
SQL query optimization helps improve performance by minimizing execution time, resource usage, and server load. This guide covers practical techniques like indexing, query refactoring, and execution plan analysis. By applying these methods, you can effectively implement SQL optimization and benefit from:
- Faster response times for critical queries.
- Reduced server CPU and memory consumption.
- Smoother application performance under load.
- Improved SQL database optimization across workloads.
- Lower risk of blocking and deadlocks during peak usage.
These gains are achievable with a few core techniques used consistently. Let’s explore the most effective SQL query optimization tips, so you can write faster, leaner, and more reliable queries.
Table of contents- SQL query optimization basics
- 15 Query optimization tips for better performance
- Tip 1: Add missing indexes
- Tip 2: Check for unused indexes
- Tip 3: Avoid using multiple OR in the FILTER predicate
- Tip 4: Use wildcards at the end of a phrase only
- Tip 5: Avoid too many JOINs
- Tip 6: Avoid using SELECT DISTINCT
- Tip 7: Use SELECT fields instead of SELECT *
- Tip 8: Use TOP to sample query results
- Tip 9: Run the query during off-peak hours
- Tip 10: Minimize the usage of any query hint
- Tip 11: Minimize large write operations
- Tip 12: Create JOINs with INNER JOIN (not WHERE)
- Tip 13: Optimize subqueries and use common table expressions
- Tip 14: Try AI-powered query optimization
- Tip 15: Check the built-in query optimization features
- SQL query optimization best practices
- Conclusion
- FAQ
SQL query optimization basics
SQL query optimization refers to refining a query’s structure to reduce resource usage and improve speed. It’s a crucial step in improving SQL Server query performance and ensuring fast, consistent results.
A common example is when a developer rewrites a nested subquery into a JOIN to reduce execution time.
-- Less efficient
SELECT Name
FROM Employees
WHERE DepartmentID IN (SELECT ID FROM Departments WHERE Name = 'Sales');
-- Optimized version
SELECT e.Name
FROM Employees e
INNER JOIN Departments d ON e.DepartmentID = d.ID
WHERE d.Name = 'Sales'; In the first version, SQL Server may perform a full scan for each row. The second version allows the optimizer to perform an index seek, drastically cutting response time.
Other common optimizations include:
- Replacing SELECT * with specific columns
- Avoiding implicit data type conversions
- Indexing frequently filtered columns
The goal is to make a query work at scale. Optimized SQL speed up queries by 10x or more, especially under load.
15 Query optimization tips for better performance
Below is a breakdown of 15 proven strategies for tuning SQL queries, categorized by type and expected performance impact.
| Optimization tip | Category | Effect on performance | Tool / technique mentioned |
|---|---|---|---|
| Add missing indexes | Indexing | High | dbForge Studio, sys.dm_db_missing_index_* views |
| Check for unused indexes | Indexing | Medium | CAST(), filtered indexes |
| Avoid using multiple OR in the FILTER predicate | Query rewrite | High | UNION instead of OR |
| Use wildcards at the end of a phrase only | Query structure | Medium | LIKE with computed REVERSE() column |
| Avoid too many JOINs | Query structure | High | JOIN elimination |
| Avoid using SELECT DISTINCT | Query structure | Medium | EXISTS instead of JOIN + DISTINCT |
| Use SELECT fields instead of SELECT * | Query optimization | High | Covering indexes |
| Use TOP to sample query results | Query optimization | Medium | SELECT TOP |
| Run the query during off-peak hours | Execution strategy | Medium | WITH (NOLOCK), snapshot isolation |
| Minimize the usage of any query hint | Query optimization | Low | NOLOCK, RECOMPILE, OPTIMIZE FOR |
| Minimize large write operations | Data management | Medium | Filegroups, compression, partitioning |
| Create JOINs with INNER JOIN (not WHERE) | Query structure | Medium | INNER JOIN vs. WHERE |
| Optimize Subqueries & Use CTEs | Query structure / Optimization | Medium–High (depends on query complexity) | WITH CTE, temp tables, subqueries |
| Try AI-powered query optimization | AI assistance | High | ChatGPT or dbForge AI Assistant, ML-based optimization |
| Check the built-in query optimization features | Query optimization | High | SSMS execution plan viewer (SQL Server), dbForge Studio’s Query Profiler (SQL Server) |
Monitoring metrics can be used to evaluate query runtime, detect performance pitfalls, and show how they can be improved. In most cases, they may include:
- Execution plan: Detailing how the SQL Server query optimizer processes a statement, including operation order, index usage, and estimated costs to guide query tuning.
