
The article deals with the basics of versioning SQL Server databases and goes into the basics of working with the Git version control system.
Table of Contents
What is a version control system?
If you don’t use version control software, you might have lots of files named like final or latest on PC. There can even be something like final_upd_3.
Or, what if you want to disable some product functionality in the future? Then, you write comments to the code to prevent its deletion.
Source code is a highly valuable asset for projects. It must be well-protected. It is version control that protects it from human mistakes and other accidents.
The software developers who work in teams write new source code and change existing code continuously. The project code is usually organized in folders or the directory tree. One team member might work on new functionality, and another developer might fix errors by modifying the code. Both can make amendments to the directory tree parts.
But what if your changes are incompatible with the changes of another developer who is working simultaneously with you? The problem must be detected and resolved without blocking the rest of the team.
Teams that don’t use any version control software may often face the following issues:
- No history of changes.
- Incompatible changes (conflicting changes).
A version control software helps to resolve and eliminating such issues.
Version control system (VCS) is a category of software tools that help developers manage changes to source code. Version control systems track each code modification in a special database. Should an error occur, the devs can compare the previous code version with the current one and quickly fix the issue.
Version control systems are an integral part of software product development. If developers got used to working with such systems, they would know for sure that version control systems are necessary even in small individual projects.
VCS tools architecture types
VCS tools come in two primary types of architecture:
- Centralized
- Distributed
The key difference between the two is the backup capability.
Centralized model
The centralized model has one point of failure, which is the remote central VCS copy. If you lose this copy, you may lose the data, and the productivity of the entire system will decrease.
In this case, you need to replace the main copy with another one. If the main copy is temporarily unavailable, it will prevent the developers from resetting or rolling back the code.
Examples of such systems are SVN and CVS.
Distributed model
The distributed model allows you to avoid these risks by keeping a full source code copy in each VCS copy. If a single point of failure occurs in a distributed model, you can replace the damaged VCS copy with any other copy. The productivity won’t decrease in this case.
Examples of such systems are Git and Mercurial
Git system
Git is a free open-source version control system created by Linus Torvalds in 2005. It is the most widely-used VCS and the world standard of software development.
Git is a distributed source control system and it does not depend on one central server storing files. Instead, it works locally and saves the data in folders on a PC hard drive. These folders are called a repository. This feature distinguishes Git version control from old SVN and CVS systems.
Still, you can save a copy of a repository online. It simplifies work on one project by several people. Sites like GitHub and BitBucket are helpful in this case.
The specificity of a repository
Specific features of the repository are as follows:
- You have access to all files in a local repository, no matter if you work on one file or several ones.
- You can view the public repository without logging in, provided that you have an URL of that repository.
- Each repository belongs to a user or a team account. When the repository is attached to a user account, that user is the repository owner. When it is attached to a team account, the team owns the repository.
- The owner of a repository is the only person that can delete it. When a repository belongs to a team, the dedicated administrator can delete it.
- The project code can consist of several repositories stored under several accounts. Alternatively, it can be the only storage under one account.
The Git system designation
When you need to accelerate the product development process, you gather a large development team. This team further gets divided into several minor groups. Each group is responsible for some product feature or part of the work.
When you develop new functionality, it is common to work with the original project copy. This copy is called a branch.
Each branch has its history. All branches are isolated until you decide to merge them using a pull request:
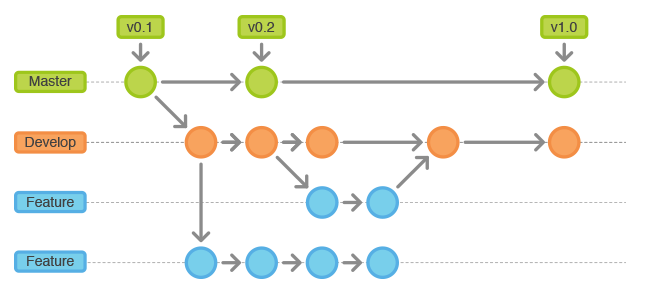
You need to work with the git VCs branches for the following reasons:
- You need to save a stable code version.
- Developers work on new functionality concurrently.
