
Databases are essential for storing data and providing user access to specific information. This fundamental task becomes increasingly complex as databases expand, data volumes swell, and data processing times lengthen. For quick and efficient data retrieval from large databases, we use indexes.
An SQL index functions similarly to an index in a book or journal, referring to data within tables. This article will explore SQL indexes, enhancing your understanding of database management.

Contents
- Understanding the types of SQL indexes
- How SQL indexes work
- Strategic considerations for indexing
- Managing index fragmentation and performance
- Introducing dbForge Index Manager for SQL Server
- Conclusion
Understanding the types of SQL indexes
An SQL index is a database component that speeds up data retrieval from a specific table or view. It is a small, optimized lookup table designed to quickly find the required records. It contains keys derived from specific column(s) of a table or view and organizes them in a B-tree structure:
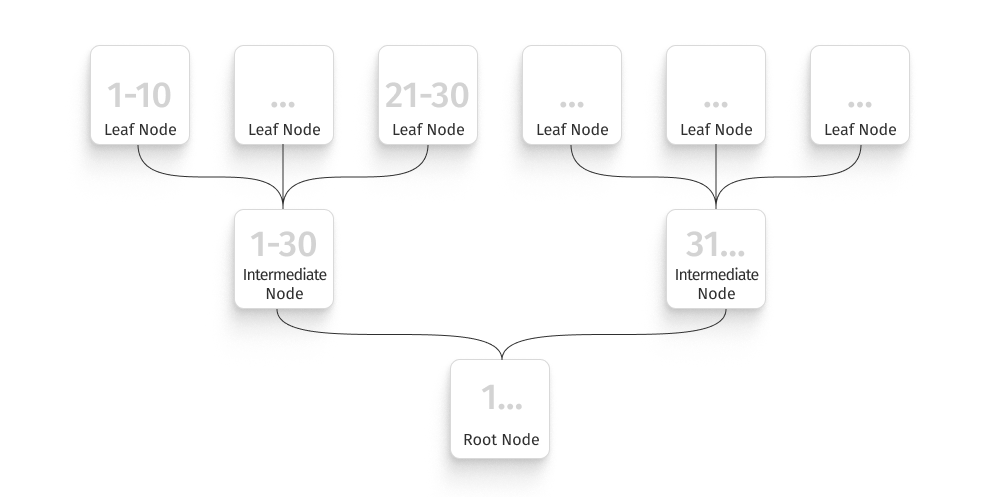
- Root Node: This top-level node contains the main keys that point to the next level (intermediate nodes). Its primary role is to divide data into larger segments.
- Intermediate Nodes: Positioned beneath the root node, these nodes contain keys that further divide the data into smaller segments, leading to other intermediate nodes or leaf nodes, depending on the tree’s depth.
- Leaf Nodes: Found at the bottom level of the B-tree, these nodes contain the keys and pointers to the corresponding data records. Leaf nodes are the actual indexes that optimize data retrieval.
There are two common types of indexes: clustered and nonclustered ones.
- Clustered Index: This index type arranges and stores data rows in a table or view in a specific physical order. A table with a clustered index is referred to as a clustered table. Only one clustered index can be created because data rows can only be physically stored in one order. The primary key column is usually set as the default clustered index.
- Nonclustered Index: This index reorders selected columns. It contains the key values and pointers to specific data rows. Unlike the clustered index, the nonclustered index is saved separately from the data, making it possible to have multiple nonclustered indexes in a single table.
Both clustered and nonclustered indexes can be unique.
A unique index ensures that duplicate values are not present in the index key column(s). If the index is built on a single column, all values in that column must be unique. If it’s built across multiple columns, each combination of values across those columns must be unique.
Any attempt to insert a duplicate value into a column with a unique index will fail, triggering an error.
The below table showcases the differences between the clustered and nonclustered indexes:
| Clustered Index | Nonclustered Index | |
| Physical Storage | Physically sorts and stores data rows in the table | Stores logical pointers to the data rows |
| Data Organization | Reorders the table based on the index keys | Does not affect the physical ordering of the table |
| Uniqueness | Is mostly unique for better efficiency | Can be unique or non-unique |
| Performance Impact | Makes querying faster as data is physically sorted | Is slower than clustered index due to extra pointer lookups |
| Space Consumption | Does not require additional storage space | Requires additional storage space |
| Primary Use Case | Querying columns that are frequently used in sorting and grouping | Selective queries that are used to locate specific individual rows |
| Maintenance | Can lead to fragmentation; requires regular maintenance | Requires maintenance for optimal performance |
How SQL indexes work
When we query a table without an index, the query often needs to scan all rows until it finds those that meet the conditions. This process is highly inefficient, requiring significant time and resources. As the table grows, such queries become increasingly problematic.