- Input/Output statistics: Showing the number of logical and physical reads performed during execution, helping identify inefficient data access and potential memory pressure.
- Buffer cache: Storing frequently accessed data pages in memory to reduce disk reads and improve response times.
- Latency: Measuring the time taken for queries or operations to complete, helping pinpoint bottlenecks in execution.
- Indexes: Providing optimized access paths to data, reducing full table scans and improving retrieval speed.
- Memory-optimized tables: Keeping data in memory to accelerate both read and write operations, particularly in high-throughput workloads.
Now, we’ll discuss the best SQL Server performance tuning practices and tips you may apply when writing SQL queries.
Tip 1: Add missing indexes
Missing indexes are one of the most common reasons for slow SQL Server performance. When the query optimizer can’t find a suitable index, it defaults to a table scan, which increases I/O load and slows down response times.
To address this, follow SQL Server index optimization best practices: regularly review execution plans and monitor missing index warnings using dynamic management views like sys.dm_db_missing_index_details.
You can also use tools such as dbForge Studio for SQL Server, which highlights missing indexes through its Query Profiler interface.
Example
-- View missing index suggestions
SELECT *
FROM sys.dm_db_missing_index_details;
-- Example: adding a helpful non-clustered index
CREATE NONCLUSTERED INDEX IX_Customers_LastName
ON Customers (LastName); Adding a missing index like this can drastically reduce query times, often by 50–90%, depending on the dataset and query complexity.
Understanding the difference between an index seek and a table scan is essential in indexes and performance tuning. Index seeks are more efficient and use fewer resources, whereas table scans indicate a lack of proper indexing.
Tip 2: Check for unused indexes
You may encounter a situation where indexes exist but are not being used. One of the reasons for that might be implicit data type conversion.
Example
SELECT *
FROM TestTable
WHERE IntColumn = '1'; When executing this query, SQL Server will perform implicit data type conversion, i.e. convert int data to varchar and run the comparison only after that. In this case, indexes won’t be used. How can you avoid this? We recommend using the CAST() function that converts a value of any type into a specified datatype. Look at the query below.
SELECT *
FROM TestTable
WHERE IntColumn = CAST(@char AS INT);Let’s study one more example.
SELECT *
FROM TestTable
WHERE DATEPART(YEAR, SomeMyDate) = '2021';In this case, implicit data type conversion will take place too, and the indexes won’t be used. To avoid this, we can optimize the query like in the code below.
SELECT *
FROM TestTable
WHERE SomeDate >= '20210101'
AND SomeDate < '20220101'Filtered indexes can affect performance too. Suppose, we have an index on the Customer table.
CREATE UNIQUE NONCLUSTERED INDEX IX ON Customer (MembershipCode)
WHERE MembershipCode IS NOT NULL;The index won’t work for the following query:
SELECT *
FROM Customer
WHERE MembershipCode = '258410';To make use of the index, you’ll need to optimize the query.
Example
SELECT *
FROM Customer
WHERE MembershipCode = '258410'
AND MembershipCode IS NOT NULL;Tip 3: Avoid using multiple OR in the FILTER predicate
Using multiple OR conditions in the WHERE clause can significantly degrade query performance. This is because SQL Server’s optimizer may not be able to use indexes effectively across all OR conditions, often defaulting to a full table scan.