- There is no risk of getting changes in your code part enforced by changes made by other peoples.
- You can implement the same idea in different ways and compare the results.
Five primary branch types are defined:
- master – the stable version matching the production
- develop – a primary branch for development
- hotfix – a branch where you develop error fixes for production
- release – a branch for release (the build comes from it)
- features – a branch for a new feature development
The primary Git vcs operations are:
- Clone – copy a remote repository from the cloud to your local system
- Add or stage – make changes and add them into your history
- Commit – add new or modified files in the repository
- Pull – fetch new changes from the cloud to your local repository
- Push – upload changes from the local system to the remote repository
Working with Git
Configure
The system configurations are stored in /etc/gitconfig:
$ git config --system
Specific user settings are stored in ~/.gitconfig:
$ git config --global
Repository local configuration files are stored in .git/config:
$ git config --local (default)
The lower “levels” (global, local) overwrite values in the previous level.
In Windows OS, the path to global config is the following:
%USERPROFILE%\.gitconfig
Reference
Get the reference:
$ git help <command>
$ git <command> --help
$ man git-<command>
Create and clone a repository
Create a repository:
$ git init
Clone an existing repository:
$ git clone https://github.com/jobgemws/JobEmplDB.git
Supported protocols:
https://, git:// or SSH: user@server:path/to/repo.git
File Status Lifecycle in Git
Suppose you have a live Git-repository and an active copy of some project files. You need to make changes and take snapshots of those changes whenever your project achieves a certain state you want to save.
Important: Each file in your Git folder can be sorted into one of two categories:
- Tracked – the file is under version control.
- Untracked – the file exists locally, but isn’t a part of the Git repository.
Tracked files are files that were in the last snapshot of the project. These files can be unmodified, modified, or staged. In brief, the tracked files are those files that the Git version control is aware of.
Untracked files are all the rest – any files in a working directory that did not get into the last snapshot and are not staged. When you clone your repository for the first time, all your files will be tracked and unmodified. Git has just checked them out, and you haven’t edited anything yet.
As soon as you edit files, Git will consider them as modified because you’ve changed them since the last commit. You stage these modified files. Then you commit those staged changes. Then the cycle repeats.
The statuses of files in a repository:
- Untracked is the file that doesn’t exist in a repository
- Modified is a changed file
- Staged is a file prepared for a commit
- Committed is an indexed file
- Unmodified is an unchanged file
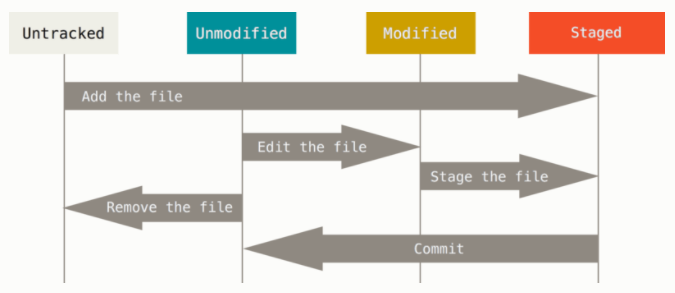
Check the status of files in a working directory:
$ git status
Start tracking the file:
$ git add <filename>
Index changes:
$ git add <filename>
Show changes between commits, commit and working tree, etc.:
$ git diff
Showing staged changes:
$ git diff --staged
Recording changes to the repository:
$ git commit
Committing all the tracked files:
$ git commit –a
Adding a message to commit:
$ git commit -m 'Add description to my project'
Combine operations:
$ git commit –a -m ‘Add description to my project’
Show commit logs:
$ git log
Options:
--stat — show the stats for each commit
--graph — build the text graph
--decorate — show HEADs
--all — show all branches
Limit Log Output:
--author
--grep
--all-match (filter commits by author and keywords simultaneously)
Delete files:
$ git rm Filename (deletes a file from the hard drive and removes it from the tracked files)
If the file was modified and indexed, you need to add the -f parameter:
$ git rm -f Filename
Move files:
$ git mv README.md README
It is the same as
$ git rm README.md
$ git add README
As a result:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: README.md -> README
Git branching models
There are different branching models, each with its purposes. For now, we distinguish the three most actual and popular branching models:
- Git flow
- GitHub flow
- Gitlab flow
Note: The branching models work only if you follow the scheme carefully.
