
The article describes the basics of a database schema, the advantages of using schemas, and covers how to create, modify, and delete them in a SQL Server database.
Prior to developing a database, a developer should thoroughly think of the database layout and objects to be included and how they should be organized logically. This is where they start creating a database schema that helps visualize and structure the SQL Server database and its relationships before implementing them.
Contents
- Concept of SQL Server schemas
- Advantages of using database schemas
- Best practices for schema design
- How to get a list of schemas and their owners in a database
- How to create a schema in the current database
- How to create a table within a schema
- How to alter a schema
- How to drop a schema
- Try it yourself with dbForge Studio for SQL Server
- Further learning
Concept of SQL Server schemas
A database schema is a collection of logically connected database objects and elements, such as tables, stored procedures, views, functions, triggers, indexes, etc. The schema describes how data should be organized and how the table relationships should be built within a particular database.
In schemas, you can grant access rights and permissions, manage security, create, modify, or drop databases, and manipulate data. A user who is associated with a schema is called a schema owner, and you can create either one or multiple schema owners. A schema is the owner of database objects and can be associated only with one database. However, the database can have multiple schemas.
In SQL Server, schemas can be logical (the ones that explain how the data can be organized in tables) and physical (the ones that explain how data can be stored).
By default, SQL Server provides dbo, guest, sys, and INFORMATION_SCHEMA. When creating a new user, dbo will be considered as the default schema for this user.
See also: What is the difference between a schema and a database?
Advantages of using database schemas
The overall benefits that you get with well-designed schemas are rather obvious yet rather compelling. First off, you can ensure quick data lookup, retrieval, management, and analysis, keeping sensitive data secure and selectively accessible. You can avoid data redundancy (or at least keep it to a minimum) and thus make your databases easy to administer. As a result, you maintain proper consistency and integrity of your data.
If we move from general ideas to more specific aspects of database management, we can outline the following:
- You can have several users per schema
- The same schema can be used with different databases
- Database objects can be quickly moved between schemas
- Database objects can be managed in logical groups
- You control access and apply user permissions to protect database objects efficiently at a schema level
- Any user can be removed without impact on user-dependent database elements
- It it easy to transfer ownership between schemas
Best practices for schema design
Database schema design might as well be the cornerstone of database management, and there are quite a few best practices that we can’t help but share with you. Some are more obvious, some are less, but still, once you start building a data model, it’s always good to have them all at hand.
1. Adopt SQL naming conventions that remain consistent across your database. Don’t use reserved words for table, column, or field names, as they can trigger syntax errors. Avoid special characters; they will either complicate your work or simply won’t be valid. Keep things simple and short where possible, and try using singular nouns for table names.
2. Another thing you need to do when creating an entity-relationship diagram for your database is define the required data types and sizes for each of your columns. The latter is no less vital—if you opt for a lesser capacity, the software that utilizes your database will be plagued with errors. If you opt for an excessive capacity, there will be troubles with performance.
3. Make sure every table has a primary key that will uniquely identify each row in it. If you have a table without a primary key, your data model will be in trouble, as you will most likely get duplicate rows in the said table. In turn, this may lead to inconsistent data retrieval, and the integrity of your data will suffer greatly.
4. Build relationships between tables with foreign keys. It’s another condition that helps you maintain referential integrity across your entire database, avoid unnecessary errors, and improve the performance of data retrieval.
5. Since we’ve touched upon the issue of performance, we can’t leave indexes unmentioned. Indexes help you locate the exact required rows within a table without the need to search through all of them. It’s fast, convenient, and thus it’s good for performance. Although you can make new indexes when your database is already up and running, it is a common practice to put indexes on primary and foreign keys beforehand, when designing a new database. Normally, it’s made automatically by the database engine, but if it isn’t, you should create indexes manually.
6. Once your database schema grows large enough to become difficult to read and understand, you might need to perform partitioning—in other words, group your database objects. For instance, if a single database is accessed by different apps, you can make separate partitions, each of which conveniently contains the objects that belong to a certain app. As for the objects that are used by all of your apps, they can be as well assigned a dedicated partition.
