
All relational database management systems, including PostgreSQL, provide specialized means and techniques to get the necessary information quickly and accurately. These means include indexes — database objects that are used to increase database performance, allowing the database server to find and retrieve specific rows faster. Indexes can also be used to help maintain data integrity, since tables with unique indexes cannot have rows with identical keys.
PostgreSQL offers several index types, but the principle is the same: any index creates a pointer to a particular table row. As a result, you can access the necessary entries with no need to read the entire table. Still, indexes mean additional overhead to database systems, which means they should be applied reasonably.
In any case, indexes are necessary for all modern relational database management systems, including PostgreSQL. That is why we would like to tell you everything you need to know about them.

Contents
- PostgreSQL index types
- Unique indexes
- Partial indexes
- Expression indexes
- Multi-column indexes
- When should indexes be avoided?
- PostgreSQL CREATE INDEX command
- Examples: CREATE INDEX via dbForge Studio for PostgreSQL
- The DROP INDEX command
- How to delete indexes in dbForge Studio for PostgreSQL
PostgreSQL index types
There are six types of PostgreSQL indexes, which are also called methods, because they define the way each particular index handles its task. They also determine the syntax specifics. These six types are as follows:
- B-Tree
- Hash
- Generalized Inverted Index (GIN)
- Generalized Search Tree (GiST)
- SP-GiST
- Block Range Index (BRIN)
Our new blog post provides more information on creating indexes in PostgreSQL for optimal database performance.
B-Tree
B-Tree is the default index type for the CREATE INDEX command in PostgreSQL. It is compatible with all data types, and it can be used, for instance, to retrieve NULL values and work with caching. B-Tree is the most common index type, suitable for most cases.
Hash
Hash is a specific index type applied only if the equality condition = is being used in the query. It is called hash because it stores a 32-bit hash code derived from the indexed column value. Hash indexes are rarely used in PostgreSQL because it is necessary to rebuild them manually after crashes, and they can cause issues during transactions.
Generalized Inverted Index (GIN)
GIN (Generalized Inverted Index) is suitable for mapping multiple values to one row. The most common case for applying the GIN index comprises operations with data types such as arrays, range types, JSON, and also for full-text search. Note that the GIN index will be slower for INSERT and UPDATE operations.
Generalized Search Tree (GiST)
The GiST (Generalized Search Tree) index allows using the tree structure to index schemes for new data types—for instance, geometric data types and network address data. GiST is also useful if you have queries that are not indexable with B-Tree. It is applicable for full-text search as well.
SP-GiST
The SP-GiST (Space-Partitioned GiST) index is similar to GiST, but it uses a partitioned search tree to index non-balanced data structures, thus simplifying the SEARCH and INSERT operations. The common characteristic of these structures is that they repeatedly divide the search space into partitions that do not have to be of the same size.
Block Range Index (BRIN)
BRIN (Block Range Index) applies to large tables where specific columns have a natural correlation with their physical location in the table. A block range is a group of pages that are physically adjacent in the table; BRIN indexes store summary information—page number along with minimum and maximum values—for each block range.
Only the B-Tree index type does not require any additional specification in the CREATE INDEX statement, as it is the default one in PostgreSQL. To create an index of any other type, you need to specify it – hash, gist, spgist, gin, or brin.
Besides the abovementioned index types, we can single out several index subsets.
Unique indexes
A unique index makes sure that your table does not have more than one row with the same value. This index type is very helpful when it comes to maintaining data integrity and high performance in PostgreSQL.
Partial indexes
A partial index is an index with a WHERE clause, which covers a particular subset of data in a table. It is rather small, works faster, and can be used alongside other indexes on more complex queries.
Expression indexes
Expression indexes are meant for queries matching on a function or modification of data. PostgreSQL makes it possible to index the result of the function and make this search as efficient as search by raw data values.
Multi-column indexes
An index can be created on more than one table column. In this case, we are dealing with a multi-column index, which is limited to 32 columns (the limit can be changed in pg_config_manual.h). Note that only B-Tree, GIN, GiST, and BRIN types support multi-column indexes.
