
Surrogate keys let software developers identify records uniquely in cases where it is impossible to use natural keys. However, what exactly is a surrogate key in SQL? What advantages and disadvantages does it bring? And, finally, how should you apply it? This article is going to explore all these questions.
Contents
- What is a surrogate key in SQL
- Surrogate keys vs. natural keys
- The pros and cons of the surrogate key
- The implementation of surrogate keys
- Conclusion
What is a surrogate key in SQL
A surrogate key is defined as a unique identifier for some record or object in a table. It is similar to a primary key, but with a significant difference: it is not derived from the table data – the object generates this key itself.
Next, the surrogate key does not have any business value or semantic meaning – it only serves for data analysis. It is not part of the application, and it is invisible to the user.
Briefly, we can define the following surrogate key characteristics:
- It holds a unique value for all records
- It is generated automatically
- It can’t be modified by the user or the application
- It can be used only in the CRUD (Create, Read, Update, Delete) operations
The most common format for the surrogate key is a sequential number that identifies a table row.
But why is the surrogate key used in SQL – is the primary key not enough?
There are cases (and it happens frequently) when it is impossible to use a unique primary key on the table. A simple example is a table with duplicate values in different columns.
For instance, we have a table containing information about books written by two authors who wrote some novels solo and co-authored other books.
| Author | Title | Year | ISBN | Publisher |
| Douglas Preston, Lincoln Child | Mount Dragon | 1996 | 0-7653-5996-0 | Tor Books |
| Douglas Preston, Lincoln Child | Thunderhead | 1999 | 0-446-60837-8 | Grand Central Publishing |
| Douglas Preston | Tyrannosaur Canyon | 2005 | 0-7653-1104-6 | Forge Books |
| Douglas Preston | Impact | 2010 | 978-0-7653-1768-1 | Forge Books |
To identify a row uniquely, we need a key based on the unique combination of the novel’s title and the writers’ names (it can have one author or two co-authors). The surrogate key will be the solution.
Surrogate keys also help us resolve more issues, such as the following ones:
- To apply primary keys to data collected from various sources
- To maintain primary keys for a longer time
- To preserve the primary key value under different conditions
The surrogate key in SQL acts as the primary key when the primary key is not applicable. Ideally, every table row should have both the primary and surrogate keys: the primary key identifies a row in the database, and the surrogate key identifies a separate entity.
Surrogate key vs. natural key
You can use both the natural and surrogate keys in databases. To apply them correctly, we’ll define them and understand how they differ.
As we already know, a surrogate key is an automatically generated unique identifier that does not have any business or contextual meaning. In the below table, you can see a separate column containing these identifiers:
| Author | Title | Year | ISBN | Publisher | |
| 1 | Douglas Preston, Lincoln Child | Mount Dragon | 1996 | 0-7653-5996-0 | Tor Books |
| 2 | Douglas Preston | Tyrannosaur Canyon | 2005 | 0-7653-1104-6 | Forge Books |
| 3 | Douglas Preston | Impact | 2010 | 978-0-7653-1768-1 | Forge Books |
A natural key is a key that has a contextual or business meaning. It relates to one or several columns already existing in the particular table.
One more difference between a surrogate key and a natural key is that a natural key needs to be created manually, whether partially or completely.
Every published book has an International Standard Book Number (ISBN) – a unique identifier of the specific publication. It is a prime example of a natural key.
| Author | Title | Year | ISBN | Publisher |
| Douglas Preston, Lincoln Child | Mount Dragon | 1996 | 0-7653-5996-0 | Tor Books |
| Douglas Preston | Tyrannosaur Canyon | 2005 | 0-7653-1104-6 | Forge Books |
| Douglas Preston | Impact | 2010 | 978-0-7653-1768-1 | Forge Books |
It is worth noticing more differences between the surrogate and natural keys:
| Surrogate key | Natural key |
| Can’t be used as a search key | Can be used as a search key |
| Is always unique | Can include duplicate values |
| Applies uniform rules to all records | Does not apply uniform rules for each record |
| Does not change with time | Can be changed according to requirements |
| Requires an additional column in a table | Does not require an additional column (already exists) |
Some business scenarios require you to combine natural and surrogate keys. For instance, you can use the surrogate key as a primary key, while the natural key will serve as a foreign key. It won’t affect user experience.
The pros and cons of the surrogate key
Database specialists like surrogate keys for many reasons. Still, they aren’t a panacea, and you need to consider both pros and cons to see whether you need them in your particular case.
The advantages of using surrogate keys
- Uniqueness. We have mentioned this parameter several times, but it is worth stressing that a surrogate key is always unique. Thus, if you migrate data, you can be sure there won’t be any duplicate keys – the system will generate new, unique keys for your inserted data.