Why does this happen? When you write a query like below, SQL Server treats each condition separately.
SELECT *
FROM Users
WHERE Name = @P OR Login = @P; Even if one column has an index, the OR logic breaks the optimization path, forcing the engine to scan the entire table.
Here are better alternatives:
- Apply UNION to split queries, allowing each part to use indexes independently.
SELECT * FROM Users WHERE Name = @P
UNION
SELECT * FROM Users WHERE Login = @P; - Use IN when possible, especially if all conditions target the same column.
SELECT * FROM Orders WHERE Status IN ('Pending', 'Processing', 'Shipped'); - Ensure proper indexing on all referenced columns, especially if you’re using multiple OR branches across different fields.
Performance insight: Full table scans caused by poorly structured OR logic can increase I/O and CPU usage, especially on large tables. Rewriting the query helps the optimizer perform index seeks instead of scans, resulting in much faster execution.
Tip 4: Use wildcards at the end of a phrase only
To maintain index efficiency, avoid placing wildcards (%) at the beginning of a search string. Leading wildcards force SQL Server to perform an index scan instead of an index seek, significantly increasing the time it takes to retrieve results, especially on large tables.
Why it matters
Consider the two queries below.
-- Causes index scan (slow)
SELECT * FROM Customers WHERE LastName LIKE '%son';
-- Uses index seek (fast)
SELECT * FROM Customers WHERE LastName LIKE 'John%'; In the first example, SQL Server cannot predict where in the index tree to begin the search, so it scans the entire index. In the second, it can seek directly to rows starting with “John”, making it much faster and more efficient.
How to optimize searches from the end
If your use case demands searching by suffix (e.g., last 4 digits of a card number), you can create a computed column using REVERSE() to preserve index usage.
Examples
ALTER TABLE Customers
ADD ReversedCardNo AS REVERSE(CardNo) PERSISTED;
CREATE INDEX IX_ReversedCardNo ON Customers(ReversedCardNo);
-- Now search like this:
SELECT * FROM Customers
WHERE ReversedCardNo LIKE REVERSE('1234%'); This technique helps optimize SQL code while retaining flexible search patterns, without sacrificing performance.
Tip 5: Avoid too many JOINs
Excessive JOINs, especially across large tables, can drastically slow down queries. SQL software like SQL Server use the query planner to decide how to combine tables, often resorting to nested loop joins or hash joins depending on indexes, row counts, and filters.
When too many joins are used (typically more than 3–5), the planner has to evaluate an increasingly complex number of join paths. This can overload memory, exhaust the join buffer, and lead to long execution times.
What happens internally:
- Nested loop joins are common but inefficient when the inner table lacks proper indexing.
- SQL Server may generate bloated execution plans that cause temporary table spooling, hash joins, or even Cartesian products.
- In the worst case, queries perform full scans and compound I/O costs across all joined tables.
How to optimize:
- Keep joins below 5 unless absolutely necessary.
- Remove unnecessary relationships or subqueries where the same data can be fetched more efficiently.
- Where possible, denormalize data for reporting or analytics layers to reduce join depth.
- Split complex joins into temporary tables or CTEs to reduce execution load and improve SQL query speed.
Here’s a simplified example.
-- Inefficient: 6+ joins can confuse the planner
SELECT *
FROM Orders o
JOIN Customers c ON o.CustomerID = c.ID
JOIN Employees e ON o.EmployeeID = e.ID
JOIN Regions r ON e.RegionID = r.ID
JOIN Products p ON o.ProductID = p.ID
JOIN Categories cat ON p.CategoryID = cat.ID
JOIN Vendors v ON p.VendorID = v.ID;
-- Optimized: break into logical stages or pre-aggregate
-- (e.g., use CTEs or pre-joined views where possible) Keeping queries lean and targeted leads to more efficient SQL queries and faster execution across the board.