Indexing helps by establishing an order in an unordered table. While indexes don’t physically reorder rows, they guide the database in creating a data structure that stores references to information needed for efficient querying as follows:
- The index creates a table with columns for search conditions and a pointer that references rows containing additional information in the memory.
- The data structure (the index table) is sorted to improve query efficiency.
- The query uses the index to locate the relevant rows.
- The index points to the memory locations containing the necessary information.
As a result, a table with an index allows a query to search significantly fewer rows.
Indexes are primarily used to improve performance and are not visible to users. In SQL, you can manage indexes using the CREATE INDEX command to create an index and the DROP INDEX command to remove an index. Let us delve deeper into these commands.
CREATE INDEX
The CREATE INDEX command is used for creating both clustered and nonclustered indexes in SQL.
The following command creates a nonclustered, non-unique index:
CREATE INDEX index_name
ON table_name (column1, column2, ...);Note: The column order is crucial for nonclustered indexes that contain multiple columns. Always place the columns you query most frequently at the beginning of the list.
The command to create a unique index (an index that does not allow duplicate records in columns) is:
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2, ...);DROP INDEX
To remove an index from the table, use the DROP INDEX command:
DROP INDEX table_name.index_name;Note: Only the index owners or users with the DROP ANY INDEX privilege can remove indexes.
Modern database management tools, particularly those with graphical user interfaces (GUIs), make handling indexes more intuitive. In this article, we highlight dbForge Studio for SQL Server as an example of software that simplifies all database tasks. This integrated development environment (IDE) also streamlines index management.
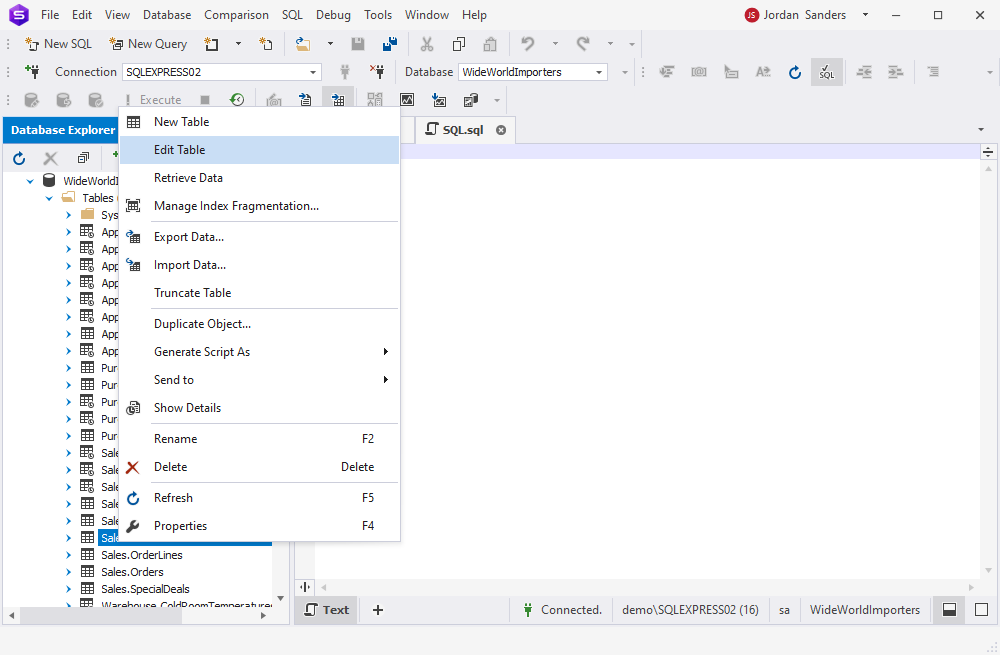
The graphical Table Editor in dbForge Studio allows users to create and manage indexes with just a few clicks. To use this feature, create a new table or edit an existing one from Database Explorer.
