")
The 17.5 version of SQL Server Management Studio (SSMS) brought with it a new built-in security tool. Since then, the Data Discovery and Classification feature has become a difference-maker in the protection of sensitive information.
Equipped with a set of advanced services, it allows us to discover, classify, and label sensitive data in the database and serves as an infrastructure for meeting regulatory compliance requirements (such as GDPR, HIPAA, PCI, etc.). In this article, we are going to review the main functionality of the SQL Server data classification tool and see an easy and quick solution to sensitive data management in SQL Complete from Devart.
To begin with, sensitive information refers to personal, organizational, or any type of confidential data that requires a higher level of protection. The vast majority of people have their personal information spread over a variety of organizations and industries, including:
- Protected health information (PHI), such as medical records, payment history for healthcare services, insurance information.
- Educational information, such as enrollment records and transcripts.
- Financial information, such as credit card numbers, banking information, tax forms, and credit reports.
As one would expect, exposure of sensitive data can potentially cause financial or personal harm and entail negative consequences. Therefore, with large amounts of sensitive data being produced and exchanged every moment, it’s imperative that businesses take proper measures to protect highly sensitive data.
SQL Data Discovery and Classification in SSMS
First things first, we need to know the type of data we store in a database. This will help us classify data based on the regulations as well as meet the data privacy standards. The new built-in tool within SQL Server Management Studio (SSMS) can help us to discover the data within the database.
The classification procedure goes as follows: the engine first scans through the columns and detects the columns that might contain sensitive data (the search is conducted based on T-SQL parsing of the column names). After that, you can review the columns and apply fitting classification recommendations.
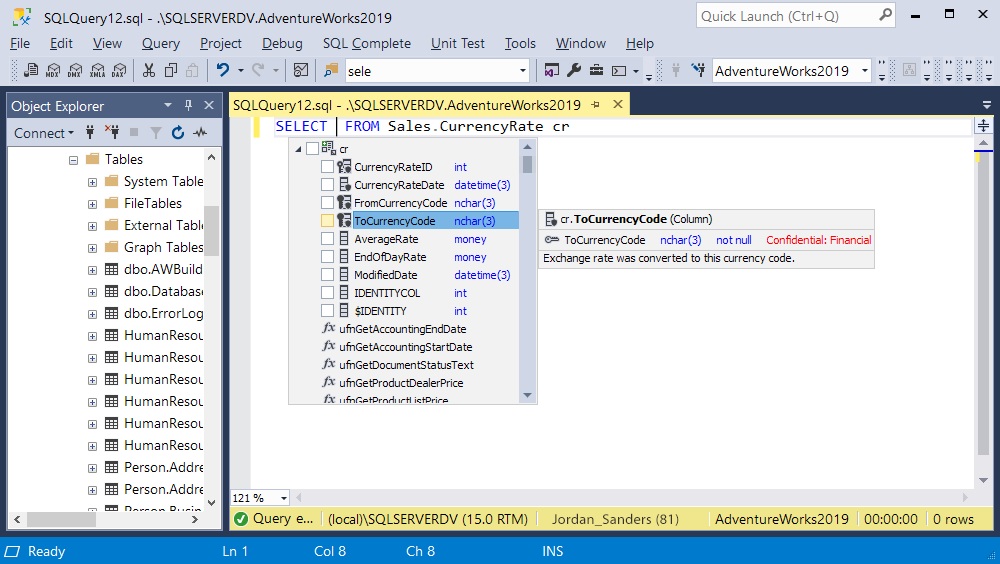
The extended properties enable you to specify the label and the information type of sensitive data. The Information Type may be one of the following: Networking, Contact Info, Credentials, Credit Card, Banking, Financial, Other, Name, National ID, SSN, Health, Date of Birth, and [n/a]. As for Sensitivity Label, it shows the level of data sensitivity with the following options: Public, General, Confidential, Confidential – GDPR, Highly Confidential, Highly Confidential – GDPR, and [n/a].