Tip 6: Avoid using SELECT DISTINCT
SELECT DISTINCT can help eliminate duplicate rows, but often at a high cost. When used indiscriminately, this approach forces SQL Server to perform a sorting operation or stream aggregate to deduplicate results. This can dramatically slow down performance, especially on large datasets.
When DISTINCT hurts performance
If you’re seeing duplicates, it’s usually a sign of a bad JOIN condition or unintended row multiplication. Below is a common example.
-- Problematic: duplicates caused by overly broad join
SELECT DISTINCT o.OrderID, c.Name
FROM Orders o
JOIN Customers c ON o.CustomerID = c.ID
JOIN Feedback f ON f.OrderID = o.OrderID; In this case, multiple feedback entries per order inflate the result set. Applying DISTINCT hides the symptom but won’t address the cause.
Here are better alternatives:
- Fix the JOIN logic: Limit joins using proper filters or EXISTS clauses.
- Use GROUP BY: More controllable and often faster for deduplication.
- Apply aggregation: Summarize or limit records at the source rather than cleaning after retrieval.
-- Preferred: use GROUP BY for clarity and control
SELECT o.OrderID, c.Name
FROM Orders o
JOIN Customers c ON o.CustomerID = c.ID
GROUP BY o.OrderID, c.Name; Unless your use case absolutely requires deduplication, avoid SELECT DISTINCT as a shortcut. It rarely aligns with the basics of query optimization, and often masks deeper query design flaws.
Tip 7: Use SELECT fields instead of SELECT *
The SELECT statement is used to retrieve data from the database. In the case of large databases, it is not recommended to retrieve all data because this will take more resources on querying a huge volume of data.
If we execute the following query, we will retrieve all data from the Users table, including, for example, users’ avatar pictures. The result table will contain lots of data and will take too much memory and CPU usage.
SELECT
*
FROM Users;Instead, you can specify the exact columns you need to get data from, thus, saving database resources. In this case, SQL Server will retrieve only the required data, and the query will have lower cost.
Example
SELECT
FirstName
,LastName
,Email
,Login
FROM Users;If you need to retrieve this data regularly, for example, for authentication purposes, we recommend using covering indexes, the biggest advantage of which is that they contain all the fields required by query and can significantly improve query performance and guarantee better results.
CREATE NONCLUSTERED INDEX IDX_Users_Covering ON Users
INCLUDE (FirstName, LastName, Email, Login)Tip 8: Use TOP to sample query results
The SELECT TOP command is used to set a limit on the number of records to be returned from the database. To make sure that your query will output the required result, you can use this command to fetch several rows as a sample.
For example, take the query from the previous section and define the limit of 5 records in the result set.
SELECT TOP 5
p.BusinessEntityID
,p.FirstName
,p.LastName
,p.Title
FROM Person.Person p
WHERE p.FirstName LIKE 'And%';This query will retrieve only 5 records matching the condition as shown below.
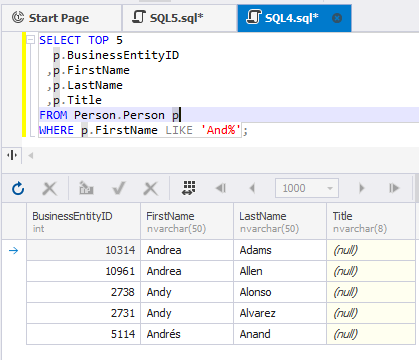
For more information about TOP, refer to Using the SELECT TOP Clause in SQL Server.
Tip 9: Run the query during off-peak hours
Another SQL tuning technique is to schedule the query execution at off-peak hours, especially if you need to run multiple SELECT queries from large tables or execute complex queries with nested subqueries, looping queries, etc.
If you are running a heavy query against a database, SQL Server locks the tables you are working with to prevent concurrent use of resources by different transactions. That means that other users are not able to work with those tables. Thus, executing heavy queries at peak times leads not only to server overload but also to restricting other users’ access to certain amounts of data. One of the popular mechanisms to avoid this is to use the WITH (NOLOCK) hint.