7. Next, you need to take care of security and use encryption for sensitive data (e.g., passwords or personally identifiable information).
8. Security is just as well tied to proper user management. Remember to give each user the minimum set of privileges required to perform their tasks.
9. Last but not least, don’t forget to document your database. If your database schema will be accessed, viewed, and managed by other users, documentation is the optimal way to get acquainted with it, containing extensive information about the overall database structure, specific database objects (including their types, owners, descriptions, properties, constraints, and DDL scripts), and inter-object dependencies.
Alongside documentation, using a SQL schema compare tool can help track changes across environments, verify consistency, and streamline deployment by highlighting structural differences between versions of your schema.
To move on, let’s take a closer look at how to retrieve SQL database schemas along with their owners, as well as how to create, alter, and drop them. We’ll illustrate our examples using dbForge Studio for SQL Server, a high-end SQL Server IDE that helps you deal with database development, administration, and management much more efficiently and productively.
To better understand the database schema and relationships between objects, use database diagram design tool for SQL Server.
How to get a list of schemas and their owners in a database
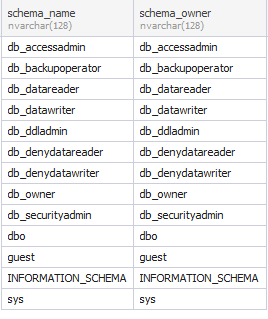
To retrieve all schemas and their respective owners from the current database ordered by the schema name, execute the following query by using sys.schemas:
SELECT
s.name AS schema_name,
u.name AS schema_owner
FROM
sys.schemas s
INNER JOIN sys.sysusers u ON u.uid = s.principal_id
ORDER BY
s.name;The output will list all database schemas in the current database.
How to create a schema in the current database
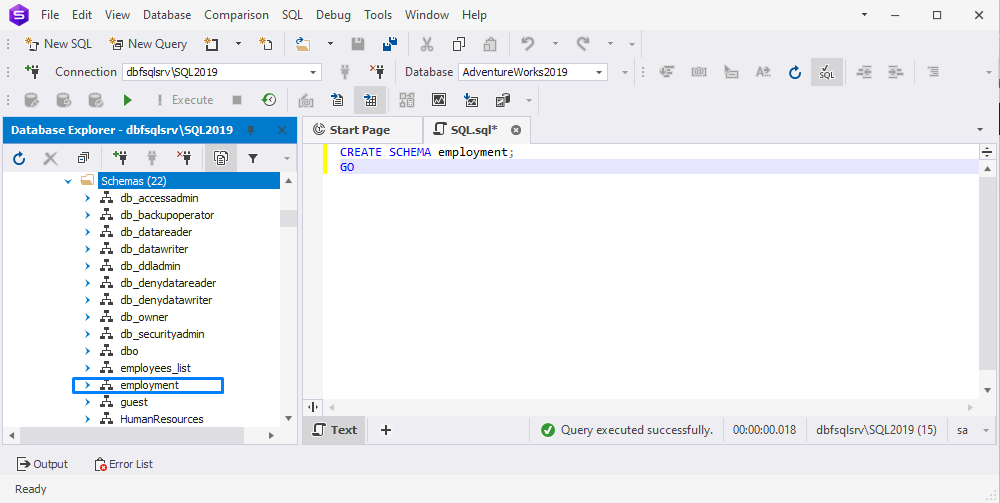
Now, let’s see how to create a new schema in the current SQL Server database using the CREATE SCHEMA statement. For example, we want to create the employment schema in the AdventureWorks2019 database.
CREATE SCHEMA employment;
GOIn the output, the new schema will be displayed in the list of available schemas for the current database.
See also: SQL database design basics with examples
See also: Database diagram (ERD) design tool for SQL Server
How to create a table within a schema
After we created the schema, we can try to add a new table (for example, vacancies) to the employment schema. For this, use the CREATE TABLE statement.
CREATE TABLE employment.vacancies(
vacancy_id INT PRIMARY KEY IDENTITY,
description VARCHAR(200),
created_at DATETIME2 NOT NULL
);In addition, other database objects can be created using the corresponding CREATE statements. If you do not specify a schema, SQL Server will use the default schema.
