
Microsoft SQL Server has a client-server database architecture, where the process typically begins with the client app sending a request to the server—and continues as the SQL Server receives and processes the request, and then returns the required result.
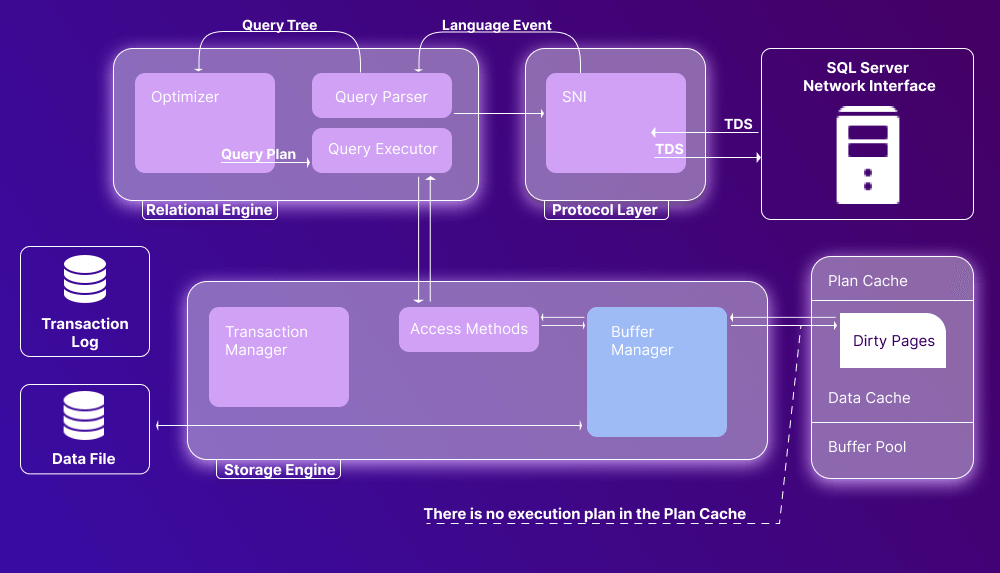
Let’s explain the main components of SQL database architecture with a diagram. We can single out three of them:
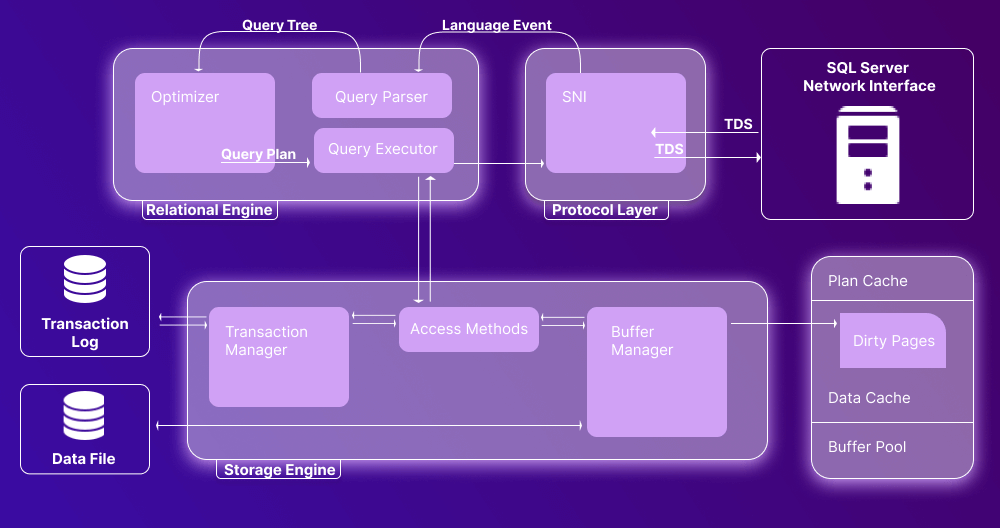
Now let’s have a detailed overview of each component.