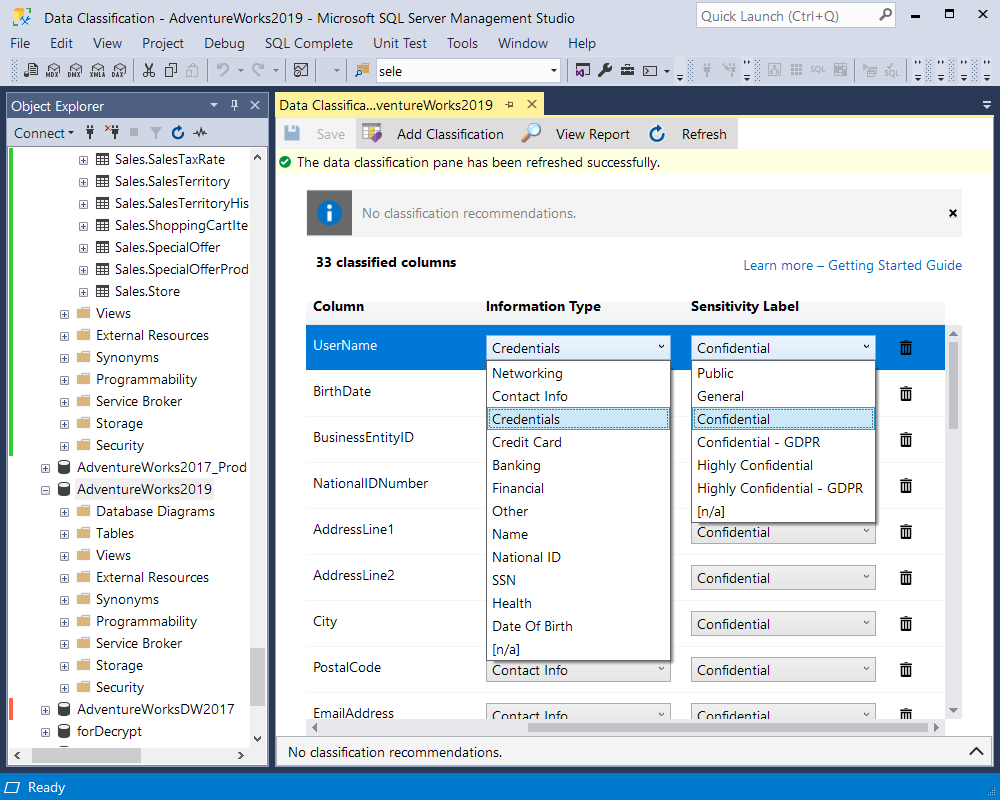
It is worth mentioning that the feature mainly supports English and only partially some other non-English languages like German, French, Spanish, Portuguese, and Italian.
Applying SQL Data Discovery and Classification
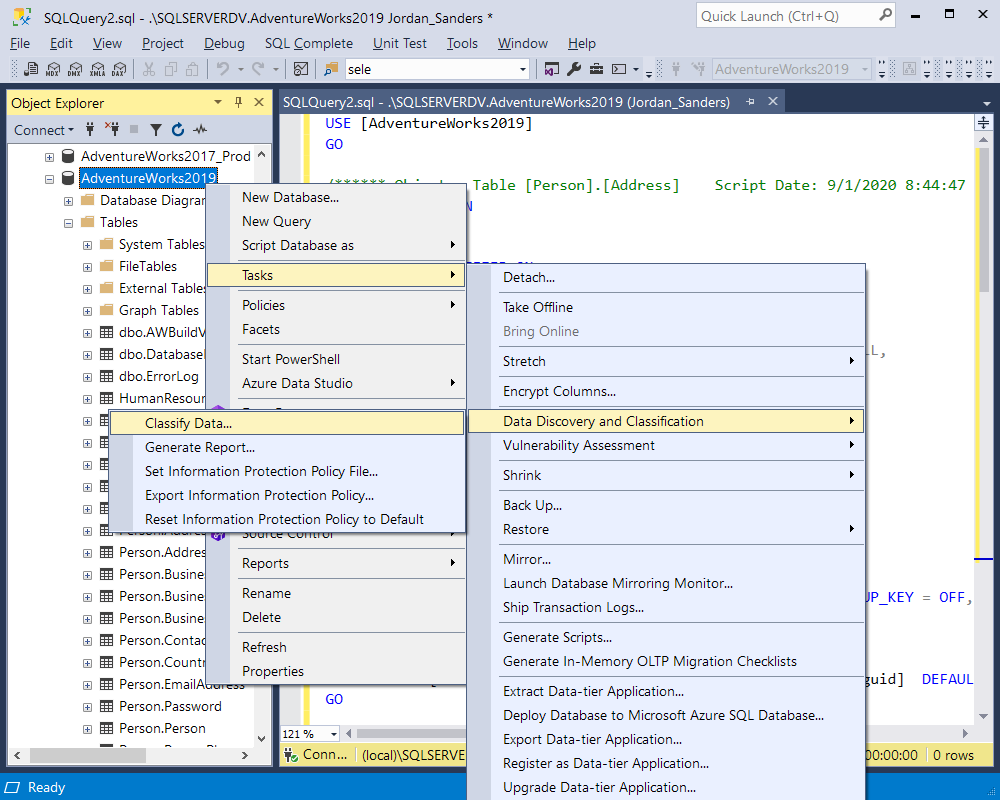
Having received some theoretical background, we are ready to come over to practice. The Data Discovery and Classification