLog (UserName, ErrorMessage)
VALUES (N'sergeys', N'Azure row')
…and call the Stretch Database wizard from SSMS 2016:
The wizard cautions us at once that we must have:
1) admin privileges
2) current Azure subscription
3) allowed access to SQL Server to the Internet
On the next page of the wizard, we face the first disappointment:
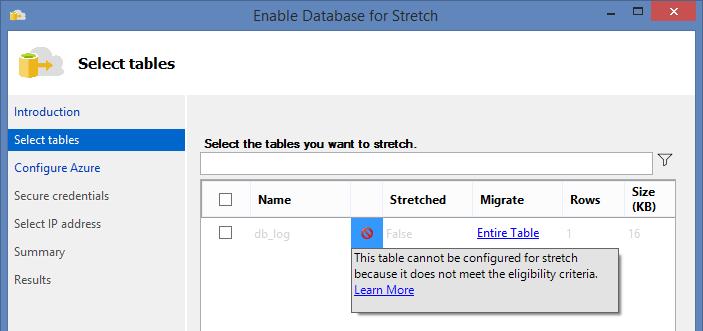
We cannot migrate data from our table to Azure because of some limitations in Stretch Database technology. I will list basic ones (limitations that are not mentioned in MSDN are highlighted in bold).
Data store in Azure is not supported for the tables which:
1) contain more than 1,023 columns and more than 998 indexes
2) include the FILESTREAM data
3) are involved in replication or use Change Tracking or Change Data Capture
4) are optimized for memory layout (In-Memory table)
5) have the Always Encrypted columns
Besides, you cannot use the following in tables:
1) all user data types (CLR, user-defined types)
2) TEXT, NTEXT, IMAGE
3) TIMESTAMP
4) SQL_VARIANT
5) XML
6) GEOMETRY, GEOGRAPHY, HIERARCHYID
7) SYSNAME
8) COLUMN_SET
9) COMPUTED columns
10) SEQUENCE in a column
11) DEFAULT and CHECK constraints
12) Full-Text Search, XML and Spatial indexes
13) there should be no index views on the table
14) external keys referring to the table (for example, you can enable Stretch for the OrderDetail child table, but you can’t do the same for the Order parent table).
As it turned out, our problem was in the DEFAULT constraint. Let’s recreate the table and try once more:
DROP TABLE IF EXISTS dbo.ErrorLog
CREATE TABLE dbo.ErrorLog (
LogID INT IDENTITY PRIMARY KEY
, PostTime DATETIME NOT NULL
, UserName NVARCHAR(100) NOT NULL
, ErrorMessage NVARCHAR(MAX) COLLATE Ukrainian_BIN NOT NULL
)
GO
INSERT INTO dbo.ErrorLog (PostTime, UserName, ErrorMessage)
VALUES (GETDATE(), N'sergeys', N'Azure row')
Now, the wizard allows to select the table:
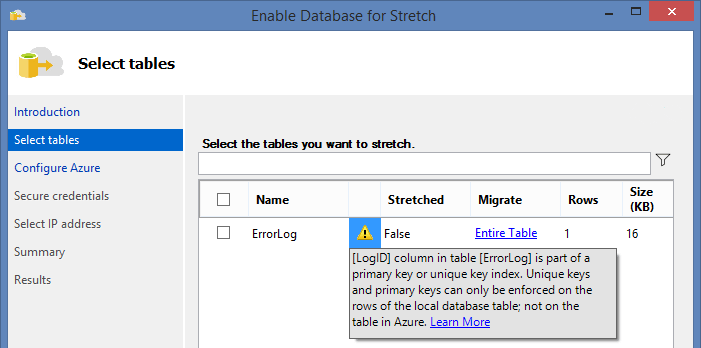
But the wizard cautions, that: Uniqueness is not enforced for UNIQUE constraints and PRIMARY KEY constraints in the Azure table that contains the migrated data. That’s why, for the Stretch tables, it’s better to create PRIMARY KEY on the IDENTITY column, or at least, to use UNIQUEIDENTIFIER.