SQL Server Network Interface (SNI) Layer
Let’s start with the layer that makes it possible for SQL Server to communicate with external environments. It is called SQL Server Network Interface, and it contains SQL Server protocols. These are the main protocols currently associated with SQL Server:
- Shared memory
- Named pipes
- TCP/IP
- TDS (Tabular Data Stream)
Additionally, we can mention a protocol called Virtual Interface Adapter (VIA). However, it requires auxiliary hardware to be set up and is deprecated by Microsoft, being no longer available in the latest versions of SQL Server.
Now let’s learn about them in detail.
Shared Memory
Shared memory is the simplest protocol, used by default for local connections, when the client application and the SQL Server are located on the same machine.
Named Pipes
Named pipes is a protocol that can be used in case the client application and the SQL Server are connected via a local area network (LAN). By default, this protocol is disabled; you can enable it using the SQL Configuration Manager. The default port for named pipes in SQL Server is 445.
TCP/IP
The most important of the bunch, TCP/IP is the primary protocol that connects to SQL Server remotely, using an IP address and a port number. This is required when the client application and the SQL Server are installed on separate machines. The default TCP port utilized by SQL Server is 1433; however, it is recommended to change the port after installing SQL Server.
TDS (Tabular Data Stream)
Tabular Data Stream is an application-level protocol that is applied to transfer requests and responses between client applications and SQL Server systems. The client typically establishes a long-standing connection with the server. As soon as the connection is established, TDS messages become the means of communication between the client application and the database server. It is also possible for a server to act as a client, which requires a separate TDS connection.
Database Engine
Database engine is the primary component of the SQL Server architecture; it is used to store and process data, comprising two components: the relational engine and the storage engine. The relational engine is responsible for query processing, while the storage engine deals with storage and retrieval of data from storage systems. Now let’s have an in-depth overview of SQL Server engine architecture for both engine types.
Relational Engine
The relational database engine in SQL Server is also known as the query processor, because it determines the execution of queries as well as conducts memory management, thread and task management, and buffer management. In a nutshell, it requests data from the storage engine and processes the results to be returned to the user.
The relational engine includes 3 main components: Query Parser, Optimizer, and Query Executor.
CMD Parser (Query Parser)
The CMD Parser (also known as the Query Parser) is the component that receives the query, checks it for syntactic and semantic errors, and eventually generates a query tree.
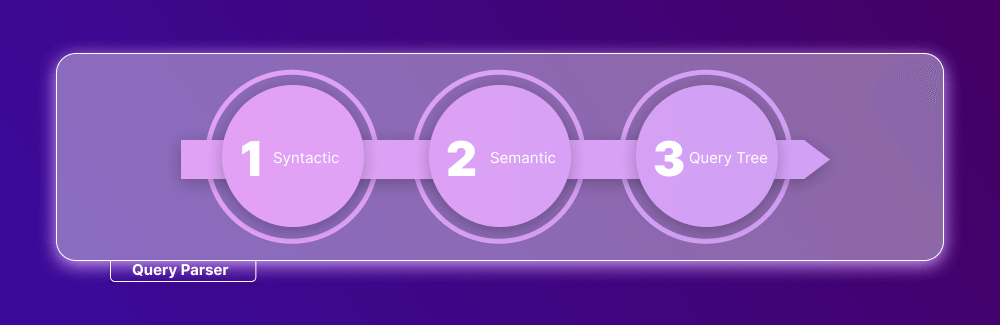
The syntactic check examines the user’s input query and checks whether it is correct syntax-wise. If the query does not comply with the SQL syntax in any way, the Parser returns an error message.
The semantic check, at its simplest, analyzes whether the queried table and column exist in the database schema. If the check is successful, the queried table is bound to the query. If the table/column does not exist, the Parser returns an error message. The complexity of the semantic check depends on the complexity of the query.
Finally, the Parser generates an execution tree for the query.
Optimizer
The Optimizer proceeds to create the cheapest execution plan for the query; that is, to minimize its run-time as much as possible. Mind you, not all queries need to be optimized; essentially, optimization is relevant for DML commands such as SELECT, INSERT, UPDATE, and DELETE, which are marked and sent to the Optimizer. The calculation of their cost is based on CPU and memory usage, as well as input/output needs.