The basic principles of popular branching models are as follows:
- Any significant change must be made in a separate branch.
- The current version of the main branch is always correct. The project builds made at any moment from the current version must be successful.
- Tags mark the project versions. A version separated and marked by a tag will never change.
- Any working, test, or demo versions of the project are built from the system repository only.
Refer to Comparing Workflows for more details.
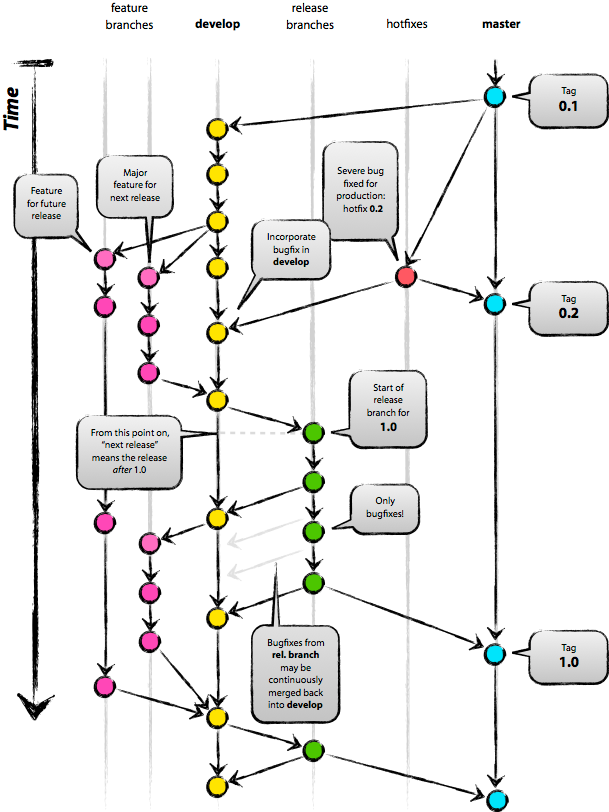
Git Flow branching model
This model is a practical implementation of the main software development principles in VCS concerning software release cycles. It suits both Scrum and Waterfall.
Key principles
There are two primary branches:
- Master is a current stable version working in the production environment
- Develop is the main development branch.
Additional branches:
- feature branches are used to develop new functionality or fix non-critical bugs. Feature branches must merge into the developed branch.
- release branches are made for release preparation and stabilization (feature-freeze). Release branches must merge into master and develop.
- hotfix branches are used for critical bug fixing. Hotfix branches must merge into master and develop.
The branches must be merged through pull requests only.
Advantages
- You can fix and stabilize the release functionality before it gets to production.
- It is possible to deploy nightly builds.
Disadvantages
- It is not the simplest workflow.
- It requires an in-depth understanding of which branch the current branch was created from, and where it is merged into.
- The ready functionality gets to production with some delay.
Refer to A successful Git branching model for more information.
GitHub Flow branching model
GitHub Flow implements the main software development principles in VCS without considering the software release cycles. It suits the Kanban approach.
Main principles
- There is one main branch – master, which contains a current stable version of the project.
- Subsidiary feature and hotfix branches are created from master. They merge back into it through pull requests.
- Merges should be made via pull requests only.
Advantages
- The ready functionality does not wait for releases – it comes to production immediately.
- It is a simple and transparent working scheme for developers.
Disadvantages
- It requires extra-precise development and maintenance culture.
- It requires maximum automation of the code testing and deployment processes.
Refer to Understanding the GitHub flow and GitHub Flow for more info.
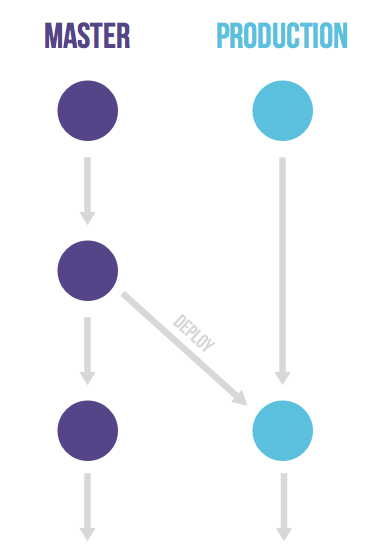
Gitlab Flow branching model
Gitlab Flow is a kind of Git Flow and GitHub Flow symbiosis. It is as simple as GitHub Flow, but it also allows release control, similar to Git Flow.