tool is pretty easy to use and doesn’t normally pose any difficulties. Simply open the required database in SSMS, go to Tasks -> Data Discovery and Classification -> Classify Data, as shown below:
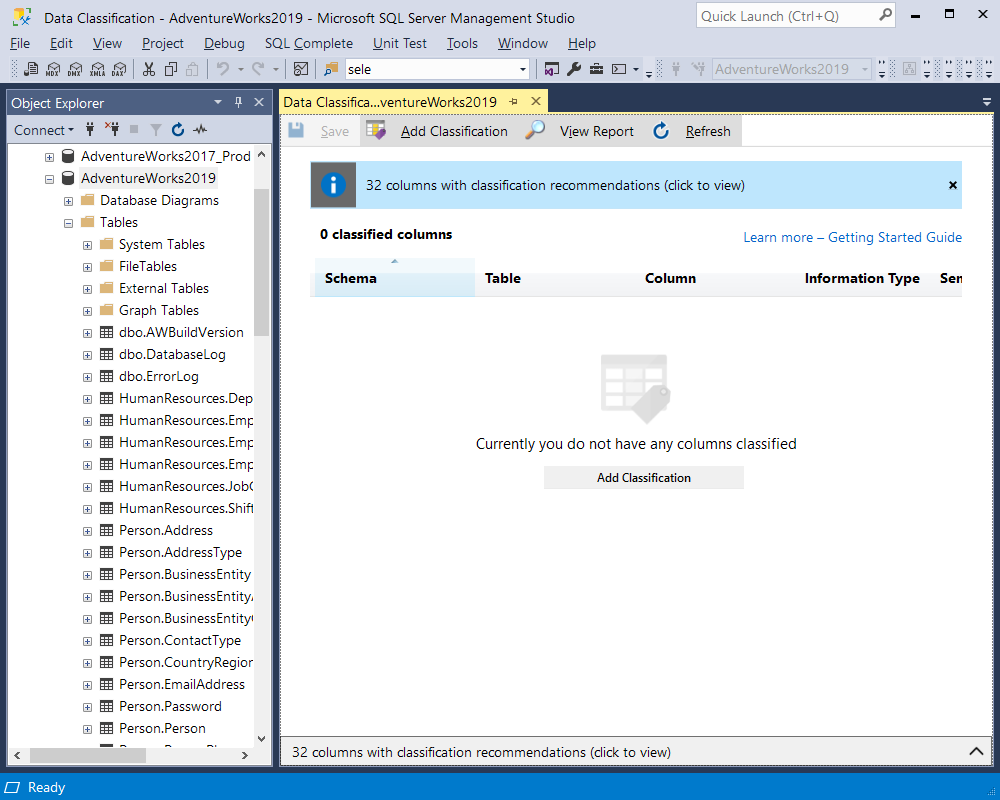
Running the ‘Classify Data’ command, we obtain the classification report. In the report, we can see classification recommendations as there are no classified columns yet.