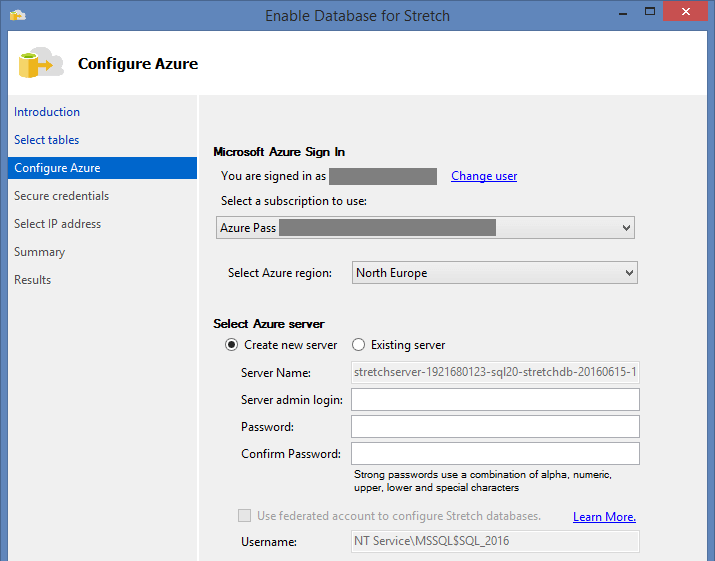
Next, we are prompted to log in and create SQL Server in Azure:
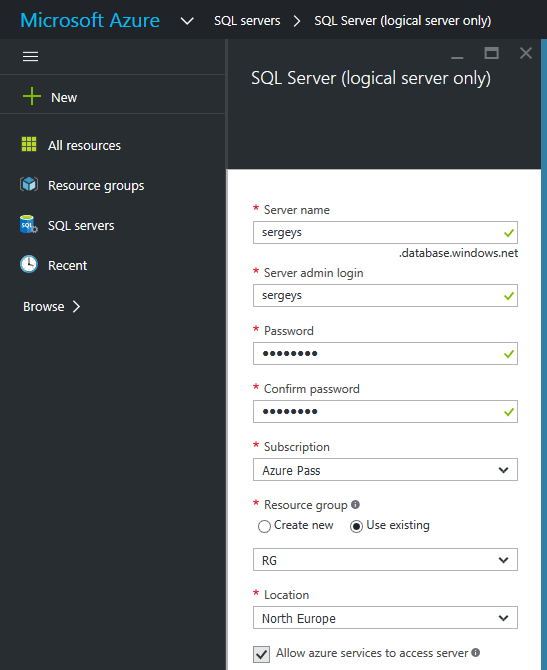
Let’s create SQL Server on Azure Portal manually:
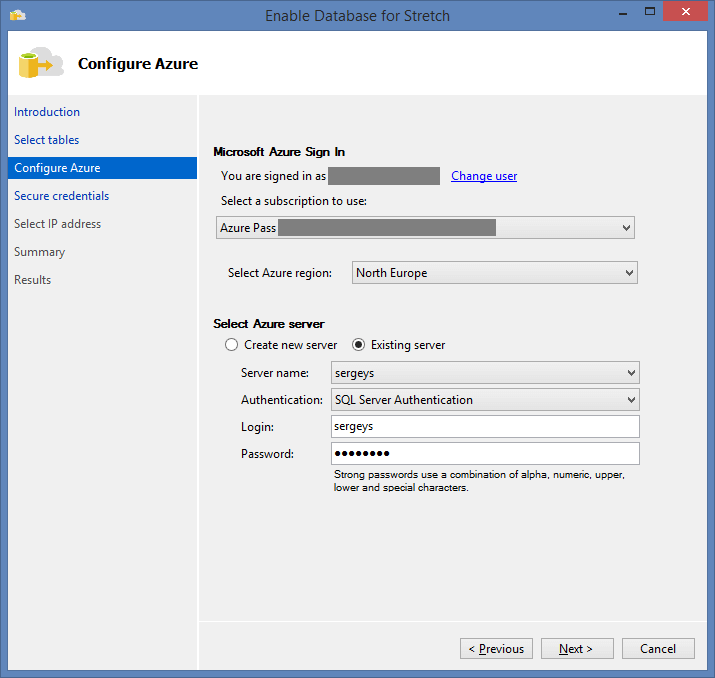
Then, we need to select the created server in the wizard:
Let’s set the master password, that we will need in the future:
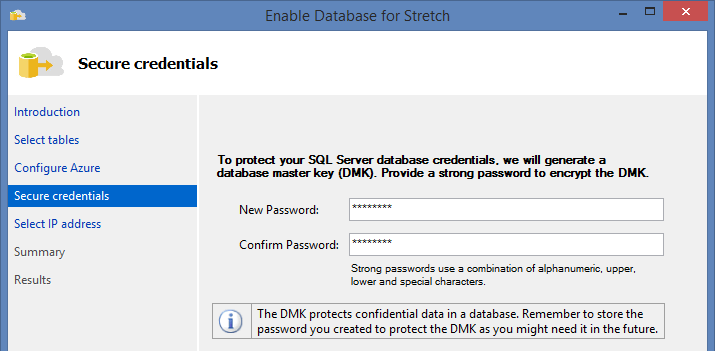
Specify the exceptions to be added to Firewall:
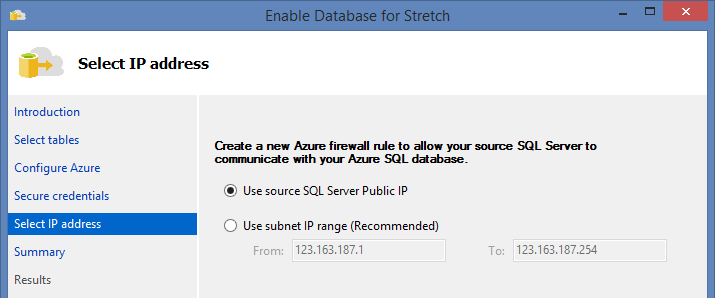
