
Storing data in databases inherently requires regular updates. This process involves adding new data and replacing outdated information. While numerous challenges are associated with updating data in databases, this article will concentrate on a specific aspect: optimization of the data updating process. We will explore the UPSERT option, which effectively combines the SQL UPDATE and INSERT statements and the application of the SQL UPSERT operation in MySQL databases.
- What is UPSERT in MySQL?
- Methods of implementing UPSERT in MySQL
- MySQL UPSERT performance comparison
- Choosing the right UPSERT method for your use case
- Common mistakes and best practices for UPSERT in MySQL
- How dbForge Studio simplifies UPSERT operations
- MySQL UPSERT using INSERT IGNORE
- MySQL UPSERT using REPLACE
- MySQL UPSERT using INSERT ON DUPLICATE KEY UPDATE
- UPSERT in MariaDB
- Conclusion
What is UPSERT in MySQL?
The UPSERT feature in SQL is a hybrid of the UPDATE and INSERT statements. It enables merging the functionality of updating existing data and adding new records. When a record is already in the database, UPSERT triggers an UPDATE to modify it. If the record doesn’t exist, UPSERT performs an INSERT, adding a new record. This operation is atomic and completed in a single step.
How do atomicity, transactions, and concurrency impact UPSERT operations? They make a single upsert run all-or-nothing, lock the target key so conflicting upserts serialize, and require a transaction when several upserts must succeed or fail together. In InnoDB, an upsert is statement-atomic (insert or, on PRIMARY/UNIQUE conflict, the specified update; nothing partial is committed). During the statement, MySQL takes row-level locks on the target key; operations on different keys can proceed in parallel. If you need multiple upserts treated as a unit, wrap them in a short transaction (START TRANSACTION … COMMIT/ROLLBACK) to control commit/rollback and limit contention.
SQL programmers often use UPSERT to prevent duplicating records while updating databases. This is especially useful in scenarios like data migration or importing data from external sources, where duplicates might occur. For example, UPSERT adds new customers while updating existing ones with new information. This simplifies the process, eliminating the need for complex statements with IF clauses in stored procedures.
While UPSERT is an essential feature in relational database management systems, it’s not universally available as a distinct command. Oracle supports a direct UPSERT command, but MySQL doesn’t. However, MySQL and MariaDB offer UPSERT-like functionality through specific variations of the INSERT statement, which will be discussed later in this article.
Methods of implementing UPSERT in MySQL
Choose the method by which you resolve key conflicts (skip, replace, or update) and by the write overhead you can accept. Here is a quick reference table.
| Method | Conflict behavior | Updates the existing row | Deletes row | Relative performance | Best for | Pitfalls/notes |
|---|---|---|---|---|---|---|
| INSERT IGNORE | Skips duplicate-key rows; leaves existing data unchanged | No | No | Fast on bulk loads | Idempotent bulk loads with expected duplicates | Can hide data issues; still pays a unique-index probe per row |
| REPLACE | Deletes the conflicting row, then inserts the new row | Yes (via delete+insert) | Yes | Slowest; highest write amplification | True full-row replacement | Fires DELETE/INSERT triggers, may cascade FKs, bumps AUTO_INCREMENT; unspecified columns reset to defaults |
| INSERT … ON DUPLICATE KEY UPDATE | Updates the existing row in place; inserts otherwise | Yes | No | Moderate to fast; balanced | Selective updates without deleting data | On MySQL 8.0.20+, replace VALUES(col) with a row alias (VALUES(…) AS new, then use new.col); avoid no-op updates |
How to choose:
- Skip duplicates: use
INSERT IGNORE. - Replace entire row: use
REPLACE. - Update specific columns: use
INSERT … ON DUPLICATE KEY UPDATE.
Next, we will delve into each of these methods in more detail.
MySQL UPSERT performance comparison
When choosing between INSERT IGNORE, REPLACE, and INSERT … ON DUPLICATE KEY UPDATE, performance can vary significantly depending on the size of the dataset, indexing, and frequency of duplicate records. Understanding these differences helps avoid unnecessary overhead.