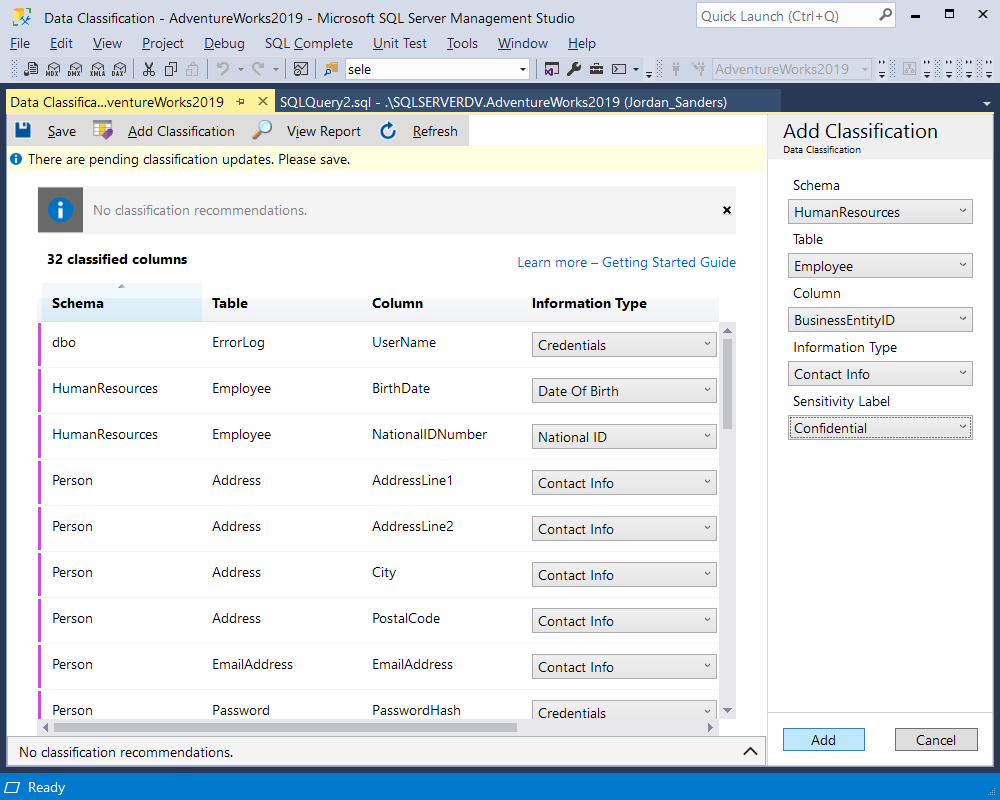
Clicking ‘Add Classification’, we can now set the options of data sensitivity with the customizable columns represented through the information type and sensitivity label or accept recommendations.