This method allows the user to retrieve the data without being affected by the locks. The biggest drawback of using WITH (NOLOCK) is that it may result in working with dirty data. We recommend that users should give preference to snapshot isolation which helps avoid data locking by using row versioning and guarantees that each transaction sees a consistent snapshot of the database.
Tip 10: Minimize the usage of any query hint
Unless you’re sure what you’re doing, avoid relying on query hints. These directives override the SQL Server optimizer’s judgment, which can degrade performance, cause plan regressions, or even break business logic, especially when the underlying data changes.
When query hints go wrong
Let’s use an example.
SELECT *
FROM Sales
WHERE Region = 'West'
OPTION (FORCESEEK); -- Forces index usage even when it's not optimal Here, FORCESEEK forces the query to use a specific index, even if a table scan or hash join would be faster for the data distribution at runtime. If the index becomes fragmented or the data grows, this hint may lead to longer execution times or I/O spikes.
Other common hints include:
- OPTION (HASH JOIN): forces a specific join strategy.
- OPTION (RECOMPILE): disables plan reuse and increases CPU.
- WITH (NOLOCK): allows dirty reads and risks data inconsistency.
While these can solve short-term issues, they should only be used after careful testing with tools like the dbForge Query Profiler, which shows how hints affect the execution plan.
Best practice
Use query hints only as a last resort, and document the reason. Test your query across real-world data volumes and monitor performance over time. Otherwise, you may lock your query into a suboptimal path that no longer suits the data.
There are many different ways to optimize SQL queries, hints is just one of them, and often not the best.
Tip 11: Minimize large write operations
Large UPDATE, DELETE, or INSERT operations can slow query performance, increase lock contention, and cause excessive transaction log growth. Without precautions, these operations may block other queries and impact overall server responsiveness.
How to minimize the impact?
Do the following:
- Use batching to control transaction size: Breaking the workload into smaller chunks helps reduce locks and log usage.
-- Batched delete to reduce lock contention
WHILE 1 = 1
BEGIN
DELETE TOP (1000)
FROM Orders
WHERE Status = 'Cancelled';
IF @@ROWCOUNT = 0 BREAK;
END - Disable non-clustered indexes temporarily: Before massive writes, drop or disable non-critical indexes, then rebuild them afterward to improve speed.
- Use table partitioning for targeted writes: Partitioning allows you to isolate and truncate large subsets of data efficiently, especially for time-based data.
- Apply minimal logging with TABLOCK or BULK INSERT: When inserting large volumes of data, using bulk load operations can significantly cut down I/O overhead.
- Avoid triggers during high-volume writes: If possible, turn off triggers that perform row-by-row validations or logging during a bulk operation.
Tip: For ETL processes, consider writing to staging tables first, then validating and merging into the live table.
Following these strategies can improve SQL query performance on large tables and result in faster SQL queries even under heavy data load.
Tip 12: Create JOINs with INNER JOIN (not WHERE)
The SQL INNER JOIN statement returns all matching rows from joined tables, while the WHERE clause filters the resulting rows based on the specified condition. Retrieving data from multiple tables based on the WHERE keyword condition is called NON-ANSI JOINs while INNER JOIN belongs to ANSI JOINs.
It does not matter for SQL Server how you write the query – using ANSI or NON-ANSI joins – it’s just much easier to understand and analyze queries written using ANSI joins. You can clearly see where the JOIN conditions and the WHERE filters are, whether you missed any JOIN or filter predicates, whether you joined the required tables, etc.
Let’s see how to optimize a SQL query with INNER JOIN on a particular example. We are going to retrieve data from the tables HumanResources.Department and HumanResources.EmployeeDepartmentHistory where DepartmentIDs are the same.