Benchmark scenarios
To illustrate the differences, here’s a test setup:
- Table size: 1M rows, unique index on
customer_id - Workload: 100k inserts, ~20% duplicates
- Engine: MySQL 8.0 (InnoDB), single transaction
| Method | Execution time (s) | Est. Row writes | CPU/memory impact | Notes |
|---|---|---|---|---|
| INSERT IGNORE | ~3.5–4.0 | ~80k inserts | Low | Skips 20k duplicates, minimal overhead |
| REPLACE | ~9.0–10.0 | ~120k (100k inserts + 20k deletes) | High | Double index maintenance, triggers cascade |
| ON DUPLICATE KEY UPDATE | ~4.5–5.0 | ~100k (80k inserts + 20k updates) | Moderate | Efficient conflict resolution |
Note: These figures are illustrative (controlled workload, single host). Real results vary depending on the schema, indexes, triggers, and hardware.
Index and constraint interaction
Index effects differ by method:
- INSERT IGNORE: Checks indexes but skips on conflict. Fast on indexed tables, but can mask duplicate data issues.
REPLACE: Deletes then reinserts, causing double index maintenance and possible trigger/foreign key side effects.
ON DUPLICATE KEY UPDATE: Uses the unique/primary key index to detect conflicts and update rows in place, minimizing write amplification.
Key takeaways
In practice, the choice comes down to this:
- INSERT IGNORE for fast bulk loads where duplicates don’t need changes.
- REPLACE only when you need an entire row replacement and can handle deletes.
- ON DUPLICATE KEY UPDATE for targeted updates without overwriting existing rows.
Choosing the right UPSERT method for your use case
Pick based on how you want to resolve key conflicts and your write overhead tolerance.
When to use INSERT IGNORE
INSERT IGNORE skips duplicate-key rows and leaves existing data untouched.
Use for:
- High-volume bulk loads with expected duplicates.
- Pipelines where the current row is authoritative and must not change.
Avoid if:
- You need to modify existing rows.
- Silent skips could hide data quality issues.
Gotchas:
- Ignore collisions; they won’t be recorded unless you capture warnings or row counts.
- Pay unique index checks for every row, which adds overhead.
Example
INSERT IGNORE INTO t (id, name, email) VALUES (?,?,?),(?,?,?); When to use REPLACE
REPLACE resolves conflicts by deleting the old row and inserting the new one.
Use for:
- Full-row replacement is required (incoming data should overwrite everything).
- Deleting the old row is acceptable (including side effects).
Avoid if
- You have foreign keys, triggers/audit trails that you don’t want to fire twice.
- You only need to change a subset of columns.
Gotchas:
- Does a DELETE then INSERT: double index maintenance, bumps
AUTO_INCREMENT, may cascade. - It has the highest write amplification of the three.
Example
REPLACE INTO t (id, name, email) VALUES (?,?,?); When to use INSERT … ON DUPLICATE KEY UPDATE (ODKU)
INSERT … ON DUPLICATE KEY UPDATE detects key conflicts and updates columns in place.
Use for:
- Selective updates while preserving existing rows.
- Balanced performance when duplicates are common.
Avoid if:
- You actually need all columns replaced (then REPLACE is simpler, though more costly).
- Your UPDATE clause doesn’t change values (wasted writes).
Gotchas:
- On MySQL 8.0.20+,
VALUES(col)is removed. Use a row alias fromVALUES(...) AS newand referencenew.col. - Update only columns that have changed to minimize writes and row logging.
Example (8.0.20+)
INSERT INTO t (id, name, email)
VALUES (?,?,?) AS new
ON DUPLICATE KEY UPDATE
name = new.name,
email = new.email; Common mistakes and best practices for UPSERT in MySQL
Small choices in UPSERT logic can lead to silent data issues or excessive write overhead. Let’s explore them.
Ignoring warnings with INSERT IGNORE
Mistake: Using INSERT IGNORE to “keep going” on bulk loads, then missing real problems (duplicate keys, truncation, invalid dates coerced to defaults).
How to fix it:
- Log collisions: check
ROW_COUNT()andSHOW WARNINGS;after batches; persist counts to a load log.
Run in STRICT mode (STRICT_TRANS_TABLES) for staging loads; only useIGNOREto skip known dupes.
Quarantine first: load into a staging table; surface dupes viaLEFT JOIN/NOT EXISTS; promote only clean rows.
Validate keys early: enforceUNIQUE/PRIMARY KEYin staging to fail fast on unexpected collisions.