- Unlimited number. As the most common SQL surrogate key formats are sequential numbers of random strings, the system can generate any number of such unique values and combinations.
- Consistency. It is another crucial factor we stressed earlier. Natural keys can change because of changes in data or business requirements, but surrogate keys never change. It is always the same reference to the particular table row. Thus, if you use the surrogate key as a primary key, you can be sure it will be stable.
- Less code. As the surrogate key is always the same, you can reuse it whenever needed. Besides, the surrogate key consists most frequently of integers, which makes it more compact. When used in an SQL JOIN clause, the surrogate key makes the query less expensive.
- Better performance. Surrogate keys are smaller than natural keys. The key consistency allows easier table integration and handling. Queries are faster, and operations require less disk IO – the usage of surrogate keys is a decent query optimization technique.
Pro tip: Looking for more ways to optimize SQL queries? Perform deep analysis of query execution plans and find bottlenecks in them using the tips and workarounds of performance tuning.
The disadvantages of using surrogate keys
- A surrogate key requires an extra column in a table. Therefore, the system consumes extra disk space and IO to store and handle surrogate keys. You will also need an additional index for the surrogate key column.
- Surrogate keys violate normalization (the third normal form) as the surrogate key value has no relation to the actual table data.
- For the same reason, surrogate keys require more table JOINs in a query.
- Surrogate keys may complicate the distinction between the test and production data. As surrogate keys are values generated automatically without meaningful references, one may not tell test data from actual business data easily.
- Finally, surrogate keys require a specific implementation technique for every particular DBMS.
Many work scenarios suggest using surrogate keys. However, every case is different. Even experienced developers should consider and evaluate all options to pick the most suitable one.
However, it won’t demand in-depth SQL knowledge to implement a surrogate key.
The implementation of surrogate keys
If the work scenario recommends using a surrogate key in a table, there are several ways to do it. Let’s review the most popular implementation techniques and illustrate our examples using dbForge Studio for SQL Server – a popular IDE for SQL Server database developers and administrators.
This multi-featured solution provides an all-embracing toolset to perform all database-related tasks effectively, an intuitive GUI to speed up and simplify these tasks, and the possibility to automate routine operations and save lots of time. In particular, the Studio allows you to accelerate code writing tremendously with a set of features like auto-completion, code formatting, and instant syntax check.
Auto-incremented keys
An auto-incremented key is created when the system inserts a new record into a table. It generates a unique value (most often, a numerical value) automatically. In SQL Server, this option is possible due to the presence of the IDENTITY column.
Have a look at the example:
-- Creates a table named Employee.
-- Id will have surrogate values that are auto-numbered.
CREATE TABLE [dbo].[Employee](
[Id] [int] IDENTITY(1,1) PRIMARY KEY,
[Name] [varchar](15) NULL,
[SSN] [varchar](11) NULL,
[Email] [varchar](25) NULL,
);
GO
-- Inserts three rows into the Employee table.
INSERT INTO [dbo].[Employee] VALUES ('Oliver', '123-45-6789', '[email protected]');
INSERT INTO [dbo].[Employee] VALUES ('Matthew','223-45-6789', '[email protected]');
INSERT INTO [dbo].[Employee] VALUES ('Sophie', '323-45-6789', '[email protected]');
GO
-- Displays the Employee data.
SELECT * FROM [dbo].[Employee];
GO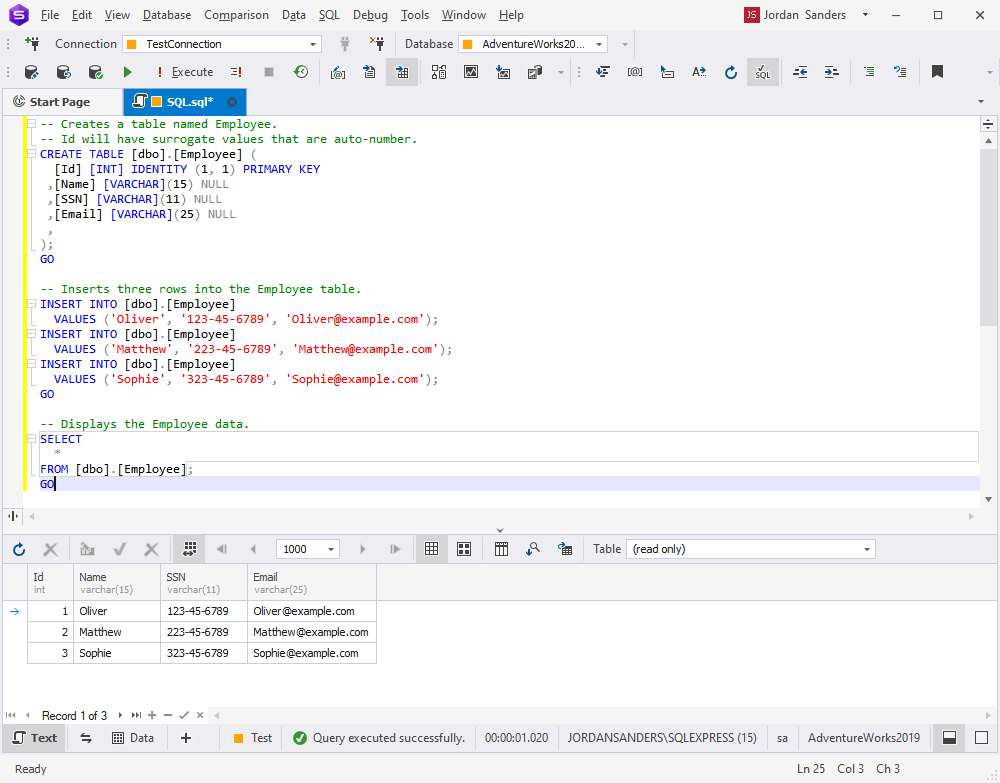
Here you can see the surrogate key column.
