
An index in a database is a special data structure that speeds up the search and retrieval of records from a table. It works similarly to an index in a book, where you can quickly find the needed page by topic or word without having to flip through the entire thing. In this article, we are going to talk about different types of indexes and how to create and use them in both command-line and GUI tools like dbForge Studio for PostgreSQL.
Contents
- Types of indexes in PostgreSQL
- Creating indexes in PostgreSQL
- How to create indexes in PostgreSQL in dbForge Studio
- Best practices for managing indexes in PostgreSQL
- Conclusion
As defined earlier, an index is a special database data structure designed to speed up the search within a table. Depending on its type, it is highly effective for database performance, as it allows you to retrieve data quickly, prevent data duplication, and reduce the need for searching, filtering, sorting, or JOIN operations.
Types of indexes in PostgreSQL
In this section, we will focus on different types of indexes, their definitions, purposes, advantages, and disadvantages.
B-Tree indexes
The first type of index is the B-Tree (Balanced Tree), which is the default in PostgreSQL. These indexes are named for their tree-like structure that maintains sorted data and enables efficient search, insertion, deletion, and sequential access.
Just like anything else, it has its stronger and weaker points:
| Advantages | Disadvantages |
| Fast search and data access speed. | Significant memory requirements for storage. |
| Efficient performance with range queries. | Slower insertion and deletion than in other index types due to the need to maintain a balanced tree. |
| Support for unique values and data sorting. |
Hash indexes
Hash indexes in PostgreSQL use hash tables for quick data access. They are created by applying hash functions that convert index values into unique hash codes, allowing for quick access to the corresponding data in the table.
| Advantages | Disadvantages |
| High search speed for equality operations. | Smaller memory footprint compared to B-Tree indexes. |
| No support for range queries or sorting. | No support for unique constraints. |
Note: In PostgreSQL, hash indexes are less commonly used and less optimized compared to B-Tree indexes.
Unique indexes
As the name suggests, unique indexes ensure that all values are distinct across the rows in a table.
| Advantages | Disadvantages |
| Guaranteed uniqueness of values in specified columns. | Overhead to data insertion and updating, uniqueness needs to be checked. |
| Support for data integrity and consistency. | Restrictions for duplicates. |
| Optimized search for records based on indexed columns. |
Other index types
In addition to the already mentioned types, PostgreSQL supports several others, each suitable for a specific use case:
- GiST is a generalized search tree that can be customized for various data types and queries, such as geometric objects.
- SP-GiST works for partitioning data space, especially for data structures that may be unevenly distributed, such as sparse data like points in space. It is effective for arrays, JSONB data, and full-text search.
- BRIN is efficient for large tables where data is naturally ordered. It uses minimum and maximum value information within data blocks, making it compact and quick to create. This type is perfect for indexing very large tables with ordered data and range queries.
Creating indexes in PostgreSQL
Now, we will be moving on from naming the indexes to actually creating them on one or multiple columns with the help of the CREATE INDEX command.
Basic syntax
We thought it would be appropriate to first provide you with an example of the basic syntax with all possible parameters:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] NAME ] ON [ ONLY ] TABLE_NAME [ USING METHOD ]
({ COLUMN_NAME | (expression) } [ COLLATE COLLATION ] [ opclass [ (opclass_parameter = VALUE [, ...]) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...])
[ INCLUDE (COLUMN_NAME [, ...]) ]
[ NULLS [ NOT ] DISTINCT ]
[ WITH (storage_parameter [ = VALUE ] [, ...]) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]Once that is out of the way, let’s discuss in more detail the creation of the specific index types discussed in the previous section, including B-Tree, hash, and unique indexes.