And here we are on the homestretch:
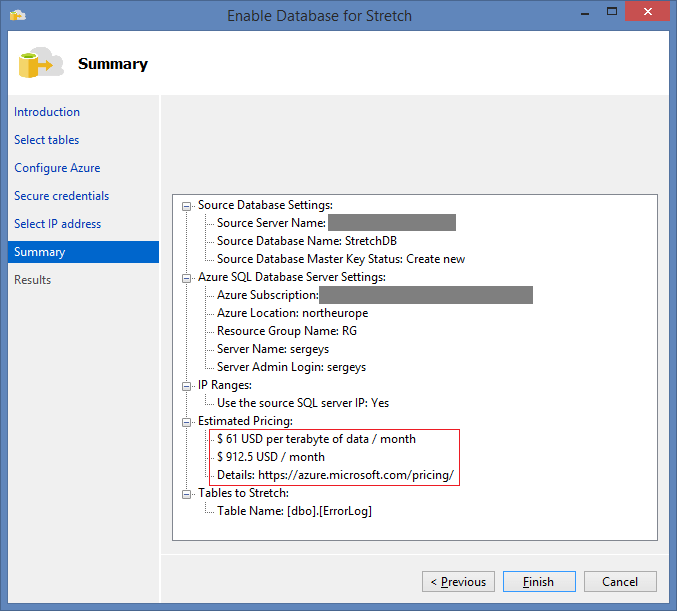
But during the setup, another exception is waiting, and again, it is not mentioned in the help:
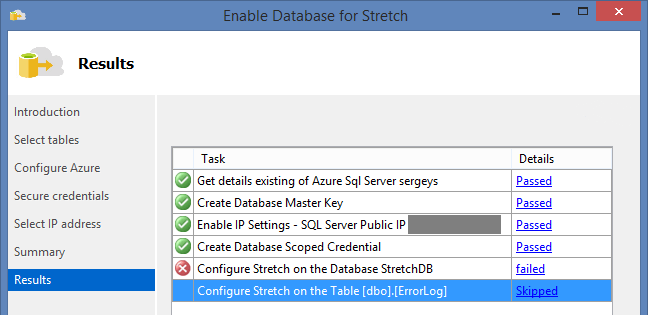
The log includes the following error: Configure Stretch on the Database StretchDB Status : 'Failed' Details : Task failed due to the following error: Alter failed for Database 'StretchDB': 'Cyrillic_General_CI_AS' is not a supported collation. ALTER DATABASE statement failed.