When should indexes be avoided?
One more thing before we proceed to the CREATE INDEX command: although indexes are meant to improve database performance, there are cases when they can slow it down and thus should best be avoided:
- You should not use indexes on small tables.
- You should not use indexes on tables that face large and frequent batch UPDATE and INSERT operations.
- You should not use indexes on columns that have many NULL values.
- You should not use indexes on columns that are frequently edited.
PostgreSQL CREATE INDEX command
You create a unique PostgreSQL index automatically when defining the primary key or unique constraint for your table. By default, it is a B-Tree index.
You must take the following steps to create an index:
- Indicate the index name after the clause. Make sure you choose a meaningful name that you can remember easily.
- Define the name of the table to which you will apply the index.
- Optional: Specify the index type if you need one other than B-Tree – Hash, GiST, GIN, SP-GiST, or BRIN.
- Optional: List the column(s) to store in that index and specify the sort order by applying
ASCorDESC. Note thatASCis the default one, and if you don’t specify the order explicitly, PostgreSQL will sort the data in ascending order. You can also useNULLS FIRSTorNULLS LASTin the statement to define whether you want NULLS to be placed before or after non-NULL values.
Thus, the basic CREATE INDEX statement in PostgreSQL is as follows:
CREATE [UNIQUE] INDEX index_name
ON table_name(column_name, [...]);Now we would like to go beyond the basics and show you a few examples of CREATE INDEX statements that can be written and executed in the top IDE for PostgreSQL databases – dbForge Studio for PostgreSQL.
Examples: using CREATE INDEX in dbForge Studio PostgreSQL
dbForge Studio for PostgreSQL is an advanced IDE that accelerates your daily SQL coding, as well as streamlines data editing and reporting. In the Studio, you can write and execute your queries in a regular SQL document. Let’s take a look at several examples.
What if you want to specify additional parameters? Let’s take a look at this example:
CREATE INDEX films_index
ON actor
(
films DESC
);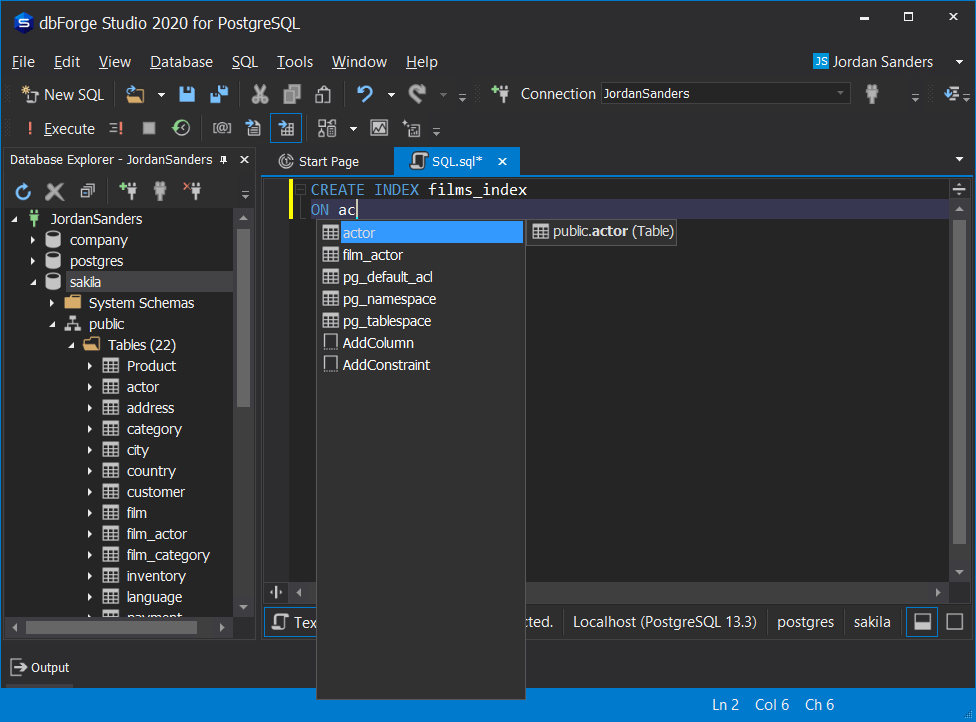
With this statement, we will create a new index named films_index applied to the actor table. The data will get sorted in descending order. Note how the SQL editor in dbForge Studio gives prompts on the table name.
