")
Knowing how to create a database is no longer just a backend task; it’s a core skill for building systems that perform under pressure and scale with complexity. With global data volumes expected to reach 175 zettabytes by 2025, developers must design systems that turn raw information into something meaningful, accessible, and usable.
But what does that look like in practice? How do you go from raw data requirements to a reliable schema? Which engine should you choose? And how do you ensure today’s structure doesn’t limit tomorrow’s growth?
This guide shows you how to build a database from the ground up: from schema design and engine selection to performance tuning with tools like dbForge Edge.
Let’s get started!
Table of contents- What is a database and why create one from scratch?
- Main components of a database
- The fundamental steps in creating a database
- Best practices for creating a database from scratch
- How AI can help you in database creation
- Enhance your database creation process with dbForge Edge
- Conclusion
- Frequently asked questions
What is a database and why create one from scratch?
A database is a structured system for storing and managing data. It enables users and applications to access, update, and organize information quickly and reliably. From powering eCommerce platforms to running enterprise ERP systems, databases are central to modern software.
Behind the scenes, every database is governed by a Database Management System (DBMS): the software that handles data structuring, querying, indexing, and enforcement of rules like uniqueness or referential integrity. Whether it’s MySQL, PostgreSQL, or SQL Server, the DBMS defines how data is stored and accessed.
Why create a new database?
In an era of plug-and-play solutions and low-code platforms, setting up a database from scratch may seem like overkill. But for serious developers and businesses, it’s often the only way to get it right. Here’s why:
- Precision architecture: Prebuilt systems are generic by design. Starting from scratch allows you to model your data around the actual logic of your business, not someone else’s assumptions.
- Full control: You define the structure, rules, and constraints, no hidden dependencies, no opaque relationships. That means better performance, stronger data integrity, and fewer surprises down the line.
- Optimization from day one: Custom schemas let you fine-tune indexes, relationships, and data types from the start, critical for applications that demand speed or scale.
- Security by design: With a scratch-built system, access control, encryption, and audit trails can be designed into the foundation, not retrofitted after a breach.
- Scalability with purpose: Whether you’re planning multi-region deployments or heavy transactional loads, designing your own schema lets you future-proof without compromise.
- Deeper technical ownership: Teams that know how to build a database from the ground up understand every detail, from normalization to indexing strategies. That knowledge becomes a strategic advantage when troubleshooting, scaling, or innovating.
In short, building a database from scratch is for teams that care about performance, ownership, and long-term adaptability. It’s a deliberate investment in doing it right.
Main components of a database
A well-structured database begins with its schema: the architectural framework that determines how data is stored, linked, and accessed. Each component plays a critical role in ensuring system reliability, performance, and long-term scalability.
Tables
Tables define the structure for storing data. Each table organizes information into rows and columns, where each row is a distinct record and each column represents a specific attribute. A well-defined table provides:
- A clear structure aligned with one concept, such as a Users table with fields like UserID, FirstName, Email, and CreatedAt.
- Column data types and constraints that enforce valid input and prevent inconsistencies.
- Logical isolation of entities to support normalization and long-term maintainability.
Relationships
Relationships establish logical connections between tables, reflecting how data points interact in the real world. These connections make it possible to design systems that scale without duplicating information. The most common types include:
- One-to-many: One customer places many orders.
- Many-to-many: Products appearing in multiple orders, and each order including multiple products, implemented through a join table.
Effective relationships create data models that are accurate, modular, and scalable.
Keys (primary & foreign)
Keys serve as anchors for identity and connection within a database. They ensure every record is uniquely identifiable, and that related data stays in sync. A solid key strategy includes:
- Primary keys that uniquely identify each record within a table.
- Foreign keys that reference primary keys in related tables to enforce referential integrity.
Key-based design is critical for reliable joins, fast queries, and trust in the data model.
Indexes
Indexes accelerate data retrieval by allowing the database engine to bypass full table scans. When applied strategically, indexes significantly boost performance without compromising accuracy. Key indexing approaches include:
- Single-column indexes for high-frequency fields like Email or OrderDate.
- Composite indexes that support filtering or sorting across multiple fields.
- Full-text indexes that enable fast keyword searches within large text columns.
