
The shorthand SELECT * command might be one of the most convenient and commonly used SQL statements during the development phase, but is it really the best practice for production environments? Let us try to find out.
In this article, we will explore the various scenarios where using SELECT * is considered acceptable and the situations where it may lead to complications. We will also demonstrate how to efficiently identify SQL SELECT statements with asterisks and quickly fix them.

Contents
- Understanding SELECT * in SQL
- Reasons to Avoid Using SELECT * by ChatGPT-4
- Guidelines for Using SELECT * in SQL Server: Do’s and Don’ts
- Using dbForge Search to Find SELECT * Statements
- Using dbForge SQL Complete to Fix SELECT * Statements
- Conclusion
Understanding SELECT * in SQL
The SELECT * command in SQL is used to select all columns from a table. This command fetches every row for every column from the table name specified in the FROM clause.
Here’s a basic example of how to use SELECT *:
SELECT * FROM table_name;While the command is extremely convenient for quick-and-dirty queries, especially during development and testing, it’s generally not recommended for production use for a variety of reasons, including performance implications and future maintainability.
Let us consider the following example. If you run the query SELECT * FROM Users; on production, you’ll pull all data from the Users table, which could include large fields like avatar pictures. This can be resource-intensive, consuming significant memory and CPU.
A more efficient strategy is to specify only the columns you actually need, thereby reducing the database resources needed for the query. For instance:
SELECT
FirstName,
LastName,
Email,
Login
FROM Users;For queries that are executed frequently, such as those used in authentication, you can further optimize performance by creating a covering index. A covering index includes all the fields required by your query, which can lead to substantially faster query execution.
CREATE NONCLUSTERED INDEX IDX_Users_Covering ON Users
INCLUDE (FirstName, LastName, Email, Login);SQL Server’s query optimizer prefers using a covering index when it can, as this avoids the need to sift through the clustered index. However, if you use SELECT *, the likelihood that an existing index will cover all columns is quite low.
Even in the extreme case where you create a non-clustered index that covers the entire table, such an index would lose its efficacy if the table grows in size significantly. Therefore, the use of SELECT * not only leads to performance issues but also undermines the advantages of indexing strategies, making them less efficient as the table evolves.
Reasons to avoid using SELECT * by ChatGPT-4
When it comes to SQL queries, the usage of the asterisk (*) is a topic that often ignites debate among developers, database administrators, and data architects alike. Let us ask ChatGPT-4 – an AI-powered chatbot developed by OpenAI – if there are reasons to avoid using SELECT *.

We agree with ChatGPT-4, that using SELECT ALL can lead to vulnerabilities and performance issues. It also also makes your code less readable, and harder to maintain. However, we should also mention an issue with duplicate column names.
Using SELECT * in SQL with multiple joined tables can lead to duplicate column names, making it hard for applications to interpret the results. For instance, the following query would generate duplicate Customer columns:
SELECT *
FROM Sales.Customer AS c
INNER JOIN Sales.SalesOrderHeader AS soh
ON c.CustomerID = soh.CustomerID;This could cause issues when the application tries to parse the result set by column names. If you attempt to create a temporary table using SELECT * INTO, you’ll run into an error because of duplicate column names:
SELECT * INTO TempCustomerOrders
FROM Sales.Customer AS c
INNER JOIN Sales.SalesOrderHeader AS soh
ON c.CustomerID = soh.CustomerID;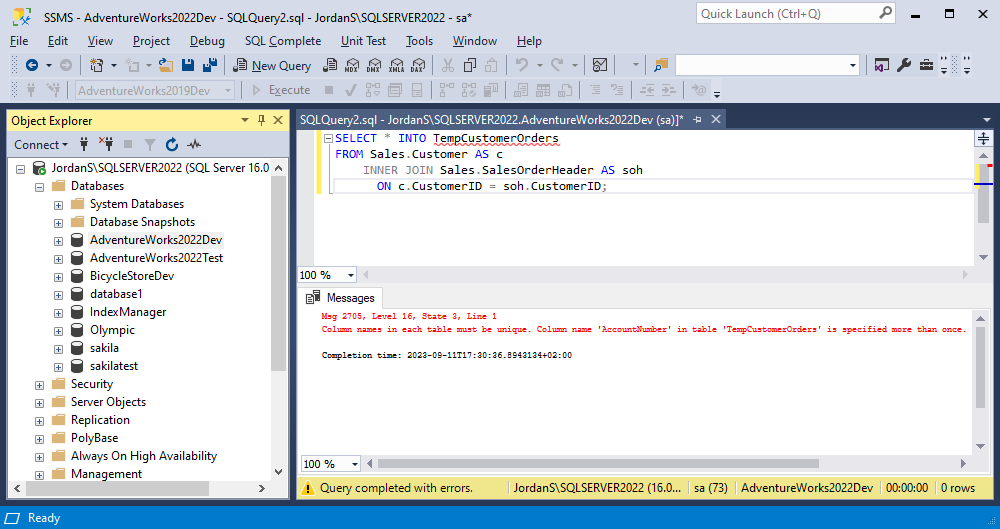
Guidelines for using SELECT * in SQL Server: Do’s and don’ts
Here are our expert recommendations for the responsible and effective use of SELECT * statements in SQL Server.