During database creation, I didn’t specify collation explicitly, and it turned out that Cyrillic_General_CI_AS is not supported in addition to many other things. During testing, it turned out, that Stretch Database won’t work if collation is used in the database properties:
1) any Windows collations (Latin1_General_100_CI_AS, …)
2) any AI and BIN collations
3) there are particular problems with CS collations
To make everything work consistently, it is better to use only SQL Server collations. I haven’t checked them all, but when I used SQL_Latin1_General_CP1_CI_AS, I didn’t have any troubles:
ALTER DATABASE StretchDB COLLATE SQL_Latin1_General_CP1_CI_AS
After the COLLATE modification for the database, I ran the wizard once more and voila:
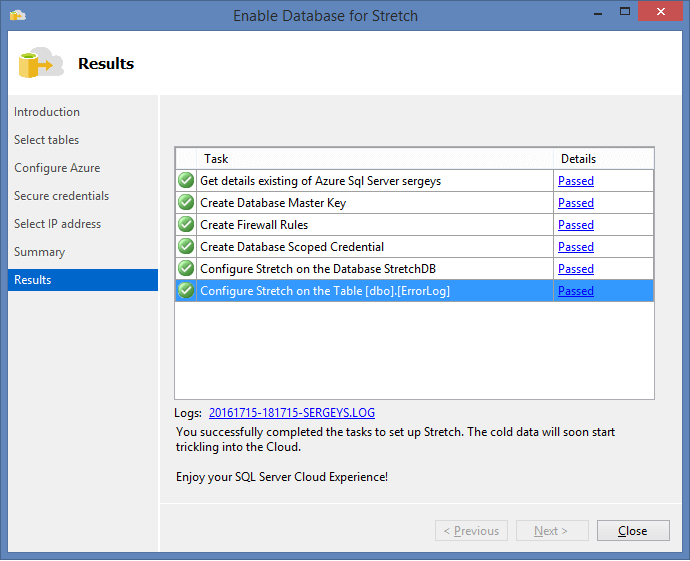
Now, let’s try to track how data is migrated to Azure through the monitor in SSMS 2016:
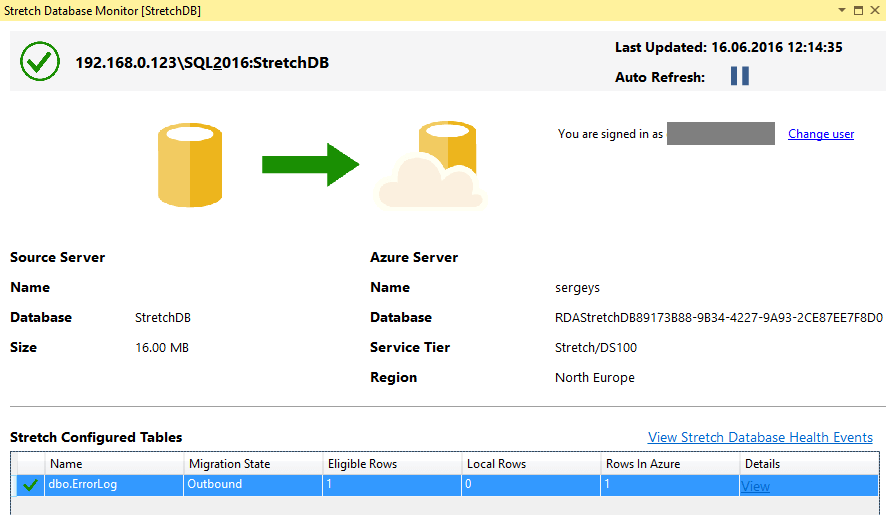
… or use a separated system view sys.dm_db_rda_migration_status:
SELECT *
FROM sys.dm_db_rda_migration_status
WHERE table_id = OBJECT_ID('dbo.ErrorLog')
AND database_id = DB_ID()
There was a bug in RC3, and if COLLATE of columns did not coincide with COLLATE of the database, sys.dm_db_rda_migration_status would grow without being cleared.
In our example, one of the columns has COLLATE that does not coincide with the one that is set in the database properties. That’s why data migration will fail from time to time by error:
table_id database_id migrated_rows start_time_utc end_time_utc error_number error_severity error_state ----------- ----------- -------------- -------------------- -------------------- ------------ -------------- ----------- 565577053 12 0 2016-06-15 15:44:41 2016-06-15 15:45:09 NULL NULL NULL 565577053 12 0 2016-06-15 15:45:16 2016-06-15 15:45:16 NULL NULL NULL 565577053 12 0 2016-06-15 15:45:16 2016-06-15 15:45:58 1205 13 55 565577053 12 0 2016-06-15 15:45:59 NULL NULL NULL NULL
But after several failed attempts it will be migrated successfully:
table_id database_id migrated_rows start_time_utc end_time_utc error_number error_severity error_state ----------- ----------- -------------- -------------------- -------------------- ------------ -------------- ----------- 565577053 12 0 2016-06-15 15:46:21 2016-06-15 15:46:21 NULL NULL NULL 565577053 12 1 2016-06-15 15:46:21 2016-06-15 15:46:27 NULL NULL NULL 565577053 12 0 2016-06-15 15:47:56 2016-06-15 15:47:56 NULL NULL NULL 565577053 12 0 2016-06-15 15:47:56 NULL NULL NULL NULL
Therefore, we may conclude that the bug has not been completely fixed. Therefore, it is highly recommended to set the same COLLATE for columns as for the database.