Strategic indexing improves response time and reduces query load on large datasets.
Views
Views are virtual tables built from stored queries. They present filtered or combined data from one or more tables without duplicating it. When used well, views improve usability and security. Common use cases include:
- Creating role-specific data access layers for analytics or reporting.
- Hiding complex joins or sensitive fields while surfacing only what’s necessary.
- Centralizing business logic within reusable, maintainable query structures.
Views enhance maintainability, improve security, and support role-based data access strategies.
Together, these components form the backbone of a high-performing database. Mastering them enables developers to design systems that are not only efficient and secure, but also adaptable to the evolving demands of modern applications.
The fundamental steps in creating a database
Building a database from scratch requires more than writing SQL; it’s a design-first process that shapes how data flows, scales, and stays reliable over time. From initial modeling to physical implementation, each step lays the groundwork for performance and integrity.
Here’s a step-by-step process of how to make a database.
Step 1: Plan your database schema
Before any table is created, the schema must be clearly defined. This is the architectural phase where you model your data based on real-world entities and how they relate to one another.
Start by identifying the core entities your system needs to support—such as Users, Orders, Products, or Transactions. Then:
- Structure each table around a single entity, with attributes represented as columns.
- Define primary keys to uniquely identify records and anchor relationships.
- Map out relationships (one-to-many, many-to-many) to clarify how tables connect through foreign keys or join tables.
- Apply normalization to eliminate redundancy and specify data dependencies.
A well-planned schema reduces friction during development, simplifies query logic, and supports long-term adaptability.
Step 2: Choose your database engine
Once your schema is designed, the next step is selecting the right database engine, also known as a Database Management System (DBMS). This choice directly impacts your application’s scalability, compatibility, and operational efficiency.
Several proven options dominate the landscape:
- MySQL: Open-source and widely used for web applications.
- PostgreSQL: Standards-compliant with advanced data type support.
- SQL Server: Enterprise-grade, strong in Microsoft environments.
- SQLite: Lightweight and portable, suited for embedded use.
When choosing a DBMS, consider:
- Workload characteristics (transactional vs. analytical)
- Hosting environment (cloud, on-premises, hybrid)
- Ecosystem requirements (support for ORMs, reporting tools, backups)
- Licensing and budget constraints
Select a DBMS that not only fits your current needs but also scales with your application’s growth trajectory.
Step 3: Create tables and define relationships
After selecting your database engine and finalizing the schema, start implementing the structure. Write SQL to create tables, define fields, and enforce relationships. Each table should represent a single entity with clearly defined attributes.
Example
CREATE TABLE Users (
UserID INT PRIMARY KEY,
FirstName VARCHAR(50),
Email VARCHAR(100) UNIQUE,
CreatedAt DATETIME
); Use foreign keys to link related records and maintain referential integrity. For example, link each order to a user by referencing the user’s primary key.
Example
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
UserID INT NOT NULL,
OrderDate DATE,
FOREIGN KEY (UserID) REFERENCES Users(UserID)
); To model many-to-many relationships, such as orders containing multiple products, introduce a junction table. This table references the primary keys of both related entities.
Example
CREATE TABLE OrderItems (
OrderID INT,
ProductID INT,
Quantity INT,
PRIMARY KEY (OrderID, ProductID),
FOREIGN KEY (OrderID) REFERENCES Orders(OrderID),
FOREIGN KEY (ProductID) REFERENCES Products(ProductID)
); Define constraints (NOT NULL, UNIQUE, CHECK) and set appropriate data types to protect data integrity from day one.
By planning the schema, selecting the appropriate engine, and implementing a sound structure, you can create your own database that supports current functionality and scales with future growth.
Best practices for creating a database from scratch
A reliable database does more than hold data, it must scale gracefully, respond quickly, and stay resilient as systems evolve. The principles below serve as the foundation for a high-performing, production-ready database.
Normalize your database
Efficient design starts with normalization. This process organizes your data into structured tables that reduce duplication and ensure logical consistency. Rather than cramming unrelated fields into a single table, normalization encourages clarity in how entities relate.