When to Avoid SELECT *
Production code: In production code, you should explicitly specify column names to prevent any unintended changes when the table structure changes.
Performance: Retrieving all columns usually means more disk I/O, more data transferred, and more memory usage than specifying only the columns you actually need.
Views and stored procedures: Avoid using SELECT * in views and stored procedures. Changes to the underlying table could break the code.
Join operations: When you’re joining multiple tables, using SELECT * could result in column name ambiguity, and again, more data transferred than necessary.
Applications: In application code, where you are interfacing with a database, always specify the columns you need to work with to avoid breaking changes and performance degradation.
When SELECT * is Acceptable
Ad-hoc queries: For quick data inspection, using SELECT * is generally fine, as long as these queries do not make their way into production.
Initial data exploration: When you’re initially exploring a new database or table schema, SELECT * can be a quick way to view table data.
Administrative scripts: Sometimes, administrative or data migration scripts may require selecting all columns. However, even in such cases, it’s generally safer to specify columns explicitly.
Best Practices
Explicit columns: Always specify which columns you need.
Qualify column names: When joining tables, qualify column names with table or alias names to avoid ambiguity.
Indexes: Make sure you have appropriate indexes in place to speed up query performance for the columns that you are actually using.
Monitor and optimize: Always check the query execution plan and use SQL Server Profiler or Extended Events to catch and optimize problematic queries.
Code reviews: Regularly review code for any instances of SELECT * that could potentially cause problems.
Using dbForge Search to Find SELECT * Statements
About dbForge Search
dbForge Search is a FREE add-in for SQL Server Management Studio designed for efficient database searching within SQL Server. It simplifies the task of locating SQL objects, data, and even specific text within stored procedures or queries. With its user-friendly interface and powerful capabilities, dbForge Search helps developers and database administrators quickly identify and manage elements in large and complex SQL Server databases.
How to Locate SELECT * Statements With dbForge Search
Locating SELECT * statements in a SQL Server database can be a crucial step for optimization and best practice enforcement. If you’re using dbForge Search, finding these statements is a straightforward process. Here’s how to do it:
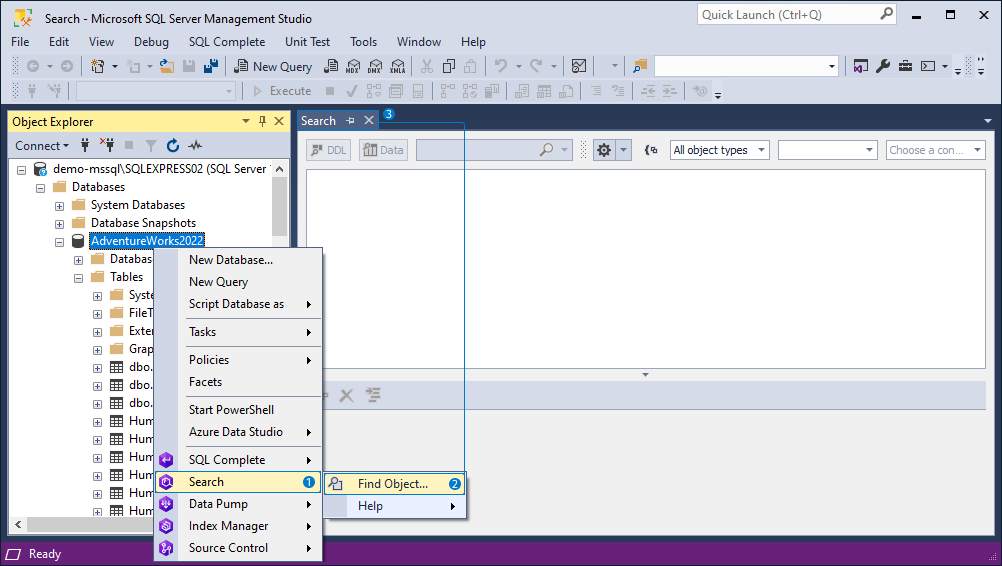
1. In the Object Explorer, right-click the database you want to search through. Then select Search -> Find Object.
2. In the search box, enter the search phrase you want to use. In this example, we enter SELECT *.
Note
Make sure that all search options are cleared before starting your search. If you select Use WildCards, dbForge Search will treat the asterisk as one of the SQL wildcard characters and will find all the occurrences of the SELECT statement in the database.