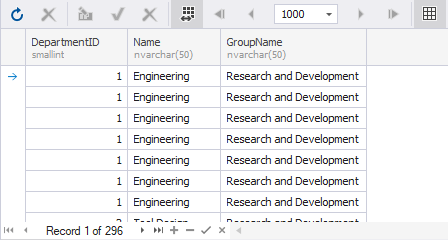
First, execute the SELECT statement with the INNER JOIN type.
SELECT
d.DepartmentID
,d.Name
,d.GroupName
FROM HumanResources.Department d
INNER JOIN HumanResources.EmployeeDepartmentHistory edh
ON d.DepartmentID = edh.DepartmentIDThen, use the WHERE clause instead of INNER JOIN to join the tables in the SELECT statement.
SELECT
d.Name
,d.GroupName
,d.DepartmentID
FROM HumanResources.Department d
,HumanResources.EmployeeDepartmentHistory edh
WHERE d.DepartmentID = edh.DepartmentIDBoth queries will output the following result:
Tip 13: Optimize subqueries and use CTEs
Deeply nested subqueries affect both readability and performance. They force the optimizer to recalculate the same logic and make debugging a nightmare.
The fix: replace them with Common Table Expressions (CTEs). A CTE defines a result set once and lets you reuse it, keeping your SQL modular and easier to maintain. They’re also the right tool for recursive or hierarchical queries.
Example
-- Inefficient: repeated subqueries
SELECT o.OrderID, o.CustomerID
FROM Orders o
WHERE o.CustomerID IN (SELECT CustomerID FROM VIP_Customers)
AND o.OrderID NOT IN (SELECT OrderID FROM CancelledOrders);
-- Optimized: CTEs reduce redundancy
WITH VIP AS (
SELECT CustomerID FROM VIP_Customers
),
Cancelled AS (
SELECT OrderID FROM CancelledOrders
)
SELECT o.OrderID, o.CustomerID
FROM Orders o
JOIN VIP v ON o.CustomerID = v.CustomerID
LEFT JOIN Cancelled c ON o.OrderID = c.OrderID
WHERE c.OrderID IS NULL;
CTEs improve readability and cut down redundant computation, especially when the same logic is reused across a query. They’re also the right choice for recursive or hierarchical data. But if you stack too many complex CTEs, execution plans can bloat and memory usage spikes.
In such cases, staging or temp tables are a safer choice, since they let you index intermediate results and control resource usage more effectively. Subqueries, on the other hand, make sense for simple, single-use conditions inside a WHERE or HAVING clause, where defining a full CTE would only add overhead.
Tip 14: Try AI-powered query optimization
Modern databases generate massive volumes of execution data, and tuning them manually is no longer scalable. That’s where AI-powered query optimization comes in.
Tools like dbForge AI Assistant and Azure SQL Intelligent Query Processing use cost-based optimization, adaptive plans, and auto-indexing to analyze SQL performance in real time and suggest instant improvements.
In a nutshell, AI can help you with:
- Rewriting inefficient queries based on execution patterns.
- Detecting missing indexes and suggesting the best columns to index.
- Identifying outdated or inefficient hints and replacing them with better alternatives.
- Simulating multiple execution plans and picking the optimal one.
- Predicting performance regression before deployment.
For example, dbForge AI Assistant can highlight an expensive query segment in the plan and recommend alternatives using natural language guidance. Likewise, Azure SQL’s automatic tuning can fix plan regressions and apply index changes without manual intervention.
AI-powered optimization is especially useful in large or evolving systems where query patterns shift often, and manual tuning becomes time-consuming or error-prone. Moreover, these tools integrate with modern DevOps pipelines and can automate tuning at scale.
If you’re working with dynamic workloads or production-critical databases, using AI can significantly improve SQL tuning velocity and consistency.
Tip 15: Check the built-in query optimization features
Before applying advanced tuning techniques, start with the tools your database already provides. These built-in query optimization tools give you a clear view of how queries behave, and where they go wrong.
Step 1: Visualize the execution plan
Use tools like:
- SSMS execution plan viewer (SQL Server): Visualizes the execution plan graph and highlights I/O cost, table scans, and missing indexes.