Apply the following normal forms as part of schema design:
- 1NF (First Normal Form): Ensure that each field contains only atomic values. For example, use separate rows, not comma-separated lists, for multiple phone numbers.
- 2NF (Second Normal Form): Eliminate partial dependencies; every non-key field must depend on the full primary key.
- 3NF (Third Normal Form): Remove transitive dependencies so that fields relate only to the primary key, not to each other.
Normalization simplifies queries, prevents data anomalies, and creates a schema that holds up under scale and change.
Use indexes to improve query performance
Once the structure is clean, the next priority is performance. Indexes play a critical role by allowing the database engine to locate records quickly without scanning full tables. Here are the index types to consider:
- Unique indexes enforce data integrity and speed up lookups on high-priority fields like Email or Username.
- Composite indexes optimize queries that filter or sort using multiple columns.
- Full-text indexes accelerate keyword searches across large text-based fields.
Indexes should be used deliberately. Every index speeds up reads but adds overhead to writes, so optimization requires a balance between performance and efficiency.
Backup your database consistently
With performance handled, attention turns to resilience. Backups protect against data loss; whether from failure, corruption, or accidental deletion. Without a reliable backup strategy, all other efforts risk being undone in a single event. Key types include:
- Full backups: A complete copy of the database.
- Incremental backups: Only changes since the last backup.
- Differential backups: All changes since the last full backup.
Automated scheduling and routine recovery tests are essential. A backup that exists but doesn’t restore is a liability, not a safeguard.
Secure your database from the ground up
Database security is not a final step, it must be woven into every layer of the database. As systems handle increasingly sensitive data, access controls and encryption are baseline requirements, not enhancements. A secure design includes:
- Encryption for both data in transit (e.g., TLS) and data at rest—especially for PII or financial records.
- Role-based access control that restricts users based on function and necessity.
- Audit logs to track who accessed what and when. This is often implemented via external monitoring or enterprise-grade auditing tools depending on the DBMS.
- Ongoing patching and monitoring to reduce exposure to known vulnerabilities.
Prioritizing security early on reduces risk and builds trust into your application infrastructure.
Plan for scalability
Finally, a database that can’t scale becomes a bottleneck. Designing with growth in mind ensures that your system remains responsive as data volume and user traffic increase. Scalability strategies include:
- Vertical scaling: Add CPU, memory, or storage to a single server.
- Horizontal scaling: Distribute load across multiple servers.
- Partitioning: Split large tables into manageable segments.
- Sharding: Spread data across databases using a shard key.
Pro Tip: While effective for scale, sharding introduces complexity in query joins, ACID guarantees, and schema versioning. It requires thoughtful design upfront to avoid technical debt later on.
Think about scalability from day one to reduce rework and ensure your database remains a strength, not a constraint, as the application evolves.
Together, these best practices form the operational backbone of a modern database. They promote clarity of design, efficiency in performance, resilience in the face of failure, and readiness for growth.
How AI can help you in database creation
Developing databases has always demanded precision; planning schemas, writing queries, optimizing performance, and resolving errors. These are high-effort, high-impact tasks. AI is now shifting the landscape, enabling developers to focus less on syntax and more on structure, logic, and project growth.
AI-assisted tools accelerate database development by automating repetitive work, reducing manual errors, and delivering context-aware guidance. What once took hours can now be accomplished in minutes, with greater confidence and clarity. However, these tools still require professional oversight. especially in production-critical systems.
Where AI delivers the most impact
In the hands of experienced professionals, AI enhances, not replaces, core workflows. It supports decision-making, speeds up delivery, and reinforces best practices at every stage.