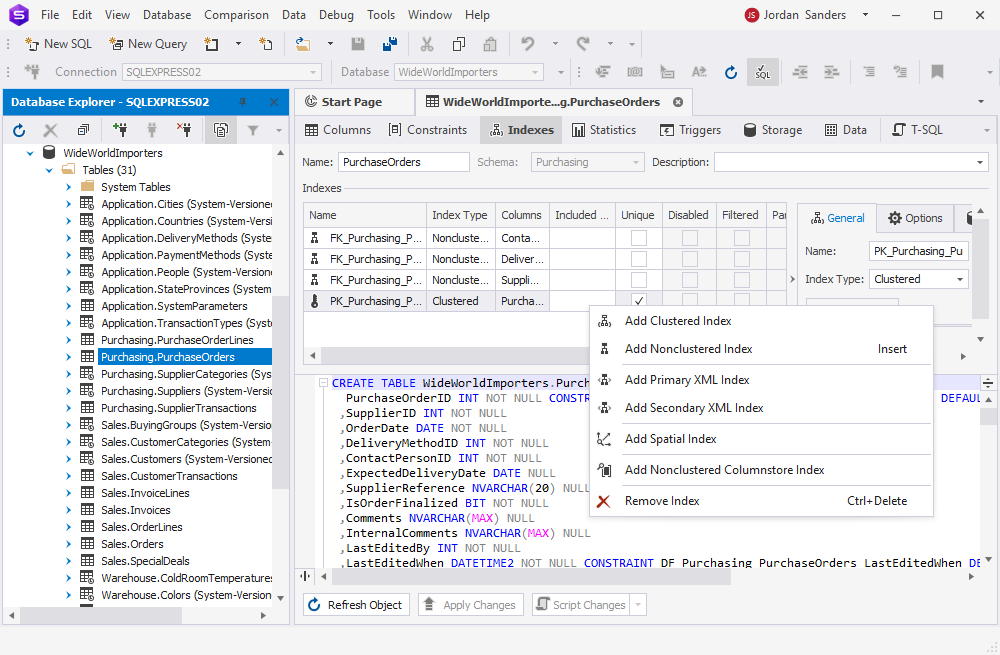
Then, navigate to the Indexes tab within Table Editor to configure the indexes.
Learn how to delete a column in SQL to drop columns completely.
Strategic considerations for indexing
Indexes are necessary performance-enhancing tools. However, they are separate database objects. Moreover, not all tables require them.
The more columns and rows are included in an index, the more space it consumes, and indexes can become large and complex. Furthermore, they add complexity to the table and to the process of database design and administration. Additionally, any updates to table data require corresponding index updates, which can affect performance and write operations.
Therefore, it’s essential to carefully assess each table before implementing an index and to select the appropriate index type and number.
Below are common scenarios for when to use or avoid indexes in SQL tables:
When to implement an index:
- Columns that have a broad range of values
- Columns that contain few NULLs
- Columns frequently used in WHERE clauses or JOINs
When to avoid an index:
- Small tables generally don’t need additional indexing
- Frequently updated columns usually shouldn’t have indexes
- Columns not often used in WHERE clauses don’t benefit much from indexing
Special considerations for clustered indexes:
Be cautious when establishing a clustered index. Ideally, use a clustered index on columns with unique values, like a primary key. The clustered index physically organizes data, which affects storage.
Managing index fragmentation and performance
SQL Server index fragmentation is a common issue that arises over time. It occurs when the logical order of an index no longer matches its physical structure. The primary factors contributing to this problem include:
- Inserting/Updating Rows: New rows may be inserted at locations that don’t align with the logical order specified in the index. Similarly, updated rows might move, disrupting the index’s structure.
- Deleting Rows: Deletion creates gaps in the index. If these gaps aren’t filled by new data, fragmentation can increase.
- Improper Index Reorganization or Rebuilding: While these operations are intended to maintain proper index structure, they can inadvertently cause issues if not executed correctly.
Monitoring index fragmentation
Monitoring database indexes is a routine and necessary task for administrators. SQL Server provides a built-in tool to detect index fragmentation: sys.dm_db_index_physical_stats().
The sys.dm_db_index_physical_stats() function in SQL Server allows the administrators to identify index fragmentation and the level of the issue.