Safer pattern
-- Staging -> target (explicitly show what will be skipped)
INSERT INTO target (id, c1, c2)
SELECT s.id, s.c1, s.c2
FROM staging s
LEFT JOIN target t ON t.id = s.id
WHERE t.id IS NULL; REPLACE and unintended row deletions
Mistake: Assuming REPLACE updates a row. It deletes the old row and inserts a new one. Side effects: fired DELETE/INSERT triggers, FK cascades, new AUTO_INCREMENT, defaults applied to unspecified columns.
How to fix it:
- Use
REPLACEonly when you truly need full-row replacement. - List all columns in
REPLACEto prevent defaults on omitted fields. - Check triggers, FKs, and audit trails for delete+insert side effects.
- Prefer ODKU when only a few columns need to be changed.
Safer alternative
-- Avoid losing data + side effects
INSERT INTO t (id, c1, c2) VALUES (?,?,?) AS new
ON DUPLICATE KEY UPDATE
c1 = new.c1,
c2 = new.c2; ODKU updates that don’t actually change values
Mistake: ON DUPLICATE KEY UPDATE clauses that set columns to the same values, causing lock/redo overhead and noisy “updated rows” counters.
How to fix it:
- Update only when changed: gate assignments with comparisons to avoid no-op writes.
- MySQL 8.0.20+: don’t use
VALUES(col)—alias the incoming row and reference it. - Detect insert vs update when needed (e.g., metrics) with the
LAST_INSERT_ID()trick.
Safer patterns (8.0.20+)
-- Only update when different (per column)
INSERT INTO t (id, c1, c2) VALUES (?,?,?) AS new
ON DUPLICATE KEY UPDATE
c1 = IF(t.c1 <> new.c1, new.c1, t.c1),
c2 = IF(t.c2 <> new.c2, new.c2, t.c2);
-- Insert vs update signal
INSERT INTO t (id, c1) VALUES (?,?) AS new
ON DUPLICATE KEY UPDATE
id = LAST_INSERT_ID(t.id), -- preserves id, signals "update"
c1 = new.c1;
/* then read LAST_INSERT_ID(): inserted -> new id, updated -> existing id */ Best-practice checklist
Here is a recap:
- Decide intent first: skip (IGNORE), replace (REPLACE), or update (ODKU). Don’t mix.
- Minimize writes: prefer ODKU with per-column change checks when updates are common.
- Control side effects: avoid
REPLACEwhere FKs/triggers/audits matter. - Surface errors: don’t rely on
IGNOREfor data quality; log warnings and counts. - Use modern syntax: on 8.0.20+, alias
VALUES(...) AS newand referencenew.col.
How dbForge Studio simplifies UPSERT operations
dbForge Studio for MySQL streamlines UPSERT queries by offering intellisense-style suggestions for the INSERT … ON DUPLICATE KEY UPDATE syntax in the SQL Editor. This ensures you can compose valid statements quickly without recalling every clause from memory. Let’s take a closer look.
Author safe ODKU in SQL Editor
Use this when you hand-craft UPSERT logic and want complete control with a transaction.
Workflow:
- Open a new script, start a transaction, write ODKU with a row alias (MySQL 8.0.20+).
- Run, review
ROW_COUNT()/warnings, then commit.
START TRANSACTION;
INSERT INTO new_customer (customer_id, store_id, first_name, last_name, email, active, last_update)
VALUES (?,?,?,?,?,?,NOW()) AS incoming
ON DUPLICATE KEY UPDATE
first_name = incoming.first_name,
last_name = incoming.last_name,
email = incoming.email,
active = incoming.active,
last_update = incoming.last_update;
-- Optional checks:
-- SELECT ROW_COUNT() AS affected, @@warning_count AS warnings;
-- SHOW WARNINGS;
COMMIT; File-to-table UPSERT via staging (data import)
Use this for CSV/Excel/JSON feeds you promote safely to the target.
Workflow:
- Import file into a staging table; match the key and add a UNIQUE/PK.
- Validate types/NULLs; then promote with ODKU; archive or truncate staging.