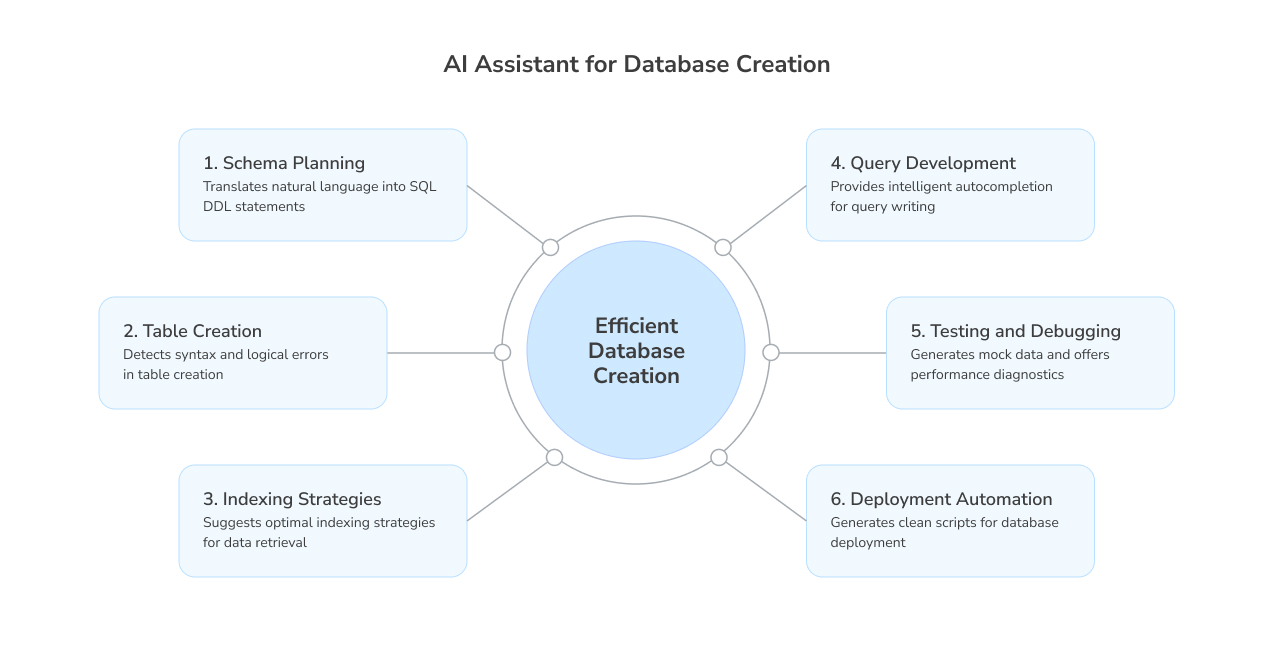
With AI-assisted tools you can:
- Plan schemas: Generate SQL DDL from plain language to jump-start modeling.
- Create tables: Catch structural and relational errors as you define tables.
- Apply indexes: Recommend high-impact indexes based on access patterns.
- Write queries: Auto-complete SQL with context-aware suggestions.
- Test and debug: Generate mock data and surface performance issues early.
- Deploy with confidence: Produce clean, CI/CD-ready scripts for production rollout.
However, these tools still require professional oversight, especially in production-critical systems.
AI in practice: dbForge AI Assistant
dbForge AI Assistant is purpose-built to support database professionals at every stage of development. Integrated into the dbForge environment, it functions as a real-time assistant, accelerating tasks while enhancing accuracy. Key features include:
- Context-aware coding support & explanations: Understands exactly what your SQL statements do and why you use them. The assistant interprets code context, offering in-line suggestions and explanations that reinforce clarity and correctness.
- Natural language to SQL conversion: Describes your data needs in plain English and provides you with fully structured SQL in return. Ideal for building queries quickly, even across unfamiliar schemas.
- SQL troubleshooting: Detects and resolves issues with precision. The assistant analyzes problematic queries and provides corrective recommendations grounded in syntax, logic, and structure.
- SQL optimization: Improves query performance with intelligent recommendations, whether by adding indexes, rewriting joins, or reordering filters. Optimization insights are tailored to the actual workload and data patterns.
By integrating these capabilities into a developer’s daily workflow, dbForge AI Assistant elevates productivity, improves code quality, and reduces time spent on trial-and-error.
Try dbForge AI Assistant for your next database project. Sign up for a free trial and experience how AI can accelerate development with low effort.
These AI-driven capabilities are just one part of the broader innovation within the dbForge ecosystem. To see how these features fit into a complete, end-to-end development environment, let’s look at dbForge Edge in practice.