In this step, we tried one of the ways of creating a Stretch table. By the way, you can do it a way simpler and faster with the script:
USE StretchDB
GO
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'VasyaPupkin12'
GO
CREATE DATABASE SCOPED CREDENTIAL azure
WITH IDENTITY = N'server_name', SECRET = N'VasyaPupkin12'
GO
ALTER DATABASE StretchDB
SET REMOTE_DATA_ARCHIVE = ON (
SERVER = 'server_name.database.windows.net',
CREDENTIAL = azure
)
GO
ALTER TABLE dbo.ErrorLog
SET (REMOTE_DATA_ARCHIVE = ON (MIGRATION_STATE = OUTBOUND))
The main thing is to set permissions for our Azure Server before:
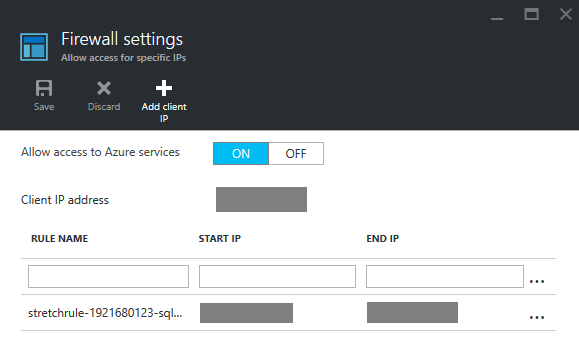
Now, let’s take a look at the changes in the table…
Whenever data comes to the table, it is physically stored on the local server for some time, and then it is migrated to Azure automatically. You can easily see it with help of the Live Query Statistic feature implemented in SSMS 2016:
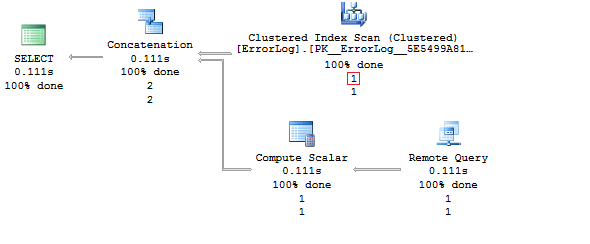
After 5-10 seconds:
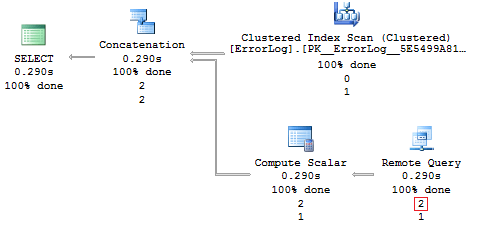
If we take a look at the execution plan, all functionality of Stretch Database is no longer a secret anymore: a linked server is created together with a separate component that migrates data to Azure.
We get the following limitations:
1) you can’t UPDATE or DELETE rows that have been migrated, or rows that are eligible for migration, in a Stretch-enabled table or in a view that includes Stretch-enabled tables
2) you can’t INSERT rows into a Stretch-enabled table on a linked server
That is, we can only insert data into a table:
INSERT INTO dbo.ErrorLog (PostTime, UserName, ErrorMessage) VALUES (GETDATE(), N'sergeys', N'Local row')
Because any DELETE, UPDATE, TRUNCATE operation results in the error:
Msg 14893, Level 16, State 1, Line 6 Table '...' cannot be a target of an update or delete statement because it has the REMOTE_DATA_ARCHIVE option enabled without a migration predicate.
Let’s try to create a Stretch table with the filter determining which data should be on the local machine, and which should be migrated to Azure:
ALTER TABLE dbo.ErrorLog
SET (REMOTE_DATA_ARCHIVE (MIGRATION_STATE = INBOUND))
Next, we create a function and a column that will store an attribute indicating that data can be migrated to cloud:
CREATE FUNCTION dbo.fn_stretchpredicate(@IsOld BIT)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT 1 AS is_eligible
WHERE @IsOld = 1
GO
ALTER TABLE dbo.ErrorLog ADD IsOld BIT
GO
During the secondary disposal of the table in cloud, we need to specify the following filter:
ALTER TABLE dbo.ErrorLog SET (
REMOTE_DATA_ARCHIVE = ON (
FILTER_PREDICATE = dbo.fn_stretchpredicate(IsOld),
MIGRATION_STATE = OUTBOUND
)
)
When the command work is over, let’s see the changes. Firstly, you can do anything you like with local data till the migration condition is not specified. You can delete, update it:
UPDATE dbo.ErrorLog SET IsOld = 0
And when we need to selectively migrate data to Azure:
UPDATE TOP(1) dbo.ErrorLog SET IsOld = 1
We need to remember this: what is already located in cloud cannot be returned with a simple UPDATE:
Msg 14875, Level 16, State 1, Line 14 DML operation failed because it would have affected one or more migrated (or migration-eligible) rows.