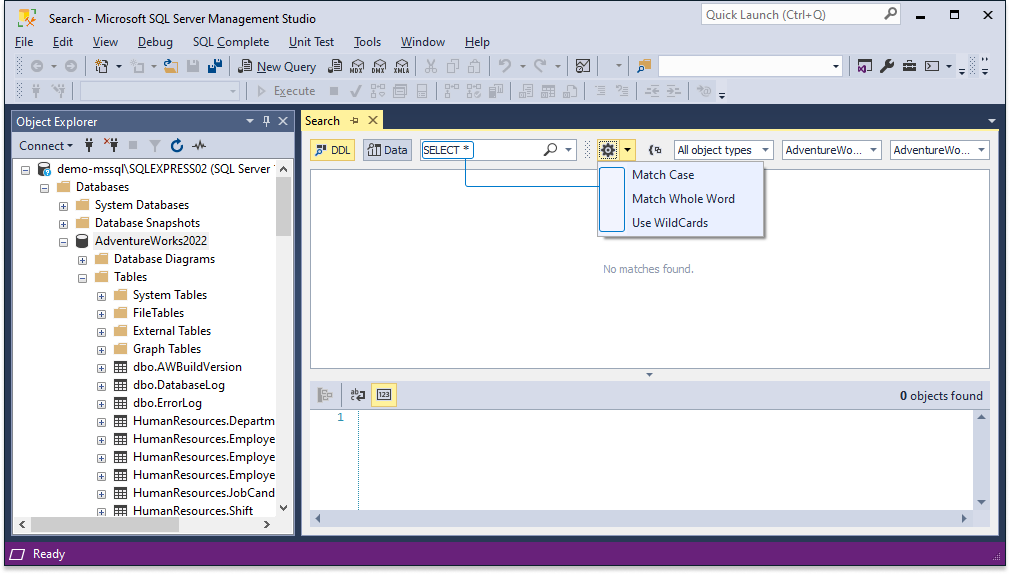
3. Press Enter or click Start Search.
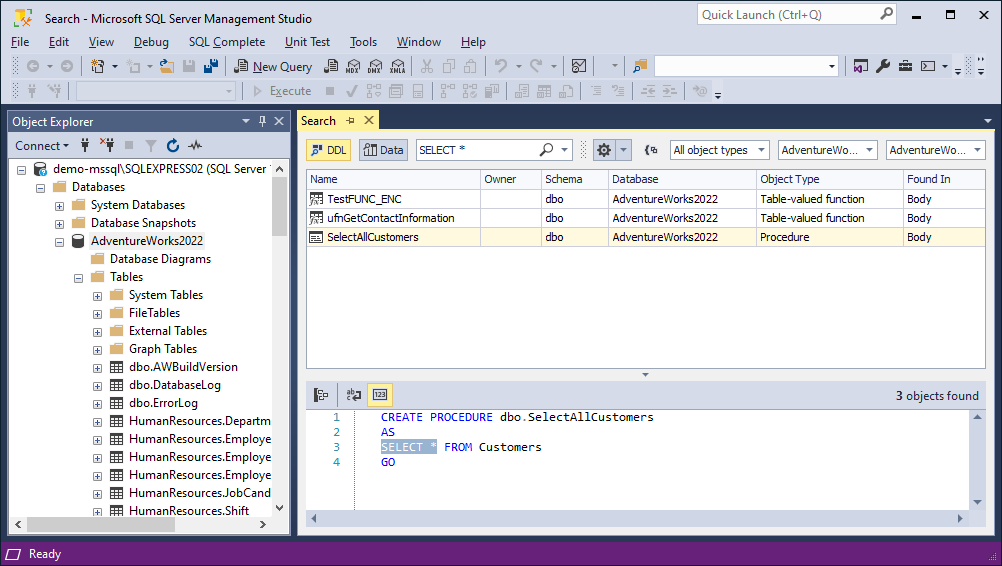
After the search is finished, you can see the found results in the Search Results grid. When you select a result in the grid, the Preview window below the grid displays the DDL statements associated with the selected result.
Using dbForge SQL Complete to Fix SELECT * Statements
After you have found all the statements containing SELECT *, you can efficiently optimize them using dbForge SQL Complete, a robust add-in developed by Devart. dbForge SQL Complete is an advanced SQL code completion and productivity tool that integrates seamlessly with SQL Server Management Studio (SSMS) and Visual Studio. It offers a wide range of features to enhance SQL coding speed and quality, such as intelligent code completion, code snippets, and query optimization, helping developers write more efficient and readable SQL queries.
How to Optimize SELECT * Queries With dbForge SQL Complete
To get rid of the statements that contain SELECT *, you can use the Statement expansion feature. It enables users to replace the asterisk symbol (*) with a list of the necessary table or view columns simply by pressing the Tab key. Let us look at how to do this step-by-step.