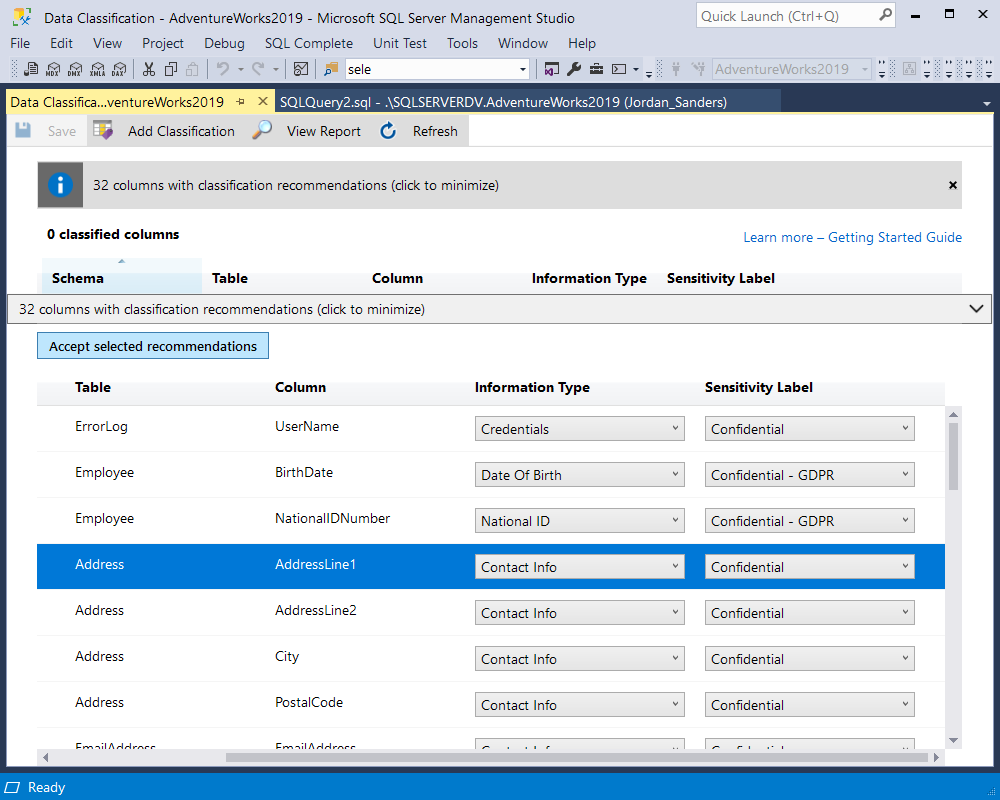
After having selected the appropriate sensitivity options, you can apply and save them. You can now see the classified columns, just as shown below:
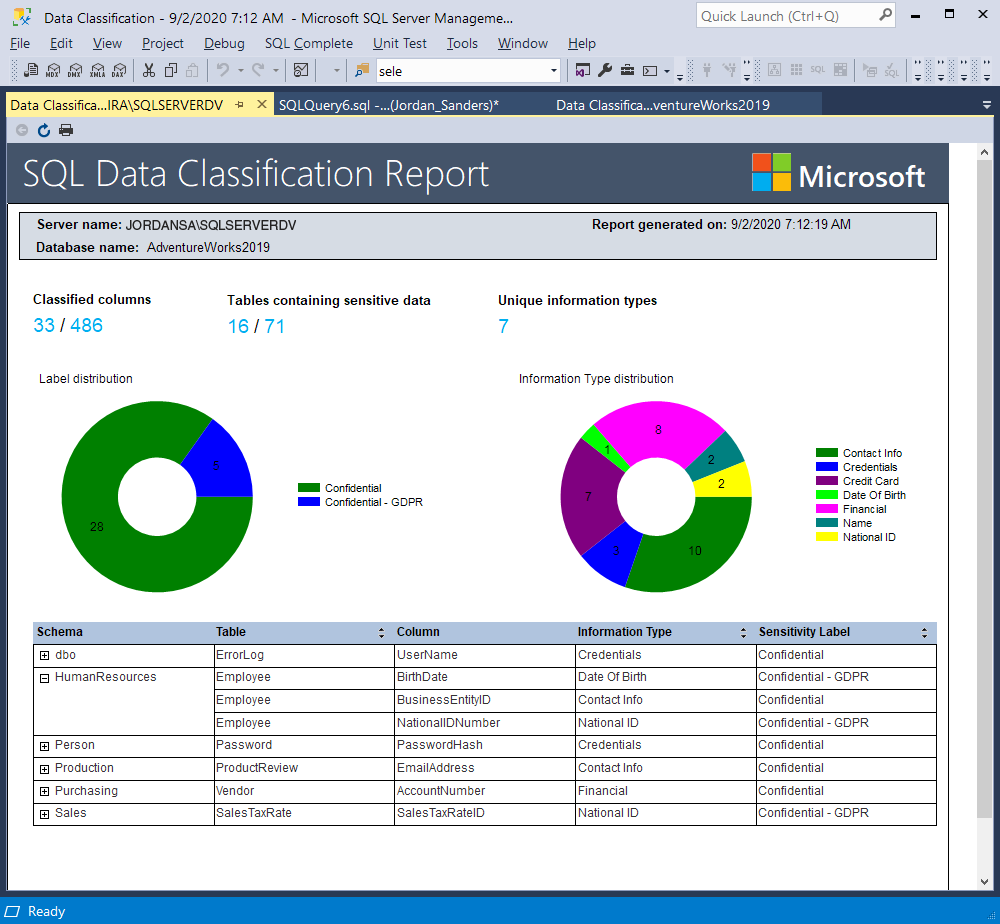
Following this, you can view the SQL Data Classification Report. It reveals the classification information with the help of pie charts and tables as follows:
ADD SENSITIVITY CLASSIFICATION SQL Server 2019
We cannot but mention the fact that SQL Server 2019 introduced a new command that is very much similar to the function of SSMS Data Discovery and Classification. ADD SENSITIVITY CLASSIFICATION command also allows defining the information type and label for sensitive data stored in a database.