Let’s see how many space our data takes:
EXEC sys.sp_spaceused 'dbo.ErrorLog', @mode = 'LOCAL_ONLY' EXEC sys.sp_spaceused 'dbo.ErrorLog', @mode = 'REMOTE_ONLY'
name rows reserved data index_size unused -------------- ----- ---------- ------ ------------- -------- dbo.ErrorLog 1 72 KB 8 KB 8 KB 56 KB
name rows reserved data index_size unused -------------- ----- ---------- ------ ------------- -------- dbo.ErrorLog 1 144 KB 8 KB 24 KB 112 KB
Now, let’s try to use a filter in our queries in order to make a call to Stretch tables more effective:
SELECT * FROM dbo.ErrorLog WHERE IsOld = 0 SELECT * FROM dbo.ErrorLog WHERE IsOld = 1
If we look at the execution plan, in the first case we don’t need to make connection to the linked server which should work a way faster:
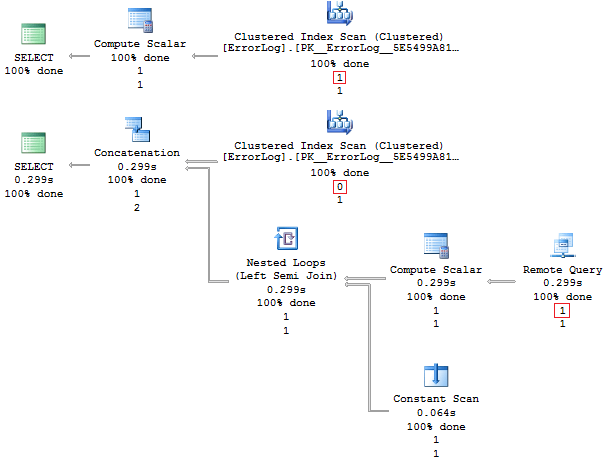
Did we really find a variant when the usage of Stretch Database would be feasible? In real life, everything is not that good, because both queries are both slow because of the bug:
Table 'ErrorLog'. Scan count 1, logical reads 2, physical reads 0, .... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1225 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms.
Table 'ErrorLog'. Scan count 1, logical reads 2, physical reads 0, .... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1104 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms.
At every call to the Stretch table, the connection to Azure takes place:

Because of such behavior, any queries with the Stretch table will freeze or fail because of time-out. The following limitations will seem ridiculous against the performance problems described above:
1) you can’t create an index for a view that includes Stretch tables
2) filtered indexes are not propagated to the remote table
Summary
As I wrote above, I tried to use Stretch Database for two projects. There was a large table with spans of work-time in TMetric time tracking app. Call to this table goes quite actively, that’s why Stretch Database simply could not do well because of its slow performance. The size of the table was treated in a simple way: all external keys were deleted and the table was recreated with the clustered COLUMNSTORE index (after all, the table was reduced by 12 times).
As for the inner project, a trick with sections switch came in handy, and I really liked to use it. The point is that two tables (A and B) are created. We work with table A actively, and then switch section to table B, which is a Stretch table:
DROP TABLE IF EXISTS A
GO
CREATE TABLE A (val INT PRIMARY KEY)
GO
INSERT INTO A SELECT 1
GO
DROP TABLE IF EXISTS B
GO
CREATE TABLE B (val INT PRIMARY KEY)
GO
ALTER TABLE B
SET (REMOTE_DATA_ARCHIVE = ON (MIGRATION_STATE = OUTBOUND))
GO
ALTER TABLE A SWITCH TO B
GO
SELECT * FROM A
SELECT * FROM B
In fact, we deal with the demarcation between historic and operative data, and as a result, we delicately sidestep the performance problem. This post covers all problems I faced for two-three months of working with Stretch Database. I do hope it will be useful for readers.