The basic query is:
SELECT *
FROM sys.dm_db_index_physical_stats(NULL, NULL, NULL, NULL, NULL)
WHERE avg_fragmentation_in_percent > 0
ORDER BY avg_fragmentation_in_percent DESC;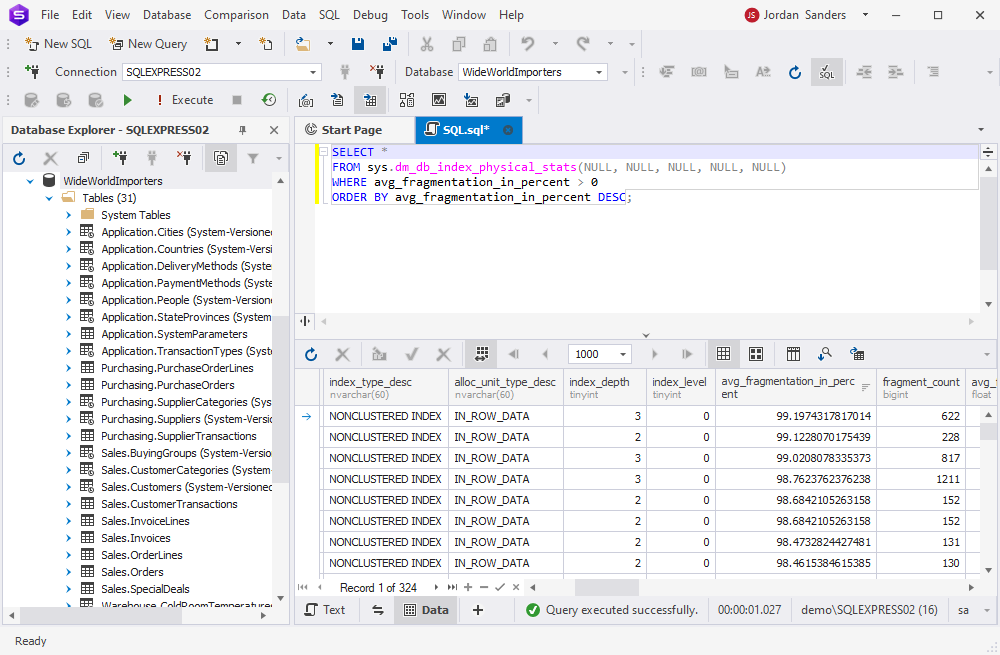
This query reveals the fragmentation level. Depending on the fragmentation percentage, administrators can choose between two corrective actions: rebuilding or reorganizing the index.
SQL index maintenance: rebuilding and reorganizing
Index rebuilding and index reorganization are distinct operations. Each serves a specific purpose. Applying both to the same index is unnecessary because it doubles the effort and resource consumption without offering any benefits.
Index Rebuilding
Rebuilding an index involves removing the old index and replacing it with a new one. It is recommended for severely fragmented indexes, typically above 30%.
The command is:
ALTER INDEX NAME_OF_INDEX ON NAME_OF_TABLE REBUILDIndex rebuilding is resource-intensive but it delivers the best results by addressing all forms of fragmentation and optimizing the index structure.
Index Reorganization
Reorganizing an index reorders the bottom-level (leaf-level) nodes to match the logical order specified in the index, making them more compact. This approach is suitable for indexes with 10-30% fragmentation:
The command is:
ALTER INDEX NAME_OF_INDEX ON NAME_OF_TABLE REORGANIZEReorganization requires fewer resources than rebuilding and is best for handling moderate fragmentation.
Regular monitoring of index fragmentation helps the database administrators address issues proactively. This can be done manually or through automation. Tools like dbForge Studio for SQL Server provide comprehensive features to monitor, detect, and resolve index fragmentation issues.
Introducing dbForge Index Manager for SQL Server
Detecting and fixing index fragmentation issues can be tedious, especially manual operations. However, specialized tools can simplify, accelerate, and automate these tasks. Earlier, we mentioned dbForge Studio for SQL Server and its Table Editor. Another valuable feature is Index Manager, a smart tool for identifying and fixing index fragmentation.