Enhance your database creation process with dbForge Edge
Building a database from scratch requires more than code, it demands visibility, structure, and control across every layer of development. That’s where dbForge Edge delivers.
dbForge Edge is an all-in-one database design and management suite built for professionals who need more than just basic SQL execution. From data modeling and query building to schema comparison and deployment, it brings structure and speed to every phase of database creation.
Why dbForge Edge stands out
Whether you’re starting a new project or modernizing legacy architecture, dbForge Edge provides the tools to design confidently and work efficiently:
- Visual database design: Build and refine your schema with an intuitive ER diagram editor. Define tables, relationships, and constraints visually—then generate clean, ready-to-deploy SQL scripts.
- Schema comparison and synchronization: Detect and manage changes across environments with precision. Compare development and production schemas, preview differences, and apply updates without risking data integrity.
- Advanced SQL development tools: Write, test, and optimize queries in an intelligent editor with auto-completion, syntax highlighting, execution plans, and real-time code diagnostics.
- Integrated data tools: Access features for data import/export, test data generation, reporting, and backup, right inside the development environment.
- Multi-platform support: Work smoothly across MySQL, PostgreSQL, SQL Server, and Oracle, all within a unified interface.
- AI-powered development: dbForge Edge includes a built-in SQL AI tool. This helps developers write queries, troubleshoot errors, and optimize performance using natural language input and context-aware recommendations.
For developers and teams managing complex environments, dbForge Edge simplifies the database lifecycle while preserving flexibility and control.
Start building your database from scratch today with dbForge Edge. Download a free trial and let an integrated toolkit improve your entire development process, from design to deployment.
Conclusion
Understanding how to make your own database gives you control over structure, performance, and scalability, yet still demands discipline in planning and execution. From defining the schema and selecting the right engine to enforcing best practices around normalization, indexing, security, and scale, each step shapes how your system will perform in production.
The right tools elevate that process. Solutions like dbForge Edge equip professionals with the depth and flexibility required to model, develop, and manage modern databases with confidence. When paired with the dbForge AI Assistant, that workflow becomes even more efficient. It offloads routine tasks like query generation, optimization, and debugging to an intelligent, context-aware system.
With a strong foundation and AI-driven guidance, teams move faster, reduce friction, and focus on building systems that scale.
Frequently asked questions
How to build a database with multiple tables and relationships?
Start by designing a schema that defines the entities and how they relate. Create individual tables for each entity, define primary keys, and use foreign keys to establish one-to-many or many-to-many relationships. Tools like dbForge Edge help visualize and manage these relationships with precision.
How to develop a database with proper indexing and optimization?
Begin with a normalized schema, then analyze query patterns to define indexes. Use a mix of unique, composite, and full-text indexes based on data access needs. dbForge Edge provides query profiling and execution plans to help you fine-tune performance.
How to set up a database for large-scale applications or systems?
Design with scalability in mind—apply normalization, implement indexing strategies, and consider partitioning or sharding early on. Choose a robust DBMS that supports high concurrency. dbForge Edge supports schema modeling, stress testing, and deployment workflows suitable for large systems.
Can dbForge assist in building a database for a web application?
Yes. dbForge Edge supports multi-platform environments including MySQL, PostgreSQL, SQL Server, and Oracle, all commonly used in web applications. It helps with schema design, query development, data management, and integration with CI/CD pipelines.
How to use dbForge to set up a database with custom schemas and tables?
You can create and manage custom schemas using dbForge Edge’s visual design tools or SQL editor. It allows you to define tables, keys, constraints, and relationships through both GUI and script-based interfaces, with instant previews and synchronization options.
Can dbForge help automate the creation of a database from scratch?
Yes. dbForge Edge provides features for visual design, schema generation, and code automation. Combined with the dbForge AI Assistant, it helps generate SQL scripts, troubleshoot logic, and validate schema structure more efficiently.
Can the AI Assistant assist in converting natural language into SQL queries for database creation?
Absolutely. The dbForge AI Assistant translates plain-language prompts into valid SQL, enabling faster query creation—especially useful during early-stage design or when exploring new schemas.
How does the AI Assistant improve query performance while building a database?
It analyzes SQL statements in real-time, flags inefficiencies, and suggests improvements such as indexing, join restructuring, or filter optimization. This ensures high-performance queries from the start, even in complex environments.