
There is a number of powerful MySQL storage engines at our disposal, and InnoDB is undoubtedly one of the most popular ones. It is highly reliable and efficient, so it is no wonder that it has become a default storage engine for all MySQL versions from 5.5 on. Let us take a look at its advantages and features more closely.
Contents
- What is InnoDB in MySQL?
- InnoDB Cluster
- Creating InnoDB tables
- InnoDB server variables & performance tuning tips
- Handling the most common errors in InnoDB
- Getting maximum performance using InnoDB with dbForge Studio for MySQL
What is InnoDB in MySQL?
Now we would like to pinpoint what makes MySQL InnoDB storage engine special. Here are its main advantages:
- InnoDB is ACID-based and supports commit and rollback operations. Moreover, it is less likely to crash, so the users’ data remains protected.
- Multi-user performance is possible due to row-level locking.
- Since InnoDB tables organize data effectively, queries based on primary keys are optimized. There is a primary key index called the clustered index in each InnoDB table. This index arranges the data to reduce I/O for primary key queries.
- MySQL InnoDB supports foreign key constraints, which allows achieving and maintaining data integrity.
InnoDB can also be used with the MariaDB server. In this case, InnoDB delivers foreign keys, XA transactions, and transactions with savepoints.

InnoDB Cluster
Every company’s policy presupposes providing the safest and the most stable data flow. But how can it be achieved and guaranteed? The answer lies in MySQL InnoDB Cluster, which offers a convenient solution for MySQL. With the involvement of AdminAPI and MySQL Shell, you can easily manage multiple MySQL server instances to work as a single InnoDB Cluster.
The components of MySQL InnoDB Cluster include the following:
- MySQL Router (safe routing to database nodes)
- MySQL Group Replication (multiple database servers that replicate each other)
- MySQL Shell (a configuration tool for MySQL, which helps enable topologies with fault tolerance)
See how it all works together in a single InnoDB Cluster:

Creating InnoDB tables
In order to create an InnoDB table, you simply specify ENGINE = InnoDB in your CREATE TABLE statement. For instance:
CREATE TABLE Emp
(
EmpID SMALLINT UNSIGNED NOT NULL,
YearBorn YEAR NOT NULL,
CityBorn VARCHAR(40) NOT NULL DEFAULT 'Unknown'
)
ENGINE=INNODB;
InnoDB server variables & performance tuning tips
Here is the list of available InnoDB server variables that help speed up and optimize your performance and interactions between MySQL databases and the InnoDB storage engine:
- innodb_flush_log_at_trx_commit
- innodb_buffer_pool_size
- innodb_buffer_pool_instances
- innodb_file_per_table
- innodb_force_recovery
- innodb_lock_wait_timeout
- innodb_large_prefix
- innodb_flush_method
- innodb_thread_concurrency
- innodb_log_buffer_size
- innodb_io_capacity
- innodb_strict_mode
- innodb_autoinc_lock_mode
- innodb_read_io_threads
- innodb_data_file_path
innodb_flush_log_at_trx_commit
The basic syntax for this command is --innodb-flush-log-at-trx-commit=#. It configures how often the transactions are flushed to the redo log.
innodb_buffer_pool_size
The basic syntax for this command is --innodb-buffer-pool-size=#. The InnoDB buffer pool is a memory domain where the InnoDB storage engine caches its table and index data. The default value is 134217728 bytes (128MB). The CPU architecture defines the maximum value, which equals 4294967295 (232-1) on 32-bit systems and 18446744073709551615 (264-1) on 64-bit systems.
innodb_buffer_pool_instances
The basic syntax for this command is --innodb-buffer-pool-instances=#. It denotes the number of regions that the InnoDB buffer pool must consist of. When it comes to buffer pools in the multi-gigabyte range, the division of an entire pool into multiple separate instances can improve concurrency.
innodb_file_per_table
The basic syntax for this command is --innodb-file-per-table[={OFF|ON}]. When the variable is enabled, tables are generated in file-per-table tablespaces by default. If it is disabled, tables are generated in the system tablespace.
innodb_force_recovery
The basic syntax for this command is --innodb-force-recovery=#. It is a crash recovery mode, usually applied for troubleshooting issues. The allowed values range from 0 to 6.
innodb_lock_wait_timeout
The basic syntax for this command is --innodb-lock-wait-timeout=#. The default duration is 50 seconds. After that, the InnoDB transaction is interrupted. If the time limit is exceeded, the following error will be issued:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
In this case, only the statement is rolled back. If you want to rollback the entire transaction, use the
–innodb-rollback-on-timeout command.
innodb_large_prefix
The basic syntax for this command is --innodb-large-prefix[={OFF|ON}]. If this option is enabled, index key prefixes exceeding 767 bytes (up to 3072 bytes) are permitted for InnoDB tables where the row format is DYNAMIC or COMPRESSED. This command does not influence the allowed index key prefix length for the tables where the row format is REDUNDANT or COMPACT.
innodb_flush_method
Use the --innodb-flush-method=value command to specify the approach that will be used to flush data to InnoDB files. Please note that the I/O throughput can be affected.
innodb_thread_concurrency
The basic syntax for this command is --innodb-thread-concurrency=#. It defines the maximum number of threads allowed by InnoDB. The infinite concurrency is defined by a value of 0, which is set by default.
innodb_log_buffer_size
The basic syntax for this command is --innodb-log-buffer-size=#. This is the size of the buffer for transactions that have not yet been committed. The value of this parameter should be changed in case you use large fields like BLOB or TEXT.