Index Manager provides a comprehensive overview of your database and its objects, collects index fragmentation statistics, and identifies the indexes that require maintenance, providing the percentage of fragmentation and recommendations for rebuilding or reorganizing each index. You can use the tool to resolve all fragmentation issues immediately via the visual interface.
To launch the tool, choose Tasks from the Database menu and proceed to Manage Index Fragmentation.
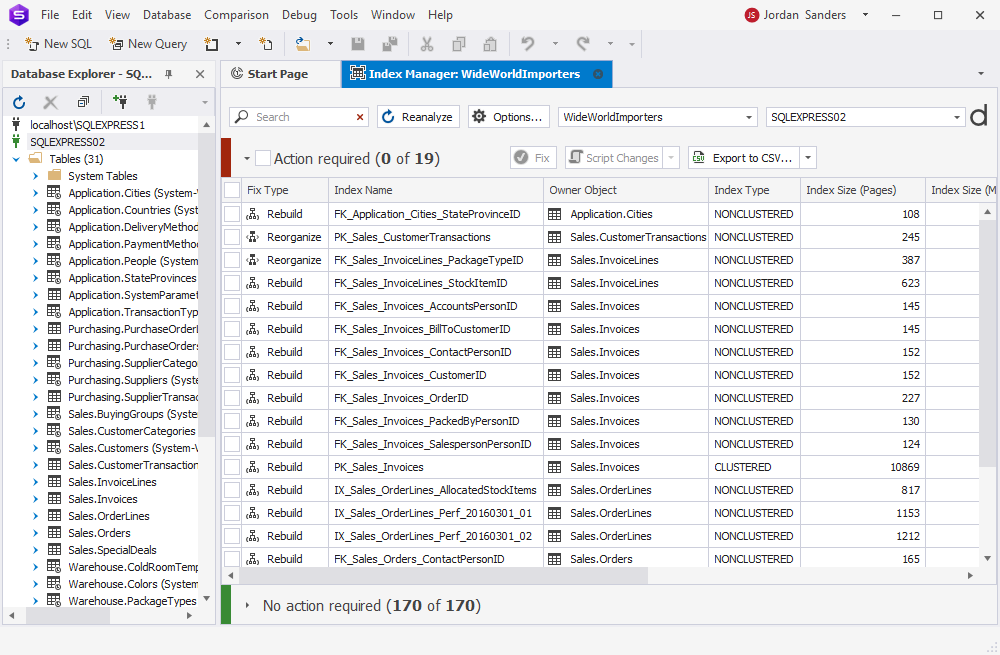
To resolve fragmentation issues visually, select the indexes and click Fix.
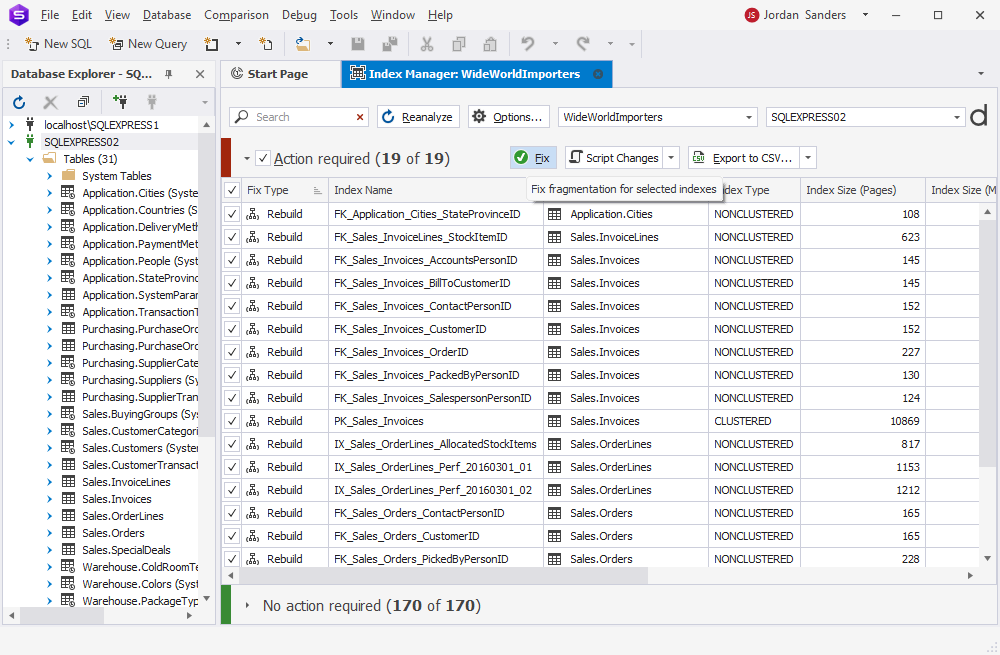
Navigate to Options to check and reconfigure (if necessary) defragmentation parameters.