Main principles
- The main master branch contains a current stable version of the project.
- Additional feature or hotfix branches are created from master. They merge into it via pull requests.
- A stable production branch serves for automated deployment to production. You move code from master to production when it comes time to release it.
- It is possible to use additional branches for different environments.
- Merges should be made via pull requests only.
Advantages
- A simple and transparent working scheme for developers.
- A ready functionality can be shipped to production immediately.
Disadvantages
- It requires extra-precise development and maintenance culture.
- It requires maximum automation of the code testing and deployment processes.
Refer to GitLab Flow for more details.
Merge Requests (Pull Requests)
Merge Request (Pull Request) is a version control system mechanism allowing you to introduce changes from some branch as a request to merge them into the master (on any other) repository branch.
Pull requests allow you to:
- show the description of any modification to all project stakeholders;
- perform code review and leave comments before merging changes into the target branch;
- disallow merging until fulfilling all the required conditions (for instance, collect a certain number of approvals from the code review participants);
- get a successful CI build;
- avoid critical comments in the results of automatic static analysis.
Tags
Git allows tagging particular points in history as being important. As a rule, tags are used to mark release points (1.0, etc.)
- A lightweight tag is a simple pointer to a specific commit.
- An annotated tag is stored in the Git database as a full object. Such tags have checksums, the date of creation, the creator name, and email. They can be verified and signed with a digital signature.
View all tags:
$ git tag
Filter the tags:
$ git tag -l '1.3.*'
Create lightweight tags
To create a lightweight tag, don’t supply arguments to a tag, except for the tag name:
$ git tag 1.0-lw
This will create a tag for the current commit:
$ git show 1.0-lw
If you need to tag another commit from history, specify the hash for that commit after the tag name:
$ git tag v1.0 7abc02
$ git tag
Create annotated tags
To create an annotated tag, you need to specify -a when you run the tag command:
$ git tag -a 1.0 -m 'my version 1.0'
$ git tag
The -m specifies a tagging message. It will be stored together with a tag.
To see the tag data, use:
$ git show 1.0
Share tags
Push a particular tag:
$ git push origin [tag name]
Push all tags:
$ git push origin --tags
To get all tags, execute git pull.
Working with a remote repository
View remote repositories
To view the list of remote repositories connected to your local repository, you need to execute git remote. If that list is not empty (for instance, you’ve cloned your repository from the network), you’ll get all your remotes as a result of running:
$ git remote
You can specify -v, to view the URLs assigned to be used when reading and writing to that remote:
$ git remote -v
Get the details on the remote repository:
$ git remote show [remote-name]
Adding, renaming, and deleting records
Add:
$ git remote add [shortname] [url]:
Now, you can use [shortname] instead of the whole URL:
$ git fetch [shortname]
Rename:
$ git remote rename [shortname_old] [shortname_new]
Delete:
$ git remote rm [shortname]
Fetching and pushing changes
Fetch changes from the remote repository:
$ git fetch [remote-name]
git fetch receives the list of changes from a remote repository and the changes themselves, without merging to yours.
git pull receives changes from a remote branch and merges them into your current branch.
Pushing changes to the remote repository:
$ git push [remote-name] [branch-name]
If anyone modified the remote repository since the last commit, it will reject PUSH. First, you’ll have to fetch their work and incorporate it into yours before you’ll be allowed to push.
Favoring a visual interface over writing complex commands? Check the list of the clients that provide best Git GUI for Windows to strengthen your toolset!
Conclusion
In the first part of the article, we have reviewed the basics of versioning SQL Server databases and went into the basics of working with the Git version control system.
Note: The Source Control tool supports various types of source control systems, including Working Folder, Git, SVN, and Mercurial.