The optimization comprises 3 phases.
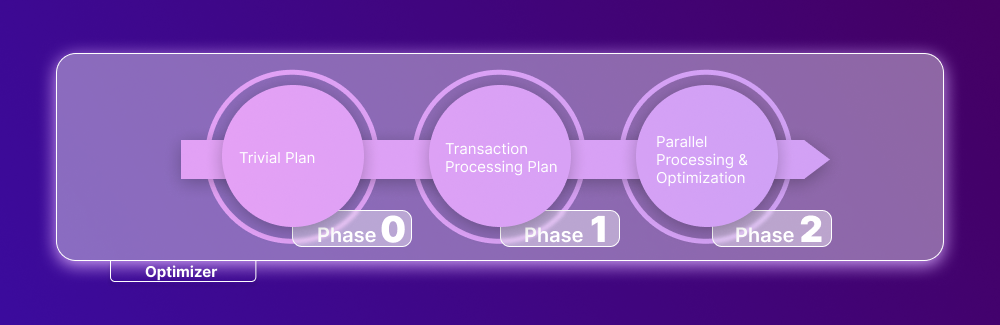
Phase 0: Trivial Plan (a.k.a. pre-optimization)
Sometimes there is no need to create an optimized plan—mainly, when the extra cost of searching for an optimized plan would not reduce the run-time. So first off, the Optimizer conducts search for a trivial plan. If there is none available, the Optimizer proceeds to the first phase.
Phase 1: Transaction Processing Plan
This step involves the search for an optimized transaction processing plan. First, there can be a simple plan that incorporates one index per table; if a simple plan is not found, the Optimizer searches for a more complex plan with multiple indexes per table.
Phase 2: Parallel Processing & Optimization
If the Optimizer fails to reduce the query run-time using the abovementioned methods, it proceeds to parallel processing, which depends on the processing capabilities and configuration of the user’s machine. In case it is not possible, the final optimization begins. Its goal is to find any other possible options to execute the query in the cheapest way.
Query Executor
Finally, the Query Executor calls the access method. Once the required data is retrieved from the storage engine, it proceeds to the Server Network Interface in the protocol layer and is sent to the user. That’s it!
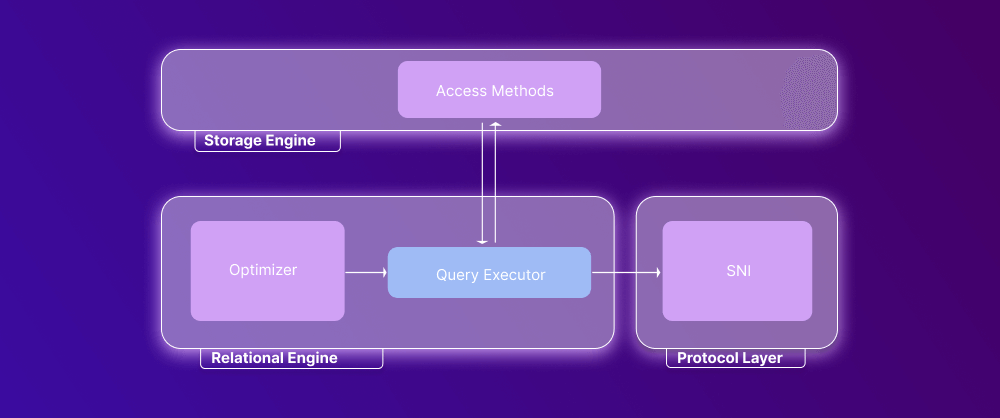
Storage Engine
The storage engine handles the storage and retrieval of actual data when requested by the user. It contains a buffer manager and a transaction manager that interact with data and log files according to the query.