Creating B-Tree indexes
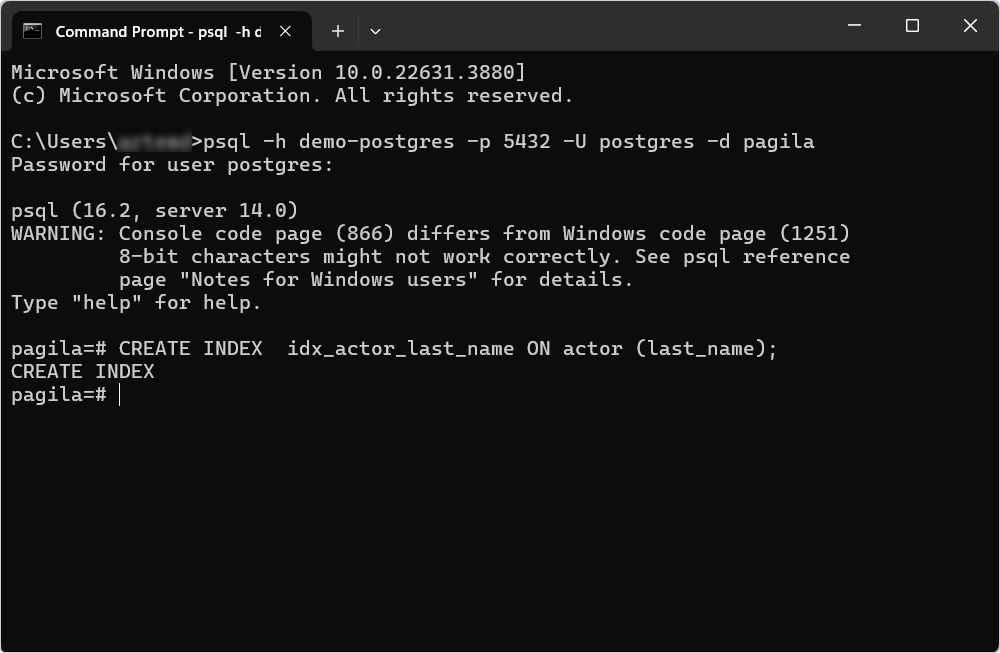
The below command creates a B-Tree index named idx_actor_last_name on the last_name column of the actor table:
CREATE INDEX idx_actor_last_name ON actor (last_name);It can be used to speed up queries that involve searching, sorting, or filtering by the last_name column.
Creating hash indexes
This command creates a hash index idx_hash_email on the email column of the customer table:
CREATE INDEX idx_hash_email ON customer USING HASH (email);This particular example of hash index usage allows you to quickly find exact matches, making them efficient for queries that use equality checks (=) on the email column.
Creating unique indexes
In this example, we create a unique B-Tree index named idx_email_unique on the email column of the customer table.
CREATE UNIQUE INDEX idx_email_unique ON customer (email);Here, a unique index ensures that all values in email are distinct, preventing duplicate entries in that column.
Using psql to create indexes
You must be excited to see all these examples in action by now. Thus, let’s get down to business!
1. Open Command Prompt.
2. Run the psql -h demo-postgres -p 5432 -U postgres -d pagila command.
3. Enter the password.
4. Enter the code to create an index and execute it:
To check which indexes have been created, you can use the system view pg_indexes. Let’s verify that the index was created:
SELECT indexname, indexdef FROM pg_indexes WHERE tablename = 'actor';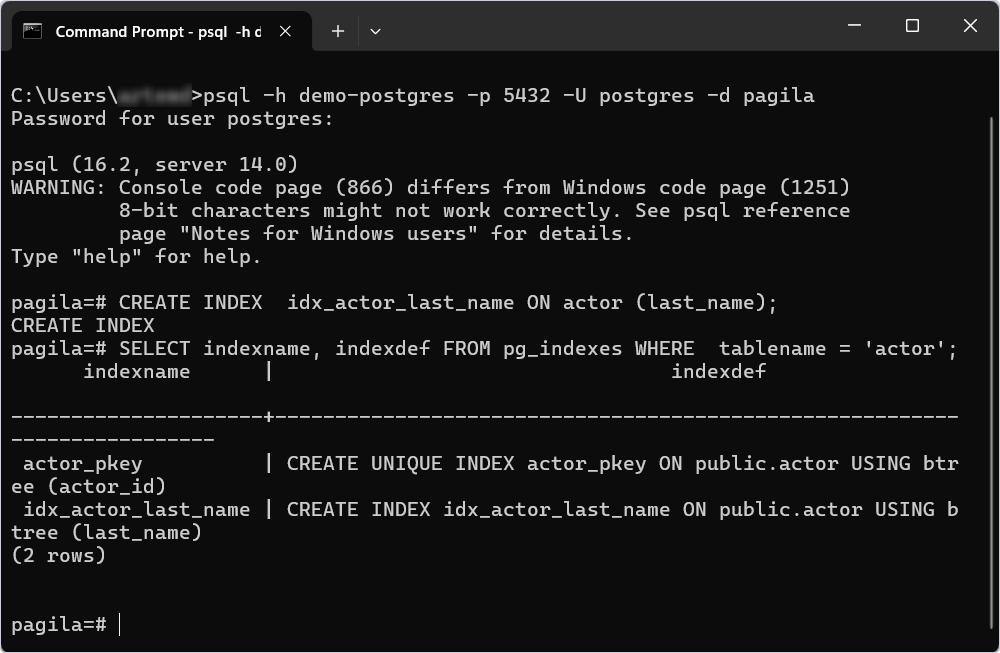
As you can see, besides the unique key, our index idx_actor_last_name is also present in the table, along with its code for creating the index.