- dbForge Query Profiler (SQL Server): Offers in-depth plan analysis, resource tracking, and visual comparison between query runs.
- MySQL EXPLAIN / EXPLAIN ANALYZE: Breaks down how queries are executed, showing join type, index usage, and estimated row counts.
- dbForge Studio for MySQL: Provides a graphical Explain Plan that transforms raw EXPLAIN output into a visual tree, highlights join order and access types, compares plans before and after query changes, and saves plans for later review.
Step 2: Interpret and act
Once you’ve identified inefficiencies:
- Create missing indexes suggested in the plan.
- Rewrite queries that trigger nested loops or full scans.
- Restructure joins based on estimated row count differences.
- Use these tools to validate improvements after tuning.
By routinely using these tools to optimize SQL queries, you gain a repeatable way to detect and fix problems, without relying on guesswork.
SQL query optimization best practices
To consistently write high-performance SQL queries, follow these 5 core best practices:
- Always analyze the execution plan: Use tools like SSMS, dbForge solutions, or MySQL EXPLAIN to visualize the query execution path. Focus on I/O cost, missing indexes, and operators like table scans or nested loops. Refer back to Tip 15 for tools and techniques.
- Avoid unnecessary columns: Don’t use SELECT *. Query only the columns you need. This reduces memory usage, network load, and improves cache efficiency. See Tip 7 for more on selective querying.
- Minimize joins and simplify query design: Follow query design patterns that reduce complexity. Break down large JOIN chains into smaller steps or use denormalized views when possible. Covered in Tip 5.
- Use indexes strategically: Ensure commonly filtered or joined columns are indexed, but avoid over-indexing. Monitor index usage regularly and clean up unused ones. Explore indexing in Tip 1 and Tip 2.
- Profile and test under real-world load: Optimize based on real execution stats, not assumptions. Profile queries during peak traffic to ensure consistent performance. Consider AI-powered tools from Tip 14 to assist.
By applying these SQL Server best practices for performance, you can improve execution speed, reduce server strain, and build scalable systems that run efficiently in production.
For further learning, see how to run an SQL query and explore SQL Server query optimization tips.
Conclusion
In the article, we have covered a lot of fine-tuning techniques and tips to improve performance. We hope that they will work for you and help you avoid any performance issues that may arise.
Also, we suggest that you should try a free fully-functional 30-day trial version of dbForge Studio for SQL Server to work with SQL queries effectively.
Watch the video to get to know the powerful capabilities of our all-in-one SQL Server GUI Tool.
FAQ
What are the optimization techniques in SQL?
Key optimization techniques in SQL include indexing for faster data retrieval, query restructuring for higher efficiency, execution plan analysis to identify bottlenecks, partitioning to distribute data for faster access, and the use of proper JOINs.
How do you optimize performance in SQL?
To optimize performance in SQL, consider analyzing execution plans to detect slow operations, using indexes for faster searches, JOINs and WHERE clause optimization, and batch processing usage. Also, it is recommended to avoid nested subqueries when possible and to monitor server performance metrics like CPU and memory usage.
What are the three major steps in query optimization?
The three major steps in query optimization include parsing and translation, which are often used to validate SQL queries and convert them to internal format; the optimization step to compare multiple execution plans; and the evaluation step, which is necessary to choose the optimal plan.
What is the SQL Server Query Optimizer?
SQL Server Query Optimizer is a component that creates query execution plans, analyzes efficiency, and chooses a query plan using a set of heuristics to balance compilation time and plan optimality in order to perform queries with the minimum amount of resources used.
Which is the best optimization technique?
There is no single best query optimization technique since it depends on the use case. However, indexing, execution plan analysis, and query restructuring often provide the most impact.
What is database performance tuning?
Database performance tuning is the process of optimizing database operations to improve speed and efficiency. This process often includes query optimization, index tuning, memory and CPU management, and optimization of data storage and retrieval.