Data File Types
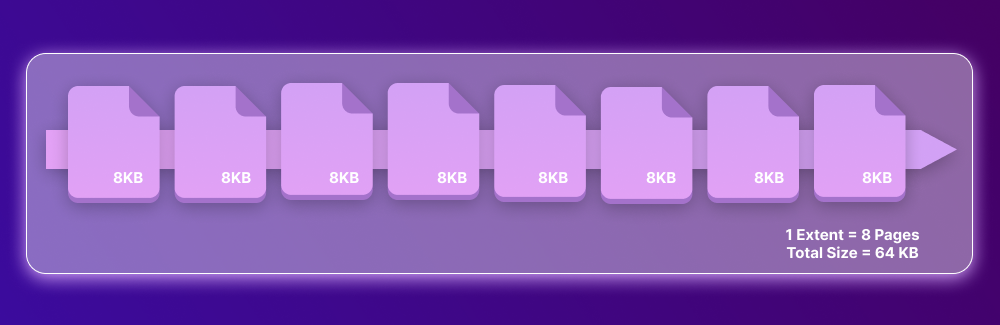
Before we proceed to types, let’s have a brief look at data files in general. SQL Server stores its data (e.g., user and system tables, indexes) and SQL code (e.g., stored procedures, views, functions) in data files of different types. Data files store data physically in pages; each page has a size of 8KB, which is the smallest data storage unit in SQL Server. A page includes a page header that contains metadata, such as page type, page number, used and free space, a pointer to the previous and subsequent pages, and so on. The size of a header is 96 bytes.
Data pages are logically grouped into extents, with 8 pages per extent.
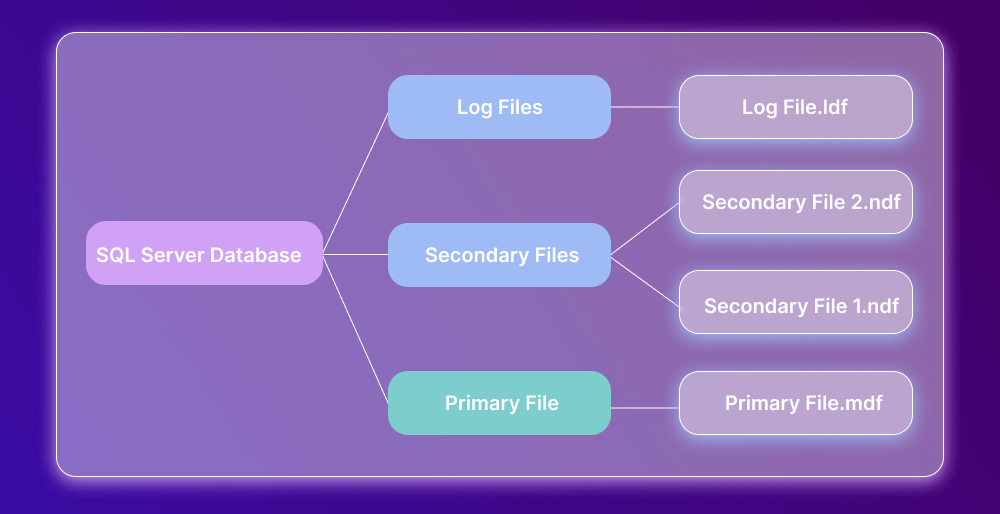
There are 3 data files to take note of.
Primary files
Every SQL Server database contains one primary file, which typically has an .mdf extension. It stores all the main data related to database tables, views, triggers, and other objects.
Secondary files
There can be multiple secondary files—or none at all. This is an optional type that contains user-specific data and has an .ndf extension.
Log files
Log files have an .ldf extension and are used for management and possible rollback of unwanted (and uncommitted) transactions. They can also be used to address possible vulnerabilities and implement corresponding security procedures as part of database hardening. If you’re restoring or migrating a database manually, understanding how to attach MDF and LDF files in SQL Server becomes essential, as these files contain the core data and transaction logs that make up a complete database state.
Access Method
Now let’s proceed to the SQL Server storage engine architecture. We will start with the access method, which defines whether the user’s query comprises a SELECT or non-SELECT statement. In the former case, the query is passed to the Buffer Manager for processing. In the latter case, it is passed to the Transaction Manager.

Buffer Manager
The SQL Server Buffer Manager handles core functions for the plan cache, data parsing, and dirty pages.