1. Find the queries you want to optimize using dbForge Search.
2. Click Find in Object Explorer.
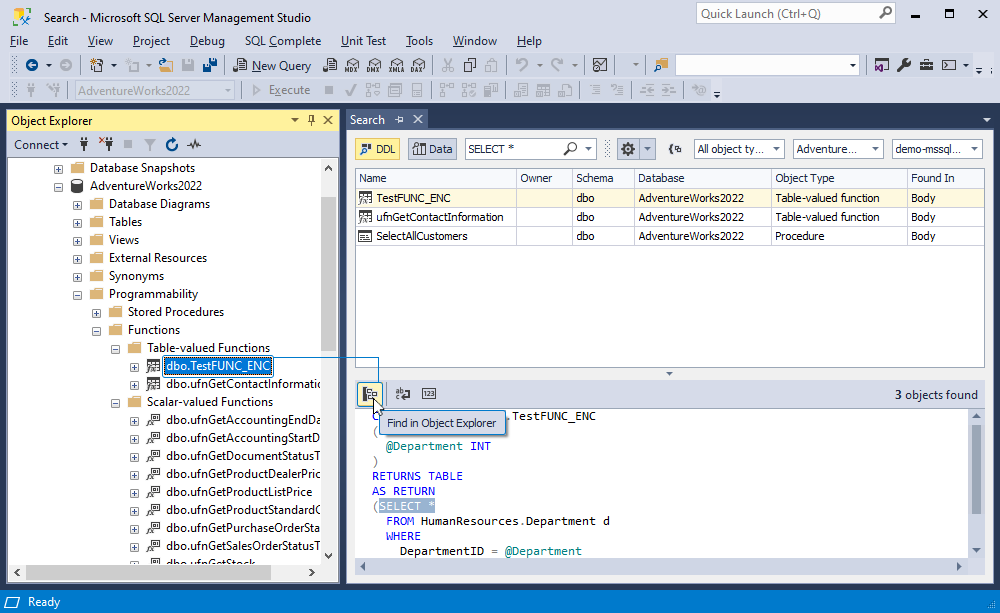
3. In Object Explorer, right-click the necessary database object and select Modify. A new tab that allows you to make changes to the object will open.
4. Place the cursor after the * in SELECT * and press Tab. dbForge SQL Complete will automatically replace * with the list of all columns from the table in a comma-separated format.
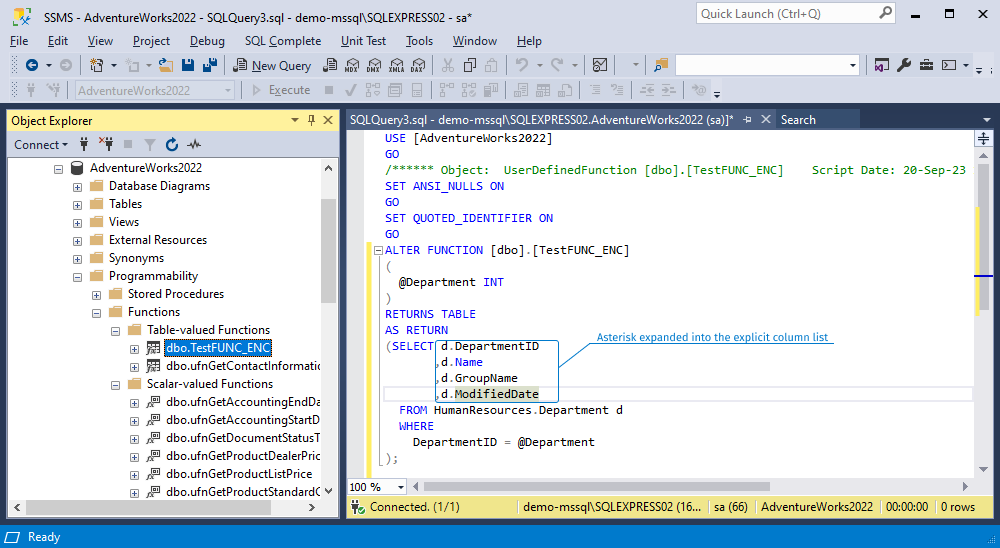
5. Now you can remove unnecessary columns from the full column list.
Conclusion
In conclusion, the practice of replacing asterisks with explicit column lists in SQL SELECT statements is not merely a matter of style—it has tangible benefits. It enhances query readability, simplifies debugging, and potentially improves performance by reducing the amount of data that needs to be retrieved and processed.
In this article, we’ve demonstrated how to identify and fix SELECT * statements using two robust tools from dbForge product line. These utilities make it easier than ever to optimize your SQL queries for improved performance and readability.
Ready to elevate your SQL coding? Download dbForge Search and dbForge SQL Complete now to get started.