Note: The EXPLAIN and EXPLAIN ANALYZE commands are used for query analysis and optimization. They help to understand how effectively the index and other database resources are being used. The SQL Query Profiler tool in dbForge Studio for PostgreSQL allows for a more detailed analysis of the query execution plan and visualization of its structure.
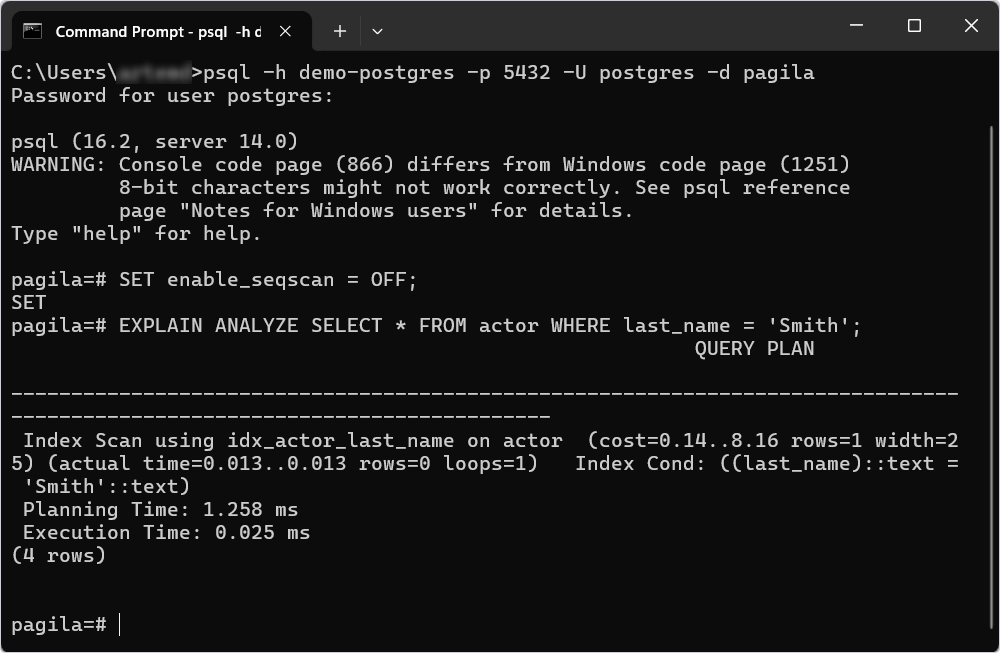
Using GUI tools
Command-line instruments are not the only option to deal with indexes. Using graphical tools simplifies database management and helps avoid errors associated with writing SQL code manually. For example, these are some of the popular solutions:
- pgAdmin
- DbSchema
- dbForge Studio for PostgreSQL
Below, we will be talking about the latter in more detail.
How to create indexes in PostgreSQL for dbForge Studio for PostgreSQL
dbForge Studio is a convenient tool designed for managing PostgreSQL databases. It offers a full range of features that include database design, administration, and development, as well as the creation and management of indexes. The GUI provides an intuitive graphical interface, making it easy to work with databases. You can create tables, indexes, views, and other database objects directly from the SQL document. The Studio supports executing SQL queries and includes tools for query profiling. Additionally, it also allows you to generate reports and create backups while comparing database objects and data.
To support our claims, we will demonstrate the entire index experience in dbForge Studio. Buckle up, and let’s proceed!