-- Staging has a PK on customer_id
INSERT INTO target (customer_id, store_id, first_name, last_name, email, active, last_update)
SELECT s.customer_id, s.store_id, s.first_name, s.last_name, s.email, s.active, NOW()
FROM staging s AS incoming
ON DUPLICATE KEY UPDATE
first_name = incoming.first_name,
last_name = incoming.last_name,
email = incoming.email,
active = incoming.active,
last_update = NOW(); Table-to-table UPSERT (data compare/sync)
Use this to synchronize the source with the target, featuring previewable insert/update scripts.
Workflow:
- Run Data Compare, review diff grid (Inserted/Updated).
- Generate a Sync Script, execute it in a transaction, and export it for CI/CD.
Safety and observability
Utilize built-ins that minimize risk and surface issues promptly.
What you get:
- Run scripts inside transactions for safe rollback.
- Preview of generated SQL before execution.
- Warnings surfaced (key collisions, truncations, coerced dates).
- Profiles to reuse import/compare settings.
MySQL UPSERT using INSERT IGNORE
INSERT IGNORE is a modification of the MySQL INSERT command designed to handle situations where duplicate entries could occur in a unique primary key or index. Unlike the standard INSERT command, which would result in an error and halt the process, INSERT IGNORE proceeds with the insertion process without throwing an error or stopping. Instead, it simply skips the duplicate record and continues inserting new records.
This variant is useful in scenarios involving bulk insert operations. In such cases, the data may include records that violate uniqueness constraints.
INSERT IGNORE serves to prevent the entire operation from being interrupted. Instead of throwing an error, it will issue a warning and continue with the data update process. However, it’s essential to use this option with caution, as ignoring mistakes can sometimes lead to unexpected results or data inconsistencies.
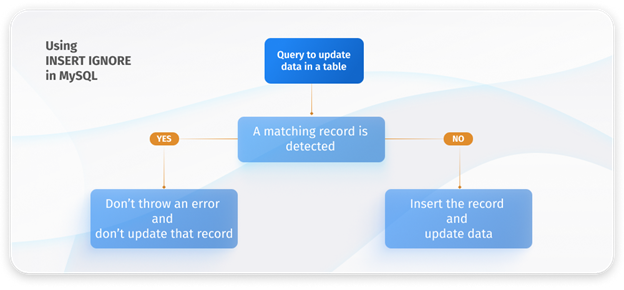
The syntax of the INSERT IGNORE statement in MySQL is as follows.
INSERT IGNORE INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Parameters:
- table_name – the name of the table into which data is inserted.
- column1, column2, … – the list of columns in the table where we insert data
- VALUES (value1, value2, …) – the values that should be inserted into the corresponding columns. The number of values must match the number of columns.
Let’s have a look at the example. We will showcase our examples using dbForge Studio for MySQL. This IDE is a robust and flexible tool for MySQL and MariaDB with comprehensive SQL coding support. It comes equipped with a variety of features, including code auto-completion, syntax validation, code debugging, formatting, refactoring, a code snippets library, and much more. With dbForge Studio for MySQL, you can efficiently handle all aspects of database development, management, and administration.
Assume that we want to insert new customers into the corresponding table of the Sakila test database.
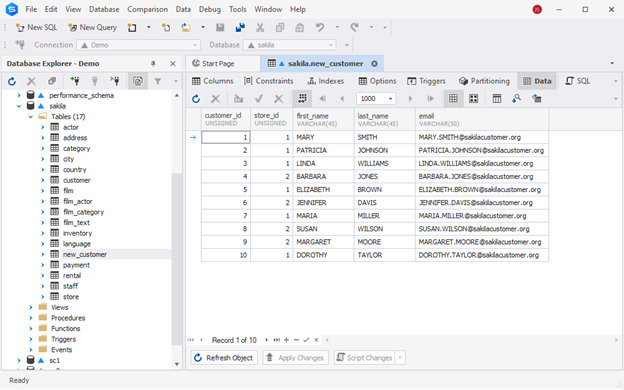
We execute the following SQL query.