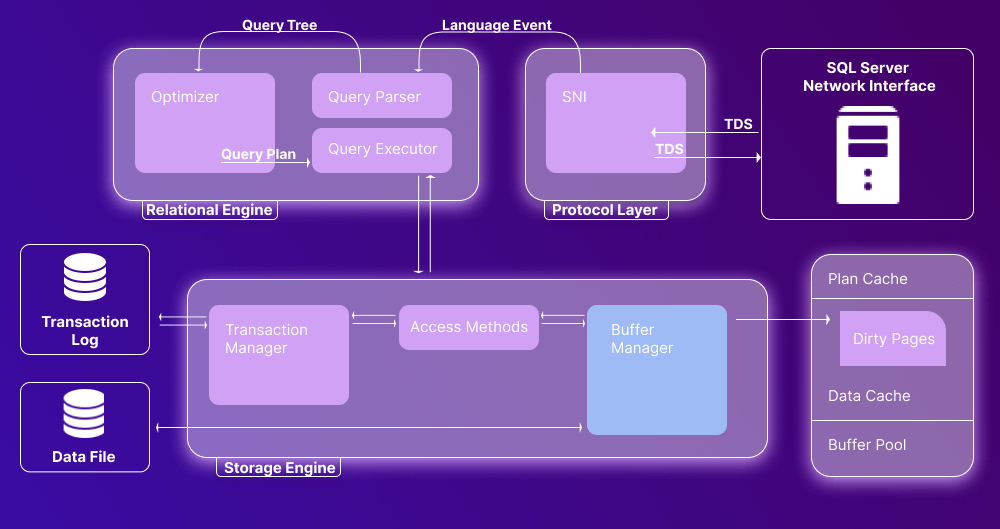
Plan Cache
First and foremost, the Manager checks whether there is an existing execution plan stored in the Plan Cache. If there is one, it is used along with the associated data.
Please note that the storage of a query execution plan in the Plan Cache ensures faster availability whenever your SQL Server receives the same query next time. This is especially useful for more complex queries.
Data Parsing
The Buffer Manager enables access to the requested data. If there is an execution plan in the Plan Cache, we have a case of soft parsing. The data is present in the Data Cache, and it is used by the Query Executor. This method boasts better performance because of the reduced number of I/O operations.
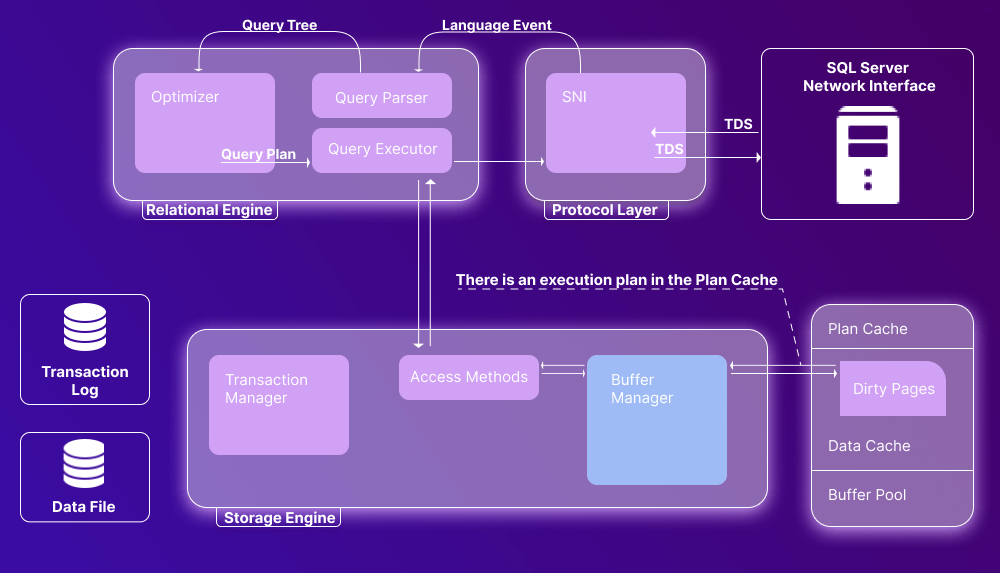
If there is no execution plan in the Plan Cache, we have a case of hard parsing, when data must be retrieved from the data storage.