Keep in mind that database objects cannot be created in sys and INFORMATION_SCHEMA.
Now, let’s examine how to modify and drop schemas in SQL Server.
How to alter a schema
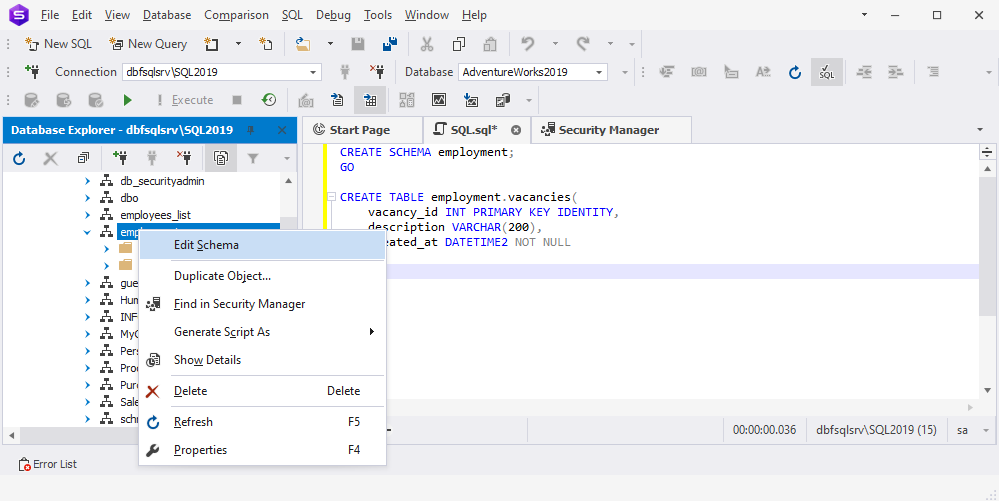
The following example shows how to define a new schema owner from the existing owners. For this, open dbForge Studio for SQL Server. In Database Explorer, right-click the schema you want to alter and select Edit Schema.
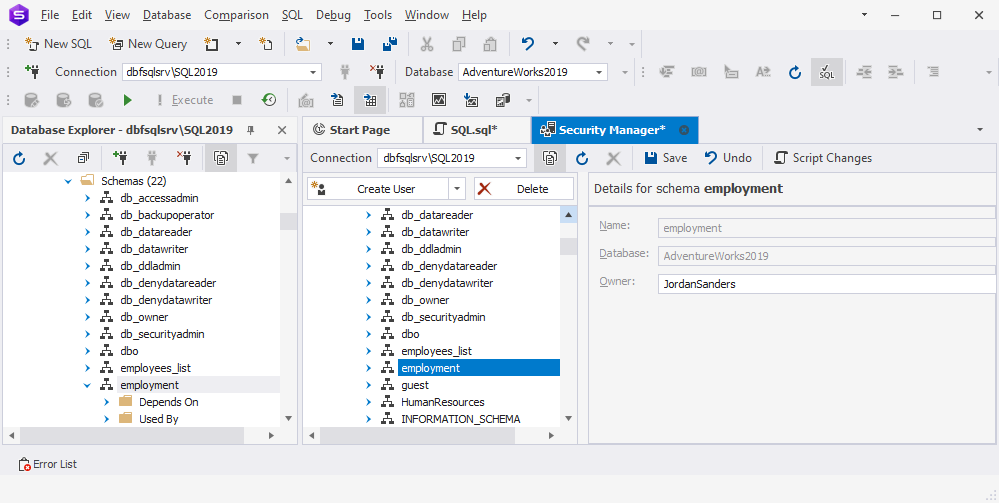
In Security Manager that opens, change the owner and click Save.
With the help of the ALTER SCHEMA statement, you can move securables from one schema to another within the same database. A securable is a database object with permissions and access granted, denied, and controlled by SQL Server.