INSERT IGNORE INTO
sakila.new_customer (customer_id, store_id, first_name, last_name, email)
VALUES
(8, 2, 'Susan', 'Wilson', '[email protected]'),
(16, 1, 'Jane', 'Harrison', '[email protected]'),
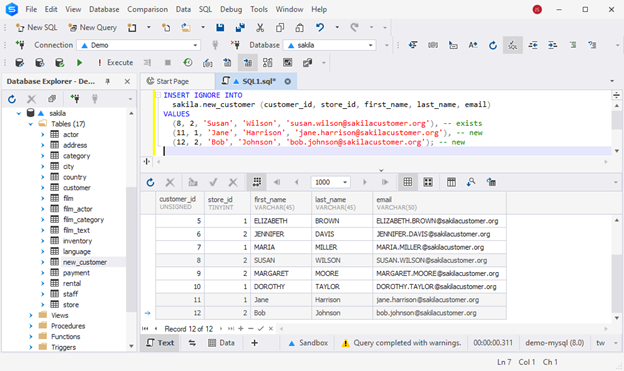
(17, 2, 'Bob', 'Johnson', '[email protected]'); The first record with customer_id 8 already exists in the table. Other records with unique customer_id values are new entries. The query will attempt to insert all records, but the first record already exists in the table. By using INSERT IGNORE, we instruct the system to ignore that record and continue inserting new records. As you can see, it only added two new records. Also, the dbForge Studio for MySQL notified us about warnings.
MySQL UPSERT using REPLACE
Frequently, when updating data, we need to update existing records. Using the standard INSERT command can lead to an error, specifically the “Duplicate entry for PRIMARY KEY” error. To address this problem, we can employ the REPLACE command.
When there are no duplicate records or primary key conflicts, REPLACE acts like an INSERT. However, if there are duplicate records, REPLACE first deletes the existing record and then proceeds with the INSERT operation for that particular row.
In essence, the MySQL REPLACE command effectively combines the functionalities of both DELETE and INSERT.
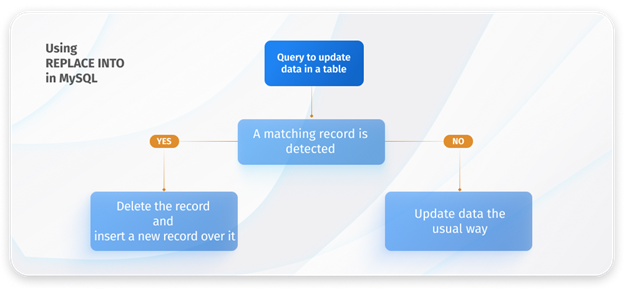
The syntax of the REPLACE statement in MySQL is as follows.
REPLACE INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...); Note that REPLACE is typically used when we have a PRIMARY KEY or UNIQUE constraint on one or more columns, as it relies on these constraints to determine if a record already exists.
Have a look at the example below. We are updating the list of customers by adding some new entries and altering some of the existing records.
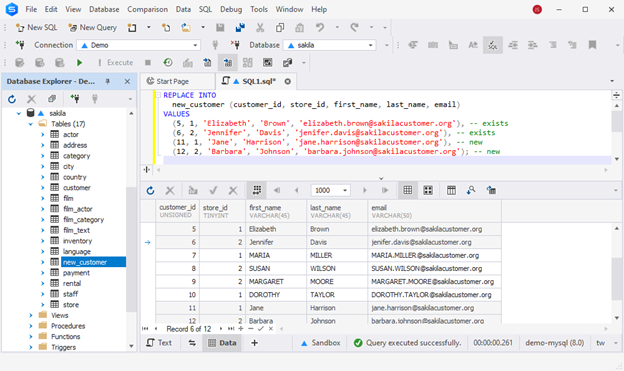
REPLACE INTO
new_customer (customer_id, store_id, first_name, last_name, email)
VALUES
(5, 1, 'Elizabeth', 'Brown', '[email protected]'),
(6, 2, 'Jennifer', 'Davis', '[email protected]'),
(11, 1, 'Jane', 'Harrison', '[email protected]'),
(12, 2, 'Barbara', 'Johnson', '[email protected]'); Now you can see two new records added to the table, along with updated data for the two existing customers. The system deleted the previously found matching records and inserted the values specified in the query instead.