Create surrogate keys with Globally Unique Identifiers
The Globally Unique Identifier (GUID) is a Microsoft standard. In SQL Server, GUIDs have a size of 16 bytes. The data type is binary. These values must be unique across all databases and servers.
See the example below:
-- Creates a table named Employee.
-- Id will have surrogate values that are represented by random GUIDs.
CREATE TABLE [dbo].[Employee](
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[Name] [varchar](15) NULL,
[SSN] [varchar](11) NULL,
[Email] [varchar](25) NULL,
);
GO
-- Inserts three rows into the Employee table.
INSERT INTO [dbo].[Employee] VALUES (NEWID(), 'Oliver', '123-45-6789', '[email protected]');
INSERT INTO [dbo].[Employee] VALUES (NEWID(), 'Matthew','223-45-6789', '[email protected]');
INSERT INTO [dbo].[Employee] VALUES (NEWID(), 'Sophie', '323-45-6789', '[email protected]');
GO
-- Displays the Employee data.
SELECT * FROM [dbo].[Employee];
GO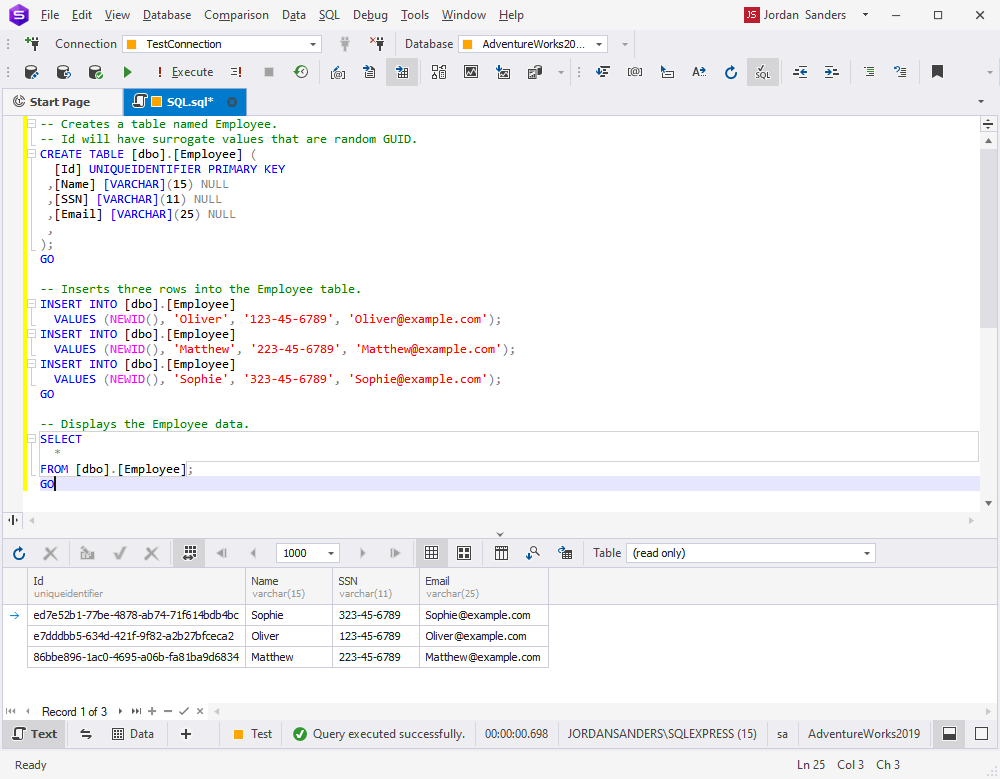
The surrogate keys in this table are random GUIDs.