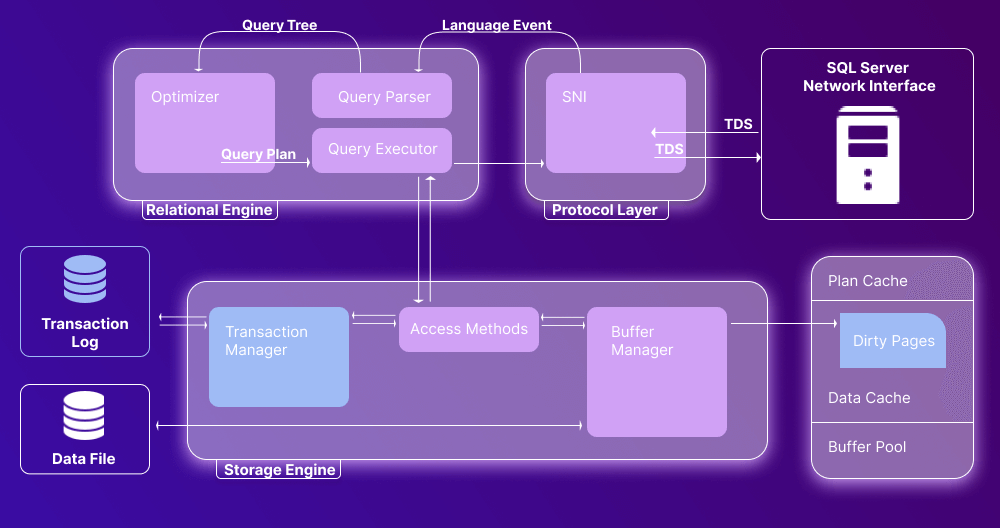
Transaction Manager
The Transaction Manager is invoked when the query comprises a non-SELECT statement. It manages the transaction using the Log Manager and the Lock Manager. The former keeps track of all updates in the system using transaction logs. The latter locks the involved data during each transaction, ensuring compliance with the ACID properties.
A special mention should be made here of write-ahead logging (WAL), which facilitates atomicity and durability (two of the ACID properties) in database systems. Its general principle is as follows: before your changes are written to the database, they are first recorded in the log, which, in turn, is written to stable storage. And if you have a detailed log of what you did, you can do it again and rebuild all of your data from scratch.
SQLOS
Now here are a few words about the role of SQLOS in the SQL Server architecture.
The SQL Server Operating System is an application layer that underlies the SQL Server database engine layer. It handles quite a few critical scheduling and resource management tasks:
- Scheduling of threads for CPU consumption and I/O completion
- Thread synchronization
- Memory allocation and consumption control (whenever Plan Cache, Lock Manager, or other components request memory from SQLOS)
- Tracking of extended events
- Exception handling (both user- and system-generated)
- Deadlock detection mechanism
- Hosting of services and memory management for external components
Afterword: Get the Best Tools for SQL Server Databases
If SQL Server Management Studio is not sufficient for your daily routine, you can enhance it with a bundle of apps and add-ins called dbForge SQL Tools. Its tools provide the following capabilities:
- IntelliSense-like SQL completion, refactoring, and formatting
- Schema comparison and synchronization
- Table data comparison and deployment of changes
- Visual query building without coding
- Realistic test data generation
- Integrated version control
- Generation of comprehensive database documentation
- Versatile data export and import
- Database and table design
- Visual modeling, including how to create database diagram in SQL Server
- Administration and security management
- Data analysis
dbForge SQL Tools also simplify practical tasks. For example, if you’re interested in learning how to attach MDF and LDF files in SQL Server, these tools guide you through the process with a more intuitive, user-friendly interface, making database recovery and migration easier to understand and perform.
Download SQL Tools for a free 30-day trial and see all of their capabilities in action!

Alternatively, if you are ready to embrace an all-in-one development environment for all operations, you can try dbForge Studio for SQL Server, which boasts a similar set of features integrated in a single product. Similarly, you can download it for a free 30-day trial.