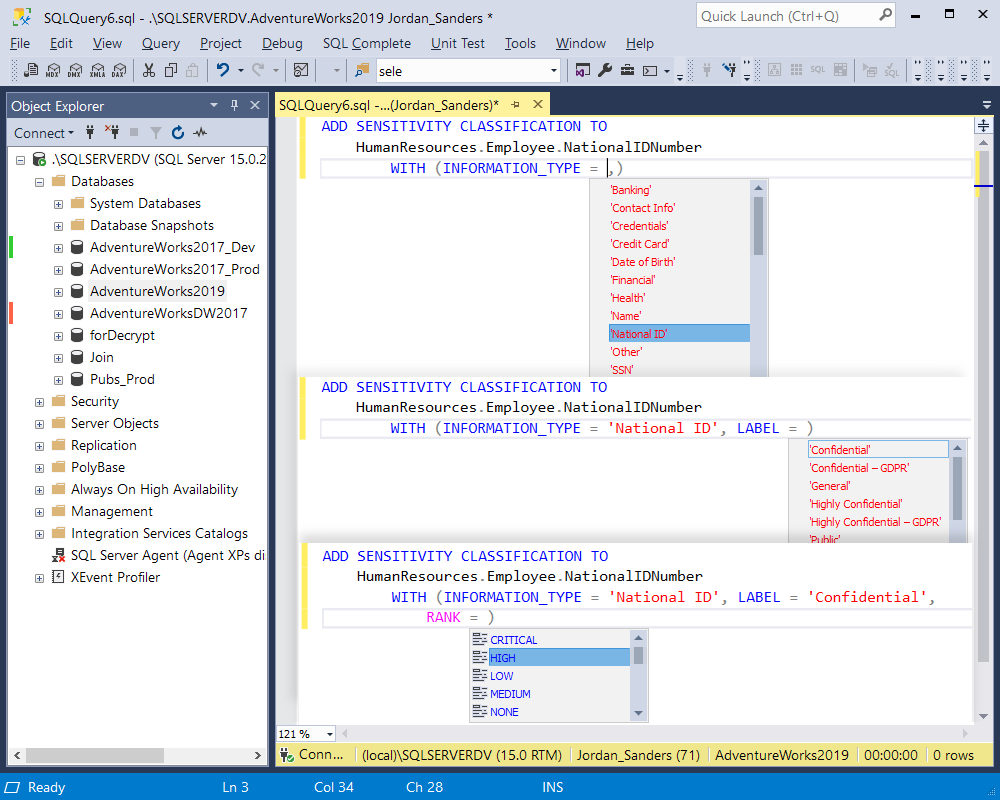
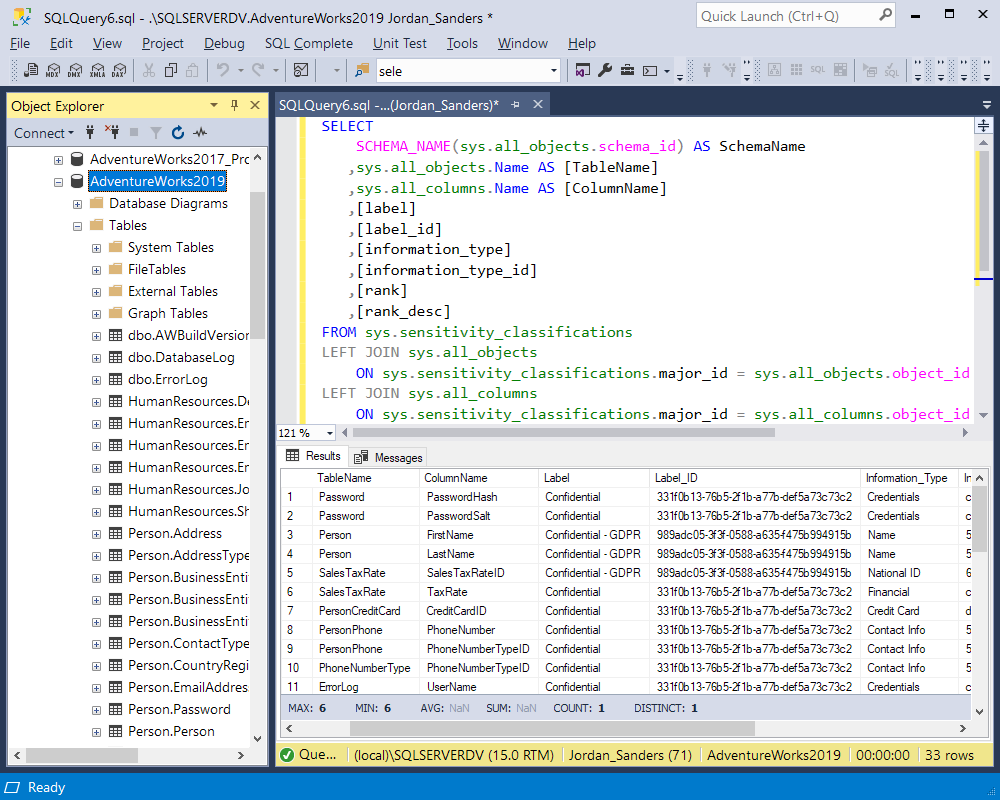
But there are a couple of differences between these two. Firstly, unlike SQL Data Discovery and Classification, the command allows defining the same label and information type for multiple columns with a single statement, which is very beneficial and time-saving. Secondly, SQL Server 2019 does not store the classification information as extended properties, instead, it adds metadata about the sensitivity classification to one or more database columns. By using the system view sys.sensitivity_classifications, we can view the information about the classified columns.
To learn more about the new useful command ADD SENSITIVITY CLASSIFICATION, refer to this article. Devart is also excited to present the new SQL Complete v6.6, an excellent solution for SQL database development, management, and administration, which now supports the ADD SENSITIVITY CLASSIFICATION command. What’s more, quick and comprehensive prompts by SQL Complete 6.6 essentially facilitate SQL data classification. Find out more about the improvements of new SQL Complete v6.6.
Summary
To conclude, we would like to say that data classification has become an integral part of safeguarding data, and with new features implemented by Microsoft, we can go one step forward in protecting our sensitive data against theft, loss, and misuse as well as ensuring compliance with regulatory standards.