The syntax is as follows:
ALTER SCHEMA target_schema_name
TRANSFER [ entity_type :: ] securable_name;where:
target_schema_name is the name of a schema in the current database, into which the securable will be moved.
entity_type is the class of the entity for which the owner is being changed. It can be Object, Type, or XML Schema Collection.
securable_name is the name of the object you want to move to the target schema.
When moving a stored procedure, function, view, or trigger, they should be dropped and recreated in the target schema. For these objects, the ALTER SCHEMA statement is not recommended to use.
When moving a table or synonym referenced in another database object definition, they should be manually modified to define the target schema name.
See also: How to compare and synchronize schemas with dbForge Studio for SQL Server
How to drop a schema
The following example shows how to drop a schema with the help of dbForge Studio for SQL Server. For this, in Database Explorer, right-click the schema you want to drop and select Delete. In the pop-up message that opens, confirm the deletion by clicking OK.
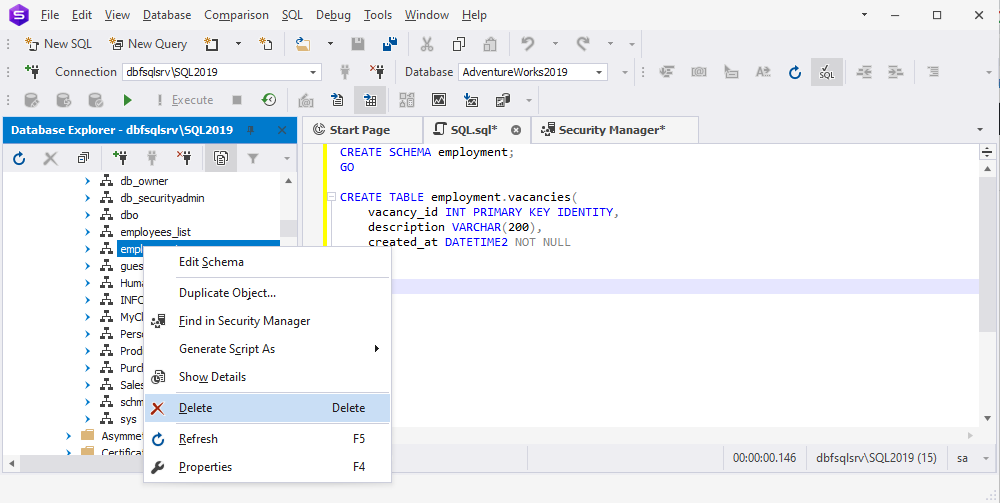
If there are objects referenced to the schema, first, you should delete the objects and then drop the schema.
In complex environments, especially those involving multiple platforms, it’s often helpful to run a schema comparison before making changes. For example, teams working with Oracle can use an Oracle schema compare tool to identify dependencies and ensure structural accuracy prior to deletion.
Also, you can drop the schema using the DROP SCHEMA statement. The syntax is as follows:
DROP SCHEMA [IF EXISTS] schema_name;Try it yourself with dbForge Studio for SQL Server
As you could see, we used dbForge Studio for SQL Server to show you our examples in action. The Studio is a top-tier alternative to the standard SSMS and a comprehensive solution for everyone who needs to handle the widest variety of tasks in SQL Server, from completion-aided SQL coding, visual database design and query building to database comparison and synchronization, source control, and data analysis.
To get a clear picture of what the Studio is, here is a concise yet informative video that compares it feature-wise with SSMS and shows just how much more it offers for your daily work with SQL Server databases.
You can try it out today—just download the Studio for a free 30-day trial, install it, connect to your SQL Server database, and explore its capabilities in full.
Further learning
To get acquainted with dbForge Studio for SQL Server more closely, we suggest checking out dbForge Studio documentation, which offers in-depth insights into every feature of the Studio, and dbForge Studio video tutorials, which conveniently cover the most relevant topics.
Additionally, you can explore a diversity of SQL Server tutorials on our blog and take a look at Devart Academy, which currently features a video course that will boost your mastery of SQL coding using another dbForge tool for SQL Server called SQL Complete.
If you work with PostgreSQL as well, Devart offers a dedicated PostgreSQL schema compare tool to help synchronize and manage schema differences across environments.