Or maybe you want to rename your PostgreSQL index? For this purpose, you can use the RENAME statement:
ALTER INDEX [ IF EXISTS ] index_name RENAME TO new_nameLet’s illustrate this with the following example:
ALTER INDEX [ IF EXISTS ] films_index RENAME TO new_films_index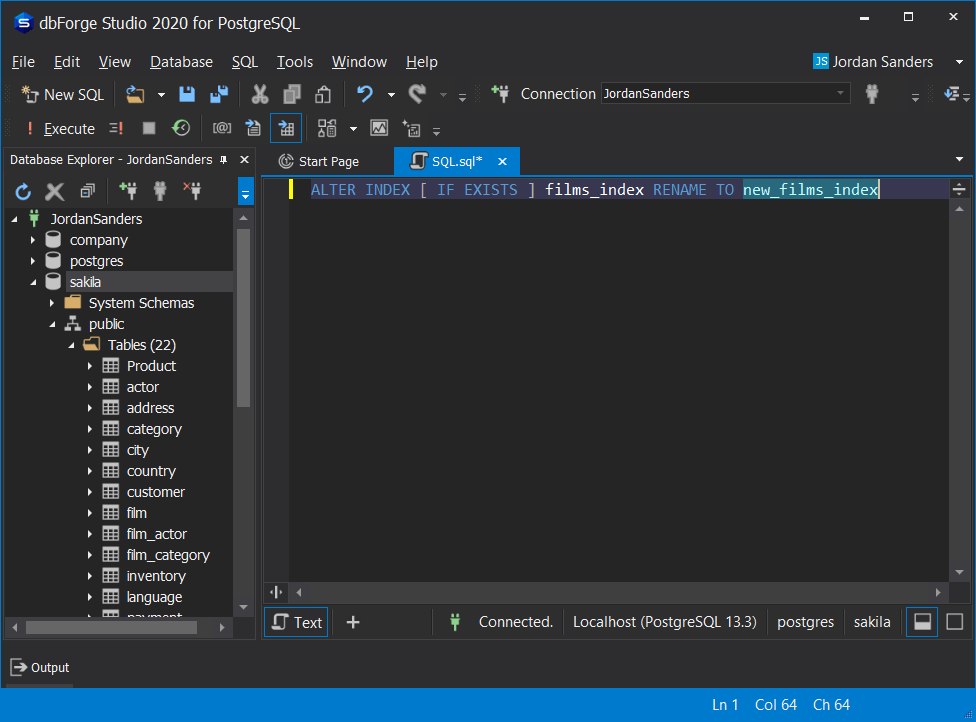
This is the standard method that will rename the required index and will not affect the data in any way.
You should also pay attention to applying IF EXISTS and IF NOT EXISTS in PostgreSQL. For instance, the latter parameter checks whether the index with the specified name exists; and if it does, you will be notified. However, it does not mean that the existing index is the same or at least similar to the index you want to create. Be careful when using these parameters.
How to create a unique index for a single column
Now let’s see how a unique index can be created for a single column. In the example below, a library needs to add mobile phone numbers to the database of its readers. All of these mobile phone numbers must be unique for all users. Thus, we need a unique index for the respective column:
CREATE UNIQUE INDEX idx_readers_mobile_phone
ON readers(mobile_phone);How to create a unique index for multiple columns
It is possible to create a unique PostgreSQL index for multiple columns. It works similarly to the single-column index; the only difference is that we need a combination of columns to maintain uniqueness.