MySQL UPSERT using INSERT ON DUPLICATE KEY UPDATE
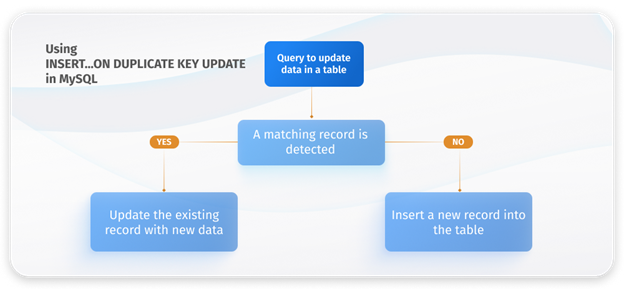
After examining the INSERT IGNORE and REPLACE statements in MySQL, you may have observed limitations associated with each method. INSERT IGNORE merely overlooks duplicate errors without making any changes to the existing data. On the other hand, REPLACE identifies INSERT errors but takes the step of deleting the existing row before adding the new record. A more efficient solution is required.
MySQL provides the INSERT … ON DUPLICATE KEY UPDATE statement as a non-destructive alternative that inserts new entries without removing already present and matching records. When it identifies an existing record that matches the UNIQUE or PRIMARY KEY value, this method initiates an UPDATE operation on that already present record. Thus, INSERT ON DUPLICATE KEY UPDATE functions as an effective UPSERT operation.
The syntax of the INSERT ON DUPLICATE KEY UPDATE statement in MySQL is as follows.
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON DUPLICATE KEY UPDATE
column1 = value1,
column2 = value2,
...; The ON DUPLICATE KEY UPDATE clause indicates that if a duplicate key conflict occurs (if a row with the same unique or primary key value already exists), the query should perform an update instead of inserting a new row.
column1 = value1, column2 = value2, … are located inside the ON DUPLICATE KEY UPDATE block and define the columns to be updated and the new values that should be set for those columns. A comma must separate each column and value pair.
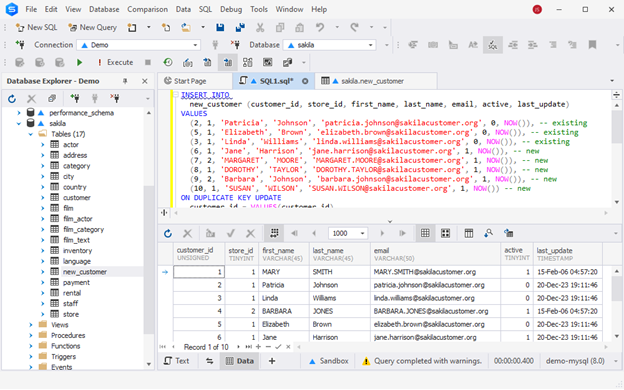
In the following example, we want to update multiple customers in the new_customer table by changing some details for existing customers (active or non-active status) and adding new customers.
INSERT INTO
new_customer (customer_id, store_id, first_name, last_name, email, active, last_update)
VALUES
(2, 1, 'Patricia', 'Johnson', '[email protected]', 0, NOW()),
(5, 1, 'Elizabeth', 'Brown', '[email protected]', 0, NOW()),
(3, 1, 'Linda', 'Williams', '[email protected]', 0, NOW()),
(6, 1, 'Jane', 'Harrison', '[email protected]', 1, NOW()),
(7, 2, 'MARGARET', 'MOORE', '[email protected]', 1, NOW()),
(8, 1, 'DOROTHY', 'TAYLOR', '[email protected]', 1, NOW()),
(9, 2, 'Barbara', 'Johnson', '[email protected]', 1, NOW()),
(10, 1, 'SUSAN', 'WILSON', '[email protected]', 1, NOW())
ON DUPLICATE KEY UPDATE
first_name = VALUES(first_name),
last_name = VALUES(last_name),
email = VALUES(email),
active = VALUES(active),
last_update = VALUES(last_update); Have a look at the following output.
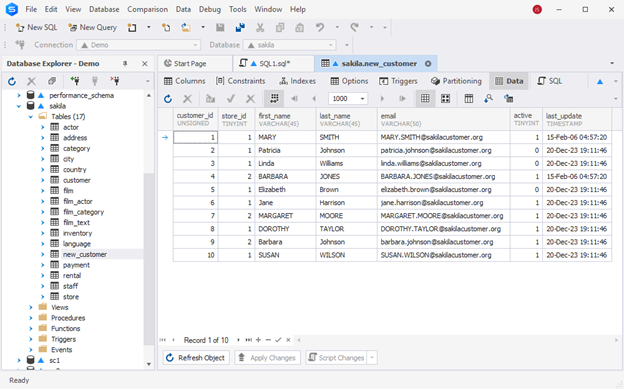
The new_customer table looks as follows.