innodb_io_capacity
The basic syntax for this command is --innodb-io-capacity=#. It specifies the number of I/O transactions per second (IOPS) accessible to InnoDB background operations.
innodb_strict_mode
The basic syntax for this command is --innodb-strict-mode[={OFF|ON}]. The strict mode acts as a shield against various accidental outcomes of different sequences of SQL statements and operational modes. When innodb_strict_mode is enabled, InnoDB issues errors for particular conditions.
innodb_autoinc_lock_mode
The basic syntax for this command is --innodb-autoinc-lock-mode=#. Auto-increment values are generated in the lock mode. The allowed values are 0, 1, or 2 (for traditional, consecutive, or interleaved lock mode, respectively). 1 (consecutive) is set by default.
innodb_read_io_threads
Use the --innodb-read-io-threads=# command to define the number of InnoDB file I/O streams.
innodb_data_file_path
The basic syntax for this command is –innodb-data-file-path=file_name. It specifies the information about the InnoDB system tablespace data files. If a value for innodb_data_file_path has not been defined, a single auto-extending data file is to be generated by default. This data file name is ibdata1, and its size is approximately 12MB.
The full syntax for a data file is as follows:file_name:file_size[:autoextend[:max:max_file_size]]
It consists of the file name, file size, autoextend attribute, and max attribute.
To get more detailed information, see InnoDB startup options and system variables.
Please note: While executing your operations, it is important to make sure that InnoDB is not using its own memory instead of the memory of the operating system. In this case, you will see a notification that the InnoDB memory heap is disabled, and an error will be displayed. It can be resolved by setting the value of innodb_use_sys_malloc to ON or 1 instead of 0.
Learn the difference between MyISAM and InnoDB performance and which is the better choice for your needs.
Handling the most common errors in InnoDB
Handling of errors in InnoDB is not always identical to the specified SQL standard. For instance, an error in a SQL statement must cause the rollback of the said statement. As for InnoDB, in some cases the failed statement gets rolled back; in others, there is a rollback of the entire transaction.
- Running out of space in a tablespace causes the
Table is fullerror, and the SQL statement gets rolled back. - A duplicate-key error causes a statement rollback unless the IGNORE option is specified in the said statement.
- A lock wait timeout causes the rollback of the statement that was waiting for the lock but faced the timeout.
- The
row too longerror also rolls back the corresponding statement. - A transaction deadlock causes the rollback of an entire transaction, which should be retried afterwards.
- Other errors are generally detected by the MySQL layer of code and thus lead to the rollback of the related statement.
Getting maximum performance using InnoDB with dbForge Studio for MySQL
Now we would like to suggest an IDE that will facilitate your work with MySQL databases and the InnoDB engine – dbForge Studio for MySQL. While it is fully compatible with all popular MySQL database engines (check the full list here), InnoDB is the one that deserves a special mention.
First and foremost, dbForge Studio supports every single advantage delivered by InnoDB, including those mentioned at the beginning of our story. Furthermore, you get a number of nifty features that will accelerate and simplify your daily work (e.g. autocommit operations). It is also worth noting that dbForge Studio uses InnoDB by default when creating tables.
Second, you can find the abovementioned server variables by proceeding to the Database menu -> Server Variables, as shown in the screenshot below.
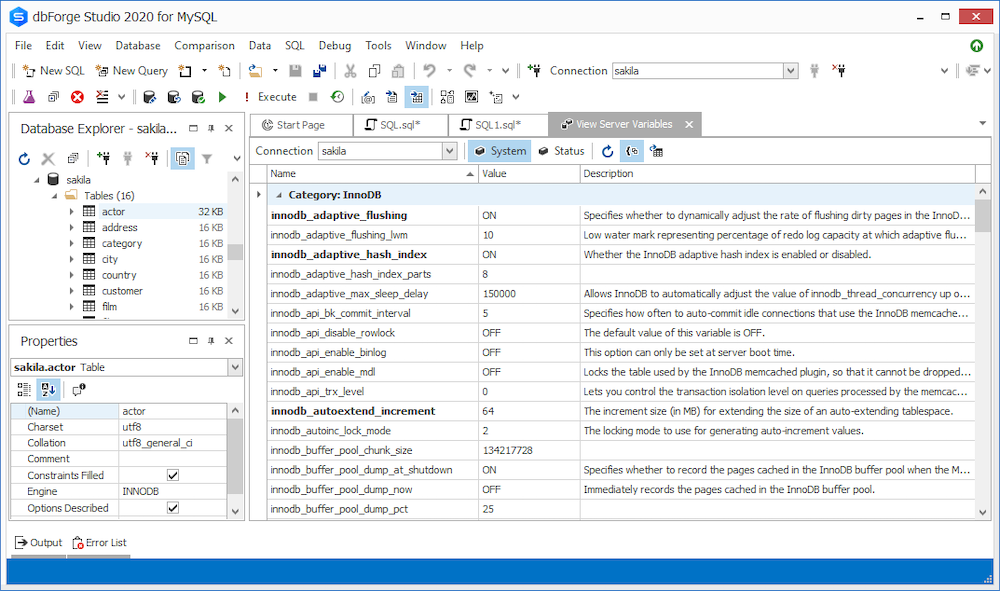
Open Category: InnoDB, and you will find all of them.
Finally, dbForge Studio supports XtraDB, a backward-compatible fork of InnoDB, developed by Percona for MariaDB and Percona Server databases.
Download a 30-day free trial of dbForge Studio for MySQL and try your own hand at all the features it delivers.