Struggling with SQL code? Use an advanced SQL Editor functionaily within dbForge Studio for SQL Server for smart code completion and error-free workflow.
Create surrogate keys via column hashing
It is possible to create surrogate keys using the hashing method. The hashed value of several database fields produces a unique constraint. It is essential to hash all involved fields together to create a unique surrogate key for each row.
-- Creates a table named Employee.
-- Id will have surrogate values that are generated by a hash of three columns.
CREATE TABLE [dbo].[Employee](
[Id] AS CONVERT(UNIQUEIDENTIFIER, HashBytes('MD5', CONCAT([Name],[SSN],[Email]))) PERSISTED PRIMARY KEY,
[Name] [varchar](15) NULL,
[SSN] [varchar](11) NULL,
[Email] [varchar](25) NULL,
);
GO
-- Inserts three rows into the Employee table.
INSERT INTO [dbo].[Employee] VALUES ('Oliver', '123-45-6789', '[email protected]');
INSERT INTO [dbo].[Employee] VALUES ('Matthew','223-45-6789', '[email protected]');
INSERT INTO [dbo].[Employee] VALUES ('Sophie', '323-45-6789', '[email protected]');
GO
-- Displays the Employee data.
SELECT * FROM [dbo].[Employee];
GO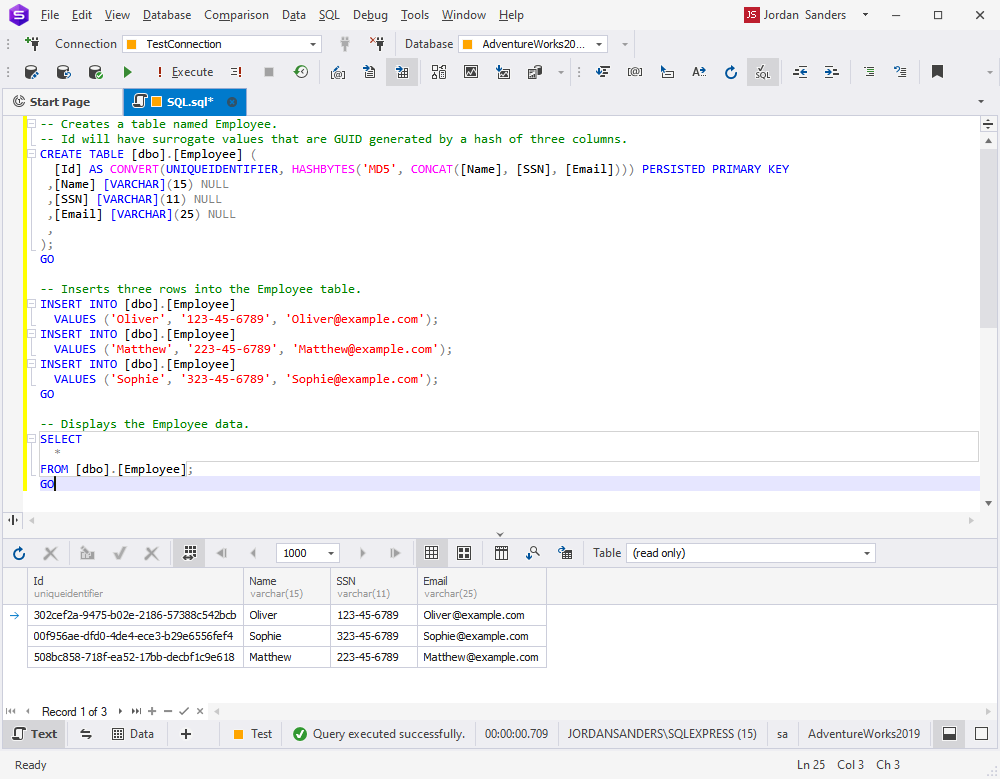
The table has a surrogate key column with hashed values (each hash includes three columns).
Conclusion
A surrogate key is one of the most convenient and secure options for identifying database entities. It creates relationships between tables without affecting any existing data or rules and allows us to detect and explore data easily and quickly.
If your table does not have a natural key, you should create a surrogate key. Besides, many scenarios suggest using both natural and surrogate keys – and you might need both in your table as well. And the creation of surrogate keys is not a complicated task in any case.
Last but not least, work with keys becomes considerably simpler with professional tools, such as dbForge Studio for SQL Server that we used in our article. Get it for a 30-day free trial and check the most advanced SQL Server development and management functionality in action.