1. Launch dbForge Studio for PostgreSQL.
2. In Database Explorer, click New Connection.
3. Enter your PostgreSQL server connection details (hostname, port, username, and password) and click Connect.
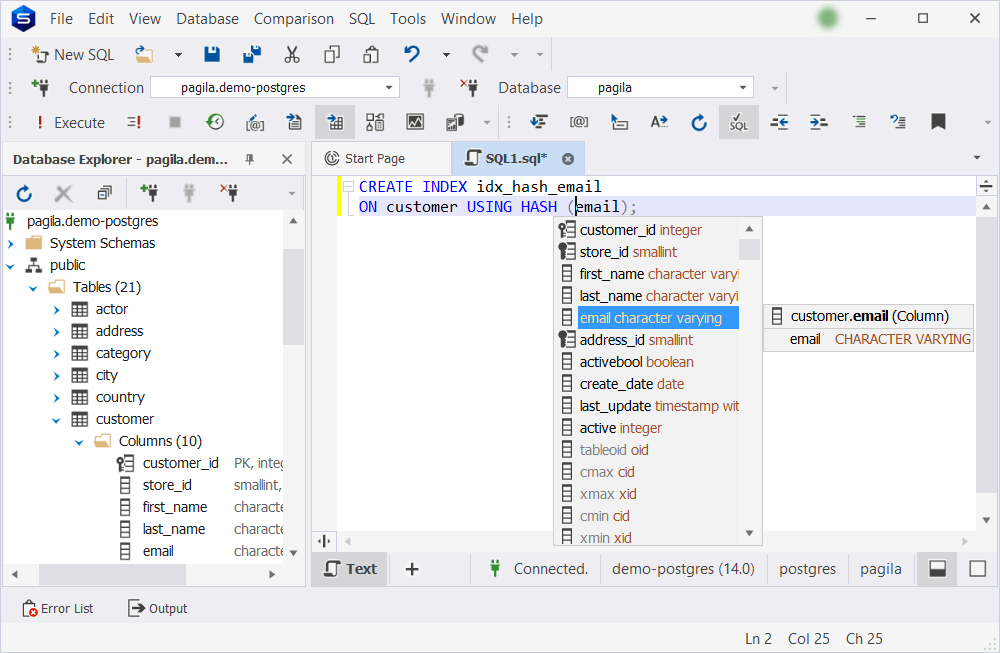
4. Choose a column for which you want to create an index. In our case, let’s stick to the email column from the customer table we used earlier.
5. Open a new SQL window by pressing Ctrl+N. Here, you can type in the CREATE INDEX command with the help of Code Completion, which will substantially speed up the coding process.
CREATE INDEX idx_hash_email ON customer USING HASH (email);6. Once done, execute the command.
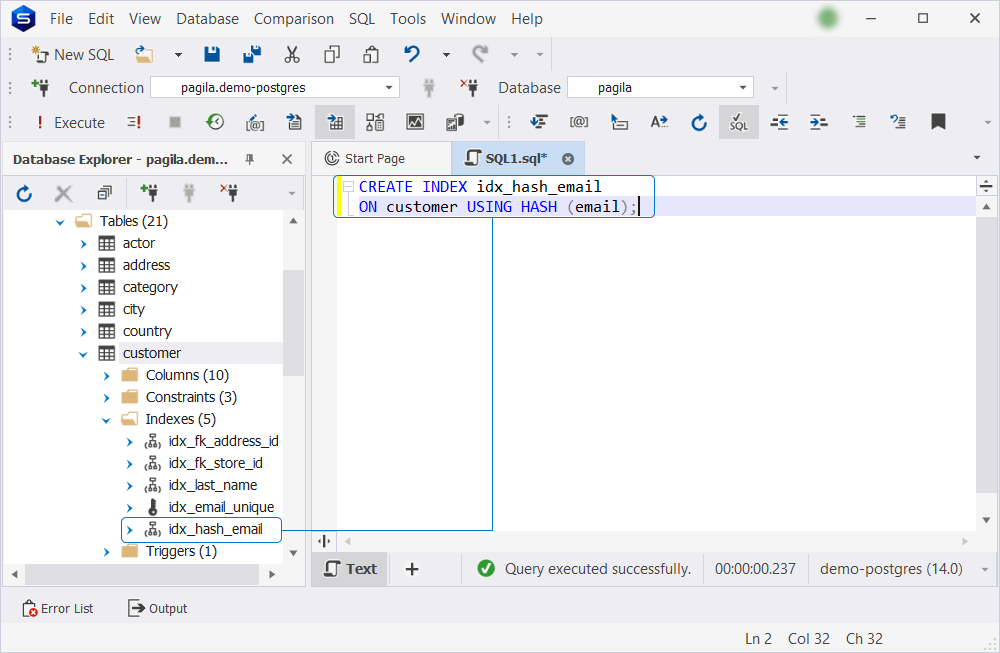
7. Open the Indexes folder in Database Explorer to make sure idx_hash_email was created successfully.
Working with PostgreSQL indexes in Query Profiling Mode
In dbForge Studio, you can enable Query Profiling Mode and use it to see how PostgreSQL executes queries and how indexes affect performance.