UPSERT in MariaDB
In MariaDB, the UPSERT operation is also possible through the INSERT … ON DUPLICATE KEY UPDATE method, which is common for both MySQL and MariaDB.
This statement enables you to add new rows to a table. If the table already contains a row with a conflicting PRIMARY/UNIQUE key, the statement updates that existing row with the new values. The syntax is the same as shown earlier for MySQL.
Caveats for bulk multi-row UPSERTs (MariaDB)
- Duplicate key handling: Keys in the same statement are processed from left to right. If the same key appears multiple times in one
INSERT … VALUES (…) , (…) … ON DUPLICATE KEY UPDATE …, the target row may be updated multiple times; the last occurrence determines the final values. - Batch size impact: Large batches increase lock time and contention; aim for smaller chunks (500–2,000 rows) to reduce lock duration and retries.
- Trigger execution: If a row is updated multiple times in the same statement (because the key repeats), the associated side effects (e.g., UPDATE triggers) also run multiple times.
Example: multiple duplicates in one statement (last-wins behavior)
Let’s assume email is UNIQUE.
CREATE TABLE mdb_customer (
customer_id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
-- Existing row
INSERT INTO mdb_customer (email, name)
VALUES ('[email protected]', 'Alice-Original'); Now, issue a single multi-row UPSERT where the same key appears twice.
INSERT INTO mdb_customer (email, name)
VALUES
('[email protected]', 'Alice-v1'), -- duplicate #1
('[email protected]', 'Alice-v2'), -- duplicate #2 (later → wins)
('[email protected]', 'Bob')
ON DUPLICATE KEY UPDATE
name = VALUES(name); -- MariaDB supports VALUES() here Results:
[email protected]becomesAlice-v2(the last duplicate processed wins).[email protected]is inserted asBob.
If you expected Alice-v1 (or wanted to merge fields), a single bulk statement won’t do that; later duplicates overwrite earlier ones.
Safer pattern: pre-deduplicate, then UPSERT
Select one row per key before performing an UPSERT. If you track a “latest” marker like received_at, use a two-step staging + join (works on MariaDB broadly):
-- Example incoming payload (already loaded into a staging table)
-- CREATE TABLE incoming_rows(email VARCHAR(255), name VARCHAR(100), received_at DATETIME);
-- Keep only the latest row per email into a temporary staging table
CREATE TEMPORARY TABLE staging_dedup AS
SELECT r.*
FROM incoming_rows r
JOIN (
SELECT email, MAX(received_at) AS latest
FROM incoming_rows
GROUP BY email
) x ON x.email = r.email AND x.latest = r.received_at;
-- Now perform the UPSERT once per key
INSERT INTO mdb_customer (email, name)
SELECT email, name
FROM staging_dedup
ON DUPLICATE KEY UPDATE
name = VALUES(name); Tip: If you don’t have a timestamp, choose a deterministic tie-breaker (e.g., max/min id) in the subquery.
Conclusion
As previously mentioned, while MySQL doesn’t have a dedicated UPSERT command, you can still achieve this functionality through various methods, ensuring smooth and error-free database updates. MySQL provides three approaches: INSERT IGNORE, REPLACE, and INSERT … ON DUPLICATE KEY UPDATE.
Use the right method for the job:
- Use
INSERT IGNOREif you’re performing idempotent bulk loads and are fine leaving existing rows unchanged.
UseREPLACEif you truly need full-row replacement and can accept the delete+insert side effects (triggers/FKs,AUTO_INCREMENT, higher write cost).
UseINSERT … ON DUPLICATE KEY UPDATEif you need selective updates while preserving existing rows; it is often the best balance.
When working with dbForge Studio for MySQL, you can efficiently create the necessary queries for data updates, achieving faster and safer results thanks to the Studio’s extensive feature set. Beyond offering coding assistance, it also provides dedicated tools for data migration. The dbForge Studio for MySQL stands out as one of the most robust IDEs for both MySQL and MariaDB, simplifying the work of all database specialists.
To experience the capabilities of dbForge Studio for MySQL, take advantage of the fully functional free trial, which grants access to all available features for 30 days. This trial period allows you to thoroughly test the solution under a full workload.