Let’s assume that multiple users of the library can have identical last names. However, they will not have the same mobile phone numbers. So, we must use a unique index on the last_name and mobile_phone columns. Thus, creating a unique index for multiple columns will be as follows:
CREATE UNIQUE INDEX idx_readers_personal_phone
ON readers(mobile_phone, last_name);The DROP INDEX command
The DROP INDEX command removes an existing index from your database system. Note that you must be the owner of the index in order to remove it. Here is the common syntax for this command is:
DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] index_name [, ...] [ CASCADE | RESTRICT ]This syntax has several parameters to take note of:
CONCURRENTLYdrops your index without locking out concurrent SELECTs, INSERTs, UPDATEs, and DELETEs on the table with the index. A regular DROP INDEX acquires a lock on the table, blocking other accesses until the drop is completed. And if you useCONCURRENTLY, the command waits until the conflicting transactions are completed.CASCADEautomatically drops the objects that depend on this index.RESTRICTdoes not drop the index if there are objects that depend on it.
Note that after you drop an index, database performance may be either improved or slowed down.
How to delete indexes in dbForge Studio for PostgreSQL
Similarly to our previous examples, let’s drop our index films_index:
DROP INDEX films_index;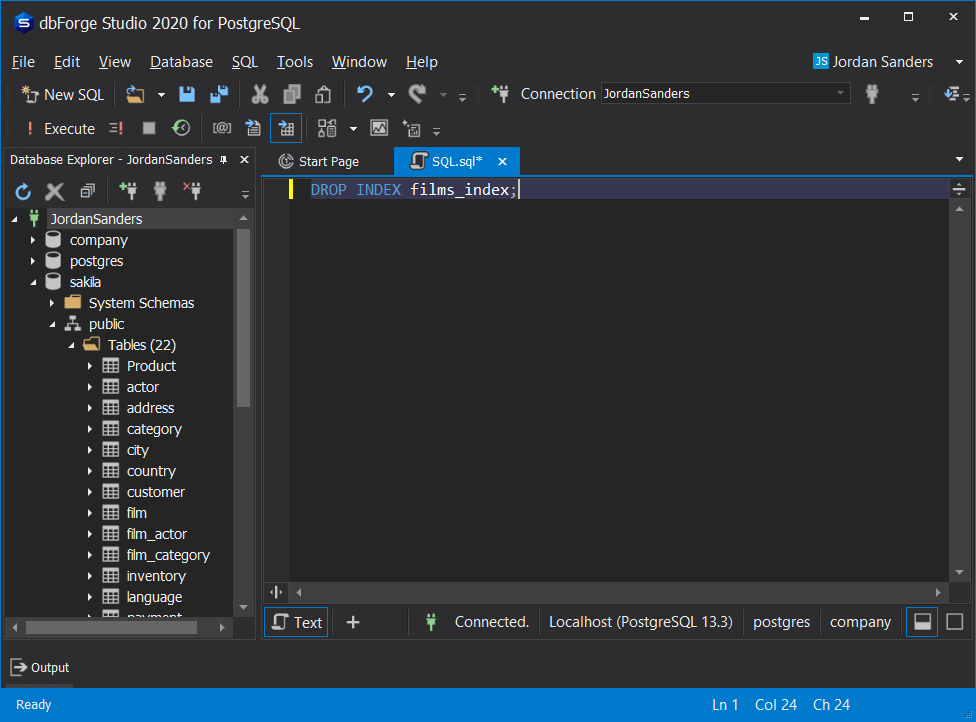
As you could see, indexes are essential to PostgreSQL, and you need to understand their specifics properly to be able to create any particular index that best suits your particular case. Besides, the use of specialized database software will simplify your tasks significantly.
dbForge Studio for PostgreSQL is the best example of the database software in question, and its capabilities go far beyond effective work with indexes. Download it for a FREE 30-day trial and check all of them in action.