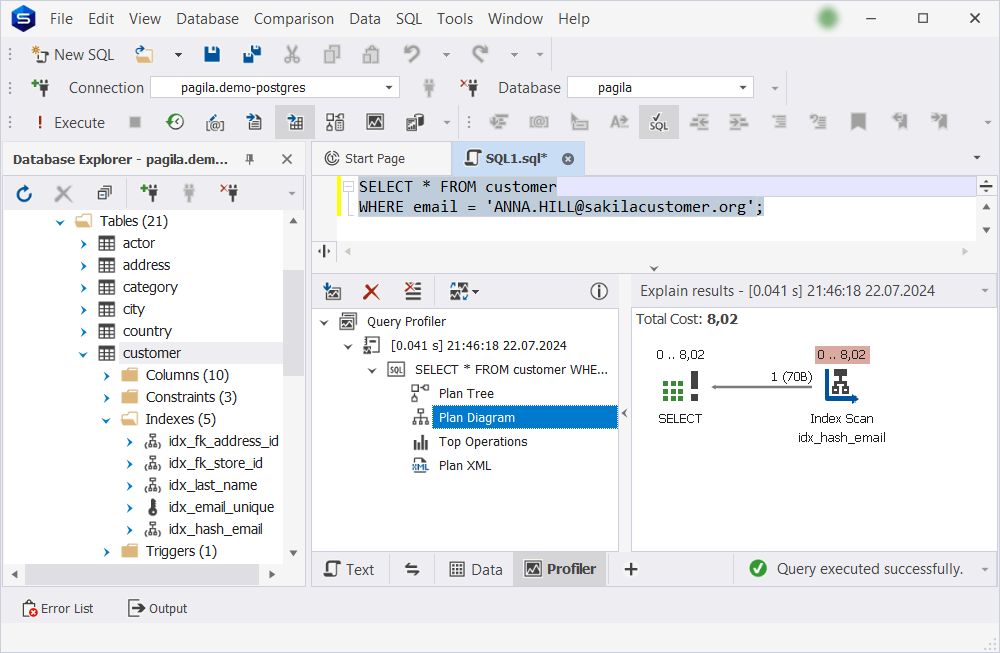
You can use dbForge Studio for PostgreSQL to ensure your query uses indexes. For example, if you have an index on the email column and execute a query on it, you should see an Index Scan on the diagram. If the Query Profiler shows a Seq Scan instead, it may indicate that PostgreSQL is not using the index, possibly due to missing statistics or incorrect configuration. In this case:
- Ensure statistics are updated (use
ANALYZEto do that). - Check configuration settings, such as
random_page_costandseq_page_cost.
Best practices for managing indexes in PostgreSQL
| Use indexes wisely | Create indexes only on columns frequently used in WHERE clauses, JOINs, or for ordering. Having too many indexes can slow down insert, update, and delete operations. |
| Regularly update statistics | Use the ANALYZE command to update table statistics, enabling the query planner to make informed decisions about which indexes to use. |
| Analyze and test | Utilize the SQL Query Profiler to analyze query execution plans. Test the impact of indexes on performance in real-world scenarios. |
| Clean up unnecessary indexes | Remove indexes that are no longer used or do not provide significant performance improvements. This reduces the overhead of maintaining indexes. |
| Monitor performance | Regularly check query performance and ensure indexes are being used correctly, especially after schema changes or significant data volume increases. |
Conclusion
In this article, we explored various types of indexes in PostgreSQL, including B-Tree, hash, unique, GiST, SP-GiST, GIN, and BRIN. While command-line tools are useful for managing indexes, consider using dbForge Studio for PostgreSQL to take advantage of its extensive features and streamlined functionality. Download dbForge Studio and experience how its rich capabilities can enhance your database management.