Note: The Save Command Line option allows you to generate a .bat file for automating index maintenance tasks through the Command Line utility.
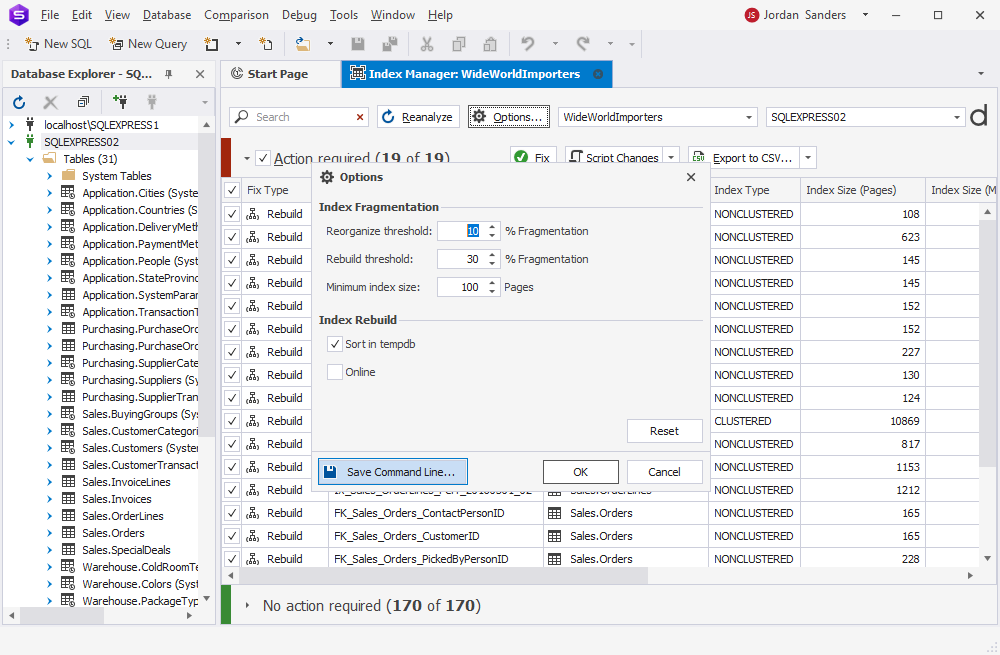
You can also save the scripts generated for index rebuilding and reuse them later.
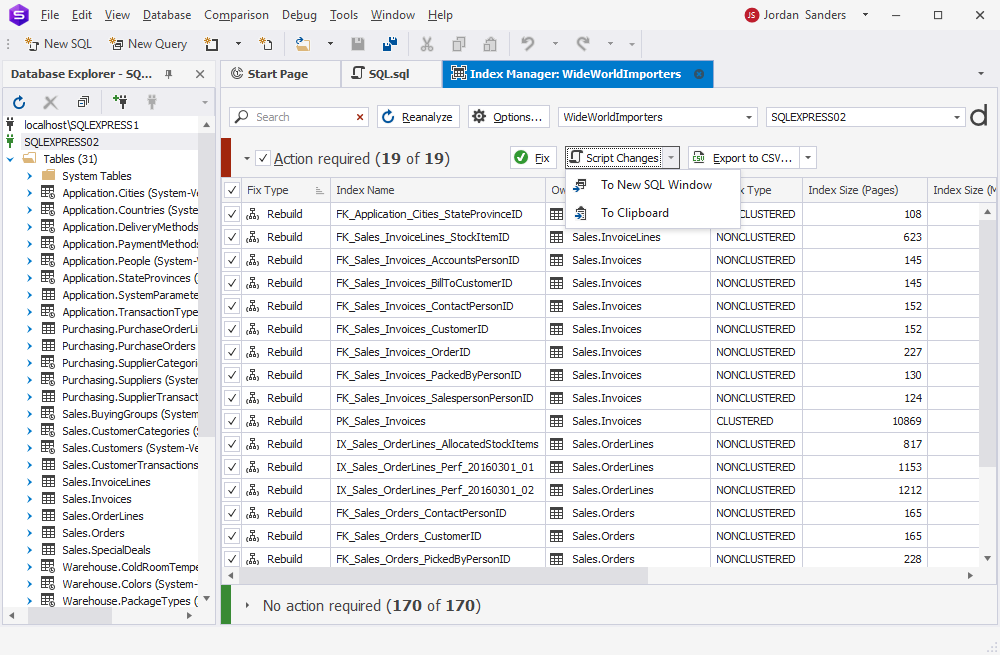
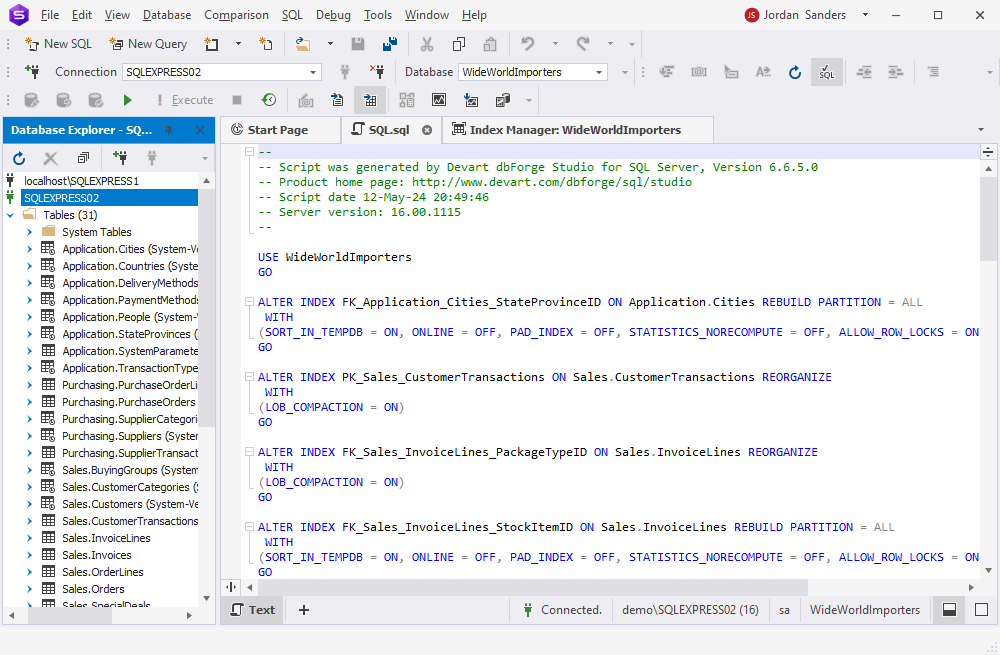
These scripts can further be used to automatically scan and fix fragmented indexes on schedule using the command line.
dbForge Studio for SQL Server is a more powerful alternative to SQL Server Management Studio (SSMS), and many experts prefer it. However, if you prefer SSMS, you can still benefit by integrating an add-in called dbForge SQL Index Manager, which similarly enhances SSMS’s index management and defragmentation capabilities.
As an SSMS add-in, Index Manager integrates seamlessly, introducing advanced functionality to the familiar interface. After installation, new options become available directly within SSMS. The integrated Index Manager offers you all the functionality necessary to detect and resolve fragmented indexes both manually and automatically, through the built-in command-line support.
Conclusion
SQL indexes are essential performance tools that improve data organization and enable faster data search and retrieval from databases. As databases grow, implementing indexes becomes crucial for optimal performance.
However, over time, SQL indexes can become fragmented, leading to performance issues and excessive resource consumption. Therefore, it’s crucial to monitor existing indexes and address fragmentation promptly. Ideally, this should be a regular, automated routine.
Tasks like configuring indexes, monitoring them, detecting fragmentation issues, and resolving those problems through index rebuilding or reorganization can be straightforward with dbForge products, particularly dbForge Studio for SQL Server. You can explore this powerful solution with a fully functional 30-day free trial, which provides an excellent opportunity to see firsthand how it handles your data management challenges.